CMS 垃圾回收器
CMS 垃圾回收器
-
- 1. cms 回收过程分析
-
- 1.1 初始标记(initial-mark)
- 1.2 并发标记(concurrent-mark)
-
- 1.3.1 Card Table
- 1.3.2 mod-union table
- 1.3 并发预清理 (concurrent-preclean)
- 1.4 可中断预清理(concurrent-abortable-preclean)
- 1.5 重新标记(remark)
- 1.6 并发清除(concurrent-sweep)
- 1.7 并发重置(concurrent reset)
- 2. cms 日志解析
-
- ParNew
- 初始标记
- 并发标记
- 并发预清理
- 可中断预清理
- 最终标记
- 并发清除
- 并发重置
- 3. cms 注意事项
-
- 3.1 concurrent mode failure
- 3.2 promotion failure
- 4. cms 优化方向
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它是专门回收老年代,基于标记-清除算法实现的。
它主要分为六个阶段:
- 初始标记(initial-mark)
- 并发标记(concurrent-mark)
- 并发预清理(concurrent-preclean)
- 可中断预清理(concurrent-abortable-preclean)
- 重新标记(remark)
- 并发清除(concurrent-sweep)
- 并发重置(concurrent reset)
接下来我们针对每个步骤进行逐步分析,看看 CMS 回收原理是怎样的,又存在什么样的问题。
1. cms 回收过程分析
1.1 初始标记(initial-mark)
initial-mark 需要 Stop The World,初始标记仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快。这个GC Roots 仅仅是老年代的 GC Roots ,同时初始标记不用去解决跨代引用(新生代引用老年代)问题,这个问题需要留在 remark 阶段去解决。
即便 initial-mark 阶段去扫描跨代引用对象,经过 concurrent-mark 阶段后,整个新手代对老年代的跨代引用变更频繁,remark 阶段还得重新扫描跨代引用对象,所以还不如直接在 remark 阶段去做这部分工作
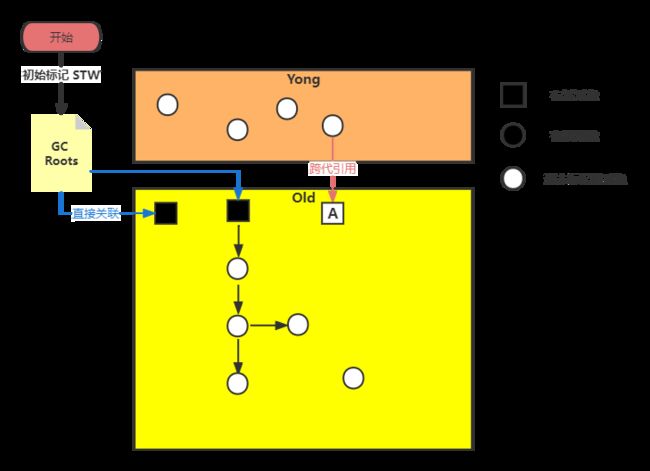
A 对象作为跨代引用对象不会在初始标记阶段进行标记,在老年代直接和 GC Roots 关联的对象引用会被压入标记栈(marking stack)。
1.2 并发标记(concurrent-mark)
concurrent-mark 阶段不需要 Stop The World,用户线程和 GC 线程可以一起执行。具体做法弹出标记栈记录的对象引用,将本对象引用指向的其他对象引用压入标记栈等待被标记,同时标记本对想引用为存活对象。同时整个过程应用线程也在不断更改引用,新创建对象等。

因为 concurrent-mark 是非 STW ,所以整个标记过程会出行很多情况,我们一一分析。
- A 对象引用:initial-mark 阶段说过,跨代引用会在 remark 阶段进行标记
- B 对象引用:B 对象是在 concurrent-sweep 阶段,触发 ygc 存活到老年代对象,或者直接分配在老年代的大对象,B 对象被
GC Roots直接关联。这部分对象会在 remark 阶段进行标记 - C 对象引用:C 对象也是在 concurrent-mark 阶段进入到老年代的对象,这部分标记和 A 对象一样,属于跨代引用,会在 remark 阶段进行标记
