目标检测模型------Faster_RCNN模型
深度学习在目标检测领域按处理步骤分为两种,第一种称为two_stage,以Faster-RCNN为代表,第二种称为one_stage,以YOLO,SSD等为代表。这里先从最经典的Faster-RCNN开始,从流程图,组件结构,实现细节,训练要点方面进行介绍,如有不妥之处,欢迎指正。
Fater-RCNN流程图

如上图所示,conv_layers是指特征特征提取层,feature_maps是经过conv_layers获取到的图像特征,注意从feature_maps就开始要分成两支了。第一支走向RPN(Region Proposal Network),第二支走向Classifier分类器(当然这里也有位置回归)。第一支在RPN中会进行一次分类回归,分类是指前景背景分类,回归是指对边框位置进行回归,RPN中返回符合一定条件的边框。将RPN中返回的边框映射在第二支的特征图上,利用ROIPooling获取每个边框的特征图,最后再classifier中进行分类回归,这里的分类是指真正的目标类别,回归是指目标对应的位置。
Fater-RCNN组件结构
conv_layers特征提取
特征提取就是目前的主流神经网络结构,这里以VGG16为例,输入大小为(N, C, H, W)N为输入批次,这里默认为1,C为输入通道,H为输入图片的高,W为输入图片的宽,输出为(N, 512, H/16, W/16),注意这里是去掉了全连接层。
anchor先验框

anchor是指先验框,顾名思义:预先设定的矩形框。原文中预先设定了9个anchor,分别是三个面积尺寸(128*128,256*256, 512*512),三种不同的长宽比例(1:1,1:2,2:1),这样就会产生9中不同尺寸的anchor,这些anchor的中心点都在同一点,也就是下文中将说的特征点的位置。
bounding box regression原理

一般用(x, y, w, h) 来表示一个矩形框,其中(x, y)为矩形的中心点坐标,(w, h) 为矩形的宽高。如上图所以, G G G, G ′ G^{'} G′, A A A分别代表真实框,回归框,原始框。 G G G用 ( G x , G y , G w , G h ) (G_x,G_y,G_w,G_h) (Gx,Gy,Gw,Gh)表示, G ′ G^{'} G′用 ( G x ′ , G y ′ , G w ′ , G h ′ ) (G_x^{'},G_y^{'},G_w^{'},G_h^{'}) (Gx′,Gy′,Gw′,Gh′)表示, A A A用 ( A x , A y , A w , A h ) (A_x,A_y,A_w,A_h) (Ax,Ay,Aw,Ah)表示。这里我们需要找到一种变换,使得 G ≈ G ′ G \approx G^{'} G≈G′,变换方法如下:
1.先做平移变换
G x ′ = A w ⋅ d x ( A ) + A x G y ′ = A w ⋅ d y ( A ) + A y \begin{aligned} &G_x^{'} = A_w \cdot d_x(A) + A_x \\ &G_y^{'} = A_w \cdot d_y(A) + A_y \\ \end{aligned} Gx′=Aw⋅dx(A)+AxGy′=Aw⋅dy(A)+Ay
