protobuf 入门
参考自
https://juejin.cn/post/7029961388411846664
介绍了protobuf基本概念、优缺点、与protobuf在C++上的基本使用
1. 什么是protobuf
它是一个灵活、高效、结构化的序列化数据结构,它与传统的XML、JSON等相比,它更小、更快、更简单。
ProtoBuf是由Google开发的一种数据序列化协议(类似于XML、JSON、hessian)。ProtoBuf能够将数据进行序列化,并广泛应用在数据存储、通信协议等方面。protobuf压缩和传输效率高,语法简单,表达力强。
我们说的 protobuf 通常包括下面三点:
- 一种二进制数据交换格式。可以将 C++ 中定义的存储类的内容 与 二进制序列串 相互转换,主要用于数据传输或保存
- 定义了一种源文件,扩展名为
.proto(类比.cpp文件),使用这种源文件,可以定义存储类的内容 - protobuf有自己的编译器
protoc,可以将.proto编译成.cc文件,使之成为一个可以在 C++ 工程中直接使用的类
序列化:将数据结构或对象转换成二进制串的过程。反序列化:将在序列化过程中所产生的二进制串转换成数据结构或对象的过程。
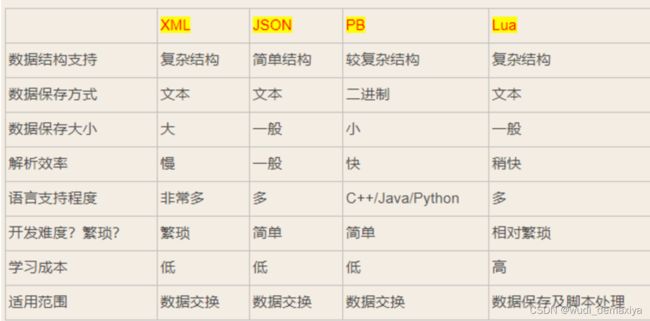
1.1 protobuf优缺点
protobuf / XML / JSON这三种序列化方式优缺点
优点:
-
json
较XML格式更加小巧,传输效率较xml提高了很多,可读性还不错。
-
xml
可读性强,解析方便。
-
protobuf
就是传输效率快(据说在数据量大的时候,传输效率比xml和json快10-20倍),序列化后体积相比Json和XML很小,支持跨平台多语言,消息格式升级和兼容性还不错,序列化反序列化速度很快。
并且protobuf有代码生成机制。序列化反序列化直接对应程序中的数据类,不需要解析后在进行映射(XML/JSON都是这种方式)
比如你你写个一下类似结构体的内容
message testA { int32 m_testA = 1; }像写一个这样的结构,protobuf可以自动生成它的.h 文件和点.cpp文件。protobuf将对结构体testA的操作封装成一个类。
protobuf中定义一个消息类型是通过关键字message字段指定的,这个关键字类似于C++/Java中的class关键字。使用protobuf编译器将proto编译成C++代码之后,每个message都会生成一个名字与之对应的C++类,该类公开继承自google::protobuf::Message。性能方面
- 序列化后,数据大小可缩小3倍
- 序列化速度快
- 传输速度快
使用方面
- 使用简单:
proto编译器自动进行序列化和反序列化 - 维护成本低:多平台只需要维护一套对象协议文件,即
.proto文件 - 可扩展性好:不必破坏旧的数据格式,就能对数据结构进行更新
- 加密性好:http传输内容抓包只能抓到字节数据
使用范围
- 跨平台、跨语言、可扩展性强
缺点:
-
json缺点就是传输效率也不是特别高(比xml快,但比protobuf要慢很多)。
-
xml缺点就是效率不高,资源消耗过大。
-
protobuf缺点就是使用不太方便。
为了提高性能,protobuf采用了二进制格式进行编码。这直接导致了可读性差。但是同时也很安全
在一个需要大量的数据传输的场景中,如果数据量很大,那么选择protobuf可以明显的减少数据量,减少网络IO,从而减少网络传输所消耗的时间。考虑到作为一个主打社交的产品,消息数据量会非常大,同时为了节约流量,所以采用protobuf是一个不错的选择。
2. 定义.proto文件
2.1 message 介绍
message:protobuf中定义一个消息类型是通过关键字message字段指定的,这个关键字类似于C++/Java中的class关键字。使用protobuf编译器将proto编译成C++代码之后,每个message都会生成一个名字与之对应的C++类,该类公开继承自google::protobuf::Message。
2.2 message 消息定义
创建tutorial.person.proto文件,文件内容如下:
// FileName: tutorial.person.proto
// 通常文件名建议命名格式为 包名.消息名.proto
// 表示正在使用proto3
syntax = "proto3";
//包声明,tutorial 也可以声明为二级类型。在C++中则是命名空间tutorial::
//例如a.b,表示a类别下b子类别。在C++中则是命名空间a::b::
package tutorial;
//编译器将生成一个名为person的类
//类的字段信息包括姓名name,编号id,邮箱email,以及电话号码phones
message Person
{
string name = 1;
int32 id =2;
string email = 3;
enum PhoneType { //电话类型枚举值
MOBILE = 0; //手机号
HOME = 1; //家庭联系电话
WORK = 2; //工作联系电话
}
//电话号码PhoneNumber消息体
//组成包括号码number、电话类型type
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
//重复字段,保存多个PhoneNumber
repeated PhoneNumber phones = 4;
}
// 通讯录消息体,包括一个重复字段,保存多个Person
message AddressBook {
