HBase高手之路5—HBase的JavaAPI编程
文章目录
- Hbase高手之路5—Hbase的JavaAPI编程
-
- 一、需求与数据集
- 二、准备工作
-
- 1.下载安装Java
- 2.下载安装Idea
- 3.下载安装maven
- 4.Maven配置国内的镜像库
- 5.Idea使用自定义的maven配置
- 6.创建一个maven测试项目
- 7.创建所需要的包
- 8.创建类文件,输入代码
- 9.运行项目
- 三、创建HBase java api项目
-
- 1.修改pom文件,导入HBase的Java API的依赖包
- 2.创建HBase的连接类
- 3.运行,查看结果
- 四、案例一:使用HBase的Java API创建表
-
- 1.主要步骤
- 2.把hadoop的配置文件core-site.xml和HBase的配置文件hbase-site.xml复制到resources文件夹下,同时再添加一个日志文件log4j.properties
- 3.编写代码
- 4.运行,查看结果
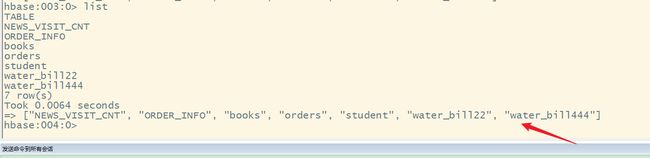
- 5.在HBase的shell中查看创建的表名
- 五、案例二:删除创建的表
-
- 1.主要步骤
- 2.创建类,编写代码
- 六、代码优化
-
- 1.创建一个获取admin的类
- 2.修改删除表的类的代码
- 3.运行,查看结果
- 七、代码继续优化
-
- 1.创建一个主类,把前面的类的功能写成对应的方法
- 2.main调用相应的方法实现操作
-
- 2.1 创建表
- 2.2 删除表
- 2.3 进一步优化代码
- 八、案例三:往创建的表中插入数据
-
- 1.主要步骤
- 2.创建方法,编写代码
- 3.在main中调用插入数据的方法
- 4.执行,查看结果
- 5.作业:插入其他列的数据
- 6.完整代码
- 九、案例四:获取数据
-
- 1.获取某一列的数据
-
- 1)获取某一列的数据
- 2)在main中调用用并执行,查看结果
- 2.获取一行数据
- 3.代码
- 十、案例五:删除数据
- 十一、案例六:导入大量的数据
-
- 1.需求
- 2.导入数据到HBase表中
- 3.上传数据文件到hdfs上
- 4.创建表
- 5.启动yarn
- 6.运行导入命令
- 7.查看数据
- 8.count计数
- 9.mapreduce 计数
- 十二、案例七:查询2020年6月份所有的用户的用水量
-
- 1.需求分析
- 2.编写代码
- 3.在main中调用方法
- 4.执行,查看结果
- 5.用量及金额乱码,需要对代码进行改进
- 十三、案例八:导出数据

Hbase高手之路5—Hbase的JavaAPI编程
一、需求与数据集
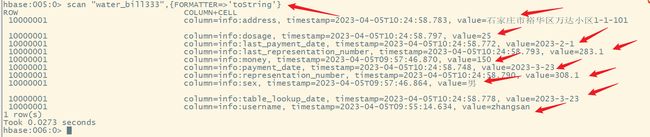
某某自来水公司,需要存储大量的缴费明细数据。以下截取了缴费明细的一部分内容。
| 用户ID | 姓名 | 地址 | 性别 | 缴费时间 | 表示数(本次) | 表示数(上次) | 用量(立方) | 金额 | 查表日期 | 最近缴费日期 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4944191 | 张三 | 石家庄市裕华区万达小区1-1-101 | 男 | 2023-3-23 | 308.1 | 283.1 | 25 | 150 | 2023-3-23 | 2023-2-1 |
因为缴费明细的数据记录非常庞大,该公司的信息部门决定使用HBase来存储这些数据。并且,他们希望能够通过Java程序来访问这些数据。
二、准备工作
1.下载安装Java
下载jdk1.8
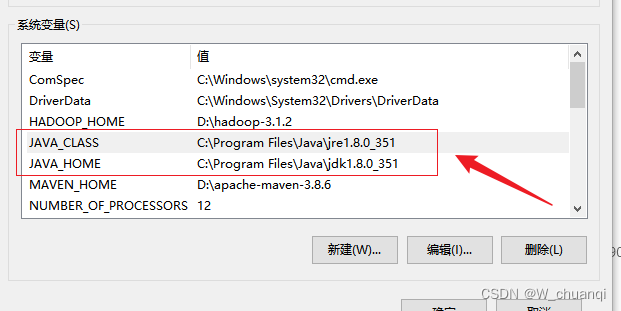
环境变量配置
2.下载安装Idea
下载社区版本就可以了。
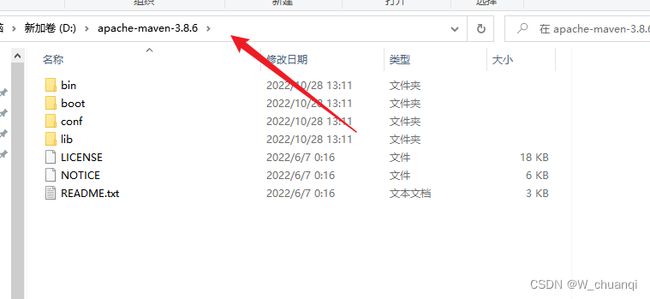
3.下载安装maven
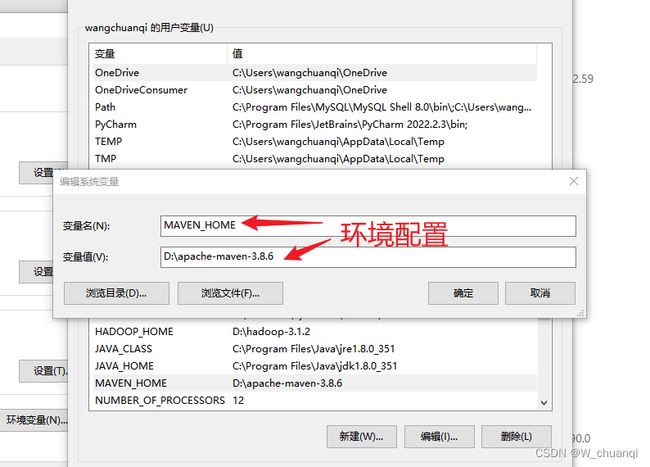
4.Maven配置国内的镜像库
打开配置文件:
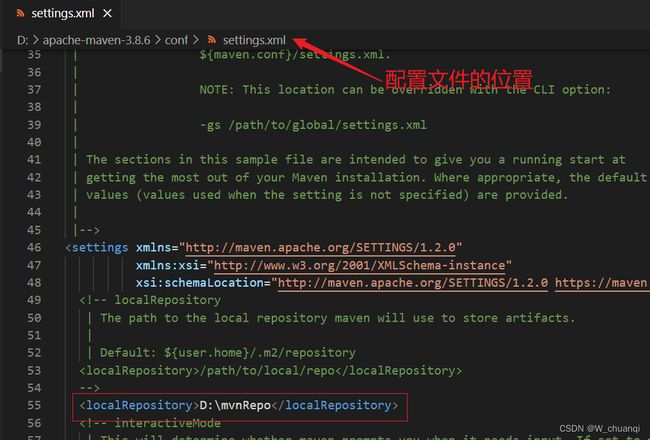
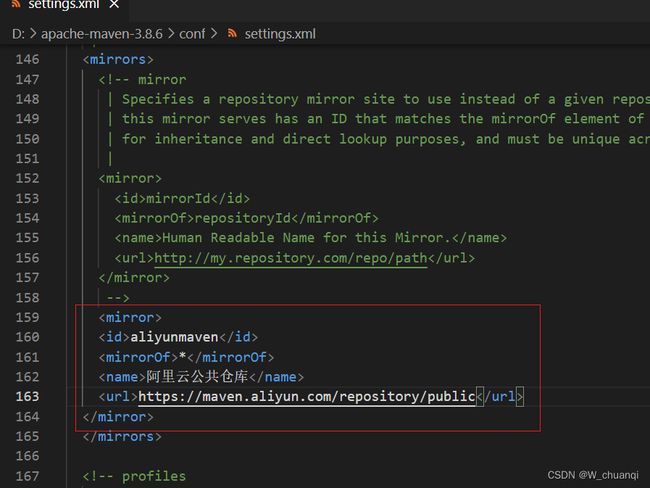
配置阿里云镜像:
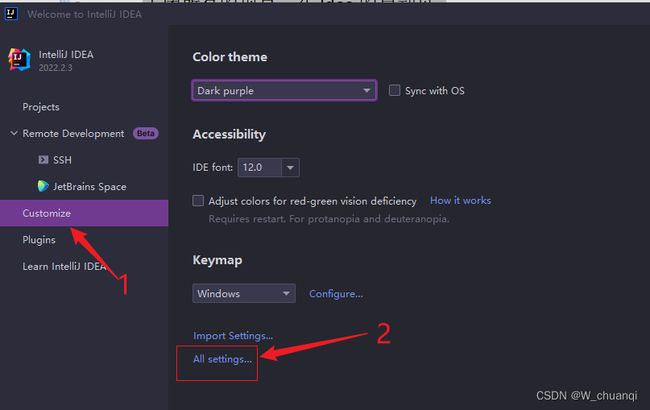
5.Idea使用自定义的maven配置
关闭所有的项目,在Idea的启动页
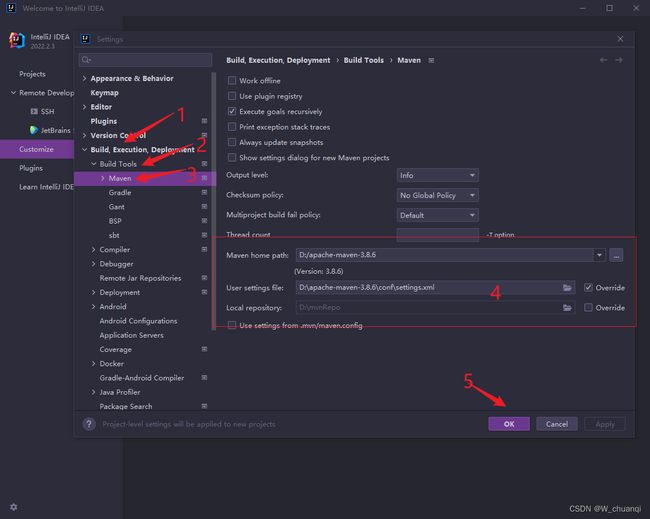
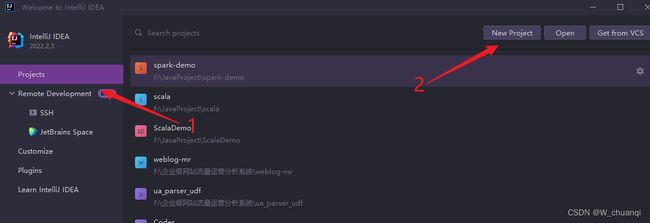
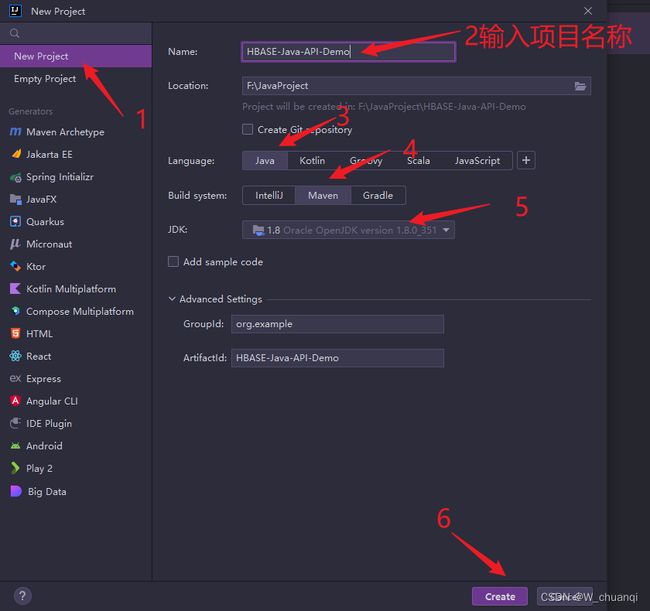
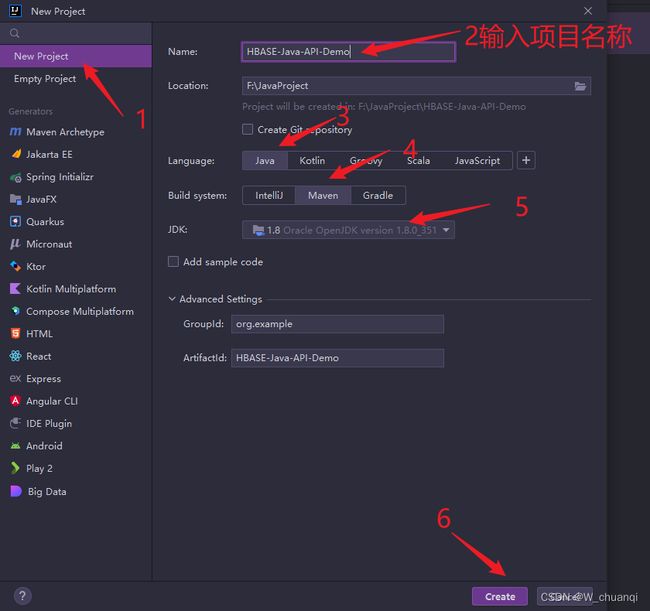
6.创建一个maven测试项目
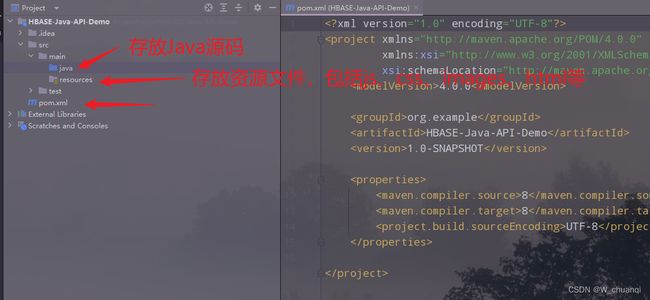
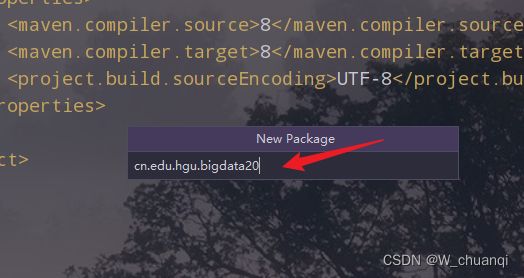
7.创建所需要的包
8.创建类文件,输入代码
快捷键
psvm:
public static void main(String[] args) { }sout:
System.out.println();
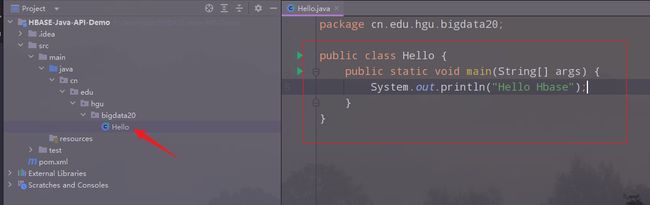
9.运行项目
点击运行项目:
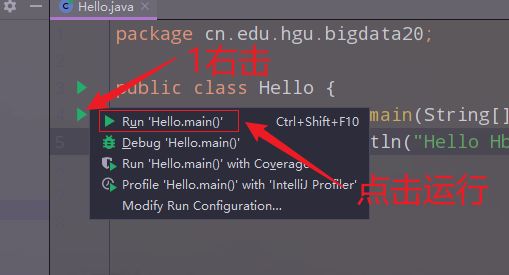
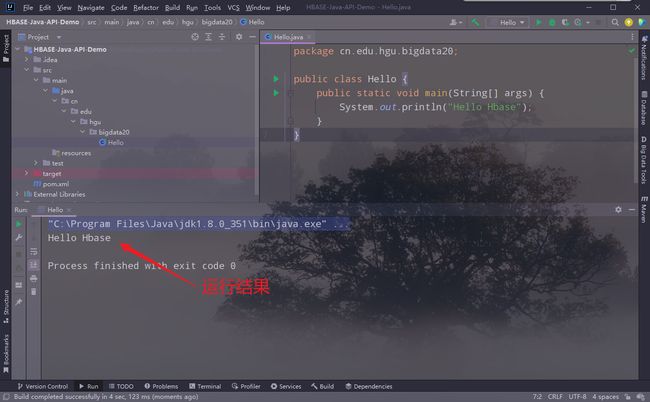