2.再做缩放变换
G w ′ = A w ⋅ exp ( d w ( A ) ) G h ′ = A h ⋅ exp ( d h ( A ) ) \begin{aligned} &G_w^{'} = A_w \cdot \exp(d_w(A)) \\ &G_h^{'} = A_h \cdot \exp(d_h(A)) \\ \end{aligned} Gw′=Aw⋅exp(dw(A))Gh′=Ah⋅exp(dh(A))
以上四个公式中, ( d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ) (d_x(A), d_y(A), d_w(A), d_h(A)) (dx(A),dy(A),dw(A),dh(A))就是我们需要通过神经网络学习到的值。当 A A A与 G G G相差较小时,可以认为这种变换时一种线性变换,那么可以用线性回归建模对窗口进行微调。
d x ( A ) = w x T ⋅ ϕ ( A ) d y ( A ) = w y T ⋅ ϕ ( A ) d w ( A ) = w w T ⋅ ϕ ( A ) d h ( A ) = w h T ⋅ ϕ ( A ) \begin{aligned} &d_x(A) = w_x^T \cdot \phi(A) \\ &d_y(A) = w_y^T \cdot \phi(A) \\ &d_w(A) = w_w^T \cdot \phi(A) \\ &d_h(A) = w_h^T \cdot \phi(A) \\ \end{aligned} dx(A)=wxT⋅ϕ(A)dy(A)=wyT⋅ϕ(A)dw(A)=wwT⋅ϕ(A)dh(A)=whT⋅ϕ(A)
简写为: d ∗ ( A ) = W ∗ T ⋅ ϕ ( A ) d_*(A) = W_*^T \cdot \phi(A) d∗(A)=W∗T⋅ϕ(A)
( d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ) (d_x(A), d_y(A), d_w(A), d_h(A)) (dx(A),dy(A),dw(A),dh(A))作为预测值,与目标值 ( t x ( A ) , t y ( A ) , t w ( A ) , t h ( A ) ) (t_x(A), t_y(A), t_w(A), t_h(A)) (tx(A),ty(A),tw(A),th(A))( A A A与 G G G之间的变换量)的差距越小,微调的效果就越好,所以设计损失函数为:
L o s s = ∑ i N ( t ∗ i − w ∗ T ⋅ ϕ ( A i ) ) 2 Loss = \sum_i^N(t_*^i - w_*^T \cdot \phi (A^i))^2 Loss=i∑N(t∗i−w∗T⋅ϕ(Ai))2
( t x ( A ) , t y ( A ) , t w ( A ) , t h ( A ) ) (t_x(A), t_y(A), t_w(A), t_h(A)) (tx(A),ty(A),tw(A),th(A))的计算方法如下:
