TensorFlow 决策森林详细介绍和使用说明
使用TensorFlow训练、调优、评估、解释和部署基于树的模型的完整教程
两年前TensorFlow (TF)团队开源了一个库来训练基于树的模型,称为TensorFlow决策森林(TFDF)。经过了2年的测试,他们在上个月终于宣布这个包已经准备好发布了,也就是说我们可以真正的开始使用了。所以这篇文章将详细介绍这个软件包,并向你展示如何(有效地)使用它。

在这篇文章中,我们将使用美国小企业管理局数据集训练一些贷款违约预测模型。模型将使用已经预处理的数据进行训练。安装TensorFlow决策森林非常简单,只需运行
pip install tensorflow_decision_forests
。
TensorFlow Decision Forest
1、什么是TFDF?
TensorFlow决策森林实际上是建立在c++的Yggdrasil决策森林之上库的,Yggdrasil决策森林也是由谷歌开发的。最初的c++算法旨在构建可扩展的决策树模型,可以处理大型数据集和高维特征空间。通过将这个库集成到更广泛的TF生态系统中,用户无需学习另一种语言就可以轻松地构建可扩展的RF和GBT模型。
2、为什么要用它?
与XGBoost或LightGBM相比,这个库的主要优势在于它与其他TF生态系统组件紧密集成。对于已经将其他TensorFlow模型作为管道的一部分或使用TFX的团队来说,这是非常有用的,因为TFDF可以很容易地与NLP模型集成。如果你正在使用TF Serving为模型提供对外服务,这个库也是可以用的,因为它是官方的原生支持(不需要ONNX或其他跨包序列化方法)模型的部署。最后这个库为还提供了大量参数,可以根据XGBoost、LightGBM和许多其他梯度增强机(GBM)方法来调整获得近似模型。这意味着不需要在训练过程中在不同的GBM库之间切换,这从代码可维护性的角度来说非常好。
模型训练
1、数据准备
我们使用了数据处理后的版本,所以不需要进行数据的预处理:
# Read in data
train_data: pd.DataFrame=pd.read_parquet("../data/train_data.parquet")
val_data: pd.DataFrame=pd.read_parquet("../data/val_data.parquet")
test_data: pd.DataFrame=pd.read_parquet("../data/test_data.parquet")
# Set data types
NUMERIC_FEATURES= [
"Term",
"NoEmp",
"CreateJob",
"RetainedJob",
"longitude",
"latitude",
"GrAppv",
"SBA_Appv",
"is_new",
"same_state",
]
CATEGORICAL_FEATURES= [
"FranchiseCode",
"UrbanRural",
"City",
"State",
"Bank",
"BankState",
"RevLineCr",
"naics_first_two",
]
TARGET="is_default"
# Make sure that datatypes are consistent
dsets= [train_data,val_data,test_data]
fordindsets:
d[NUMERIC_FEATURES] =d[NUMERIC_FEATURES].astype(np.float32)
d[CATEGORICAL_FEATURES] =d[CATEGORICAL_FEATURES].astype(str)
2、特征
为了确保项目结构良好并避免意外行为,可以为每个特性指定一个FeatureUsage,尽管这不是强制性的,但是使用这种方法可以让我们的项目更加规范。并且这也是一项简单的任务:只需要从支持的六种类型(BOOLEAN、CATEGORICAL、CATEGORICAL_SET、DISCRETIZED_NUMERICAL、HASH和NUMERICAL)中决定将哪些特征类型分配给哪个类型就可以了。其中一些类型带有额外的参数,所以请确保在这里阅读更多关于它们的信息。
在本例中我们将保持简单,只使用数值和类别数据类型,但是需要说明下DISCRETIZED_NUMERICAL,它可以显著加快训练过程(类似于LightGBM)。我们使用的代码如下,指定所选的数据类型,对于类别特征,还要指定min_vocab_frequency参数以去除罕见值。
importtensorflow_decision_forestsastfdf
# Prepare Feature Usage list
feature_usages= []
# Numerical features
forfeature_nameinNUMERIC_FEATURES:
feature_usage=tfdf.keras.FeatureUsage(
name=feature_name, semantic=tfdf.keras.FeatureSemantic.NUMERICAL
)
feature_usages.append(feature_usage)
# Categorical features
forfeature_nameinCATEGORICAL_FEATURES:
feature_usage=tfdf.keras.FeatureUsage(
name=feature_name,
semantic=tfdf.keras.FeatureSemantic.CATEGORICAL,
min_vocab_frequency=1000,
)
feature_usages.append(feature_usage)
3、使用TF Dataset读取数据
读取数据的最简单方法是使用TF Dataset。TFDF有一个非常好的实用函数pd_dataframe_to_tf_dataset,它使这一步变得非常简单。
