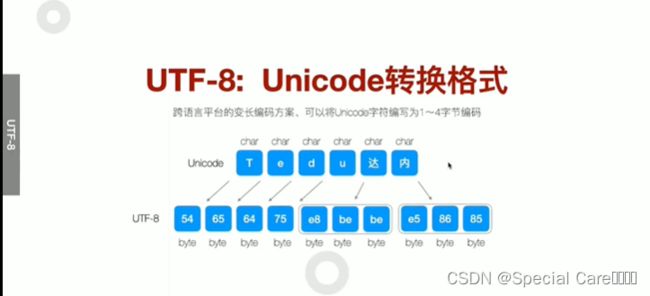
UTF-8(Unicode Transformation Format)

文章目录
- 一、Unicode
-
- 示例代码:
- 二、网络传输与Unicode
- 三、UTF-8如何编码
- 四、使用UTF-8转换传输Unicode
- 五、利用Java-API进行UTF8编码和解码
- 六、利用代码输出Unicode编码和UTF8编码
- 七、手写UTF8编码、解码
- 八、总结UTF8
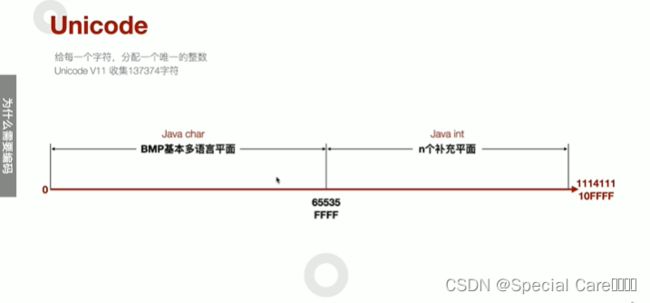
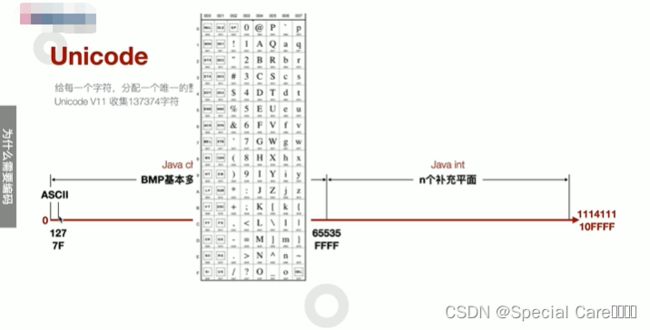
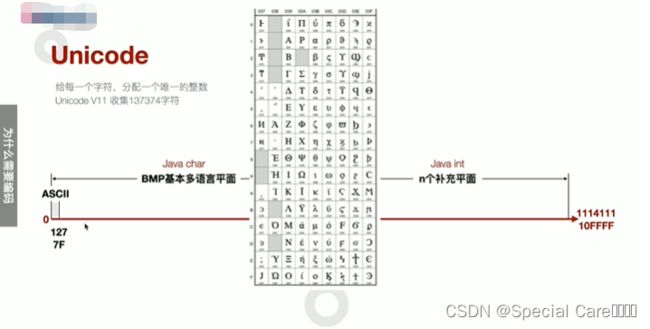
一、Unicode
示例代码:
package demo;
/**
* @Date: 2023-3-17 周五 15:48
* @Author: Special Care
* @Description: TODO Unicode编码
* @Version: 1.0.0
*/
public class UnicodeDemo01 {
public static void main(String[] args) {
/**
* Unicode编码
* Java中的字符存储的是一个符号的Unicode编码
* 可以显示为10进制或16进制形式
* Java的字符范围0~65535(FFFF)
*/
char c1 = 'A'; // 65 41
char c2 = '中'; // 20013 4e2d
char c3 = '✈'; // 9992 2708
char c4 = 'a'; // 97 61
System.out.println((int)c1);// 65
System.out.println(Integer.toHexString(c1));// 41
System.out.println((int)c2);// 20013
System.out.println(Integer.toHexString(c2));// 4e2d
System.out.println((int)c3);// 9992
System.out.println(Integer.toHexString(c3));// 2708
System.out.println((int)c4);// 97
System.out.println(Integer.toHexString(c4));// 61
}
}
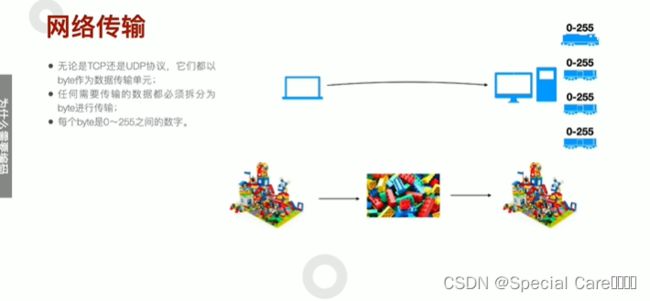
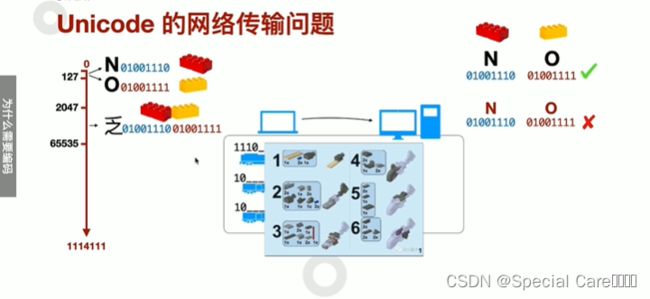
二、网络传输与Unicode
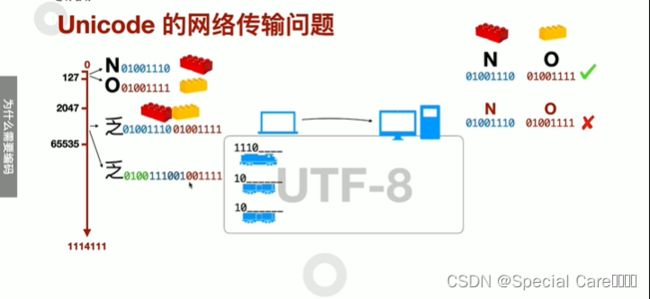
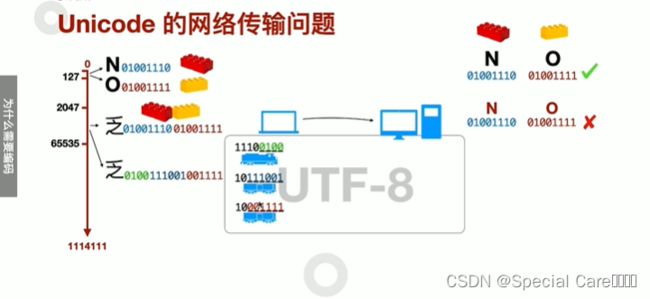