查看输出结果:
三、创建HBase java api项目
在测试项目的基础上
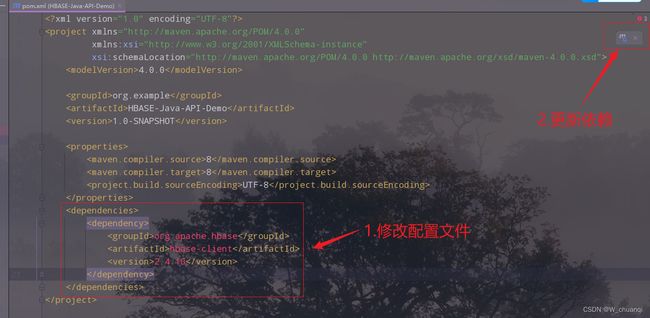
1.修改pom文件,导入HBase的Java API的依赖包
org.apache.hbase
hbase-client
2.4.10
2.创建HBase的连接类
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class Hello {
public static void main(String[] args) {
Configuration configuration = new Configuration();
try {
Connection connection = ConnectionFactory.createConnection(configuration);//工厂模式
Admin admin = connection.getAdmin();
System.out.println(admin);
} catch (IOException e) {
e.printStackTrace();
}
}
}
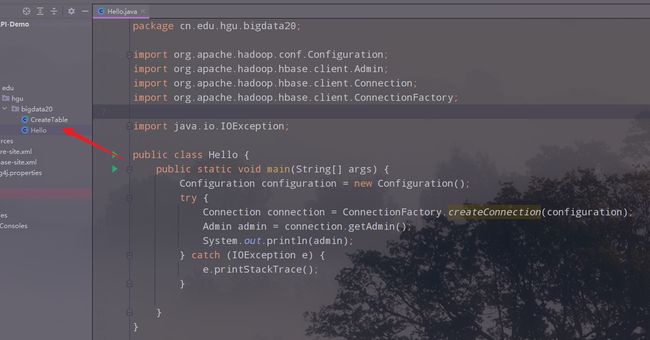
3.运行,查看结果
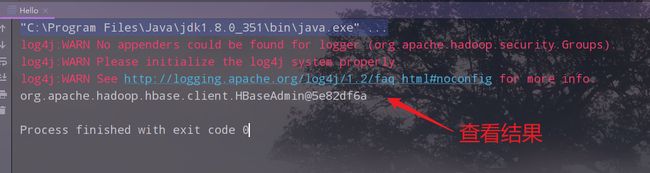
四、案例一:使用HBase的Java API创建表
创建一个名为water_bill的表,包含一个列簇info
1.主要步骤
- 定义表名,判断表是否存在
- 表描述构建器,建立表描述对象
- 列簇描述构建器,建立列簇描述对象
- 表描述对象和列簇描述对象建立关系
- 创建表
2.把hadoop的配置文件core-site.xml和HBase的配置文件hbase-site.xml复制到resources文件夹下,同时再添加一个日志文件log4j.properties
先导出到本地计算机
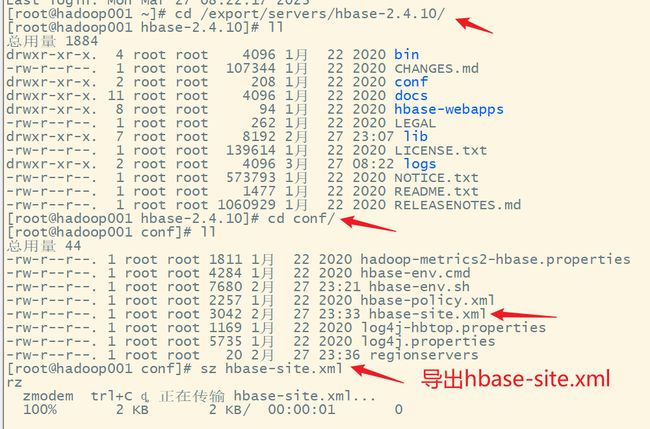
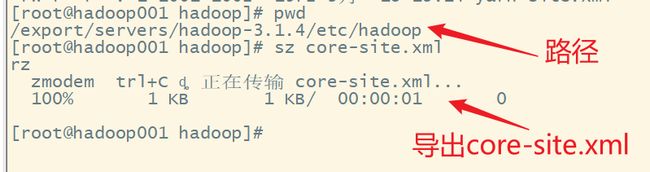
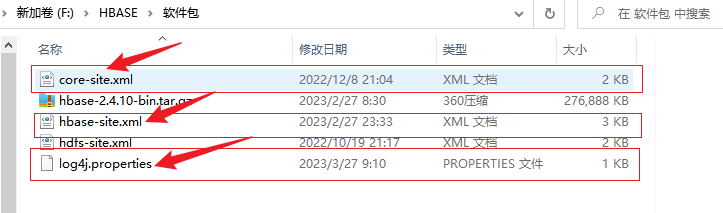
复制到resources文件夹下
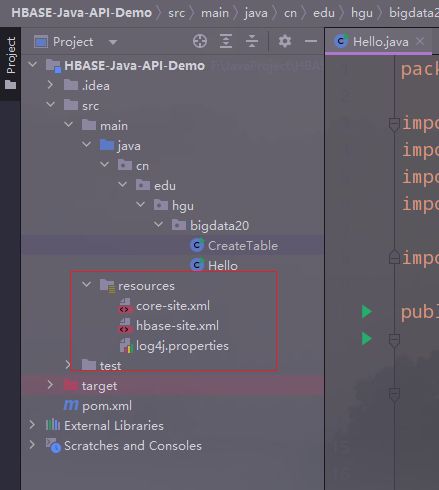
3.编写代码
创建CreateTable类,编写代码
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* describe:创建表
* author:王
* date:2023/03/27
*/
public class CreateTable {
public static void main(String[] args) {
// 定义配置
Configuration configuration = HBaseConfiguration.create();
try {
// 定义HBase连接
Connection connection = ConnectionFactory.createConnection(configuration);//工厂模式
// 定义Admin对象
Admin admin = connection.getAdmin();
System.out.println(admin);
// 1.定义表名,判断表是否存在
TableName tableName = TableName.valueOf("water_bill");
// 2.表描述构建器
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tableName);//构建器模式
// 3.列簇描述构建器
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
// 3.1 定义列簇描述构建器,建立列簇描述对象
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 4.表描述对象和列簇描述对象建立关系
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
// 定义表描述对象
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 5.创建表
admin.createTable(tableDescriptor);
} catch (IOException e) {
e.printStackTrace();
}
}
}
4.运行,查看结果
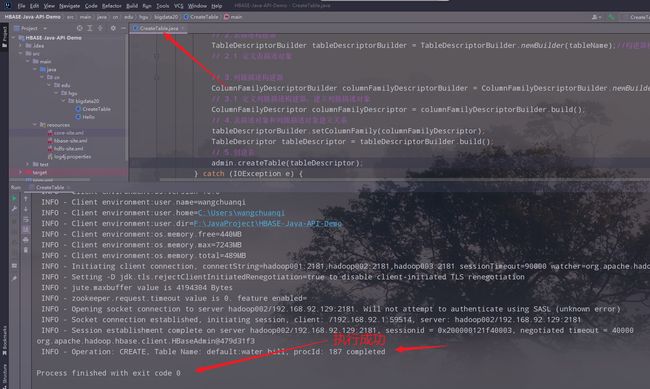
5.在HBase的shell中查看创建的表名

五、案例二:删除创建的表
删除刚刚创建的表
1.主要步骤
- 定义表名,判断表是否存在
- 如果表存在,禁用表
- 删除表
2.创建类,编写代码
package cn.edu.hgu.bigdata20;
import javafx.scene.control.Tab;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* describe:删除表
* author:王
* date:2023/03/27
*/
public class DeleteTable {
public static void main(String[] args) throws IOException {