# Use TF Dataset to read in data
train_dataset=tfdf.keras.pd_dataframe_to_tf_dataset(
train_data, label=TARGET, weight=None, batch_size=1000
)
val_dataset=tfdf.keras.pd_dataframe_to_tf_dataset(
val_data, label=TARGET, weight=None, batch_size=1000
)
test_dataset=tfdf.keras.pd_dataframe_to_tf_dataset(
test_data, label=TARGET, weight=None, batch_size=1000
)
在上面的代码中,我们将DataFrame对象传递到函数中,并提供以下参数:
- label 列的名称
- weight 列的名称(在本例中为None)
- 批大小(有助于加快数据的读取)
得到的数据集是就是TF Dataset的格式。也可以创建自己的方法来读取数据集,但必须特别注意输出的格式,没有这个方法这样方便。
3、TFDF默认参数
## Define the models
# Gradient Boosted Trees model
gbt_model=tfdf.keras.GradientBoostedTreesModel(
features=feature_usages,
exclude_non_specified_features=True,
)
# Random Forest modle
rf_model=tfdf.keras.RandomForestModel(
features=feature_usages,
exclude_non_specified_features=True,
)
# Compile the models (Optional)
gbt_model.compile(metrics=[tf.keras.metrics.AUC(curve="PR")])
rf_model.compile(metrics=[tf.keras.metrics.AUC(curve="PR")])
# Fit the models
gbt_model.fit(train_dataset, validation_data=val_dataset)
rf_model.fit(train_dataset, validation_data=val_dataset)
只需要几行代码就可以使用默认参数构建和训练GBT和RF模型。当使用ROC和PR auc评估这两个模型时可以看到性能已经相当好了。
# GBT with Default Parameters
PR AUC: 0.8367
ROC AUC: 0.9583
# RF with Default Parameters
PR AUC: 0.8102
ROC AUC: 0.9453
那么是否可以进行超参数调优进一步改善这些结果呢。
超参数调优
Yggdrasil官方文档中有大量的参数可以进行调优,每一个参数都有很好的解释。TFDF也提供了一些内置选项来调优参数,为了简单也使用超参数的搜索库,例如Optuna或Hyperpot。
1、超参数模板
TFDF提供的非常好特性就是超参数模板。这些参数在论文中被证明在广泛的数据集上表现最好。有两个可用的模板:better_default和benchmark_rank。如果你时间不够,或者对机器学习不太熟悉,这是一个不错的选择。指定这些参数只需要一行代码。
# Define the models
better_default_gbt_model=tfdf.keras.GradientBoostedTreesModel(
hyperparameter_template='better_default', # template 1
features=feature_usages,
exclude_non_specified_features=True,
)
benchmark_gbt_model=tfdf.keras.GradientBoostedTreesModel(
hyperparameter_template='benchmark_rank1', # template 2
features=feature_usages,
exclude_non_specified_features=True,
)
# Fit the models (notice that we're skipping compiling step)
better_default_gbt_model.fit(train_dataset, validation_data=val_dataset)
benchmark_gbt_model.fit(train_dataset, validation_data=val_dataset)
看看结果怎么样:使用better_default参数,在ROC和PR auc中得到轻微的提升。benchmark_rank参数的性能要差得多。这就是为什么在部署结果模型之前正确地评估它们是很重要的。
GBT with 'Better Default' Parameters
PR AUC: 0.8483
ROC AUC: 0.9593
GBT with 'Benchmark Rank 1' Parameters
PR AUC: 0.7869
ROC AUC: 0.9442
2、定义搜索空间
TFDF附带了一个很好的程序,叫做RandomSearch,它在许多可用参数之间执行随机网格搜索。TFDF可以使用预定义的搜索空间或者通过一个选项可以手动指定这些参数(见示例)。如果您不太熟悉ML,这可能是一个很好的选择,因为它不需要手动设置这些参数。
# Create a Random Search tuner with 50 trials and automatic hp configuration.
tuner=tfdf.tuner.RandomSearch(num_trials=50, use_predefined_hps=True)