t x = ( x − x a ) / w a t y = ( y − y a ) / h a t w = log ( w / w a ) t h = log ( h / h a ) \begin{aligned} & t_x = (x - x_a) / w_a \\ & t_y = (y - y_a) / h_a \\ & t_w = \log(w / w_a) \\ & t_h = \log(h / h_a) \\ \end{aligned} tx=(x−xa)/waty=(y−ya)/hatw=log(w/wa)th=log(h/ha)
RPN

如图上图,将VGG16得到的feature_maps利用一个(256, 3, 3)的卷积核作为中间层,然后分别利用cls_layer、reg_layer的卷积核得到前景背景分类特征cls_features、边框位置特征_reg_features。经过cls_layer得到的特征维度为(N,2k, H/16, W/16),经过reg_layer得到的特征维度为(N,4k, H/16, W/16),这里的k是指每个特征点对应的先验框anchors的数量,原文中k=9。
RPN的训练阶段步骤如下:
- 构造anchors。由于每个特征点对应k个anchor,所以这里需要将reg_layer中每个特征点对应的anchors全部构建出来,这样就会得到 k * (H/16) * (W/16) 个。
- 挑选正负样本。首先需要计算anchors与gt_boxes的ious,计算ious时,首先选出每一个anchor与对应gt_boxes的最大iou,如果iou大于pos_thresh的anchor就标记为正样本,如果iou小于neg_thresh的anchor就标记为负样本,其它的标记为不关心样本。然后选出每个gt_box对应iou最大的anchor,将这些样本标记为正样本。由于正负样本的不平衡,大部分都是负样本,所以这里需要控制正负样本的比例。这里限定正样本128个,负样本128个,这个比例可以自行调整。为了达到这个目的,我们从正负样本中各随机选出128个(如果样本数不到128,则按真是数量)作为正负样本,剩下的都标记为不关心样本。
- 构造target。构建前景背景分类标签labels,将 2 中的所有anchors,正样本标记为1,负样本标记为0,不关心样本标记为-1。构建位置回归标签bbox_target,将 2 中所有anchors与对应的最大iou的gt_boxes求解 ( t x ( A ) , t y ( A ) , t w ( A ) , t h ( A ) ) (t_x(A), t_y(A), t_w(A), t_h(A)) (tx(A),ty(A),tw(A),th(A))。
- 根据 3 中的labels,选出正负样本对应的cls_layer,reg_layer的输出,然后利用交叉熵作为前景背景分类的损失函数,均方差作为位置回归的损失函数。
RPN的中的输出是region_proposals,region_proposals的产生方法如下:
- 利用reg_layer的输出,构造出anchors;