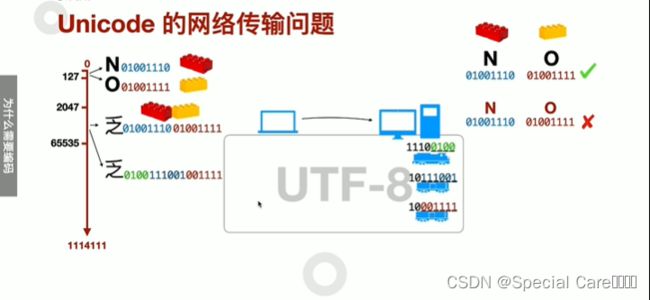
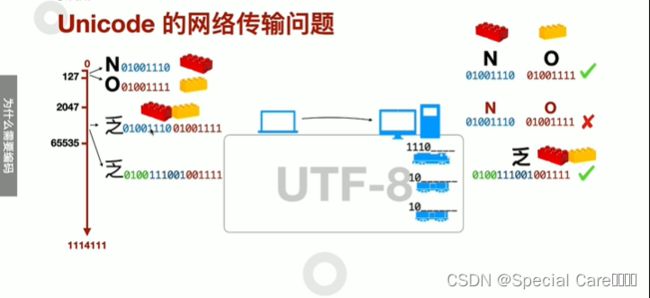
三、UTF-8如何编码
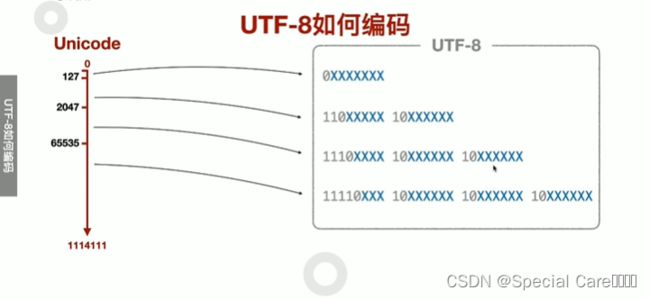
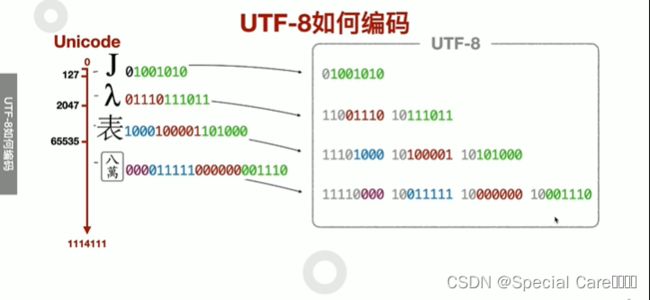
四、使用UTF-8转换传输Unicode

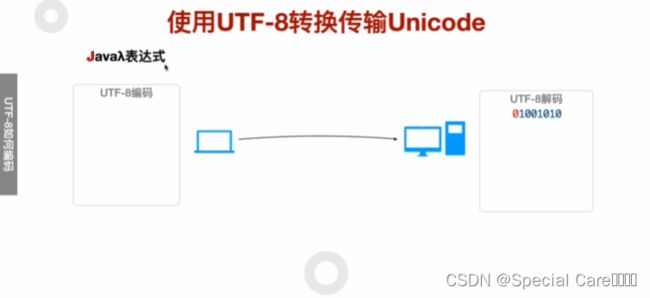
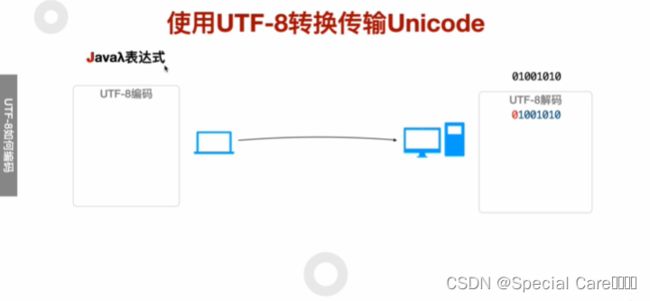

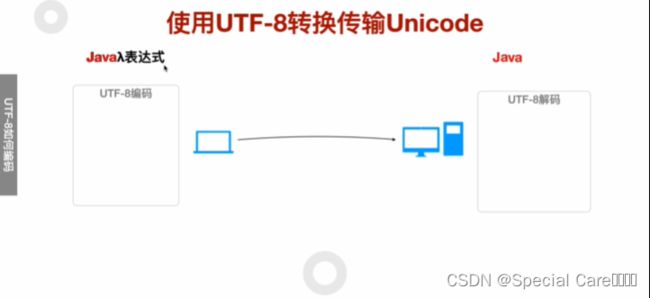
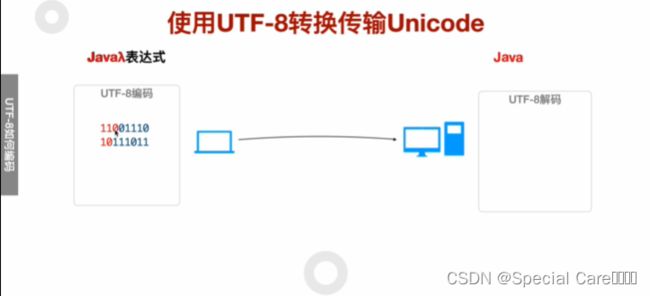
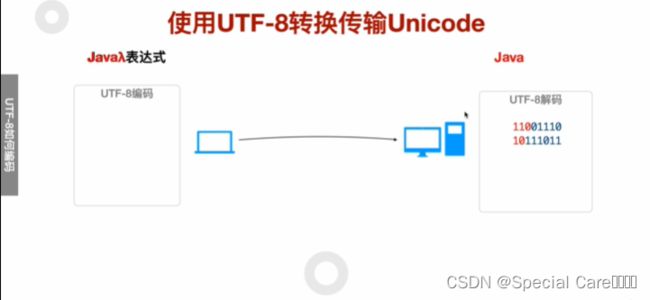


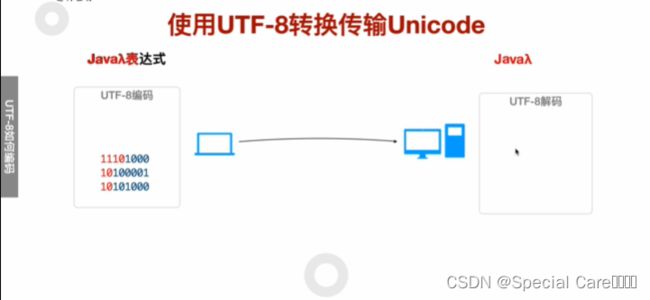
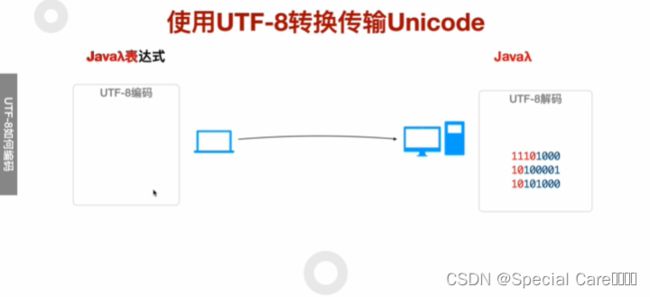

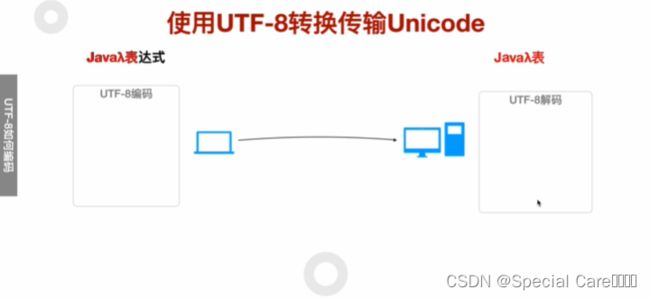
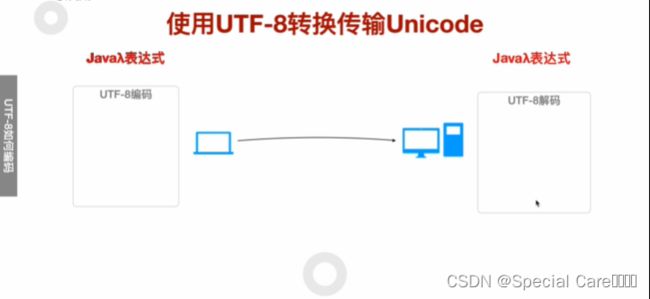
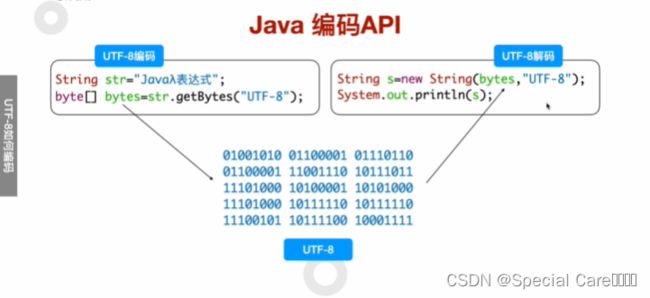
五、利用Java-API进行UTF8编码和解码
package demo;
import java.nio.charset.StandardCharsets;
/**
* @Date: 2023-3-17 周五 16:44
* @Author: Special Care
* @Description: TODO 测试UTF-8编解码API
* @Version: 1.0.0
*/
public class UTF8Demo {
public static void main(String[] args) throws Exception{
/**
* 测试UTF-8编解码API
*/
String str = "Javaλ表达式";
// 将字符串中的文字进行UTF-8编码
// str.getBytes(StandardCharsets.UTF_8)也可以写成str.getBytes("UTF_8")
// 经过getBytes方法的转换得到了UTF-8编码的字节数组
byte[] bytes = str.getBytes(StandardCharsets.UTF_8);
// bytes就可以利用网络进行传输
// 将字节数组中的UTF-8编码的字符进行解码
// new String(bytes, "UTF-8")
String s = new String(bytes, StandardCharsets.UTF_8);
System.out.println(s); // Javaλ表达式
}
}
六、利用代码输出Unicode编码和UTF8编码