# Define and train the model.
tuned_model=tfdf.keras.GradientBoostedTreesModel(tuner=tuner)
tuned_model.fit(train_dataset, validation_data=val_dataset, verbose=2)
注意:无论那个超参数搜索都会耗费大量的时间,所以请根据模型谨慎选择。
进行完搜索后,可以使用下面的命令查看所有尝试过的组合。
tuning_logs = tuned_model.make_inspector().tuning_logs()

我们进行了12次迭代,最佳模型的表现比基线稍差,所以请谨慎使用内置的调优方法,建议使用其他库,比如Optuna。
PR AUC: 0.8216
ROC AUC: 0.9418
3、optuna
下面我们介绍如何使用optuna进行调优。
importoptuna
defobjective(trial: optuna.Trial) ->float:
params= {
"max_depth": trial.suggest_int("max_depth", 2, 10),
"l1_regularization": trial.suggest_float("l1_regularization", 0.01, 20),
"l2_regularization": trial.suggest_float("l2_regularization", 0.01, 20),
"growing_strategy": trial.suggest_categorical(
"growing_strategy", ["LOCAL", "BEST_FIRST_GLOBAL"]
),
"loss": trial.suggest_categorical(
"loss", ["BINOMIAL_LOG_LIKELIHOOD", "BINARY_FOCAL_LOSS"]
),
"min_examples": trial.suggest_int("min_examples", 5, 1000, step=5),
"focal_loss_alpha": trial.suggest_float("focal_loss_alpha", 0.05, 0.6),
"num_candidate_attributes_ratio": trial.suggest_float(
"num_candidate_attributes_ratio", 0.05, 0.95
),
"shrinkage": trial.suggest_float("shrinkage", 0.01, 0.9),
"early_stopping_num_trees_look_ahead": 50,
"num_trees": 2000,
}
model=tfdf.keras.GradientBoostedTreesModel(**params)
model.fit(train_dataset, validation_data=val_dataset, verbose=0)
preds=model.predict(val_dataset).ravel()
ap=average_precision_score(val_data[TARGET], preds)
returnap
study=optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)
这些参数中的大多数对于gbt来说是相当标准的,但也有一些值得注意的参数:
- 将growing_strategy更改为BEST_FIRST_GLOBAL(又称为按叶生长),这是LightGBM使用的策略。
- 使用BINARY_FOCAL_LOSS,它应该对不平衡的数据集更好。
- 更改split_axis参数以使用 sparse oblique splits,这在论文中证明是非常有效的。
- 使用honest参数构建“honest trees”。
可以看到使用最佳参数获得的结果,自定义永远要比自动的好。
GBT with Custom Tuned Parameters
PR AUC: 0.8666
ROC AUC: 0.9631
现在我们已经确定了超参数,可以重新训练模型并继续进行我们的工作。
模型检验
TFDF提供了一个很好的实用工具来检查经过训练的模型,称为Inspector,他有3个主要用途:
- 检查模型的属性,如类型,树的数量或使用的特征
- 获取特性的重要性
- 提取树结构
1、检查模型属性
inspector类存储了模型各种属性:模型类型(GBT或RF)、树的数量、训练目标以及用于训练模型的特征等等
inspector = manual_tuned.make_inspector()
print("Model type:", inspector.model_type())
print("Number of trees:", inspector.num_trees())
print("Objective:", inspector.objective())
print("Input features:", inspector.features())
或者使用
manual_tuned.summary()
来更详细地查看模型。
2、特征的重要性
像所有其他库一样,TFDF带有内置的特性重要性评分。对于gbt,可以访问NUM_NODES, SUM_SCORE, INV_MEAN_MIN_DEPTH, NUM_AS_ROOT方法。需要注意的是,可以在训练期间将compute_permutation_variable_importance参数设置为True,这将添加一些额外的方法,但是模型的训练速度会慢。
defplot_tfdf_importances(
inspector: tfdf.inspector.AbstractInspector, importance_type: str