- F 对象引用:F 对象是在引用树被扫描过程中,发送了引用变更。在遍历标记 D 对象的时候,它还没有引用 F 对象,引用树继续往下遍历标记,当遍历到 E 对象的时候,E 断开引用 F 对象,转而 F 对象被 E 对象引用,导致 F 对象漏标。怎么解决这个问题呢?CMS 采用了增量更新(Incremental Update)方法
增量更新:
增量更新概念:当黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描后,再将这些记录过的引用关系中的黑色对象为根,重新扫描一遍。
浮动垃圾:
增量更新会造成浮动垃圾,如果 F 对象已经被标记黑色,再断开 F 对象的引用链,而不重新被其他对象引用,F 对象已经变成了垃圾对象,因为增量更新记录插入的引用,F 对象则不会被记录到,也就不会被重新扫描,F 对象在本次 GC 无法被回收
CMS 是通过 mod-union table 来实现增量更新方法,说到 mod-union table,那得先了解 card table。
1.3.1 Card Table
card table 是记忆集的一种具体实现,它主要是为了解决跨代引用问题出现的。
ygc 标记对象除了年轻代 GC ROOTS 外,还有标记老年代对年轻代的跨代引用对象,为了标记这部分对象而去全扫描老年代,这个代价是非常大,JVM 通过
card table这一数据结构来记录老年代对年轻代的跨代引用,所以 ygc 扫描不用去扫描整个老年代而是扫描card table即可。
card table是一个数组,里面每一个元素都对应着其标识的内存区域一块特定大小的内存块,这个内存块被称作“卡页”。一个卡页有一个或更多个对象,如果对象字段存在跨代指针,那么“卡页”对应的元素的值标识为1。
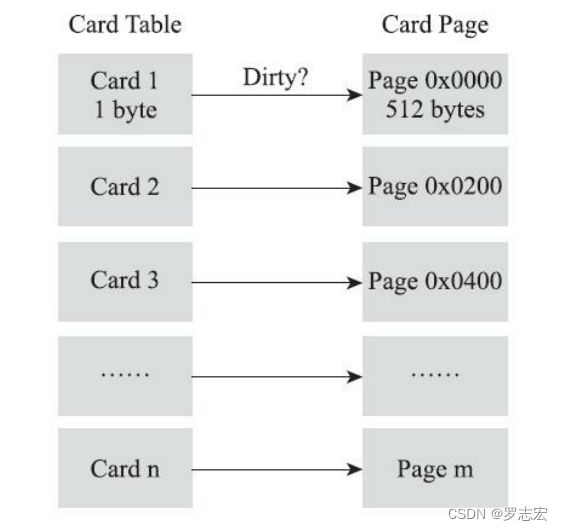
card table 的维护是通过写后屏障(post-write barrier)来完成的
void oop_field_store(oop* field, oop new_value) {
// 引用字段赋值操作
*field = new_value;
// 写后屏障,在这里完成卡表状态更新
post_write_barrier(field, new_value);
}
/*********************************/
void post_write_barrier(oop* field, oop val) {
jbyte* card_ptr = card_for(field);
// 更新卡表
*card_ptr = dirty_card;
}
写后屏障其实并不关心 new_value 是年轻代还是老年代,只要 card 对应内存上有引用变更,就会把这个 card 标记为脏卡。也就是说老年代的 card table记录不止是 old -> young 变更,还记录着 old -> old 的变更,都会让 card 变为脏卡。
抛出一个问题?存在年轻代的 card table 吗?
不存在年轻代的 card table,年轻代对象朝生夕灭,对象引用变更极其频繁,如果维护年轻代 card table,card table 会更新极其频繁。JVM 设计者考虑,与其维护年轻代 card table 代价,还不如老年代在回收时,扫描整个新手代来解决跨代引用问题。而 CMS 的 remark 阶段就是这样做的
1.3.2 mod-union table
我们知道 card table 会记录下老年代所有发生过引用变化对象所在的 card,而 CMS 在 concurrent-mark 阶段,也需要记录下老年代发生引用变化的对象以便后续重新扫描,是否可以直接复用 card table 来解决 F 对象的问题呢?