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
Connection connection = null;
Admin admin = null;
try {
//通过工厂模式,根据配置来创建连接
connection = ConnectionFactory.createConnection(configuration);
//System.out.println(connection);
// 3.创建admin对象
admin = connection.getAdmin();
//System.out.println(admin);
// 1.定义表名,判断表是否存在
TableName tableName = TableName.valueOf("water_bill");
// 2.如果存在,禁用表
if (admin.tableExists(tableName)) {
//禁用表
admin.disableTable(tableName);
//3.删除表
admin.deleteTable(tableName);
} else {
System.out.println("表不存在!");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
admin.close();
connection.close();
}
}
}
六、代码优化
因为每种操作都需要admin对象,可以将其拿出来,作为一个单独的类。
1.创建一个获取admin的类
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* describe:获取admin对象
* author:王
* date:2023/03/27
*/
public class GetAdmin {
public static Admin getAdmin() throws IOException {
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
//通过工厂模式,根据配置来创建连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 3.创建admin对象
Admin admin = connection.getAdmin();
// 4.返回创建的admin对象
return admin;
}
}
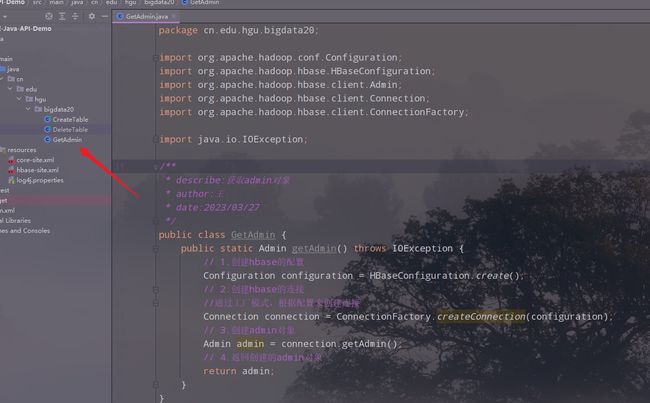
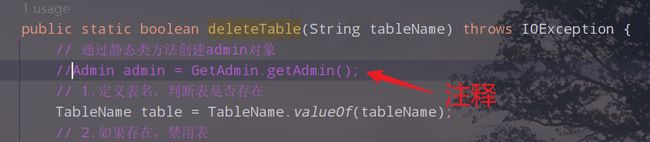
2.修改删除表的类的代码
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import java.io.IOException;
/**
* describe:删除表
* author:王
* date:2023/03/27
*/
public class DeleteTable {
public static void main(String[] args) throws IOException {
// 通过静态类方法创建admin对象
Admin admin = GetAdmin.getAdmin();
// 1.定义表名,判断表是否存在
TableName tableName = TableName.valueOf("water_bill");
// 2.如果存在,禁用表
if (admin.tableExists(tableName)) {
//禁用表
admin.disableTable(tableName);
//3.删除表
admin.deleteTable(tableName);
} else {
System.out.println("表不存在!");
}
}
}
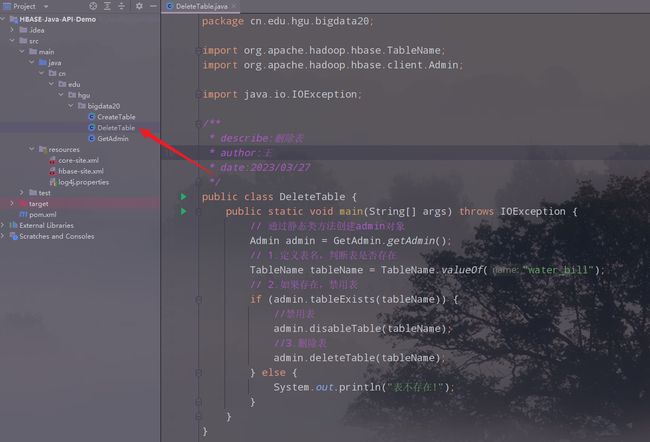
3.运行,查看结果
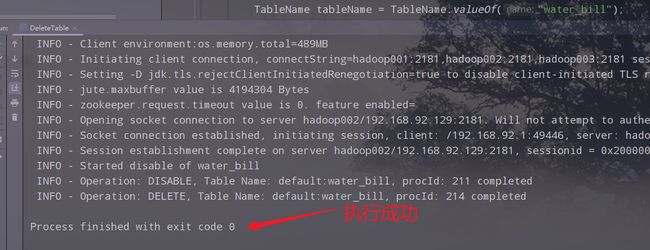

七、代码继续优化
1.创建一个主类,把前面的类的功能写成对应的方法
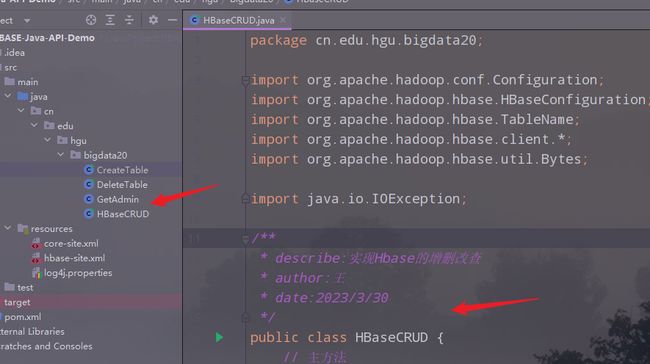
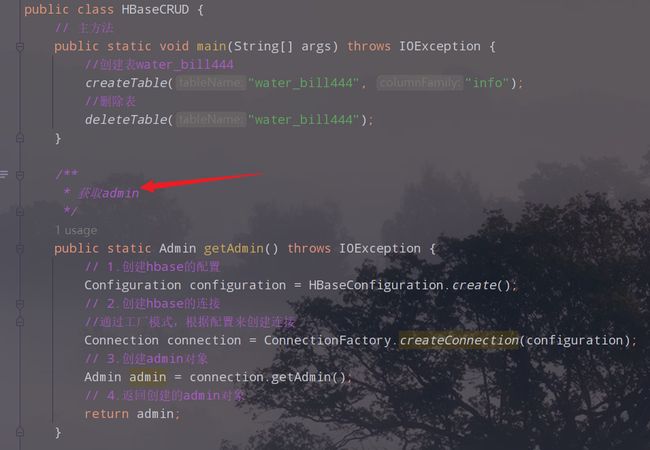
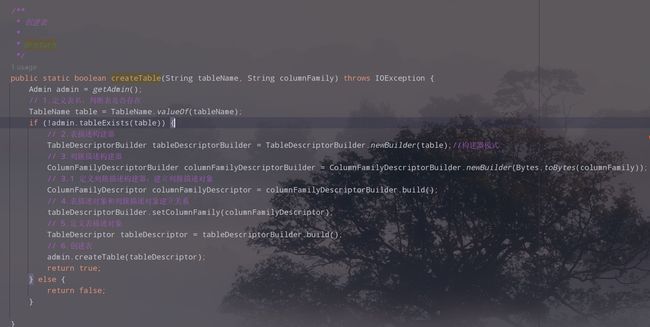
代码如下:
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* describe:实现Hbase的增删改查
* author:王
* date:2023/3/30
*/
public class HBaseCRUD {
// 主方法
public static void main(String[] args) throws IOException {
//创建表water_bill444
createTable("water_bill444", "info");
//删除表
deleteTable("water_bill444");
}
/**
* 获取admin
*/
public static Admin getAdmin() throws IOException {
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
//通过工厂模式,根据配置来创建连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 3.创建admin对象