):
"""Extracts and plots TFDF importances from the given inspector object
Args:
inspector (tfdf.inspector.AbstractInspector): inspector object created from your TFDF model
importance_type (str): importance type to plotß
"""
try:
importances=inspector.variable_importances()[importance_type]
exceptKeyError:
raiseValueError(
f"No {importance_type} importances found in the given inspector object"
)
names= []
scores= []
forfinimportances:
names.append(f[0].name)
scores.append(f[1])
sns.barplot(x=scores, y=names, color="#5a7dbf")
plt.xlabel(importance_type)
plt.title("Variable Importance")
plt.show()
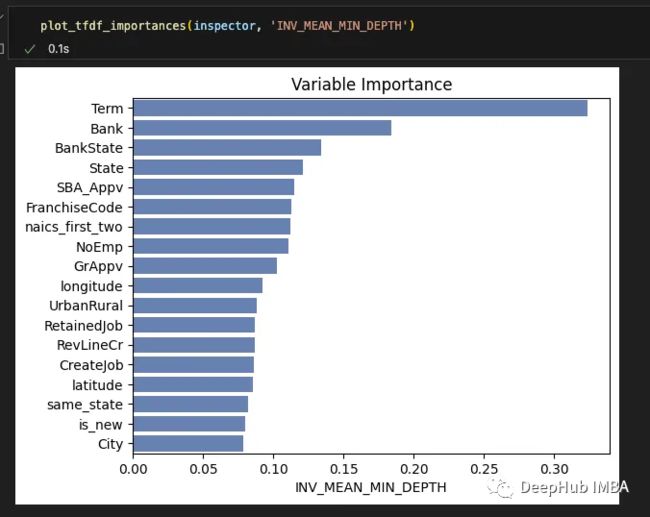
可以看到,Term变量一直是最重要的特征,紧随其后的是Bank、State和Bank State等类别变量。但是TFDF库最大的缺点之一是不能使用SHAP,这样可解释性的查看就有一些不方便。
3、检查树的结构
为了解释或模型验证,我们希望查看单个树。TFDF可以方便地访问所有树。比如GBT模型的第一棵树,因为它通常是信息量最大的树。
first_tree=inspector.extract_tree(tree_idx=0)
print(first_tree.pretty())
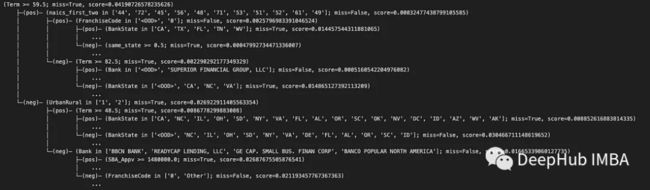
当处理较大的树时,使用print语句检查它们不太方便。TFDF提供了一个树绘图工具——TFDF .model_plotter
withopen("plot.html", "w") asf:
f.write(tfdf.model_plotter.plot_model(manual_tuned, tree_idx=0, max_depth=4))

这样就方便很多了。
TF Serving
我们已经对模型进行了训练、调优和评估。最后的一个工作就是部署了,这部分也很简单,因为TFDF是官方的,必然会支持TF Serving。如果已经有了一个TF服务实例,那么所需要做的就是在model_base_path参数中指向要发布的模型。
首先就是保存我们的模型:
manual_tuned.save("../models/loan_default_model/1/")
然后就是在本地安装TF services,并使用正确的参数启动它。
./tensorflow_model_server \
--rest_api_port=8501 \
--model_name=loan_default_model \
--model_base_path=/path/models/loan_default_model/1
这里的model_base_path一定要是绝对路径。在TF服务服务器启动后,就可以开始接收请求了。有两种预期的格式——实例和输入。
# Input data formatted correctly
data= {
"Bank": ["Other"],
"BankState": ["TN"],
"City": ["Other"],
"CreateJob": [12.0],
"FranchiseCode": ["0"],
"GrAppv": [14900000.0],
"NoEmp": [28.0],
"RetainedJob": [16.0],
"RevLineCr": ["N"],
"SBA_Appv": [14900000.0],
"State": ["TN"],
"Term": [240.0],
"UrbanRural": ["0"],
"is_new": [0.0],
"latitude": [35.3468],
"longitude": [-86.22],
"naics_first_two": ["44"],
"same_state": [1.0],
"ApprovalFY": [1]
}
payload= {"inputs": data}
# Send the request
url='http://localhost:8501/v1/models/default_model:predict'
response=requests.post(url, json=payload)
# Print out the response
print(json.loads(response.text)['outputs'])
# Expected output: [[0.0138759678]]
返回的json串就包含了模型的预测结果。
总结
经过了2年的测试,TFDF终于发布正式版了。它是在TensorFlow中基于训练树的模型的一个强大且可扩展的库。TFDF模型与TensorFlow生态系统的其他部分很好地集成在一起,所以如果你正在使用TFX,在生产中有其他TF模型,或者正在使用TF服务,你会发现这个库非常有用。
本文的代码部分并不完全,如果你想自己探索,可以在这里下载完成的代码和数据集:
https://avoid.overfit.cn/post/db8eeaae665f410f90111b4ca0017b94
作者:Antons Tocilins-Ruberts