答案是不行的,这是因为每次 YGC 过程中都涉及重置和重新扫描 card table,这样是满足了 YGC 的需求,但却破坏了 CMS 的需求,CMS 需要的信息可能被 YGC 给重置掉了。为了避免丢失信息,于是在 card table 之外另外加了一个 Bitmap 叫做 mod-union table,mod-union table 和 card table 的位是一一对应的关系。
在 CMS 并发标记正在运行的过程中,每当发生一次 YGC,当 YGC 要重置 card table 里的某个记录时,就会更新 mod-union table 对应的 bit,相当于将 card table 里的信息转移到了 mod-union table 里。
相当于 card table + mod-union table 收集了并发标记阶段 D —> F 引用指向关系
1.3 并发预清理 (concurrent-preclean)
concurrent-preclean 阶段不会 STW,前一个阶段在并行运行的时候,一些对象的引用发生了变化(F 对象),所在的内存区域被标记为 dirty card,并发预清理阶段会扫描 dirty card ,对这块内存区域进行重新递归标记,目的是减轻 remark 阶段的工作量。标记完之后,会清除 card 标识。
通过参数 -XX:-CMSPrecleaningEnabled 选择关闭该阶段,默认启用;关闭之后将直接进入 remark 阶段
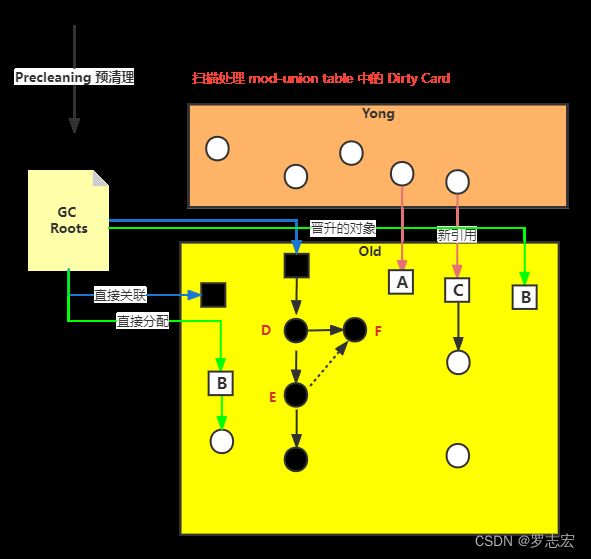
1.4 可中断预清理(concurrent-abortable-preclean)
concurrent-abortable-preclean 阶段目的是减轻 remark 阶段的负担,这个阶段同样会对 dirty card 的扫描/清理,和 concurrent-preclean 的区别在于,concurrent-abortable-preclean 会重复地以迭代的方式执行,直到满足退出条件。循环执行就是为了找到进入 remark 阶段最合理的时机。
当 eden 内存占用超过 2m 时才会执行 concurrent-abortable-preclean,否则没有执行的必要,通过
-XX:CMSScheduleRemarkEdenSizeThreshold=2m控制,默认是 2m
循环退出条件解读
- 如果执行这个逻辑的时间达到了阈值
-XX:CMSMaxAbortablePrecleanTime=5,默认是 5s,会退出循环。
循环执行,期望发生一次 ygc ;如果年轻代内存占用增长缓慢,不触发 ygc 或达不到阈值,那么作为兜底策略,避免 concurrent-abortable-preclean 长时间执行。
- 如果新生代 Eden 区的内存使用率达到了阈值
-XX:CMSScheduleRemarkEdenPenetration=50,默认50%,会退出循环。
注意!是在 concurrent-abortable-preclean 阶段触发一次 ygc 后,如果 eden 区的达到了阈值,才会退出循环
- 可以设置最多循环的次数
-XX:CMSMaxAbortablePrecleanLoops=20,默认是 0,意思没有循环次数的限制。
为什么要循环执行?
remark 阶段需要扫描新生代来解决跨代引用问题,为了减轻 remark 阶段扫描新生代的压力,concurrent-abortable-preclean 阶段循环执行就是期望在这一阶段发生一次 ygc。
除此之外,在发生一次 ygc 后,什么情况下退出循环合适?首先我们考虑下这个情况:如果 remark 阶段开始时刚好进行了 ygc,应用程序刚因为 ygc 暂停,然后又会因为 remark 阶段暂停,造成连续 STW,所以 Eden 阈值设置为 50,就表示在 eden 占用达到 50% 的时候进入下一阶段,这样这次 remark 阶段就差不多在两次 ygc 中间。
concurrent-abortable-preclean 循环执行目的就是为了控制进入 remark 阶段合理时机
1.5 重新标记(remark)
remark 阶段需要 STW,这个阶段会比 initial-mark 阶段要长,但远比 concurrent-mark 阶段要短。主要是为了标记前面并发阶段,用户线程继续运作而导致漏标、少标的对象。
简单来说,就是 A、B、C、F 类型对象
需要标记的对象
- GC Roots(老年代):解决 B 类对象问题,在并发阶段,新晋老年代且和
GC Roots直接相连的对象,它会基于整个对象引用树遍历下去
注意,与
GC Roots直接相连的对象,如果在并发标记阶段已经被标记过了,则不会继续基于对象引用树遍历下去
- 新生代:解决 A、C 类对象问题。新生代跨代引用老年代问题通过扫描新生代来解决
- card table + mod-union table:解决 F 类对象问题。通过扫描/标记
dirty card里对象,来解决并发标记阶段引用变更问题
CMS 在这个阶段任务还是比较重的,特别是在新生代比较大的情况下。CMS算法中提供了一个参数:-XX:+CMSScavengeBeforeRemark,默认并没有开启,如果开启该参数,在执行 remark 阶段之前,会强制触发一次 YGC,可以减少新生代对象的遍历时间。

CMS 标记的是存活对象,在最终标记完成之前,记录哪些不存活对象的内存区域可以进行回收。(CMS 内存分配采用空闲列表方式)
1.6 并发清除(concurrent-sweep)
concurrent-sweep 阶段不需要 Stop The World,上一阶段记录了本次 GC 的内存区域,标记整理算法并不用一一去回收已死对象,只需要把已死对象所在内存区域重新加入空闲列表即可。由于是和用户线程并发执行,这时新晋对象进入老年代所在的内存范围不在 GC 内存范围之内,所以它没被标记也不会被参与回收。