package demo;
import java.nio.charset.StandardCharsets;
/**
* @Date: 2023-3-17 周五 16:44
* @Author: 李林泼
* @Description: TODO 测试UTF-8编解码API
* @Version: 1.0.0
*/
public class UTF8Demo {
public static void main(String[] args) throws Exception{
/**
* 测试UTF-8编解码API
*/
String str = "Javaλ表达式";
// 将字符串中的文字进行UTF-8编码
// str.getBytes(StandardCharsets.UTF_8)也可以写成str.getBytes("UTF_8")
// 经过getBytes方法的转换得到了UTF-8编码的字节数组
byte[] bytes = str.getBytes(StandardCharsets.UTF_8);
// bytes就可以利用网络进行传输
// 将字节数组中的UTF-8编码的字符进行解码
// new String(bytes, "UTF-8")
String s = new String(bytes, StandardCharsets.UTF_8);
System.out.println(s);
/**
* 输出字符串中每个字符的Unicode
* String str = "Javaλ表达式";
*/
System.out.println("Unicode:");
for (int i = 0; i < str.length(); i++) {
// i = 0, 1, 2, 3, 4, ...
char c = str.charAt(i);
System.out.print(c);
System.out.print(":");
System.out.println(Integer.toBinaryString(c));
}
System.out.println();
System.out.println("UTF-8:");
for (byte b : bytes) {
System.out.println(Integer.toBinaryString(b & 0xff));
}
/**
* Javaλ表达式
* Unicode:
* J:1001010
* a:1100001
* v:1110110
* a:1100001
* λ:1110111011
* 表:1000100001101000
* 达:1000111110111110
* 式:101111100001111
*
* UTF-8:
* 1001010
* 1100001
* 1110110
* 1100001
* 11001110
* 10111011
* 11101000
* 10100001
* 10101000
* 11101000
* 10111110
* 10111110
* 11100101
* 10111100
* 10001111
*/
}
}
七、手写UTF8编码、解码
package demo;
import java.util.Arrays;
/**
* @Date: 2023-3-17 周五 17:15
* @Author: 李林泼
* @Description: TODO 手工编写UTF-8编码、解码
* @Version: 1.0.0
*/
public class UTF8Coding {
/**
* 手工编写UTF-8编码
* Char. number range | UTF-8 octet sequence
* (hexadecimal) | (binary)
* --------------------+------------------------------
* 0000 0000-0000 007F | 0xxxxxxx
* 0000 0000-0000 07FF | 110xxxxx 10xxxxxx
* 0000 0000-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
* 0000 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
*/
/**
* 将一个字符串编码为UTF-8字节数组
* @param str 被编码的字符串
* @return 经过UTF-8编码以后字节数组
*/
public static byte[] getBytes(String str){
// 预估一下返回值的最大情况
byte[] bytes = new byte[str.length() * 4];
// index代表bytes数组中数据的存储位置
int index = 0;
// 遍历字符串中每个字符,根据字符的Unicode编码范围,进行编码
// 将编码存储到bytes,bytes中就是返回值UTF-8数据
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
// 判断c范围,根据范围进行编码
if (c <= 0x7F){
// c在0~0x7F范围内,是1字节编码,1字节编码添加到bytes
bytes[index++] = (byte) c;
}else if (c <= 0x7FF){
// c在0x80~0x7FF范围内,处理两个字节的UTF-8编码
// b1 b2
// 110xxxxx 10xxxxxx
// 截取字符的后6位
// 0b111111
int b2 = (c & 0x3F) | 0b10000000;
// 0b11111
int b1 = ((c >>> 6) & 0x1F) | 0b11000000;
bytes[index++] = (byte) b1;
bytes[index++] = (byte) b2;
}else if (c < 0xFFFF){
// 处理3字节编码
// 1110xxxx 10xxxxxx 10xxxxxx
int b3 = (c & 0b111111) | 0b10000000;
int b2 = ((c >>> 6) & 0b111111) | 0b10000000;
int b1 = ((c >>> 12) & 0b1111) | 0b11100000;
bytes[index++] = (byte) b1;
bytes[index++] = (byte) b2;
bytes[index++] = (byte) b3;
}
}
return Arrays.copyOf(bytes,index);
}
/**
* 将UTF-8编码的字节数组解码为字符串(Unicode字符)
* @param bytes UTF-8编码的字节
* @return 解码以后的字符串
*/
public static String decode(byte[] bytes){
char[] chs = new char[bytes.length];
int index = 0;
// 遍历字节数组,检查每个字节
// 如果字节以0开头,则是单字节编码
// 如果是以110开头,则是双字节编码
// 如果是以1110开头,则是三字节编码
for (int i = 0; i < bytes.length; ) {
int b1 = bytes[i++] & 0xff;
if ((b1 >>> 7) == 0){
// 检查01001010是否为单字节编码0xxxxxxx
// b1 00000000 00000000 00000000 01001010
// b1>>>7 000000000000000 00000000 00000000 0
chs[index++] = (char)b1;
}else if ((b1 >>> 5) == 0b110){
// 检查是否为双字节编码 b1 11001110 b2 10111011
// b1 -> int
// b1 00000000 00000000 00000000 11001110
// b1>>>5 0000000000000 00000000 00000000 110
int b2 = bytes[i++] & 0xff;
// b1 00000000 00000000 00000000 11001110
// b2 00000000 00000000 00000000 10111011
// c 00000000 00000000 0000001110 111011
int c = ((b1 & 0b11111)<<6) | (b2 & 0b111111);
chs[index++] = (char) c;
}else if ((b1 >>> 4) == 0b1110){
// 检查是否为三字节编码:11101000 10100001 10101000
int b2 = bytes[i++] & 0xff;
int b3 = bytes[i++] & 0xff;
