使用RNN encoder-decoder学习短语表示用于机器翻译
使用单层RNN实现机器翻译,论文地址。
2.1 Introduction
一个通用的seq2seq模型是:
上一个项目使用的是两层LSTM组成的seq2seq模型:
这个模型的缺点是,我们的解码器隐藏状态信息太多,解码的同时,隐藏状态会包含整个源序列的信息。
除此之外,本次还将使用GRU来代替LSTM。
2.2 准备数据
这部分的过程上次大致相同。
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
设置随机种子
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
加载spacy的德语和英语模型
spacy_de = spacy.load("en_core_web_sm")
spacy_en = spacy.load("de_core_news_sm")
之前我们颠倒了德语句子,这次不需要。
def tokenize_de(text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
建立field
SRC = Field(tokenize=tokenize_de,
init_token='',
eos_token='',
lower=True)
TRG = Field(tokenize = tokenize_en,
init_token='',
eos_token='',
lower=True)
加载数据
train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),
fields = (SRC, TRG))
建立词汇表
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
选择设备,建立迭代器
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
2.3建立seq2seq模型
2.3.1Encoder
encoder和上个项目的encoder类似,将多层LSTM换成了单层GRU。另外GRU只需要并返回隐藏状态,没有LSTM的单元状态。
从上面的公式看起来,RNN和GRU似乎是一样。但是在GRU的内部,有许多门控机制,它们控制信息流入和流出隐藏状态(类似于LSTM)。具体信息可以查看这篇文章
其他部分和上一个模型类似,循环计算序列的隐藏状态,返回上下文向量。
这与通用seq2seq模型的Encoder相同,不同发生在GRU内(绿色)
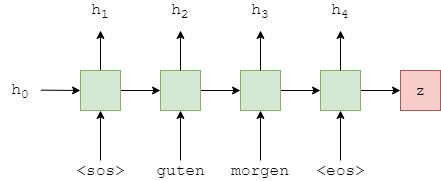
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, dropout):
super().__init__()
self.hid_dim = hid_dim
self.embedding = nn.Embedding(input_dim, emb_dim) #no dropout as only one layer!
self.rnn = nn.GRU(emb_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, hidden = self.rnn(embedded) #no cell state!
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden
2.3.2Decoder
Decoder则和上次的有很大不同,模型减轻了信息压缩。
GRU需要获取目标token,上一个时间步隐藏状态,和上下文向量。
z没有下标,说明我们用的是encoder同一层的上下文状态。而预测是用一个全连接层处理当前token,和上下文向量。
初始隐藏状态仍然是上下文向量,因此当我们生成第一个token时,实际上是输入了两个一样的上下文向量到GRU。
传入GRU的是和的串联,所以输入维度是emd_dim+hid_dim。
全连接层输入的是的的串联,所以输入维度是emd_dim+hid_dim+hid_dim。
forward函数需要接受一个context参数。在前向传播时,我们将连接为emb_con,再输入到GRU。我们将cancat在一起输出,再经过全连接层输出预测
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, dropout):
super().__init__()
self.hid_dim = hid_dim
self.output_dim = output_dim
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hid_dim, hid_dim)
self.fc_out = nn.Linear(emb_dim + hid_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, context):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#context = [n layers * n directions, batch size, hid dim]
#n layers and n directions in the decoder will both always be 1, therefore:
#hidden = [1, batch size, hid dim]
#context = [1, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
emb_con = torch.cat((embedded, context), dim = 2)
#emb_con = [1, batch size, emb dim + hid dim]
output, hidden = self.rnn(emb_con, hidden)
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#seq len, n layers and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [1, batch size, hid dim]
output = torch.cat((embedded.squeeze(0), hidden.squeeze(0), context.squeeze(0)),
dim = 1)
#output = [batch size, emb dim + hid dim * 2]
prediction = self.fc_out(output)
#prediction = [batch size, output dim]
return prediction, hidden
2.3.3seq2seq
在每个时间步:
output被创建来储存所有的预测
源句子,被传入encoder来获取上下文向量
初始decoder隐藏状态被设置为上下文向量,即
第一个输入使用一个batch的
来代替 -
在decoder 的每个时间步:
将输入token,上一个时间步隐藏项链和上下文向量z传入decoder
得到一个预测和新的隐藏状态
适当使用teacher forcing
2.4训练
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, DEC_DROPOUT)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(enc, dec, device).to(device)
def init_weights(m):
for name, param in m.named_parameters():
nn.init.normal_(param.data, mean=0, std=0.01)
model.apply(init_weights)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
optimizer = optim.Adam(model.parameters())
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
训练结果:
Epoch: 01 | Time: 0m 23s
Train Loss: 5.058 | Train PPL: 157.219
Val. Loss: 5.305 | Val. PPL: 201.323
Epoch: 02 | Time: 0m 23s
Train Loss: 4.399 | Train PPL: 81.338
Val. Loss: 5.026 | Val. PPL: 152.384
Epoch: 03 | Time: 0m 23s
Train Loss: 4.054 | Train PPL: 57.643
Val. Loss: 4.671 | Val. PPL: 106.856
Epoch: 04 | Time: 0m 23s
Train Loss: 3.672 | Train PPL: 39.333
Val. Loss: 4.161 | Val. PPL: 64.160
Epoch: 05 | Time: 0m 23s
Train Loss: 3.308 | Train PPL: 27.339
Val. Loss: 3.913 | Val. PPL: 50.047
Epoch: 06 | Time: 0m 23s
Train Loss: 2.974 | Train PPL: 19.573
Val. Loss: 3.781 | Val. PPL: 43.870
Epoch: 07 | Time: 0m 23s
Train Loss: 2.728 | Train PPL: 15.305
Val. Loss: 3.621 | Val. PPL: 37.372
Epoch: 08 | Time: 0m 23s
Train Loss: 2.467 | Train PPL: 11.791
Val. Loss: 3.553 | Val. PPL: 34.933
Epoch: 09 | Time: 0m 23s
Train Loss: 2.247 | Train PPL: 9.462
Val. Loss: 3.559 | Val. PPL: 35.121
Epoch: 10 | Time: 0m 23s
Train Loss: 2.071 | Train PPL: 7.932
Val. Loss: 3.499 | Val. PPL: 33.075