repeated Person people = 1;
}
2.3 字段解释
2.3.1 包声明
proto 文件以package声明开头,这有助于防止不同项目之间命名冲突。在C++中,以package声明的文件内容生成的类将放在与包名匹配的namespace中,上面的.proto文件中所有的声明都属于tutorial,即在命名空间tutorial::(如果是package a.b,则对应命名空间a::b:: )。
2.3.2 字段规则
repeated: 消息体中重复字段,可以保存多个相同类型的字段值。其中,proto3默认使用packed方式存储,这样编码方式比较节省内存。
2.3.3 标识号
在消息定义中,**每个字段都有唯一的一个数字标识符。这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。**注:[1,15]之内的标识号在编码的时候会占用一个字节。[16,2047]之内的标识号则占用2个字节。所以应该为那些频繁出现的消息元素保留 [1,15]之内的标识号。切记:要为将来有可能添加的、频繁出现的标识号预留一些标识号。
最小的标识号可以从1开始,最大到2^29 - 1。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。
2.3.4 数据定义
许多标准的简单数据类型都可以用作message字段类型,包括bool,int32,float,double和string。还可以使用其他message类型作为字段类型在消息体中添加更多结构。比如上面的例子中,AddressBook消息内包含Person类型的字段;Person内还包含了PhoneNumber类型的字段
protobuf中简单数据类型说明
| .proto Type | Notes | C++ Type | Java Type | Python Type[2] | Go Type | Ruby Type | C# Type | PHP Type |
|---|---|---|---|---|---|---|---|---|
| double | double | double | float | float64 | Float | double | float | |
| float | float | float | float | float32 | Float | float | float | |
| int32 | 使用变长编码,对于负值的效率很低,如果你的域有可能有负值,请使用sint64替代 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer |
| uint32 | 使用变长编码 | uint32 | int | int/long | uint32 | Fixnum 或者 Bignum(根据需要) | uint | integer |
| uint64 | 使用变长编码 | uint64 | long | int/long | uint64 | Bignum | ulong | integer/string |
| sint32 | 使用变长编码,这些编码在负值时比int32高效的多 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer |
| sint64 | 使用变长编码,有符号的整型值。编码时比通常的int64高效。 | int64 | long | int/long | int64 | Bignum | long | integer/string |
| fixed32 | 总是4个字节,如果数值总是比总是比228大的话,这个类型会比uint32高效。 | uint32 | int | int | uint32 | Fixnum 或者 Bignum(根据需要) | uint | integer |
| fixed64 | 总是8个字节,如果数值总是比总是比256大的话,这个类型会比uint64高效。 | uint64 | long | int/long | uint64 | Bignum | ulong | integer/string |
| sfixed32 | 总是4个字节 | int32 | int | int | int32 | Fixnum 或者 Bignum(根据需要) | int | integer |
| sfixed64 | 总是8个字节 | int64 | long | int/long | int64 | Bignum | long | integer/string |
| bool | bool | boolean | bool | bool | TrueClass/FalseClass | bool | boolean | |
| string | 一个字符串必须是UTF-8编码或者7-bit ASCII编码的文本。 | string | String | str/unicode | string | String (UTF-8) | string | string |
| bytes | 可能包含任意顺序的字节数据。 | string | ByteString | str | []byte | String (ASCII-8BIT) | ByteString | string |
2.3.5 函数方法
protocol buffer 编译器为.proto文件中定义的每个message定义一个class,message的字段即为class中的成员变量
//继承自google::protobuf::Message
class Person : public ::google::protobuf::Message{
...