Admin admin = connection.getAdmin();
// 4.返回创建的admin对象
return admin;
}
/**
* 创建表
*
* @return
*/
public static boolean createTable(String tableName, String columnFamily) throws IOException {
Admin admin = getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
if (!admin.tableExists(table)) {
// 2.表描述构建器
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(table);//构建器模式
// 3.列簇描述构建器
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
// 3.1 定义列簇描述构建器,建立列簇描述对象
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 4.表描述对象和列簇描述对象建立关系
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
// 5.定义表描述对象
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 6.创建表
admin.createTable(tableDescriptor);
return true;
} else {
return false;
}
}
/**
* 删除表
*/
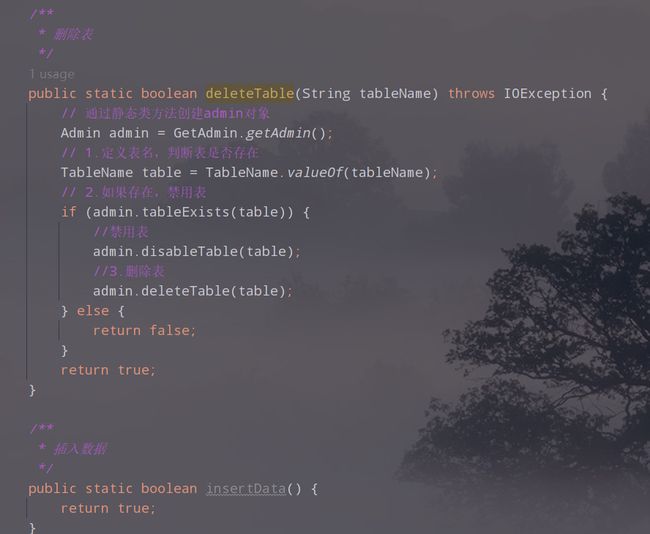
public static boolean deleteTable(String tableName) throws IOException {
// 通过静态类方法创建admin对象
Admin admin = GetAdmin.getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
// 2.如果存在,禁用表
if (admin.tableExists(table)) {
//禁用表
admin.disableTable(table);
//3.删除表
admin.deleteTable(table);
} else {
return false;
}
return true;
}
/**
* 插入数据
*/
public static boolean insertData() {
return true;
}
}
2.main调用相应的方法实现操作
2.1 创建表
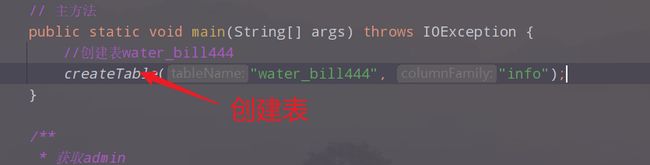
2.2 删除表
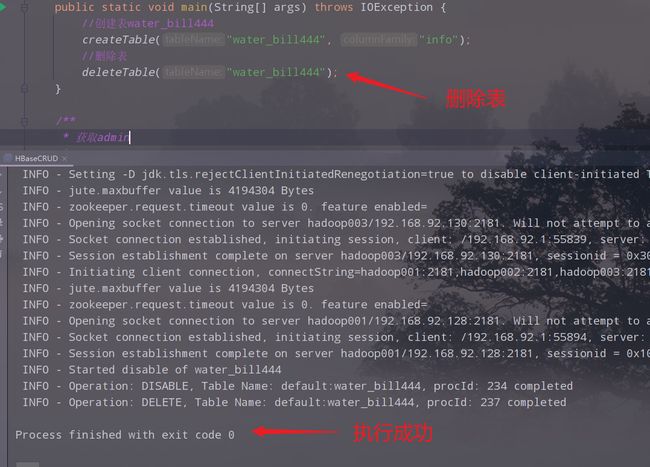
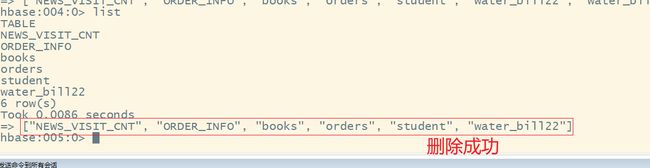
2.3 进一步优化代码
我们发现创建表和删除表方法中的admin是重复调用的,感觉比较浪费资源,我们可以先对使用初始化方法,初始化admin,其他的方法只需要调用这个静态变量就可以了,而不是调用getAdmin方法。
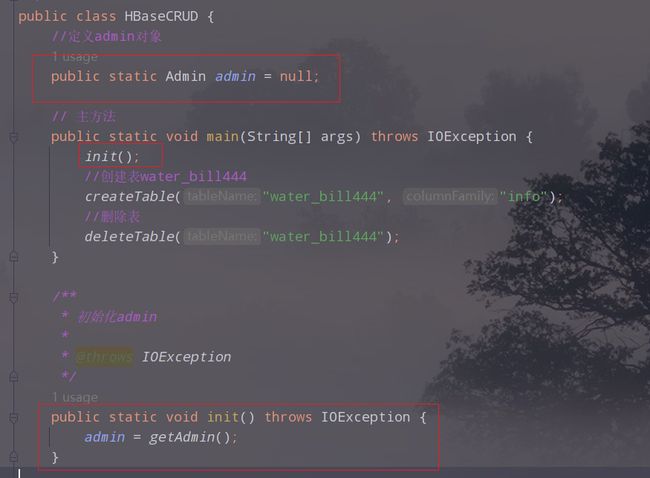

代码如下:
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* describe:实现Hbase的增删改查
* author:王
* date:2023/3/30
*/
public class HBaseCRUD {
//定义admin对象
public static Admin admin = null;
// 主方法
public static void main(String[] args) throws IOException {
init();
//创建表water_bill444
createTable("water_bill444", "info");
//删除表
deleteTable("water_bill444");
}
/**
* 初始化admin
*
* @throws IOException
*/
public static void init() throws IOException {
admin = getAdmin();
}
/**
* 获取admin
*/
public static Admin getAdmin() throws IOException {
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
//通过工厂模式,根据配置来创建连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 3.创建admin对象
Admin admin = connection.getAdmin();
// 4.返回创建的admin对象
return admin;
}
/**
* 创建表
*
* @param tableName
* @param columnFamily
* @return
* @throws IOException
*/
public static boolean createTable(String tableName, String columnFamily) throws IOException {
