TI在物联网和AI边缘计算中落伍了吗?
摘要:本文介绍一下TI在边缘计算工作中所做的努力。

发明“人工智能”这个term的老头儿也不会想到人工智能在中国有多火。
不管是懂还是不懂,啥东西披上“人工智能“的面纱都能瞬间成为大项目。
学习AI 的年轻人认识NVIDIA,可能不太知道DSP是啥玩意儿了。
我们上学那会,NVIDIA仅仅是”显卡“代名词而已,DSP是绝对的天花板。
现在,貌似DSP都赶不上FPGA了,因为FPGA加速AI应用好像更快一点。
不过,TI没有沉睡,相信下一次的浪潮会是他引领。
我的理由比较简单--乘法比加法更需要实力(大家意会)。
1.TI想让AI模型在自己的DSP上跑一跑
AI最重要的就是模型,这个面纱不揭开,大家都以为神圣的不得了,本文也不揭开它,让它继续神圣。通用AI才是集模型之大成,通用AI取得飞跃之前,尤其是能够拜托超级计算能力之前,现在仍然处于一个相对不那么高的阶段。为了模仿人类学习的过程,大家用一大堆服务器,一大堆GPU(很贵,一般我们购买云服务)从一大堆数据中训练出来一个模型,那么这个模型可以对你想要的事情进行分类或者回归(根本上来说,它俩应该是统一的)。比如你让这个模型分辨一下输入的一张图片中的动物是猫还是狗。
当然这只是初级的模型,要想实现ChatGPT等通用模型,那么所需要的硬件和数据就更多更多了。
但是根本上还是模型。
有的模型就很小,或者不太大,体积恰好可以放进”边缘计算“设备。例如华为的Atlas 500,或者很多厂家声称的Jetson XXX,这些设备可以跑一跑训练好的“模型”。
那么TI DSP呢?也能够跑一跑。
我想说的是,边缘计算跑一个模型浪费不?
在古老的嵌入式系统领域,崇尚的是“够用就好”,在AI时代,好像不怎么提了。
功耗?成本?统统不用考虑,因为跟其他开支相比,这个根本就不是个事。
其实AI时代需要冷静一下,尽管AI寒冬的时候,那几个坚持下来的老头儿的确是非常值得尊敬的。我们需要考虑,AI怎么样才能为我们带来最合适的科技舒适感。并不是说,处处都有人脸识别,每个汽车都装一个激光雷达,我们的生活就一下子提升到了24小时都是幸福指数拉满的水平。毕竟我们只是一个时代的沙尘而已。
以前大家开玩笑说,汽车时速表上的一大部分空间是没有用过的,现在可以说,自动驾驶也没有太多人敢于彻底放松地上车就享受它们。
arduino有一款板子,也可以跑简单的AI模型,例如识别简单的语音指令。
TI也有。它想实现的是把模型放在这个DSP上来执行。看上去它并不太像是一个DSP,而是一个ARM内核的CPU而已。

有一篇技术文章讲述了如何这么做
https://www.ti.com.cn/cn/lit/an/zhcabs1/zhcabs1.pdf?ts=1681788583275&ref_url=https%253A%252F%252Fwww.ti.com.cn%252Fproduct%252Fcn%252FTDA4VM

2.具有深度学习、视觉功能和多媒体加速器的双核 Arm® Cortex®-A72 SoC 和 C7x DSP
它是名字叫做TDA4VM
具有深度学习、视觉功能和多媒体加速器的双核 Arm® Cortex®-A72 SoC 和 C7x DSP
适用于 L2、L3 和近场分析系统且采用深度学习的汽车片上系统
可以运行Linux, QNX, RTOS
硬件上,有1 Deep learning accelerator, 1 Depth and Motion accelerator, 1 Vision Processing accelerator, 1 video encode/decode accelerator
2 个Arm Cortex-A72核

性能强大,但是怎么看怎么像是迎合AI应用所做。
比如它可以做环视泊车,我们叫做全景影像。可是似乎这也没啥,现在街上的车辆,带全景影像的好像很多,解决方案并不一定用的的TI的。

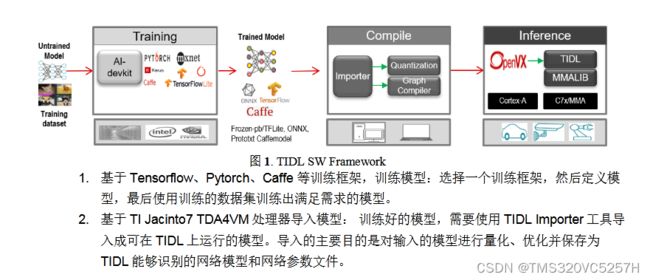
3.TI的边缘云计算[1]
如果在没有嵌入式处理器供应商提供的合适工具和软件的支持下,既想设计高能效的边缘人工智能(AI)系统,同时又要加快产品上市时间,这项工作难免会冗长乏味。面临的一系列挑战包括选择恰当的深度学习模型、针对性能和精度目标对模型进行训练和优化,以及学习使用在嵌入式边缘处理器上部署模型的专用工具。从模型选择到在处理器上部署,TI可免费提供相关工具、软件和服务,为您深度神经网络(DNN)开发工作流程的每一步保驾护航。
第1步:选择模型
边缘AI系统开发的首要任务是选择合适的DNN模型,同时要兼顾系统的性能、精度和功耗目标。GitHub上的TI边缘AI Model Zoo等工具可助您加速此流程。
Model Zoo广泛汇集了TensorFlow、PyTorch和MXNet框架中常用的开源深度学习模型。这些模型在公共数据集上经过预训练和优化,可以在TI适用于边缘AI的处理器上高效运行。TI会定期使用开源社区中的新模型以及TI设计的模型对Model Zoo进行更新,为您提供性能和精度经过优化的广泛模型选择。
Model Zoo囊括数百个模型,TI模型选择工具(如图2所示)可以帮助您在不编写任何代码的情况下,通过查看和比较性能统计数据(如推理吞吐量、延迟、精度和双倍数据速率带宽),快速比较和找到适合您AI任务的模型。