1.7 并发重置(concurrent reset)
重新设置 CMS 相关的各种状态及数据结构,为下一个垃圾收集周期做好准备。
2. cms 日志解析
ParNew
[GC (Allocation Failure) 2022-05-06T11:41:53.547+0800: [ParNew: 1637397K->204031K(1843200K), 0.1173220 secs] 1637397K->1482029K(7987200K), 0.1173704 secs] [Times: user=0.36 sys=1.00, real=0.12 secs]
-
Allocation Failure:分配失败,触发 GC -
ParNew:年轻代垃圾回收器 -
1637397K->204031K(1843200K):年轻代回收之前,年轻代被占用内存大小 =1637397K,回收之后年轻代占用内存大小 =204031K,(1843200K)代表年轻代可用内存大小,也就是 Eden 区 + 一个 S 区 -
0.1173220 secs:在没有最终清理的情况下收集的持续时间 -
1637397K->1482029K(7987200K):年轻代回收之前,整个堆被占用内存大小 =1637397K,回收之后整个堆被占用内存大小 =1482029K,(7987200K)代表整个堆可分配的内存大小,等于整个堆大小减去一个 S 区 -
0.1173704 secs:整个ParNew阶段耗时 -
[Times: user=0.78 sys=0.01, real=0.11 secs]:GC 事件在不同维度的耗时
user=0.78:CPU维度,在垃圾回收期间,所有 CPU 总的耗时加起来 = 078sys=0.01:操作系统维度,操作系统调用或等待系统事件的时间 = 0.01real=0.11 secs:应用程序维度,应用程序停顿事件 = 0.11,对于并行GC,这个数字应该接近 ( user + sys ) 除以垃圾收集器使用的线程数
初始标记
[1 CMS-initial-mark: 1277998K(6144000K)] 1500461K(7987200K), 0.0012375 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
这个阶段是 STW,通常这个阶段耗时很短。
(CMS Initial Mark):cms 初始标记1277998K(6144000K):初始标记阶段,老年代被占用内存大小 =1277998K,(6144000K)代表整个老年代可用内存大小1500461K(7987200K):初始标记阶段,整个堆被占用内存大小 =1500461K,(7987200K)代表整个堆可分配的内存大小,等于整个堆大小减去一个 S 区0.0012375 secs:初始标记阶段耗时
并发标记
[CMS-concurrent-mark-start]
[CMS-concurrent-mark: 0.004/0.004 secs] [Times: user=0.02 sys=0.09, real=0.00 secs]
这个阶段耗时意义不大,垃圾回收是和应用程序并行的。
0.004/0.004 secs:并发标记阶段持续的时间和 CPU 总的耗时
并发预清理
[CMS-concurrent-preclean-start]
[CMS-concurrent-preclean: 0.006/0.006 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
这个阶段也是和应用程序并行的。
0.006/0.006 secs:并发预清理阶段持续的时间和 CPU 总的耗时
可中断预清理
[CMS-concurrent-abortable-preclean-start]
[CMS-concurrent-abortable-preclean: 0.008/0.119 secs] [Times: user=0.41 sys=0.74, real=0.12 secs]
这个阶段也是和应用程序并行,但这个阶段会影响到最终标记
0.008/0.119 secs:可中断预清理阶段持续的时间和 CPU 总的耗时。通常情况下,这个阶段可能持续 5 秒
最终标记
[GC (CMS Final Remark) [YG occupancy: 254114 K (1843200 K)]
2022-05-06T11:41:53.868+0800: [Rescan (parallel) , 0.0009828 secs]
2022-05-06T11:41:53.869+0800: [weak refs processing, 0.0000080 secs]
2022-05-06T11:41:53.869+0800: [class unloading, 0.0001843 secs]
2022-05-06T11:41:53.869+0800: [scrub symbol table, 0.0002124 secs]
2022-05-06T11:41:53.869+0800: [scrub string table, 0.0000710 secs]
[1 CMS-remark: 2882604K(6144000K)] 3136718K(7987200K), 0.0015087 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
最终标记阶段是 STW,CMS 停顿最长时耗大概率就是发生在这个阶段