//Admin admin = getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
if (!admin.tableExists(table)) {
// 2.表描述构建器
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(table);//构建器模式
// 3.列簇描述构建器
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
// 3.1 定义列簇描述构建器,建立列簇描述对象
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 4.表描述对象和列簇描述对象建立关系
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
// 5.定义表描述对象
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 6.创建表
admin.createTable(tableDescriptor);
return true;
} else {
return false;
}
}
/**
* 删除表
*
* @param tableName
* @return
* @throws IOException
*/
public static boolean deleteTable(String tableName) throws IOException {
// 通过静态类方法创建admin对象
//Admin admin = GetAdmin.getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
// 2.如果存在,禁用表
if (admin.tableExists(table)) {
//禁用表
admin.disableTable(table);
//3.删除表
admin.deleteTable(table);
} else {
return false;
}
return true;
}
/**
* 插入数据
*/
public static boolean insertData() {
return true;
}
}
八、案例三:往创建的表中插入数据
往water_bill中插入数据
1.主要步骤
- 使用hbase的连接获取表对象
- 构建rowkey、列簇名、列名、值
- 构建Put对象(对应shell中的put命令)
- 添加某列(列簇、列名、值)
- 表对象执行put操作
- 关闭表对象
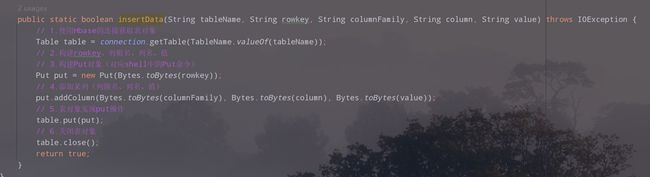
2.创建方法,编写代码
3.在main中调用插入数据的方法
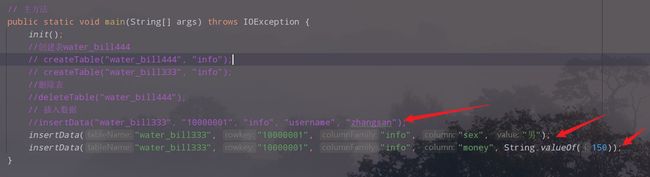
4.执行,查看结果

5.作业:插入其他列的数据
在前面,我们只插入了3列数据,下面我们插入其他列的数据:

6.完整代码
package cn.edu.hgu.bigdata20;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* describe:实现Hbase的增删改查
* author:王
* date:2023/3/30
*/
public class HBaseCRUD {
//定义admin对象
public static Admin admin = null;
// 定义connection对象
public static Connection connection = null;
// 主方法
public static void main(String[] args) throws IOException {
init();
//创建表water_bill444
// createTable("water_bill444", "info");
// createTable("water_bill333", "info");
//删除表
//deleteTable("water_bill444");
// 插入数据
//insertData("water_bill333", "10000001", "info", "username", "zhangsan");//插入姓名
//insertData("water_bill333", "10000001", "info", "sex", "男");//插入性别
//insertData("water_bill333", "10000001", "info", "money", String.valueOf(150));//插入金额
insertData("water_bill333", "10000001", "info", "payment_date", "2023-3-23");//插入缴费时间
insertData("water_bill333", "10000001", "info", "last_payment_date", "2023-2-1");//插入最近缴费日期
insertData("water_bill333", "10000001", "info", "table_lookup_date", "2023-3-23");//插入查表日期
insertData("water_bill333", "10000001", "info", "address", "石家庄市裕华区万达小区1-1-101");//插入地址
insertData("water_bill333", "10000001", "info", "representation_number", String.valueOf(308.1));//插入表示数(本次)
