超详细的堆排序,进来看看吧。
1.堆的基本概念
1.1什么是堆
堆是一种叫做完全二叉树的数据结构,
1.2大堆和小堆
大堆:每个节点的值都大于或者等于他的左右孩子节点的值
小根堆:每个结点的值都小于或等于其左孩子和右孩子结点的值
1.3完全二叉树节点之间的关系
leftchild = parent*2 + 1
rightchild = parent*2 + 2
parent = (child - 1) / 2
1.4堆这个数据结构的实现
heap.h//需要实现的功能列表
#pragma once
#include
#include
#include
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
heap.c
堆的向上调整和向下调整
(只能处理一次,创建大小堆的时候需要反复调用)
void Swap(HPDataType* x1, HPDataType* x2)
{
HPDataType tmp = *x1;
*x1 = *x2;
*x2 = tmp;
}
void AdjustDown(HPDataType* a, int n, int root)//孩子不断向下
{
int parent = root;
int child = parent * 2 + 1;//初始化成左孩子
while (child < n)
{
// 选左右孩纸中大的一个
if (child + 1 < n
&& a[child + 1] > a[child])
{
++child;
}
//如果孩子大于父亲,进行调整交换
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void AdjustUp(HPDataType* a, int n, int child)//孩子不断向上
{
int parent;
assert(a);
parent = (child - 1) / 2;
while (child > 0)
{
//如果孩子大于父亲,进行交换
if (a[child] > a[parent])
{
Swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
定义出堆的数据结构
typedef int HPDataType;
typedef struct Heap
{
HPDataType* arr;
int size;
int capacity;
}Heap;初始化一个堆
void HeapInit(Heap* hp, HPDataType* a, int n)
{
int i;
assert(hp && a);
hp->arr = (HPDataType*)malloc(sizeof(HPDataType) * n);
hp->size = n;
hp->capacity = n;
for (i = 0; i < n; ++i)
{
hp->arr[i] = a[i];
}
// 建堆: 从最后一个非叶子节点开始进行调整
// 最后一个非叶子节点,按照规则: (最后一个位置索引 - 1) / 2
// 最后一个位置索引: n - 1
// 故最后一个非叶子节点位置: ((n - 1) / 2)-1
for (i = (n - 2) / 2; i >= 0; --i)
{
AdjustDown(hp->arr, hp->size, i);
}
//for (i = 1; i < n; i++)
//{
// AdjustUp(hp->arr,hp->size, i);
//}
}// 建堆: 从最后一个非叶子节点开始进行调整
// 最后一个非叶子节点,按照规则: (最后一个位置索引 - 1) / 2
// 最后一个位置索引: n - 1
// 故最后一个非叶子节点位置: ((n - 1) / 2)-1
我们向下调整来建堆时,要保证当前要调整的节点的左右子树都已经是堆后,才可以向下调整。所以我们要从倒数第一个非叶子结点开始调整
向上调整来建立堆的时候,要保证要调整的节点前面已经是一个合法的堆才行——为了达到这个目的,我们在向上建堆的时候,就需要从数组的第二个元素开始
堆的插入和删除
我们需要注意的是插入删除后我们仍需保持调整后的数组仍是一个堆
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
//检查容量
if (hp->size == hp->capacity)
{
hp->capacity *= 2;
hp->arr = (HPDataType*)realloc(hp->arr, sizeof(HPDataType) * hp->capacity);
}
//尾插
hp->arr[hp->size] = x;
hp->size++;
//向上调整
AdjustUp(hp->arr, hp->size, hp->size - 1);//因为数据插在尾向不会打乱已有关系,可以直接向上调整
}
void HeapPop(Heap* hp)
{
assert(hp);
//交换
Swap(&hp->arr[0], &hp->arr[hp->size - 1]);
hp->size--;
//向下调整
AdjustDown(hp->arr, hp->size, 0);
}
HPDataType HeapTop(Heap* hp)
{
assert(hp);
return hp->arr[0];
}
int HeapSize(Heap* hp)
{
return hp->size;
}
int HeapEmpty(Heap* hp)
{
return hp->size == 0 ? 0 : 1;
}
void HeapPrint(Heap* hp)
{
int i;
for (i = 0; i < hp->size; ++i)