[YG occupancy: 254114 K (1843200 K)]:年轻代当前占用情况和总容量[Rescan (parallel) , 0.0009828 secs]:完成对象标记工作耗时[weak refs processing, 0.0000080 secs]: 第一个子阶段,这个阶段处理弱引用[class unloading, 0.0001843 secs]:第二个子阶段,卸载未使用的类,以及该阶段的持续时间[scrub symbol table, 0.0002124 secs]:第三个子阶段,that is cleaning up symbol tables which hold class-level metadata and internalized string respectively[scrub string table, 0.0000710 secs]:最后一个子阶段,that is cleaning up string tables which hold class-level metadata and internalized string respectively[1 CMS-remark: 2882604K(6144000K)] 3136718K(7987200K), 0.0015087 secs]:最终标记阶段,2882604K(6144000K)代表老年代占用内存大小和容量,3136718K(7987200K):代表整个堆占用内存大小和可分配的容量,0.0015087 secs代表最终标记阶段持续时间
并发清除
[CMS-concurrent-sweep-start]
[CMS-concurrent-sweep: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
这个阶段也是和应用程序并行的。
[CMS-concurrent-sweep: 0.002/0.002 secs]:并发清除阶段持续的时间和 CPU 总的耗时
并发重置
[CMS-concurrent-reset-start]
[CMS-concurrent-reset: 0.045/0.045 secs] [Times: user=0.16 sys=0.03, real=0.05 secs]
这个阶段也是和应用程序并行的。
[CMS-concurrent-reset: 0.045/0.045 secs]:并发重置阶段持续的时间和 CPU 总的耗时
3. cms 注意事项
3.1 concurrent mode failure
CMS 很多阶段是和用户线程并发执行,这些阶段会源源不断有新的对象产生,从而触发 YGC,如果需要搬进老年代的对象大于老年代的可用空间,则会触发 Full GC。
解决方案:
这种情况一般是触发 cms 垃圾回收太晚了,可用适当提前触发来保证 cms 回收阶段不会触发 full gc,可用通过 -XX:CMSInitiatingOccupancyFraction=68 参数来控制。
日志如下:
2022-05-29T00:07:24.046+0800: [GC (Allocation Failure) 2022-05-29T00:07:24.046+0800: [ParNew: 2170K->26K(5568K), 0.0010644 secs] (concurrent mode failure): 20684K->19615K(24576K), 0.0168460 secs] 20807K->19615K(30144K), [Metaspace: 3318K->3318K(1056768K)], 0.0179448 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]
2022-05-29T00:07:24.064+0800: [Full GC (Allocation Failure) 19615K->19598K(30144K), [Metaspace: 3318K->3318K(1056768K)], 0.0028353 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
3.2 promotion failure
promotion failure 后面都会伴随着 concurrent mode failure 出现,但它有点不同,他是在触发 YGC 后,需要搬进老年代的对象太大,虽然老年代的可用空间大于这个对象大小,但是没有连续规整的内存空间来存放这个大对象,从而触发 Full GC 来整理老年代内存空间,这是由于 cms 采用 标记-清除 算法造成的。
解决方案:
无特别好的解决方案,建议换 G1
日志如下:
2022-05-29T00:10:33.173+0800: [GC (Allocation Failure) 2022-05-29T00:10:33.173+0800: [ParNew (promotion failed): 3221K->3202K(4608K), 0.0008771 secs](concurrent mode failure): 23744K->23713K(25600K), 0.0096309 secs] 24918K->23713K(30208K), [Metaspace: 3339K->3339K(1056768K)], 0.0105546 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2022-05-29T00:10:33.188+0800: [Full GC (Allocation Failure) 27792K->27698K(30208K), [Metaspace: 3348K->3348K(1056768K)], 0.0101636 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
4. cms 优化方向
// TODO