insertData("water_bill333", "10000001", "info", "last_representation_number", String.valueOf(283.1));//插入表示数(上次)
insertData("water_bill333", "10000001", "info", "dosage", String.valueOf(25));//插入用量(立方)
}
/**
* 初始化admin
*
* @throws IOException
*/
public static void init() throws IOException {
//admin = getAdmin();
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
//通过工厂模式,根据配置来创建连接
connection = ConnectionFactory.createConnection(configuration);
// 3.创建admin对象
admin = connection.getAdmin();
// 4.返回创建的admin对象
// return admin;
}
/**
* 获取admin
*/
public static Admin getAdmin() throws IOException {
// 1.创建hbase的配置
Configuration configuration = HBaseConfiguration.create();
// 2.创建hbase的连接
//通过工厂模式,根据配置来创建连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 3.创建admin对象
Admin admin = connection.getAdmin();
// 4.返回创建的admin对象
return admin;
}
/**
* 创建表
*
* @param tableName
* @param columnFamily
* @return
* @throws IOException
*/
public static boolean createTable(String tableName, String columnFamily) throws IOException {
//Admin admin = getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
if (!admin.tableExists(table)) {
// 2.表描述构建器
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(table);//构建器模式
// 3.列簇描述构建器
ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));
// 3.1 定义列簇描述构建器,建立列簇描述对象
ColumnFamilyDescriptor columnFamilyDescriptor = columnFamilyDescriptorBuilder.build();
// 4.表描述对象和列簇描述对象建立关系
tableDescriptorBuilder.setColumnFamily(columnFamilyDescriptor);
// 5.定义表描述对象
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
// 6.创建表
admin.createTable(tableDescriptor);
return true;
} else {
return false;
}
}
/**
* 删除表
*
* @param tableName
* @return
* @throws IOException
*/
public static boolean deleteTable(String tableName) throws IOException {
// 通过静态类方法创建admin对象
//Admin admin = GetAdmin.getAdmin();
// 1.定义表名,判断表是否存在
TableName table = TableName.valueOf(tableName);
// 2.如果存在,禁用表
if (admin.tableExists(table)) {
//禁用表
admin.disableTable(table);
//3.删除表
admin.deleteTable(table);
} else {
return false;
}
return true;
}
/**
* @param tableName
* @param rowkey
* @param columnFamily
* @param column
* @param value
* @return
* @throws IOException
* @describe 插入数据
*/
public static boolean insertData(String tableName, String rowkey, String columnFamily, String column, String value) throws IOException {
// 1.使用Hbase的连接获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 2.构建rowkey、列粗名、列名、值
