反汇编基础学习(二)
参考教材:《IDA Pro权威指南》(第2版)
逆向与汇编工具
一些用于逆向工程的老工具,IDA已经将这些工具的功能整合到它的用户几面中。
分类工具
分辨一个文件时 “文件扩展名并无实际意义”
file
file命令是一个标准的实用工具,大多数*NIX分割的操作风格的操作系统和windows下的Cygwin或MinGw工具都带有这个实用工具。Linux file命令
Cygwin是运行于Windows平台的POSIX“子系统”,提供Windows下的类Unix环境,并提供将部分 Linux 应用“移植”到Windows平台的开发环境的一套软件。Cygwin是什么
MinGw 是用于进行 Windows 应用开发的 GNU 工具链(开发环境),它的编译产物一般是原生 Windows 应用,虽然它本身不一定非要运行在 Windows 系统下(MinGW 工具链也存在于 Linux、BSD 甚至 Cygwin 下)。MinGW 是什么?
file试图通过检查文件中的某些特定字段来确认文件类型。有时,file能过识别常见的字符串,如#bin/sh(shell脚本文件)或 < html >(HTML文件)。但识别包含非ASCII内容的文件要困难的多,在这种情况下,file会设法判断该文件的结构是否符合某种文件格式,它会搜索某些文件类型所特有的标签值(通常为幻数Magic Number)。文件格式的幻数



在某些情况下,file还能辨别某一指定文件中的细微变化。
如果某个文件碰巧使用了某种文件的标记,file工具可能错误的识别,例如将任意文件前四个字节修该为CA FE BA BE,file会将这个文件错误的识别为已编译的Java类数据库。
在逆向工程过程中,绝不要完全相信任何一个工具所提供的结果,除非该结果得到其他几款工具和动手分析的确认,这是一个良好的习惯。
PE Tools
PETools是一组用于分析Windows系统中正在进行的进程和可执行文件的工具。PETools的主要界面如下图所示

在进程列表中,用户可以将一个进程的内存映像转储存到某个文件中,也可以使用PESinffer实用工具确定可执行文件由何种编译器构建,或者该文件是否经过某种已知的模糊处理。Tools菜单提供了分析磁盘文件的类似选项。另外,用户还可以使用内嵌的PEEditor实用工具查看PE文件头字段,使用该工具还可以方便的修改任何文件头的值。通常,如果想要从一个文件的模糊版本重建一个有效的PE,就需要修改PE文件头。
二进制文件模糊技术
模糊(abfuscation)指任何掩盖真是意图的行为。应用于可执行文件时,模糊是指任何掩盖程序真实的行为。出于各种原因,程序员可能会采用模糊技术,如保护专有算法及掩盖恶意意图。几乎所有恶意软件都采用了某种模糊技术,以防止人们对其进行分析。有大量模糊技术供程序员使用。
PEiD
PEiD是一款Windows工具,它主要用于识别构建某一特定Windows PE二进制文件多使用的编译器,并确定任何用于模糊WindowsPE二进制文件的工具。

