hbase进阶操作——读流程与写流程介绍
系列文章目录
centos7虚拟机下hbase的使用案例讲解
文章目录
系列文章目录
一、hbase架构原理
1.1、StoreFile
1.2、MemStore
1.3、WAL
二、hbase的写流程
2.1、写流程的流程图
2.2、写流程的流程图说明
三、hbase读流程
3.1、读流程的流程图
3.2、读流程的流程图解释
四、zookeeper客户端查看hbase的meta表的步骤
4.1、查看zookeeper客户端
4.2、查看根目录
4.3、查看hbase文件夹
4.4、查看meta-region-server内容
五、hbase客户端
5.1、加入hbase客户端编辑
5.2、查看hbase:meta信息
5.3、meta表的条目介绍
5.4、在Hadoop的界面查看log日志文件
前言
本文主要介绍hbase的写和读流程,以及zookeeper在客户端查看hbase的meta内容。本文案例仅供参考。
一、hbase架构原理

1.1、StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有
一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
1.2、MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好
序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
1.3、WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的
概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件
中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重
建。
二、hbase的写流程
2.1、写流程的流程图

2.2、写流程的流程图说明
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据写请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
三、hbase读流程
3.1、读流程的流程图

3.2、读流程的流程图解释
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将
查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不
同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到
Block Cache。
6)将合并后的最终结果返回给客户端。
四、zookeeper客户端查看hbase的meta表的步骤
4.1、查看zookeeper客户端
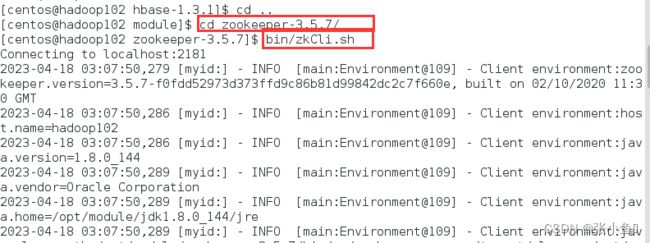
4.2、查看根目录
![]()
4.3、查看hbase文件夹

4.4、查看meta-region-server内容

五、hbase客户端
此处小编的master节点是103
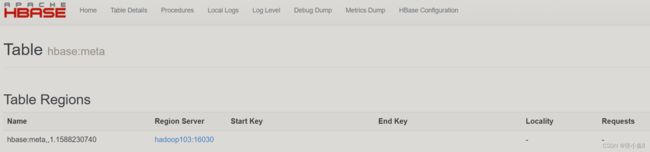
退出zookeeper客户端:quit

5.1、加入hbase客户端
5.2、查看hbase:meta信息
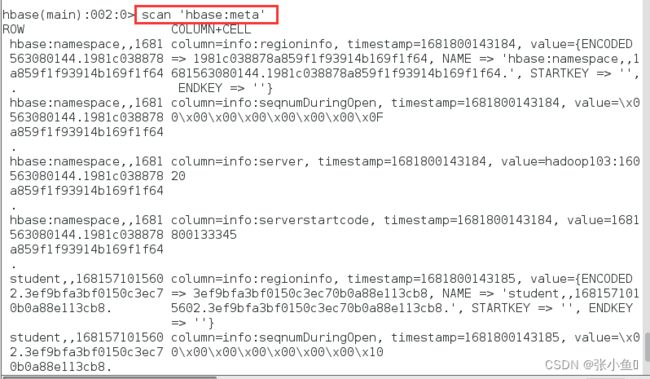
对meta表内容的解释:
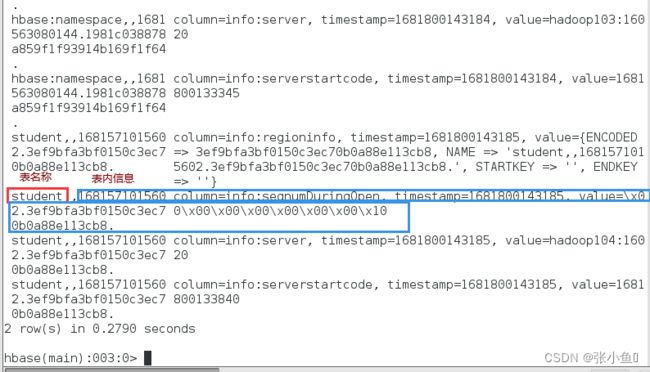
5.3、meta表的条目介绍
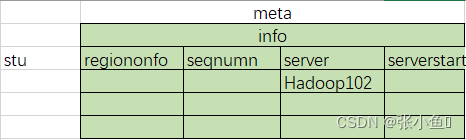
flash +表即可以将hbase的内容写入,不写入数据还是在内存当中
5.4、在Hadoop的界面查看log日志文件


从这里可以看到文件在三个节点都存储了,所以即便一个节点数据丢失,对其他结点的影响也很小,可以恢复过来

总结
以上就是hbase的进阶内容,
最后欢迎大家点赞,收藏⭐,转发,
如有问题、建议,请您在评论区留言哦。