// 3.构建Put对象(对应shell中的Put命令)
Put put = new Put(Bytes.toBytes(rowkey));
// 4.添加某列(列簇名、列名、值)
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
// 5.表对象实现put操作
table.put(put);
// 6.关闭表对象
table.close();
return true;
}
}
九、案例四:获取数据
1.获取某一列的数据
1)获取某一列的数据
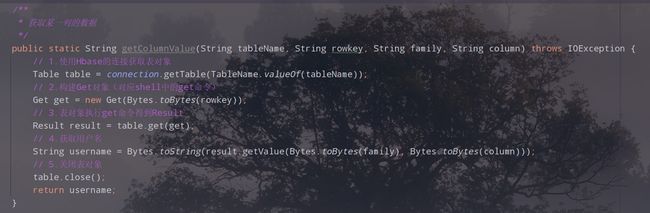
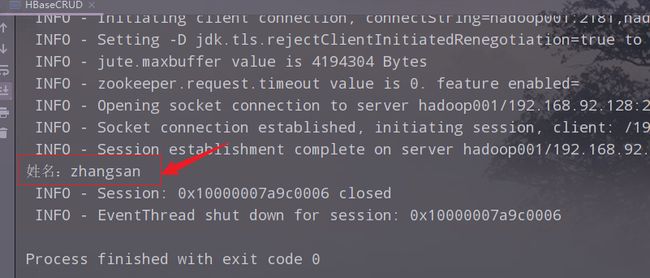
2)在main中调用用并执行,查看结果

2.获取一行数据
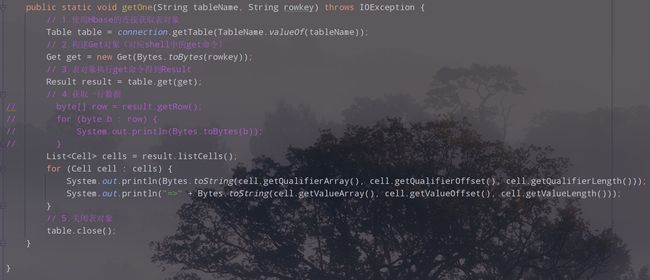
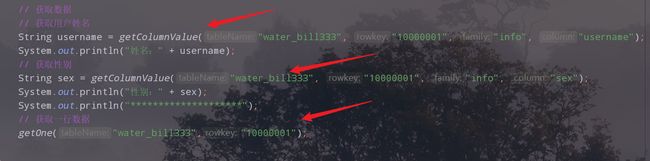
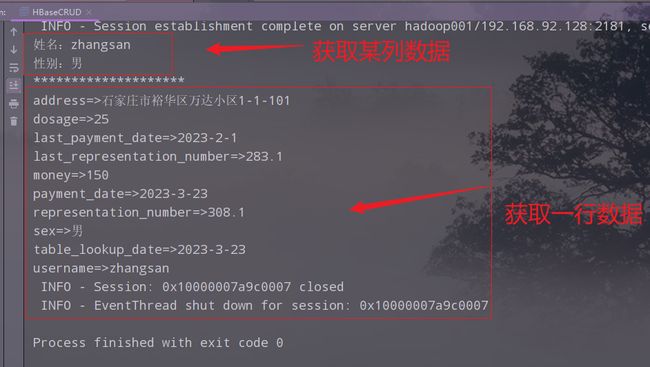
3.代码
public static void getOne(String tableName, String rowkey) throws IOException {
// 1.使用Hbase的连接获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 2.构建Get对象(对应shell中的get命令)
Get get = new Get(Bytes.toBytes(rowkey));
// 3.表对象执行get命令得到Result
Result result = table.get(get);
// 4.获取一行数据
// byte[] row = result.getRow();
// for (byte b : row) {
// System.out.println(Bytes.toBytes(b));
// }
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));
System.out.println("=>" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
// 5.关闭表对象
table.close();
十、案例五:删除数据
执行并查看结果



十一、案例六:导入大量的数据
1.需求
有一份10w条记录的抄表数据文件
2.导入数据到HBase表中
在HBase中,有一个import的MapReduce方法,可以专门用来将数据导入HBase表中。
使用命令:
hbase org.apache.hadoop.hbase.mapreduce.Import 表名 hdfs数据文件路径
3.上传数据文件到hdfs上
新建文件夹:
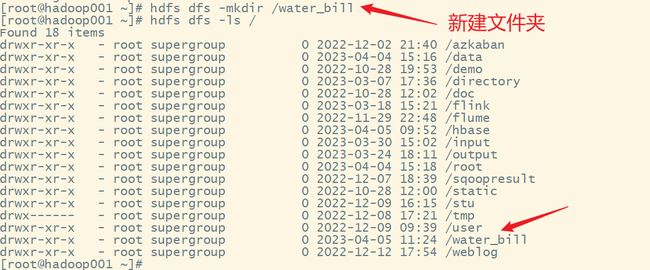
上传文件到hadoop集群:
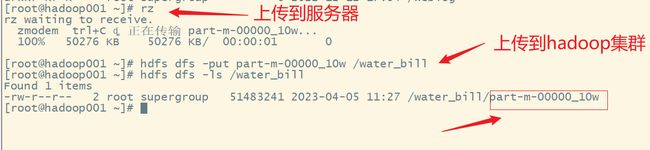
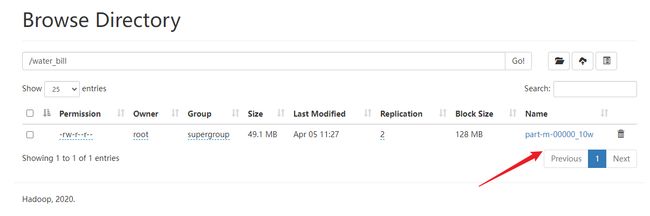
web ui查看
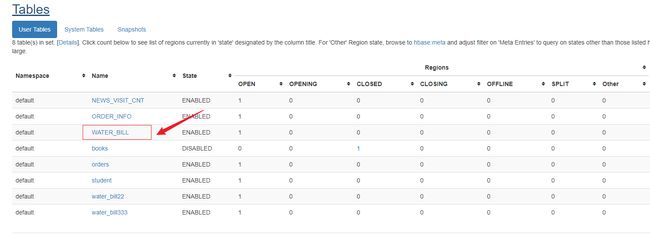
4.创建表

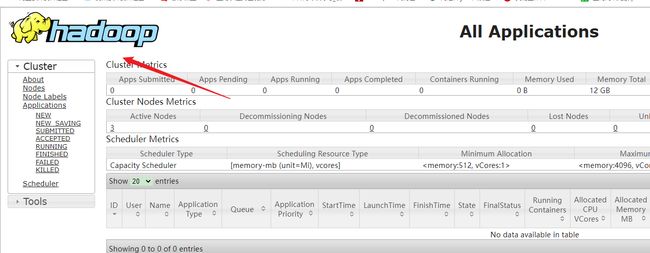
5.启动yarn
6.运行导入命令
hbase org.apache.hadoop.hbase.mapreduce.Import WATER_BILL /water_bill

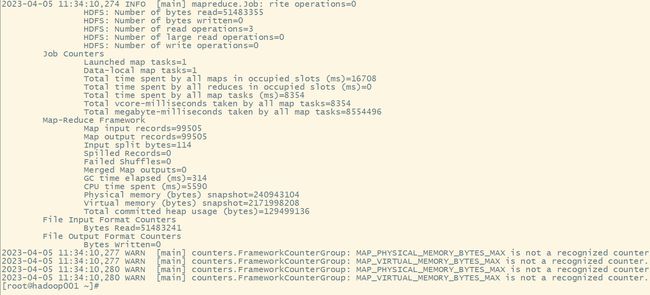
执行成功:
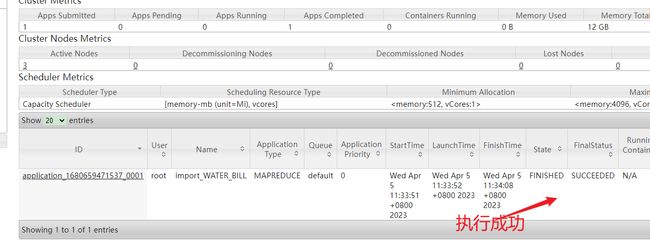
7.查看数据
scan "WATER_BILL",{FORMATTER=>'toString',LIMIT=>2}
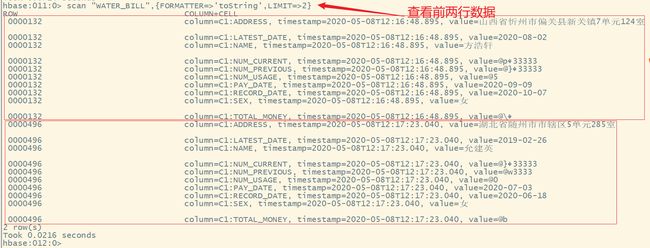
8.count计数
count "WATER_BILL"
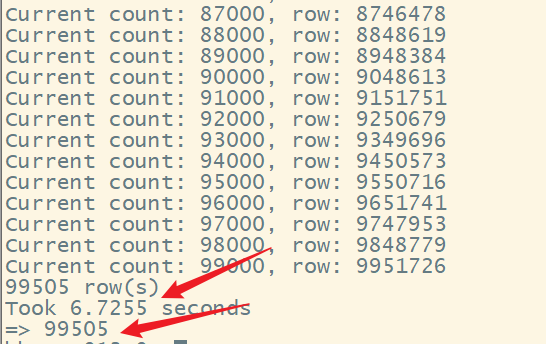
9.mapreduce 计数
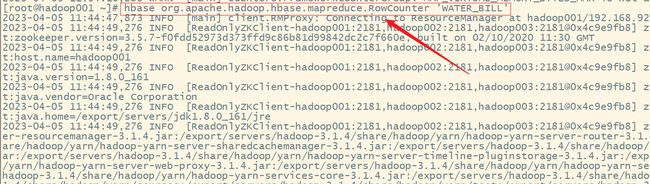
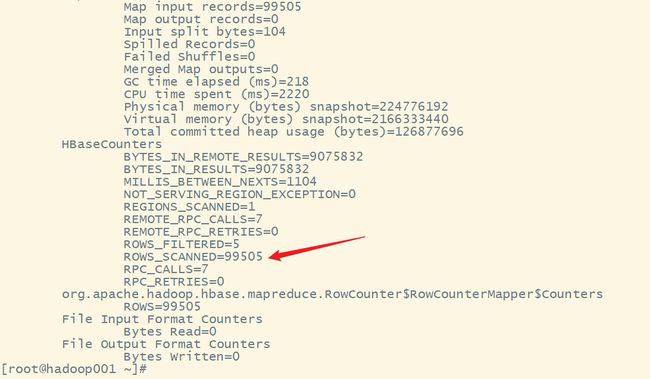
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'WATER_BILL'
十二、案例七:查询2020年6月份所有的用户的用水量
1.需求分析
在HBase中使用scan+filter实现数据的过滤查询。2020年6月份其实就是从2020年6月1号到2020年6月30号的所有的超标数据中的用水量
实现步骤:
- 获取表
- 构建scan请求对象
- 构建两个过滤器
- a) 构建两个日期范围过滤器(注意此处请使用RECORD_DATE——抄表日期比较
- b) 构建过滤器列表
- 执行scan扫描请求
- 迭代打印result
- 迭代单元格列表
- 关闭ResultScanner(这玩意把转换成一个个的类似get的操作,注意要关闭释放资源)
- 关闭表
2.编写代码
/**
* 查询数据
*
* @param tableName
* @param family
* @param column
* @param startValue
* @param endValue
* @return
* @throws IOException
