Chrome 浏览器全球大翻车?让 20 多亿用户无网可上
Chrome 浏览器要翻车了?随着版本号即将达到 100,谷歌浏览器遇到了一些意想不到的问题。而这可能会影响高达 20 多亿的用户。

当然了,紧随其后的 Firefox 和 Edge 也不能幸免。
满 100 减 90
这个问题吧,倒不是说浏览器会闪退,只不过是失去了它原本的作用:访问网站罢了。当你使用 Chrome 100 时,网站一看,你这是个什么「老古董」?对不起,不支持,我拒绝。

对此谷歌表示,这一问题主要出现在与 Duda 合作开发的网站中,并已着手开始修复。原因其实很简单:版本号。

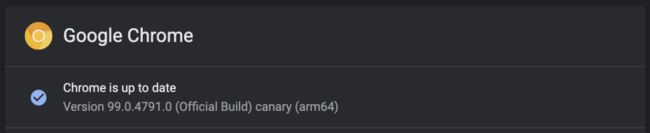
大多数网站都会检查用户代理字符串来确定用户的浏览器版本。在 Chrome 浏览器中,以当前公共版本为例,这个用字符串表示的版本号的内容是:Chrome/96.0.4664.110。正常情况下,开发者不需要知道浏览器的具体版本。因此,Duda 在默认情况下只会读取「Chrome/」后面的两个字符。比如,在「Chrome/96.0.4664.110」的例子中,Duda 将只读取「96」。

而 「Chrome Canary」已经到了「99.0.4791.0」,那么 Duda 就只读取「99」。
这种读取方法是出于安全考虑,以阻止旧的、已经不予支持的 Chrome 浏览器访问(40 及以上是一个常见的 Chrome 浏览器版本分界点)。这样的设计虽然简洁,但如此一来,Chrome 100 只能被识别为 Chrome 10。而最坑的是,Duda 出于兼容性的考虑,会阻止版本低于 40 的 Chrome 浏览器打开网站,这样就会导致 Chrome 100 无法正常访问网站。为了避免这种尴尬的情况,网络开发者必须在 Chrome 100 推出之前找到一种方法,正确解析三位数的版本号。

不过,要寻找一个能够彻底修复这一漏洞的方法是很棘手的,而且时间已经不多了。因为谷歌公司开发 Chrome 浏览器的速度极为惊人,Chrome 浏览器的版本号也在不断增加。根据目前的发布速度,Canary 用户可能最快会在下个月就会遇到这个 bug,而运行稳定版的数十亿用户也只剩 3 至 6 个月的时间了。这也就意味着,Chrome 浏览器的用户需要为网络中断做好准备,或者在问题解决之前先用其他浏览器。
99.100 先凑合用
其实,在 11 月 1 日的时候,谷歌就发现这个潜在的问题了。

图片
对此,谷歌为 Chrome 提供了一个测试 flag,从而可以强制浏览器的版本号显示为 100,以便于网站排查问题并为变化做好准备。只需在地址栏中输入 chrome://flags 并启用 #force-major-version-to-100 就可以了。

不得不说,工程师的脑洞还真挺大。如果实在是不行的话,也不是没有办法!他们想出了一个能凑合用的方法:让 Chrome 浏览器版本的前两个数字锁定为 99,然后将实际版本号放在第二组数字中。对于几乎没有机会更新的老网站来说,这招应该会非常有效。这样,用户代理字符串中表达版本号的内容将以「Chrome/99.100.XX」的形式呈现,从而解决了 Duda 的识别问题。此外,谷歌也在寻找有识别问题的网站,并试图与开发者取得联系,从而通过修改代码来解决问题。

当然,这听起来肯定不是最优雅的解决方案。
谷歌方面也把这个解决方案认定为一个「备份计划」。
毕竟这个「备份计划」并不能覆盖所有情况,因为 Duda 可能并不是唯一出现问题的网络工具包。
目前,谷歌希望能够明确地找到全网所有在 Chrome 100 发布时出现故障的网站,并就这个问题与它们的开发者联系。

如果这些问题能在 3 月底 Chrome 100 发布前得到解决,那么对网络开发者来说就根本不需要改变什么。
否则,Chrome 就只能在用户代理字符串中增加新的内容。
谷歌的金丝雀
Chrome 有四个「发布渠道」:稳定版,测试版,开发版和金丝雀版。
从为普通用户提供最稳定的版本的稳定版,到提供尖端功能和修复但更不稳定的金丝雀。

煤矿工人过去下矿井时,他们带着一只金丝雀作为早期预警系统。如果金丝雀活下来,空气就可以安全呼吸。如果不安全,则是时候离开了。

技术圈的 Canary 正式来自「矿井里的金丝雀」这个谚语,指的是软件的 alpha 测试版本,谷歌浏览器也不例外。
Chrome Canary 中的一些修复和新功能在成为主要稳定版的一部分之前,将在开发和测试版进行全面测试。
除了缺乏测试,并且可能没有修复所有错误之外,Canary 仅仅是 Chrome FROM THE FUTURE。
异曲同工的「千年虫」
Y2K 是 2000 年软件 bug 的通用缩写。
该缩写中的字母 Y 代表「年」,数字 2 和大写的 k 代表 kilo,意思是 1000,因此,2K 表示 2000 年。
Y2K 也被命名为「千年虫」,因为它与千禧年的时间戳有关。

在上个世纪,无论是大型计算机还是个人计算机,「存储信息」这一行为是非常昂贵的,少说也要每千字节 10 美元,在许多情况下甚至超过超过每千字节 100 美元。
因此,对于程序员来说,最大限度地减少存储信息是非常重要的,能省 1bit 是 1bit 。
所以,那时候的数据文件的日期格式是六位数字,形式为 DDMMYY,日为两位数,月为两位数,年为两位数的 YY。比如,1970 年 1 月 1 日,就是 700101。
甚至,还有一种更短的表示方法「YYDDD」,其中 DDD 是一年中的天数。由于磁盘和磁带上的空间也很昂贵,因此通过减少存储日期的数据文件大小也节省了资金。
可是,有些程序在面对两位数年份时,无法区分 2000 年和 1900 年。这便是「千年虫」的由来。

不过,有一个地区是例外。
1999 年年底,在全世界程序员在为千年虫问题焦虑的的时候,日本程序员却灵机一动:如果继续沿用昭和(1926 年开始)年号的话,千年虫会足足延后到 2025 年。
25 年的时间总该可以解决这次的问题了。当然,如果真的打算解决的话……
然而日本在 2019 年改元为令和时,不但要更改年号,而且昭和时代年号计算的「新千年虫」(昭和 100 年)马上就要来临。
而且不幸的是,不少系统的源代码经过 30 至 40 年都已经丢失了。
更加不巧的是,据说在日本 IT 界还有一个叫「2007 年问题」的问题。
也就是说,当年建立电脑系统的工程师,大部分都会集中在 2007 年退休。到现在,已经基本上没有多少人知道如何维护旧的系统了。