mysql架构浅析
前言
mysql作为当前比较流行的开源关系型数据库之一,想必在很多公司中都有使用。今天这边文章我来和大家一起探讨下mysql的整体构架,让大家在宏观上能大致了解mysql
mysql架构图
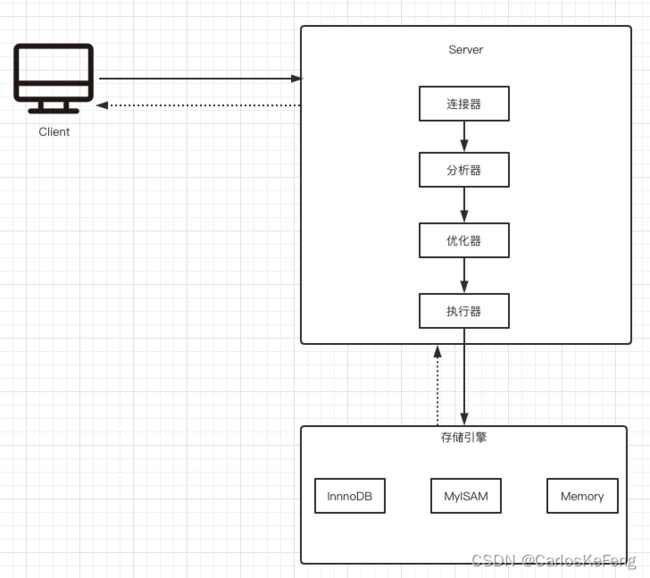
如上图所示,mysql内部大体分为Server层和存储引擎层
其中Server层:
- 连接器
管理Client连接,同时还可以处理Client的权限验证等问题
- 分析器
对Client的SQL语法进行合法性分析
- 优化器
生成SQL执行计划,选择索引等
- 执行器
与存储引擎进行交互,获取SQL操作结果
存储引擎层:
mysql目前提供的存储引擎有三种
- InnoDB
- MyISAM
- Memory
最常用的是InnoDB引擎(主要是因为它支持事务),在Mysql5.5.5之后也成为了默认的存储引擎
Server层详解
连接器
当我们使用客户端连接mysql服务时(其他IDE工具也是同理),
mysql -uxxx -hxxx -pxxx
Server层的连接器会处理你的请求,连接器会校验权限,并维护与客户端创建的连接。
一旦一个客户端成功建立连接后,及时管理员修改了该User的权限。这对当前已经创建的连接是没有影响的,只会影响到新建的连接中。
你可以使用以下命令查看当前创建的连接:
show processlist;
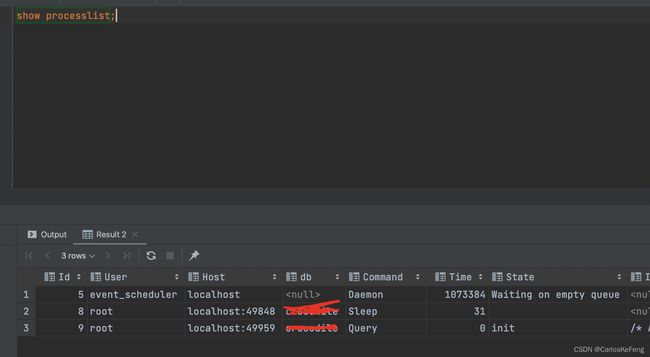
我们可以看到结果栏中有一个state字段,其中有一行的记录为Sleep。
当客户端建立连接后如果没有后续的操作,那么改连接会处于空闲状态,也就是我们查询结果的state的值为:Sleep
当客户端长时间未使用该连接(未与mysql服务进行通信),连接器会将该连接断开。这个时间是可配置的,配置参数是:wait_timeout(默认是8小时)。
当连接被连接器关闭时,客户端是无法感知的。这个时候如果客户端使用了一个已经被关闭的连接来请求mysql时,连接器会抛出「lost connection xxxxx」异常。
分析器
当客户端与mysql成功建立连接后,客户端向mysql发送请求(查询,新增啥的)。我们这里以查询为例,mysql会在查询缓冲中查看该查询语句是否存在查询缓存中(key为该查询sql,value为查询的结果)。如果查询缓冲中有命中则直接将结果返回给客户端,反之该查询请求会经过分析器进行处理。
分析第一步需要知道你要干什么:
也就是分析你的行为是select还是update等
第二步就是check你这样干的方式对不对:
也就是分析你的sql语法是否正确
select * form job_log limit 10;
注意这里我故意把from协程了form,我们可以查看分析器给我们返回的错误:
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘form job_log limit 10’ at line 1
这里我把需要我们重点关注的内容加粗和斜体标注出来了,以后遇到错误时其实你可以直接定位到「use near」后面的内容进行排查即可
优化器
当分析器成功处理完成后,请求会到达优化器进行处理。
优化器所做的工作就是根据你当前查询的SQL语句来看下当前查询请求的该使用哪些索引,并最终选择合理的查询方案。所以你经常会发现你的sql语句被mysql给改写了,那是因为优化器在其中起了作用
执行器
当优化器处理完毕后,请求会继续流转从到到达执行器。执行器会check当前连接的用户是否具有查询该表的权限。校验通过后,执行器会根据当前表使用的存储引擎来调用存储引擎提供的接口来查询数据,这里我们以InnoDB举例
select * from job_log where id = 10;
假设 job_log 表中id是主键索引(聚簇索引),并且使用的是B+ tree。那么这条查询语句执行的逻辑是:
执行器调用InnoDB提供的接口进行查询,InnoDB将满足条件的一行记录进行返回(主键索引,叶子节点中会存储这一行的记录。所以不会像普通索引那样还会回表进行查询)。由于是主键索引,索引就不会在继续调用存储引擎的接口获取下一行的数据。