*/
public static boolean queryData(String tableName, String family, String column, String startValue, String endValue) throws IOException {
// 1.使用Hbase的连接获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
// 2.创建Scan对象
Scan scan = new Scan();
// 3.创建两个过滤器
// 3.1 创建开始日期过滤器
SingleColumnValueFilter startDateFilter = new SingleColumnValueFilter(Bytes.toBytes(family), Bytes.toBytes(column),
CompareOperator.GREATER_OR_EQUAL, Bytes.toBytes(startValue));
// 3.2 创建结束日期过滤器
SingleColumnValueFilter endDateFilter = new SingleColumnValueFilter(Bytes.toBytes(family), Bytes.toBytes(column),
CompareOperator.LESS_OR_EQUAL, Bytes.toBytes(endValue));
// 3.3 创建过滤器列表
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL, startDateFilter, endDateFilter);
// 4.构建扫描器
scan.setFilter(filterList);
// 5.执行扫描操作
ResultScanner resultScanner = table.getScanner(scan);
// 6.迭代打印result
for (Result result : resultScanner) {
// 打印rowkey
System.out.println("rowkey=>" + Bytes.toString(result.getRow()));
// 迭代打印单元格列表
List<Cell> cells = result.listCells();
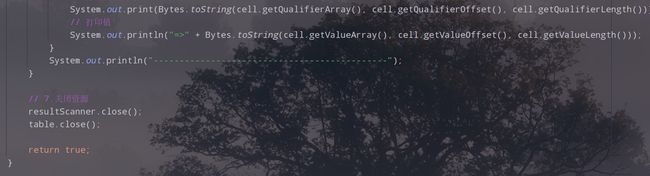
for (Cell cell : cells) {
// 打印列簇及列名
System.out.print(Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength()));
// 打印值
System.out.println("=>" + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
}
// 7.关闭资源
resultScanner.close();
table.close();
return true;
}
3.在main中调用方法

queryData("WATER_BILL", "C1", "RECORD_DATE", "2020-06-01", "2020-06-30");
4.执行,查看结果
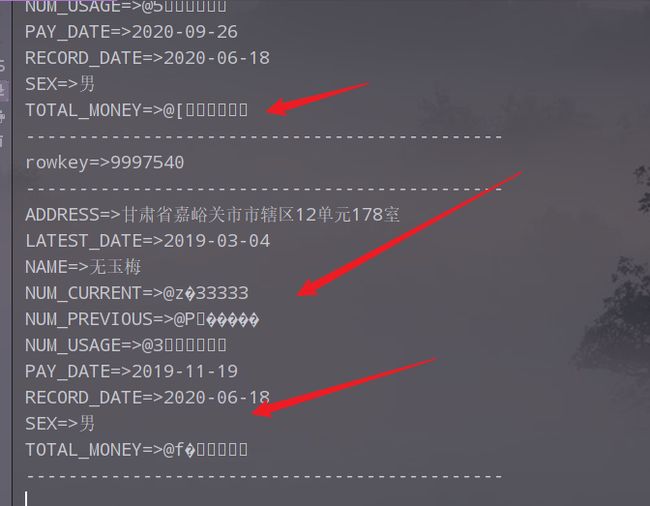
5.用量及金额乱码,需要对代码进行改进
解决数值型数据的显示乱码问题,在HBase中,如果是字符串数据,则可以正常显示,但是如果HBase存储的是int、double、float等数值型数据时,显示就会乱码,解决的方法就是判断是否是数值型数据,如果是则进行相应的转换
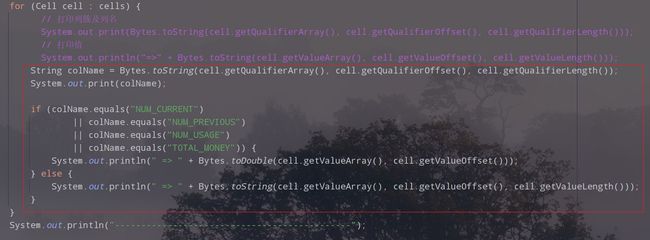
String colName = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
System.out.print(colName);
if (colName.equals("NUM_CURRENT")
|| colName.equals("NUM_PREVIOUS")
|| colName.equals("NUM_USAGE")
|| colName.equals("TOTAL_MONEY")) {
System.out.println(" => " + Bytes.toDouble(cell.getValueArray(), cell.getValueOffset()));
} else {
System.out.println(" => " + Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength()));
}
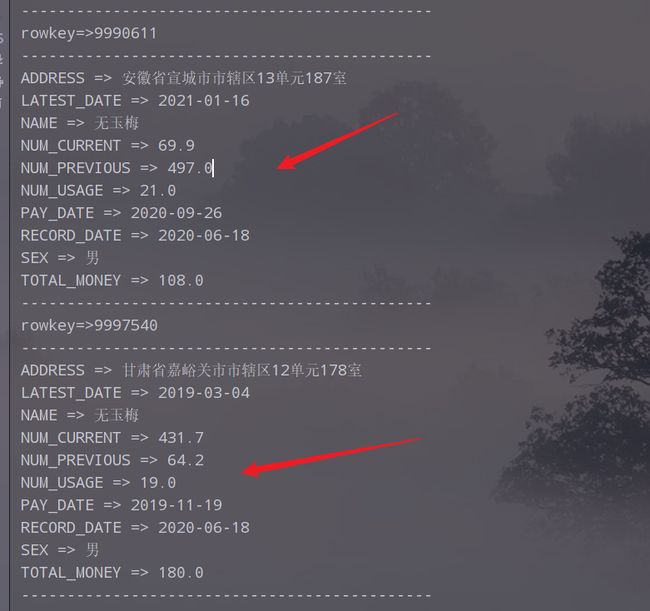
重新执行,查看结果
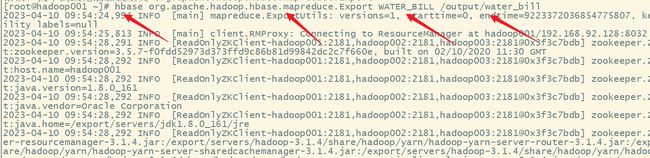
十三、案例八:导出数据
Export Job
用法:
hbase org.apache.hdoop.hbase.mapreduce.Export 表名 hdfs路径
执行命令:
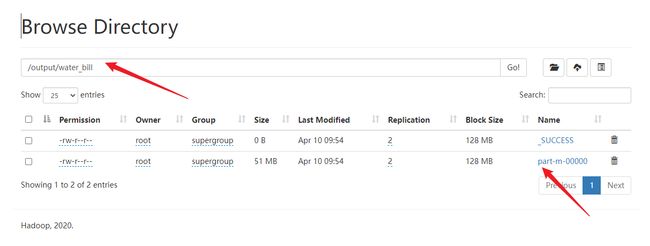
hbase org.apache.hadoop.hbase.mapreduce.Export WATER_BILL /output/water_bill
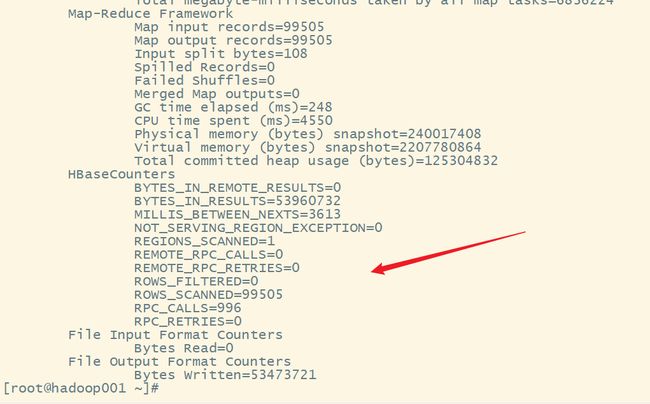
在web ui 上查看: