【图像分割】LabelMe基本使用/标注标签格式转换及可视化
前言
之前一直在做目标检测的相关内容,使用LabelImg标注检测数据轻车熟路。不过最近尝试探索一下图像分割场景,需要用到LabelMe标注用于分割的数据标签,本文进行过程记录。
图像分割数据标签示例
以道路分割为例,下图是deepglobe数据集中的一组数据,右侧是卫星拍摄影像,左侧为该影像标签,以Mask的方式来标注出图像。

LabelMe安装
安装很简单,用pip安装即可:
pip install labelme
数据准备
在启动之前,先按照下面目录整理好数据位置:
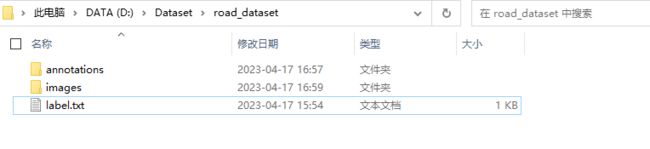
- annotations:空文件夹,准备用来保存标注后的标签
- images:放置图片,将图片数据拷贝到里面
- label.txt:这个主要用来预先设定类别
label.txt文件内容如下:
__ignore__
_background_
road
前行内容固定,和后面处理脚本相关,第三行开始为类别名称,我这里只需要分割道路,因此就一个road类别。
软件使用
首先在Anaconda Prompt里面进入到数据文件根目录:
cd D:\Dataset\road_dataset
然后启动labelme:
labelme --labels label.txt
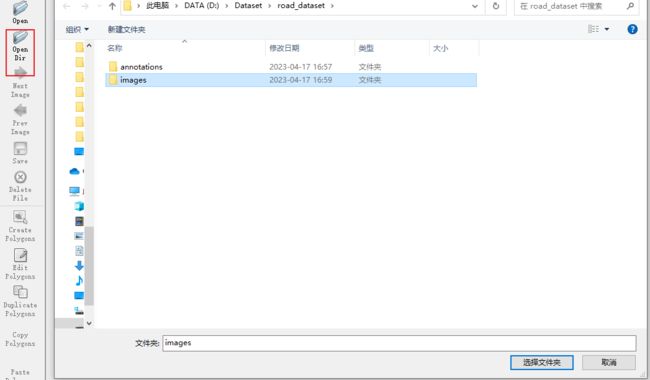
选择OpenDir导入图片:
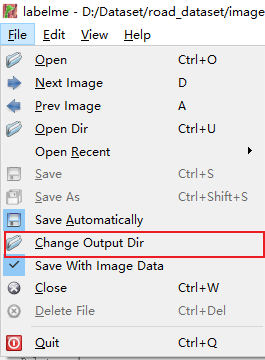
设置标签输出文件夹:
 `
`
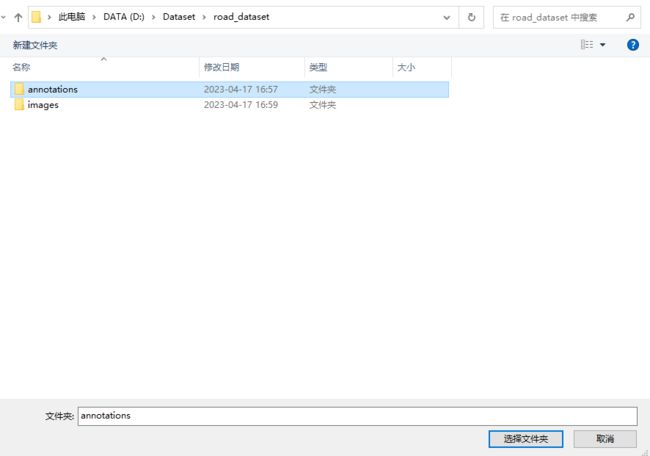
设定为之前建的annotations:
点击Create Polygons(快捷键Ctrl+N),围绕目标点一圈,类似PS里的抠图,首尾相连,保存即可。
格式转换
标注完之后,可以得到json格式的标签。
下面需要根据该标签进行格式转换,得到图像类型的标签。
下面这段转换代码修改自labelme官方仓库,主要修改了文件加载逻辑和路径:
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="D:/Dataset/road_dataset/annotations", help="input annotated directory")
parser.add_argument("--output_dir", default="D:/Dataset/road_dataset", help="output dataset directory")
parser.add_argument("--labels", default="D:/Dataset/road_dataset/label.txt", help="labels file")
args = parser.parse_args()
args.noviz = False
if not osp.exists(args.output_dir):
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
lbl,
imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()
运行之后,会多出几个文件夹:
- JPEGImages:原始图像
- SegmentationClass:npy格式label
- SegmentationClassPNG:掩码图像
- SegmentationClassVisualization:掩码图像和实景图像叠加显示
- class_names.txt:全部类别(包括背景)
标签可视化
对于此任务,我仅需要白色掩码图像,但是labelme的mask可视化没给相关颜色接口。
因此自己用opencv重撸一个mask可视化程序:
import json
import cv2
import numpy as np
from tqdm import tqdm
import os
fill_color = (255, 255, 255)
root_dir = 'D:/Dataset/road_dataset'
def visualize_one(label_name):
with open(root_dir + '/annotations' + '/' + label_name + '.json', 'r') as obj:
dict = json.load(obj)
img = cv2.imread(root_dir + '/images' + '/' + label_name + '.jpg')
for label in dict['shapes']:
points = np.array(label['points'], dtype=np.int32)
black_img = np.zeros(img.shape)
cv2.polylines(black_img, [points], isClosed=True, color=fill_color, thickness=1)
cv2.fillPoly(black_img, [points], color=fill_color)
cv2.imwrite(root_dir + '/labels' + '/' + label_name + '.jpg', black_img)
if __name__ == '__main__':
os.mkdir(root_dir + '/labels')
for i in tqdm(os.listdir(os.path.join(root_dir, "annotations"))):
label_name = i[:-5]
visualize_one(label_name)
运行之后,可以顺利得到相应的标签。

参考
[1] Labelme分割标注软件使用 https://blog.csdn.net/qq_37541097/article/details/120162702