数据采集
XPath,XML路径语言的简称。XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPath主要用于解析XML文档,可以用来获取XML文档中某个元素的位置、属性值等信息。XPath可以用于XML文档解析、XML数据抽取、XML路径匹配等方面。
发送请求
首先,我们要进行数据来源分析,知道我们的需求是什么?
明确需求:
- 明确采集网站是什么?
- 明确采集数据是什么?
车辆基本信息
然后,我们分析车辆基本信息数据, 具体是请求那个网址可以得到我们想要的数据。
通过开发者工具, 进行抓包分析:
打开开发者工具: F12 / 鼠标右键点击检查选择network
刷新网页: 让本网页数据内容重新加载一遍 <方便分析数据出处>
搜索数据来源: 复制你想要的内容, 进行搜索即可
import requests
url = 'https://www.che168.com/china/a0_0msdgscncgpi1ltocsp1exx0/'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,headers=headers)
我们和之前一样,获取数据,我们会发现,车辆的基本信息就在网页源代码中,我们今天就用xpath的方法来解析数据。
解析数据
接下来,我们用xpath解析数据。我们用开发者工具定位到标签位置。
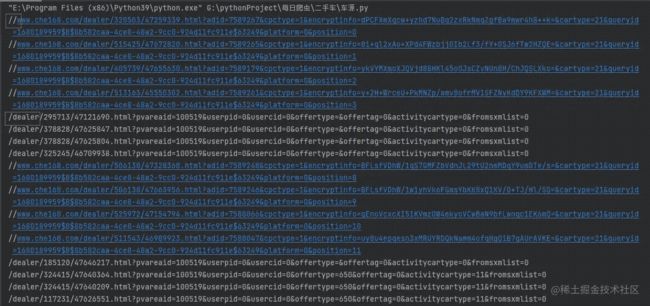
我们通过网页源代码,我们可以获取到每一个网页的url。
selector=parsel.Selector(res.text)
detail_url_list = selector.xpath('//ul[@class="viewlist_ul"]/li/a[@class="carinfo"]/@href').getall()
我们可以看到,得到下面数据。
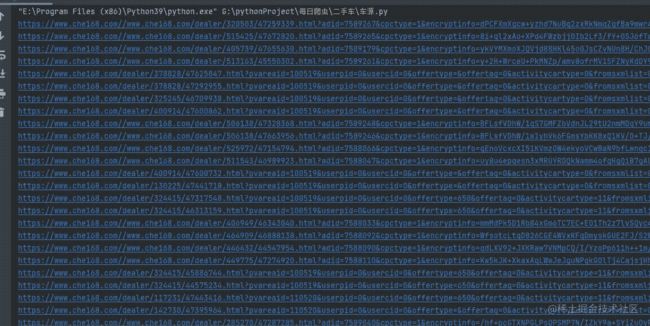
我们会发现,我们得到了两种网页,所以,在这里我们拼接网页就需要注意,这里,我不多说,直接看我是怎么写的。
if detail_url.split('/') == '':
detail_url = 'https:'+detail_url
else:
detail_url = 'https://www.che168.com'+detail_url
这样,我们就得到了每一个车辆信息的数据网页,看看运行之后的效果吧。
接下来,我们就依次访问某个链接,获取我们想要的数据。
responses = requests.get(detail_url,headers=headers)
detail_selector = parsel.Selector(responses.text)

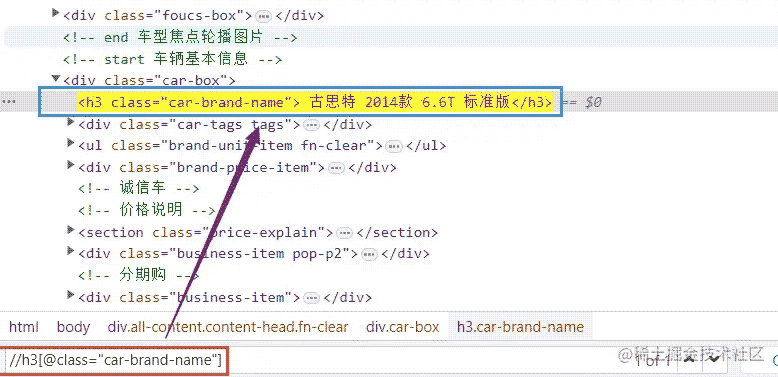
我用不同颜色标注的,就是我们这次想要获取的数据,我们这里以车辆名称为例,讲解下path如何写。
title = detail_selector.xpath('string(//h3[@class="car-brand-name"])').get("").strip()
我们看看网页源代码是如何得到的xpath。
可能有人就要问了,这个
("").strip()
是什么意思?这个就是去除空格的,只是为了后期数据的美观。
后面的我就不一一展示了,我直接放代码了,不懂的在评论区交流。
tableShowMileage = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[1]/h4/text()').get("").strip()
theRegistrationTime = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[2]/h4/text()').get("").strip()
blockADisplacement = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[3]/h4/text()').get("").strip()
addr = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[4]/h4/text()').get("").strip()
guobiao = detail_selector.xpath('//ul[@class="brand-unit-item fn-clear"]/li[5]/h4/text()').get("").strip()
price = detail_selector.xpath('string(//span[@id="overlayPrice"])').get()
我们打印这些数据,看看效果吧。

可能大家注意到了,有返回空值的,这个可能就是被反爬,大家感兴趣可以用代理IP试试。
保存数据
和我们上一篇一样,我们先写入字典,然后在写入csv文件里面。
dit ={
'车辆':title,
'表显里程':tableShowMileage,
'上牌时间':theRegistrationTime,
'挡位/排量':blockADisplacement,
'车辆所在地':addr,
'查看限迁地':guobiao,
'价格':price,
}
csv_writer.writerow(dit)
大家感兴趣还可以获取车辆信息更详细的数据,其实原理都是一样的。
总结
通过本文的学习,我们学习了数据采集。我们在采集数据的时候,遇到各种问题,自己在尝试解决问题,也是在一种学习,本次实战,我们明白如何使用xpath解析数据。
以上就是Python采集二手车数据的超详细讲解的详细内容,更多关于Python采集二手车数据的资料请关注脚本之家其它相关文章!