- 利用边框回归原理求出,求出proposals(计算 ( G x ′ , G y ′ , G w ′ , G h ′ ) (G_x^{'},G_y^{'},G_w^{'},G_h^{'}) (Gx′,Gy′,Gw′,Gh′)的值),这一步顺便可以获取每个proposal的划分类别,类别就是每个proposal对那个的gt_box的类别;
- 根据cls_layer的输出过滤掉score小于0.5的,,然后过滤掉尺寸过小的边框,过滤掉超过边界的边框等;
- 最后利用NMS(Non Maximum Suppression 非极大值抑制)选出符合条件的proposals,这就是我们最终的region_proposals了。
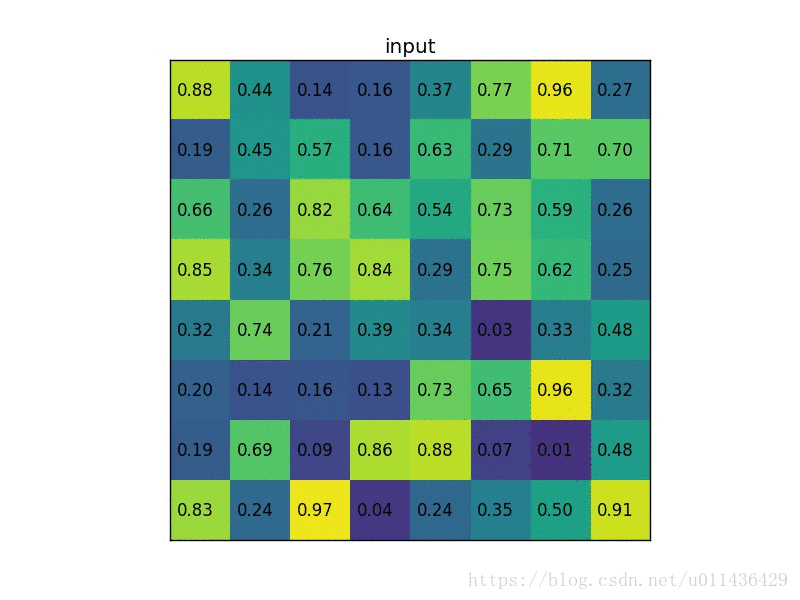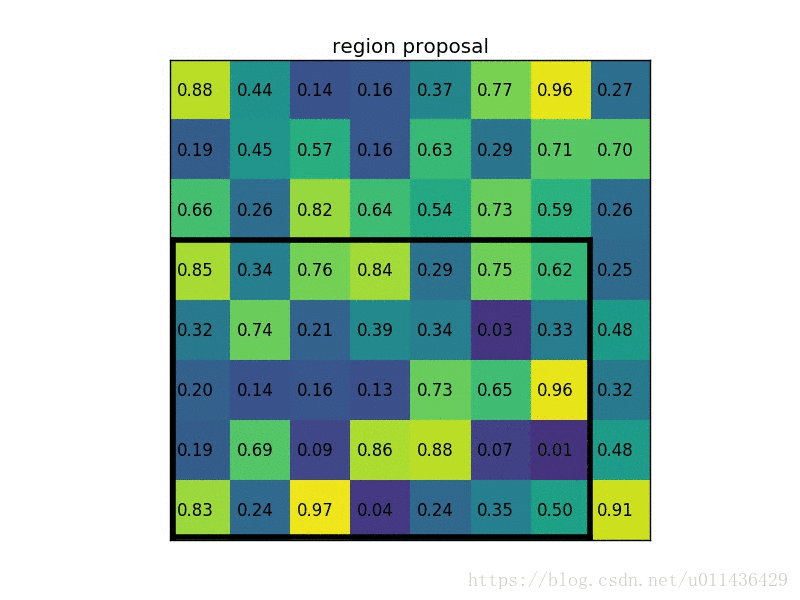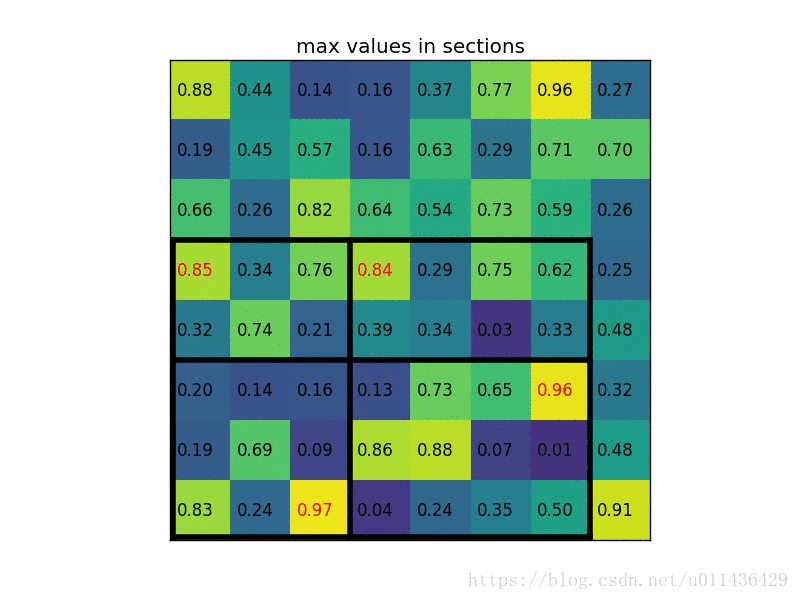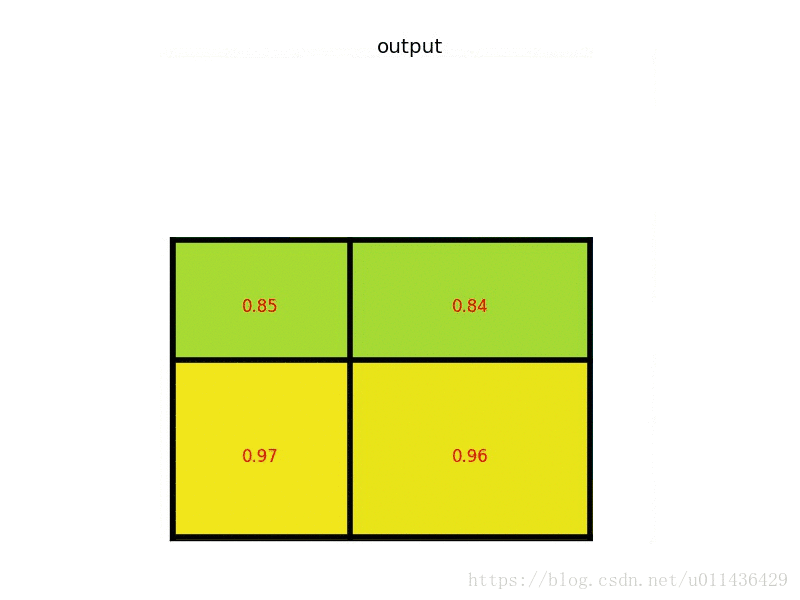
ROI Pooling
ROI Pooling的主要目的是方便训练。由于VGG16的输出是 N * 512 * 7 * 7,为了利用VGG16的全连接层(本人认为还有一个原因:由于不同的region_proposals的尺寸不同,为了同一批次训练,必须统一尺寸),所有就出现了ROI Pooling。ROI Pooling的原理如下:
- 将ROI映射到feature map对应位置;
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
- 对每个sections进行max pooling(average pooling)操作;
举例说明如下:
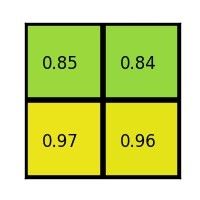
- 假设feature_map的大小为8 * 8

- 某一个proposal映射在feature_map上的坐标为:左上角(0, 3)、右下角(7,8)

- 将proposal分成 2 * 2 的尺寸
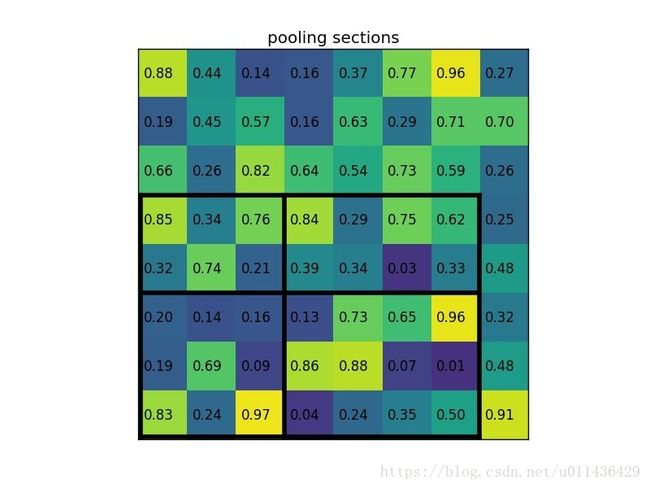
4.将格栅中的特征按照max_pooling(或者average_pooling)作为对应位置上的特征
5.整个过程的动态图如下
cls & reg
这是two-stage中的第二个阶段。将ROI Pooling的结果进行整合,假设region proposal的数量为 N ′ N^{'} N′,由于最开始的输入batch_size=1,所以我们将所有的proposal组成一个batch作为输入,此时输入的尺寸变为:( N ′ N^{'} N′,512,7,7)。
接着我们就可以进行分类,位置回归操作了。这里的操作主要是利用了VGG16的全连接层,当然也可以自定义结构。
训练阶段,分类利用交叉熵损失函数,回归利用均方误差函数。当然由于正负样本的不均衡,所以不同误差权重不同。
测试阶段,分类就不多说了,回归得到的是 ( d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) ) (d_x(A), d_y(A), d_w(A), d_h(A)) (dx(A),dy(A),dw(A),dh(A)),再根据位置回归变换就可以得到目标区域。