int c = ((b1 & 0b1111)<<12) | ((b2 & 0b111111)<<6) | (b3 & 0b111111);
System.out.println("b1:" + Integer.toBinaryString(b1));
System.out.println("b2:" + Integer.toBinaryString(b2));
System.out.println("b3:" + Integer.toBinaryString(b3));
System.out.println("c:" + Integer.toBinaryString(c));
chs[index++] = (char) c;
}
}
return new String(chs,0,index);
}
public static void main(String[] args) {
String str = "Javaλ表达式";
System.out.println("Unicode:");
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
System.out.print(c);
System.out.print(":");
System.out.println(Integer.toBinaryString(c));
}
// 调用手写UTF-8编码方法
byte[] bytes = getBytes(str);
for (byte b : bytes) {
System.out.println(Integer.toBinaryString(b & 0xff));
}
// 检查手写的UTF-8解码运算
String s = decode(bytes);
System.out.println(s);
}
/**
* Unicode:
* J:1001010
* a:1100001
* v:1110110
* a:1100001
* λ:1110111011
* 表:1000100001101000
* 达:1000111110111110
* 式:101111100001111
* 1001010
* 1100001
* 1110110
* 1100001
* 11001110
* 10111011
* 11101000
* 10100001
* 10101000
* 11101000
* 10111110
* 10111110
* 11100101
* 10111100
* 10001111
* b1:11101000
* b2:10100001
* b3:10101000
* c:1000100001101000
* b1:11101000
* b2:10111110
* b3:10111110
* c:1000111110111110
* b1:11100101
* b2:10111100
* b3:10001111
* c:101111100001111
* Javaλ表达式
*/
}
八、总结UTF8