PEiD许多其他功能与PE Tools相同。
摘要工具
由于我们的目标是对二进制程序文件进行逆向工程,因此,在对文件进行初步分类后,需要用更高级的工具来提取详尽的信息。
nm
将文件编译成目标文件时。编译器必须嵌入一些全局(外部)符号的位置 信息,以便链接器在组合目标文件以创建可执行文件时,能够解析对这些符号的引用。除非被告知要去除最终的可执行文件中的符号,否则,连接器通常会将目标文件中的符号带入最终的可执行文件中。根据nm手册的描述,它的作用是“列举目标文件中的符号”。
使用nmj检查中间目标文件(扩展名为.o的文件)时,默认输出结果是在这个文件中声明的任何函数和全局变量的名称。
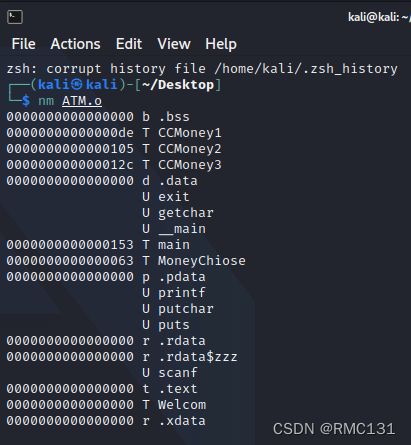
nm列出了每一个符号以及与符号有关的一些信息,字母表示所列举的符号的类型。
U:未定义符号,通常为外部符号引用。
T:在文本部分定义符号,通常为函数名称。
t:在文本部分定义的局部符号。在C程序中,这个符号通常等同于一个静态函数。
D:已初始化的数据值。
C:未初始化的数据值。
大写字母表示全局符号,小写字母表示局部符号。linux nm命令
如果使用nm列举可执行文件中的符号,将会有更多的信息显示出来。
ldd
创建可执行文件时,必须解析该去文件引用的任何库函数地址。链接器通过静态链接(static linking)和动态链接(dynamic linking)两种方法解析对库函数的调用。链接器的命令行参数决定具体使用哪一种方法,可能为静态链接、动态链接,或二者兼有。
如果要求使用静态链接,链接器会将应用程序的目标文件和所需的库文件组合起来,生成一个可执行文件。这样,在运行时就不需要确定库代码的位置,因为它已经包含在可执行文件中了。
静态链接的优点包括:函数调用更快一些;发布二进制文件更加容易,因为这时不需要对用户系统中库函数的可用性做出任何假设。
其缺点包括:生成的可执行文件更大;如果库组件发生改变,对程序进行升级会更加困难,因为一旦库发生变化,程序就必须重新链接。从逆向工程的角度看,静态链接使问题更加复杂。
使用动态链接时,链接器不需要复制它需要的任何库。链接器需将对所需库(通常为.so或.dll文件)的引用插人到最终的可执行文件中。因此,这时生成的可执行文件也更小一些。而且,使用动态链接时升级库代码也变得简单多了,因为只需要维护一个库(被许多二进制文件引用),如果需要升级库代码,用新版本的库替换过时的库,就可以立即更新每一个引用该库的二进制文件。
使用动态链接的一个缺点在于,它需要更加复杂的加载过程。因为这时必须定位所有所需的库,并将其加载到内存中,而不是加载-一个包含全部库代码的静态链接文件。动态链接的另一个缺点是,供应商不仅需要发布他们自己的可执行文件,而且必须发布该文件所需的所有库文件。如果-一个系统无法提供程序所需的全部库文件,在这个系统上运行该程序将会导致错误。
ldd(list dynamic dependencise)是一个简单的实用工具,可用来列举任何可执行文件所需的动态库。linux命令ldd详解(用一个简单的例子讲解ldd用法)
objdump
objdump具有多样的功能,能够显示与目标文件有关的信息,提供了大量命令选项(超过30个)。
节头部,程序文件每节的摘要信息。
专用头部,程序内存分布信息,还有运行时加载器所需的信息,包括ldd等工具生成的库列表。
调试信息,提取出程序文件中的任何调试信息。
符号信息,以类似nm的方式转储存符号信息。
反汇编代码清单objdump对文件中标记为代码的部分执行线性扫描反汇编(详见反汇编基础学习(一))。反汇编x86代码时,objdump可以生成AT&T或Intel语法,并可以将反汇编代码保存再文本文件中。这样的文本文件叫做反汇编死代码清单(dead listing),尽管这些文件可用于实施逆向工程,但它们很难有效导航,也无法以一致且无错的方式被修改。
objdump是 GNU binutils工具套件的一部分,用户可以在Linux、FreeBSD 和Windows (通过Cygwin)系统中找到这个工具。objdump 依靠二进制文件描述符库libbfd (二进制工具的一个组件)来访问目标文件,因此,它能够解析libbfd支持的文件格式(ELF、PE等)。另外,一个名为readelf的实用工具也可用于解析ELF文件。readelf 的大多数功能与objdump相同,它们之间的主要区别在于readelf并不依赖libbfd。
otool
otool可用于OS X Mach-O二进制文件信息有关的信息,因此,可简单将其描述为OS X系统下的类似于objdump的实用工具。逆向工具 otool 介绍
dumpbin
dumpbin是微软Visual Studio工具套件中的一个命令实用工具。与otool和objdump一样,bumpbin可以显示大量与Windows PE文件有关的信息。
VS中dumpbin.exe工具的使用
c++filt
由于每一个重载的函数都使用与原函数相同的名称,因此,支持函数重载的语言必须拥有一种机制,以区分同一个函数的许多重载版本。
通常,一个目标文件中不能有两个名称相同的函数。为支持重载,编译器将描述函数参数的类型的信息合同并到函数的原始名称中,从而为重载函数生成唯一的函数名,这个过程叫做改编(name mangling)。
c++file可以理解编译器的名称改编方案,它将每个输入的名称看成是改编后的名称(mangled name),病设法确定用于生成该名称的编译器。如果这个名称是一个合法的改编名称,c++file就输出改编之前的原始名称;如果c++file无法识别一个改编名称,那它就按原样输出该名称。改编名称可能包含其他与函数有关的信息,在逆向工程过程中,这些信息可能非常重要。在更复杂的情况下,这些额外信息中可能还包含与类名称或函数调用约定有关的信息。
深度检测工具
专用于从任何格式的文件中提取出特定信息的工具。
strings
strings 命令.
字符串:由可打印字符组成的连续字符序列。
strings实用工具专门用于提取文件中的字符串内容,但不能根据strings的输出来判断程序的功能,二进制文件中包含某个字符串,并不表示该文件会以某种方式使用这个字符串。
使用string的一些注意事项:
使用stringa处理可执行文件时,默认情况下,strings只扫描文件中可加载的、经初始化的部分。加 -a 可扫描整个文件。
strings不会指出字符串在文件中的位置,-t 可以显示所发现的每一个字符串在文件中的偏移量信息。
许多文件使用了其他字符集,-e 可以搜索更广泛的字符。
反汇编器
为了处理一些并不采用常用文件格式的二进制文件,需要一些能够从用户指定的偏移量开始反汇编过程的工具。
有两个用于x86指令集的流式反汇编起(stream disassemble):ndisasm和diStorm。
ndisasm常用方法
反汇编引擎diStorm3
diStorm3是Kali Linux自带的一款轻量级、容易使用的反汇编引擎。它可以反汇编生成16位、32位和64位指令。它支持的指令集包括FPU、MMX、SSE、SSE2、SSE3、SSSE3、SSE4、3DNow@、x86-64、VMX、AMDs、SVM等。虽然diStorm3采用C语言编写,但可以被Python、Ruby、Java快速封装。这样,用户可以使用Python、Ruby等脚本语言编写脚本,并引入diStorm3,从而定制自己的反汇编工具。
由于流式反汇编非常灵活,因此它的用途相当广泛。例如,在网络分析数据包中可能包含shellcode的计算机网络攻击时,就可以采用流式反汇编器来反汇编数据包中包含shellcode的部分,以分析恶意负载的行为。另一种情况是分析那些不包含布局参考的ROM镜像。ROM中有些部分是数据,其他部分则为代码,可以使用流式反汇编器来反汇编镜像中的代码。
上述工具可以为了解ida的用户界面以及显示它提供的许多信息提供极大的帮助。