};
protocol buffer 编译器为.proto文件中定义的每个枚举类型也有相应定义
//message Person中的PhoneType枚举
enum Person_PhoneType {
Person_PhoneType_MOBILE = 0,
Person_PhoneType_HOME = 1,
Person_PhoneType_WORK = 2
};
protocol buffer 编译器为.proto文件中定义的消息的每个字段生成一套存取器方法:
-
对于
message Person中的int32 id = 2,编译器将生成下列方法:::google::protobuf::int32 id() const;: 返回字段id的值void set_id(::google::protobuf::int32 value);: 设置字段id的值void clear_id():清除字段的值。
-
对于
message Person中的string name = 1;,编译器将生成下列方法(只显示部分):-
void clear_name();清除字段的值 -
const ::std::string& name() const;返回字段name的值 -
void set_name(const ::std::string& value);设置字段name的值 -
void set_name(const char* value);同上 -
void set_name(const char* value, size_t size);同上 -
::std::string* mutable_name();对于原型为
const std::string &name() const的get函数而言,返回的是常量字段,不能对其值进行修改。但是在有一些情况下,对字段进行修改是必要的,所以提供了一个mutable版的get函数,通过获取字段变量的指针,从而达到改变其值的目的。若字段值存在,则直接返回该对象,若不存在则新new 一个。
-
-
对于
message AddressBook中的repeated Person people = 1;,编译器将生成下列方法(只显示部分):-
int people_size() const;返回重复字段中元素个数 -
void clear_people();清空重复字段 -
const ::tutorial::Person& people(int index) const;获取重复字段中指定索引的值 -
::tutorial::Person* mutable_people(int index);获取重复字段中指定索引处元素值的指针,从而可以改变其值。 -
::tutorial::Person* add_people();向重复字段中增加一个元素并返回其指针
-
用message关键字声明的的消息体,允许你检查、操作、读、或写该消息内容,还可以序列化生成二进制字符串,以及反序列化二进制字符串。
bool SerializeToString(string* output) const;:序列化消息并将字节存储在给定的字符串中。请注意,字节是二进制的,而不是文本;我们只使用string类作为一个方便的容器。bool ParseFromString(const string& data);: 从给定的字符串解析消息。bool SerializeToOstream(ostream* output) const;: 将消息写入给定的 C++ostream。bool ParseFromIstream(istream* input);: 从istream解析消息
每个消息类还包含许多其他方法,可让您检查或操作整个消息,包括:
bool IsInitialized() const;: 检查是否所有必填字段都已设置。string DebugString() const;:返回消息的可读字符串表示,对于调试特别有用。void CopyFrom(const Person& from);: 用给定消息的值覆盖消息。void Clear();: 将所有元素清除回空状态。
3. 编译.proto文件
通过protoc编译器根据.proto文件生成C++对应的.h和.cpp文件
protoc -I=$SRC_DIR --cpp_out=$DST_DIR xxx.proto
$SRC_DIR.proto文件所在的源目录--cpp_out生成C++代码$DST_DIR生成代码的目标目录xxx.proto:要针对哪个proto文件生成接口。如tutorial.person.proto
编译完成后,将生成2个文件 tutorial.person.pb.h和tutorial.person.pb.cc 其中pb是protobuf的缩写。
4. 测试
#include
#include
#include "tutorial.person.pb.h"
using namespace std;
int main() {
//构造一个tutorial::AddressBook消息对象
tutorial::AddressBook book;
//在重复字段people中添加一个Person元素
auto p = book.add_people();
//设置这个Person的字段值
p->set_name("gailun");
p->set_id(1);
p->set_email("[email protected]");
for(int i = 0 ; i < 3 ; ++i) {
//在Person消息的可重复字段phones中添加一个PhoneNumber元素
auto phone_p = p->add_phones();
//设置这个PhoneNumber的字段值
phone_p->set_number("123456789"+to_string(i));
phone_p->set_type(static_cast(i));
}
string str;
//序列化为二进制串并保存在string中
if(book.SerializeToString(&str)){
cout << "序列化成功!" << endl;
//打印消息的可读字符串表示
cout << book.DebugString();
}
//根据二进制字符串反序列化为消息
tutorial::AddressBook book1;
if(book1.ParseFromString(str)){
cout << "反序列化成功" << endl;
auto phone_ptr = book1.people(0);//获取可重复字段的第0个元素
cout << "name: " << phone_ptr.name() << endl;
cout << "id: " << phone_ptr.id() << endl;
cout << "email: " << phone_ptr.email() << endl;
for(int i = 0 ; i < 3 ; ++i) {
cout << "phone: " << phone_ptr.phones(i).number() << endl;;
}
}
}
运行该程序
# g++ test.cpp tutorial.person.pb.cc -lprotobuf
# ./a.out
序列化成功!
people {
name: "gailun"
id: 1
email: "[email protected]"
phones {
number: "1234567890"
}
phones {
number: "1234567891"
type: HOME
}
phones {
number: "1234567892"
type: WORK
}
}
反序列化成功
name: gailun
id: 1
email: [email protected]
phone: 1234567890
phone: 1234567891
phone: 1234567892