{
printf("%d ", hp->arr[i]);
}
printf("\n");
}堆的插入,因为数据插在尾向不会打乱已有关系,可以直接向上调整。
堆的删除,因为是删除堆顶的数据,为了防止打乱已有关系,交换数据后向下调整,构建一个新的堆。
测试test.c
void test(void)
{
Heap hp;
int arr[] = { 0,4,13,45,32,45,2,56,33,32 };
HeapInit(&hp, arr, sizeof(arr) / sizeof(arr[0]));
HeapPrint(&hp);
}
int main()
{
test();
//TestHeap1();
}2.向上调整建堆和向下调整建堆的区别
2.1向上调整建堆
时间复杂度计算的是其调整的次数,根据上文的知识我们已经知晓其是从数组的第二个元素开始的,也就是可以理解为第二层的第一个节点。计算的思想非常简单:计算每层有多少个节点乘以该层的高度次,然后累计相加即可。

2.2向下调整建堆
向下调整我们前面已经知道它是从倒数第1个非叶节点开始调整的
每层的调整次数为:该层的节点个数*该层高度减1
一直从倒数第2层开始调直至第1层,并将其依次累加,累加的计算过程和向上调整差不多,都是等比*等差的求和,(但不同的是:每层的调整次数不同)

3.堆的应用
2.1堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:每个结点的值都大于等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于等于其左右孩子结点的值,称为小顶堆。该算法时间复杂度为O(n log n)。
堆排序算法的原理如下:
1.将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
2.将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
3.由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
void HeapSort(Heap* hp, int n)
{
// 向上调整建堆 -- N*logN
/*for (int i = 1; i < n; ++i)
{
AdjustUp(a, i);
}*/
// 向下调整建堆 -- O(N)
// 升序:建大堆,把最大的依次拿到下面去
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(hp->arr, n, i);
}
// O(N*logN)
int end = n - 1;
while (end > 0)
{
Swap(&hp->arr[end],&hp->arr[0]);
AdjustDown(hp->arr, end, 0);
--end;
}
}2.2 topK问题
从n个数据中选出排在前k个的数据。
建一个小堆,堆里假设就是前k个数据,如果有比堆顶大的数据则弹出堆顶数据,在插入新的数据,然后向下调整堆,得到新的小堆,如此往复,直到读完n个数据。
//1. 找最大的K个元素
//假设堆为小堆
void PrintTopK(int* a, int n, int k)
{
Heap hp;
//建立含有K个元素的堆
HeapInit(&hp, a, k);
for (size_t i = k; i < n; ++i) // N
{
//每次和堆顶元素比较,大于堆顶元素,则删除堆顶元素,插入新的元素
if (a[i] > HeapTop(&hp)) // LogK
{
HeapPop(&hp);
HeapPush(&hp, a[i]);
}
}
for(int i = 0; i < k; ++i){
printf("%d ",HeapTop(&hp));
HeapPop(&hp);
}
}
//2. 找最小的K个元素
//假设堆为大堆
void PrintTopK(int* a, int n, int k)
{
Heap hp;
//建立含有K个元素的堆
HeapInit(&hp, a, k);
for (size_t i = k; i < n; ++i) // N
{
//每次和堆顶元素比较,小于堆顶元素,则删除堆顶元素,插入新的元素
if (a[i] < HeapTop(&hp)) // LogK
{
HeapPop(&hp);
HeapPush(&hp, a[i]);
}
}
for(int i = 0; i < k; ++i){
printf("%d ",HeapTop(&hp));
HeapPop(&hp);
}
}用大数据测一下
void TestTopk()
{
int n = 1000000;
int* a = (int*)malloc(sizeof(int) * n);
srand(time(0));
//随机生成10000个数存入数组,保证元素都小于1000000
for (size_t i = 0; i < n; ++i)
{
a[i] = rand() % 1000000+1000000;
}
//确定10个最大的数
a[5] = 1;
a[1231] = 2;
a[531] = 3;
a[5121] = 4;
a[115] = 5;
a[2335] = 6;
a[9999] = 7;
a[76] = 8;
a[423] = 9;
a[3144] = 10;
PrintTopK(a, n, 10);
}
int main()
{
test();
//TestHeap1();
TestTopk();
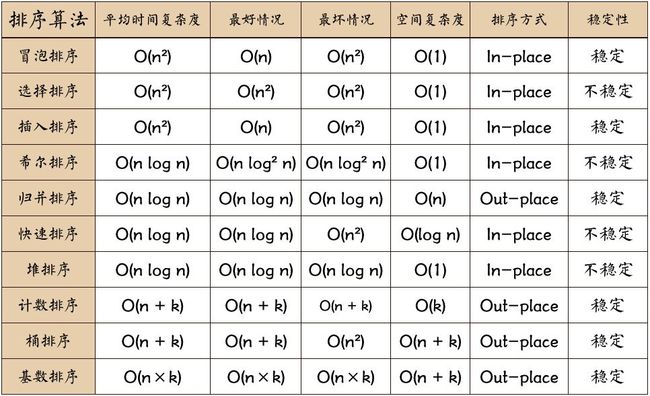
}4.附带一张排序算法的表(仅供参考)