第2步:训练和优化模型
选择模型后,下一步是在TI处理器上对其进行训练或优化,以获得出色的性能和精度。凭借我们的软件架构和开发环境,您可随时随地训练模型。
从TI Model Zoo中选择模型时,借助训练脚本可让您在自定义数据集上为特定任务快速传输和训练模型,而无需花费较长时间从头开始训练或使用手动工具。训练脚本、框架扩展和量化感知培训工具可帮助您优化自己的DNN模型。
第3步:评估模型性能
在开发边缘AI应用之前,需要在实际硬件上评估模型性能。
TI提供灵活的软件架构和开发环境,您可以在TensorFlow Lite、ONNX RunTime或TVM和支持Neo AI DLR的SageMaker Neo运行环境引擎三者中选择习惯的业界标准Python或C++应用编程接口(API),只需编写几行代码,即可随时随地训练自己的模型,并将模型编译和部署到TI硬件上。在这些业界通用运行环境引擎的后端,我们的TI深度学习(TIDL)模型编译和运行环境工具可让您针对TI的硬件编译模型,将编译后的图或子图部署到深度学习硬件加速器上,并在无需任何手动工具的情况下实现卓越的处理器推理性能。
在编译步骤中,训练后量化工具可以自动将浮点模型转换为定点模型。该工具可通过配置文件实现层级混合精度量化(8位和16位),从而能够足够灵活地调整模型编译,以获得出色的性能和精度。
不同常用模型的运算方式各不相同。同样位于GitHub上的TI边缘AI基准工具可帮助您为TI Model Zoo中的模型无缝匹配DNN模型功能,并作为自定义模型的参考。
评估TI处理器模型性能的方式有两种:TDA4VM入门套件评估模块(EVM)或TI Edge AI Cloud,后者是一项免费在线服务,可支持远程访问TDA4VM EVM,以评估深度学习推理性能。借助针对不同任务和运行时引擎组合的数个示例脚本,五分钟之内便可在TI硬件上编程、部署和运行加速推理,同时收集基准测试数据。
第4步:部署边缘AI应用程序
您可以使用开源Linux®和业界通用的API来将模型部署到TI硬件上。然而,将深度学习模型部署到硬件加速器上只是难题的冰山一角。
为帮助您快速构建高效的边缘AI应用,TI采用了GStreamer框架。借助在主机Arm®内核上运行的GStreamer插件,您可以自动将计算密集型任务的端到端信号链加速部署到硬件加速器和数字信号处理内核上。

下图是一个视频的应用

4.DSP还有机会吗?
FPAG的结构特点
片内有大量的逻辑门和触发器,多为查找表结构,实现工艺多为SRAM。规模大,集成度高,处理速度快,执行效率高。能完成复杂的时序逻辑设计,且编程灵活,方便,简单,可多次重复编程。许多FPAG可无限重复编程。利用重新配置可减少硬件的开销
DSP作为专门的微处理器,主要用于计算,优势是软件的灵活性。适用于条件进程,特别是复杂的多算法任务。采用数据和程序分离的哈佛结构和改进的哈佛结构,执行指令速度更快。独立的累加器及加法器,一个周期内可同时完成相乘及累加运算。
我们知道,AI算法的核心就是大量的乘加/乘累加。再传统的FPGA中乘累加是依靠DSP模块实现的。为了追求较高的灵活性,普通的DSP模块就是一个或者两个乘法器,外加一个加法器构成。这样就可以基于这种基本的DSP模块配合FPGA的其它部分构成各种不同的运算算法。
但AI运算不是一般的乘加,而是一种“张量”运算。简单的说就是一组数据先乘后加,乘加之间还有级联。因此提升FPGA执行AI算法的最好方法自然就是把DSP模块升级为更加适应AI张量运算的模块。
大量的乘法器,不同模块之间的级联通道,以及对应的加法。这非常符合张量运算先乘后加,多维运算的运算过程。这样让底层运算结构与算法高度匹配,就可以保证算法的执行效率。
DSP的先天优势就是哈弗总线,以及单周期执行乘加操作。
尽管人工智能目前所需的计算是“张量”,但是从它的理论提出来初期,就是用一个简单的网络结构来代替的,因此才导致了必须使用特别巨大的计算资源和功耗来实现一个人类小孩就可以完成的分类操作。所以在GPU运行算法发现之前,技术停滞了相当长的一段时间。人类小孩并没有利用身体之外的巨大计算资源来学习就能逐渐成长,所以要想实现比较低的计算资源完成比较复杂的运算在未来的时候也许是可以的。这一点,希望DSP通过结构优化能够帮得上忙。
参考资料:
1.嵌入式边缘AI应用开发简化指南 - 嵌入式处理 - 技术文章 - E2E™ 设计支持
2.为什么不经常看到利用DSP作为机器学习硬件加速器的文章或者新闻? - 知乎
3.人工智能计算领域的领导者 | NVIDIA
4.两大FPGA公司的“AI技术路线”