Inside TSQL Querying - Chapter 1. Logical Query Processing
Logical Query Processing Phases Summary
(8) SELECT (9) DISTINCT (11) <TOP_specification> <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) WITH {CUBE | ROLLUP} (7) HAVING <having_condition> (10) ORDER BY <order_by_list> |
Brief Description of Logical Query Processing Phases Don't worry too much if the description of the steps doesn't seem to make much sense for now. These are provided as a reference. Sections that come after the scenario example will cover the steps in much more detail.
|
1.
|
FROM: A Cartesian product (cross join) is performed between the first two tables in the FROM clause, and as a result, virtual table VT1 is generated.
|
|
2.
|
ON: The ON filter is applied to VT1. Only rows for which the
<join_condition> is TRUE are inserted to VT2.
|
|
3.
|
OUTER (join): If an OUTER JOIN is specified (as opposed to a CROSS JOIN or an INNER JOIN), rows from the preserved table or tables for which a match was not found are added to the rows from VT2 as outer rows, generating VT3. If more than two tables appear in the FROM clause, steps 1 through 3 are applied repeatedly between the result of the last join and the next table in the FROM clause until all tables are processed.
|
|
4.
|
WHERE: The WHERE filter is applied to VT3. Only rows for which the
<where_condition> is TRUE are inserted to VT4.
|
|
5.
|
GROUP BY: The rows from VT4 are arranged in groups based on the column list specified in the GROUP BY clause. VT5 is generated.
|
|
6.
|
CUBE | ROLLUP: Supergroups (groups of groups) are added to the rows from VT5, generating VT6.
|
|
7.
|
HAVING: The HAVING filter is applied to VT6. Only groups for which the
<having_condition> is TRUE are inserted to VT7.
|
|
8.
|
SELECT: The SELECT list is processed, generating VT8. OVER EXPRESSION CAN BE USED HERE
|
|
9.
|
DISTINCT: Duplicate rows are removed from VT8. VT9 is generated.
|
|
10.
|
ORDER BY: The rows from VT9 are sorted according to the column list specified in the ORDER BY clause. A cursor is generated (VC10). OVER EXPRESSION CAN BE USED HERE
|
|
11.
|
TOP: The specified number or percentage of rows is selected from the beginning of VC10. Table VT11 is generated and returned to the caller.
|
Logical Query Processing Phase Details
Step 1: From (Cross Join)
A Cartesian product (a cross join, or an unrestricted join) is performed between the first two tables that appear in the FROM clause, and as a result, virtual table VT1 is generated. VT1 contains one row for every possible combination of a row from the left table and a row from the right table. If the left table contains n rows and the right table contains m rows, VT1 will contain n x m rows. The columns in VT1 are qualified (prefixed) with their source table names (or table aliases, if you specified ones in the query). In the subsequent steps (step 2 and on), a reference to a column name that is ambiguous (appears in more than one input table) must be table-qualified (for example, C.customerid). Specifying the table qualifier for column names that appear in only one of the inputs is optional (for example, O.orderid or just orderid).
More Operators(Tables and Set Operators)
Table Operators
(J) <left_table_expression> <join_type> JOIN <right_table_expression> ON <join_condition>
(A) <left_table_expression> {CROSS | OUTER} APPLY <table_expression>
(P) <left_table_expression> PIVOT (<aggregate_func(<expression>)> FOR <source_col> IN(<target_col_list>)) AS <result_table_alias>
(U) <left_table_expression> UNPIVOT (<target_values_col> FOR <target_names_col> IN(<source_col_list>)) AS <result_table_alias>
Set Operations
SQL Server 2005 supports three set operations: UNION, EXCEPT, and INTERSECT. Only UNION is available in SQL Server 2000. These SQL operators correspond to operators defined in mathematical set theory. This is the syntax for a query applying a set operation:
[(]left_query[)] {UNION [ALL] | EXCEPT | INTERSECT} [(]right_query[)]
[ORDER BY <order_by_list>]
Step 2: ON Filter (Join Condition)
The ON filter is the first of three possible filters (ON, WHERE, and HAVING) that can be specified in a query. The logical expression in the ON filter is applied to all rows in the virtual table returned by the previous step (VT1). Only rows for which the <join_condition> is TRUE become part of the virtual table returned by this step (VT2).
Three-Valued LogicAllow me to digress a bit to cover important aspects of SQL related to this step. The possible values of a logical expression in SQL are TRUE, FALSE, and UNKNOWN. This is referred to as three-valued logic. Three-valued logic is unique to SQL. Logical expressions in most programming languages can be only TRUE or FALSE. The UNKNOWN logical value in SQL typically occurs in a logical expression that involves a NULL (for example, the logical value of each of these three expressions is UNKNOWN: NULL > 42; NULL = NULL; X + NULL > Y). The special value NULL typically represents a missing or irrelevant value. When comparing a missing value to another value (even another NULL), the logical result is always UNKNOWN. Dealing with UNKNOWN logical results and NULLs can be very confusing. While NOT TRUE is FALSE, and NOT FALSE is TRUE, the opposite of UNKNOWN (NOT UNKNOWN) is still UNKNOWN. UNKNOWN logical results and NULLs are treated inconsistently in different elements of the language. For example, all query filters (ON, WHERE, and HAVING) treat UNKNOWN in the same way as FALSE. A row for which a filter is UNKNOWN is eliminated from the result set. On the other hand, an UNKNOWN value in a CHECK constraint is actually treated like TRUE. Suppose you have a CHECK constraint in a table to require that the salary column be greater than zero. A row entered into the table with a NULL salary is accepted, because (NULL > 0) is UNKNOWN and treated like TRUE in the CHECK constraint. A comparison between two NULLs in filters yields an UNKNOWN, which as I mentioned earlier, is treated like FALSEas if one NULL is different than another. On the other hand, UNIQUE and PRIMARY KEY constraints, sorting, and grouping treat NULLs as equal:
In short, it's a good idea to be aware of the way UNKNOWN logical results and NULLs are treated in the different elements of the language to spare you grief. |
Step 3: Adding Outer Rows
This step is relevant only for an outer join. For an outer join, you mark one or both input tables as preserved by specifying the type of outer join (LEFT, RIGHT, or FULL). Marking a table as preserved means that you want all of its rows returned, even when filtered out by the <join_condition>. A left outer join marks the left table as preserved, a right outer join marks the right, and a full outer join marks both. Step 3 returns the rows from VT2, plus rows from the preserved table for which a match was not found in step 2. These added rows are referred to as outer rows. NULLs are assigned to the attributes (column values) of the nonpreserved table in the outer rows. As a result, virtual table VT3 is generated.
Note
| If more than two tables are joined, steps 1 through 3 will be applied between VT3 and the third table in the FROM clause. This process will continue repeatedly if more tables appear in the FROM clause, and the final virtual table will be used as the input for the next step. |
Step 4: Applying the WHERE Filter
The WHERE filter is applied to all rows in the virtual table returned by the previous step. Only rows for which <where_condition> is TRUE become part of the virtual table returned by this step (VT4).
Caution
| Because the data is not grouped yet, you cannot use aggregate filters herefor example, you cannot write WHERE orderdate = MAX(orderdate). Also, you cannot refer to column aliases created by the SELECT list because the SELECT list was not processed yetfor example, you cannot write SELECT YEAR(orderdate) AS orderyear ... WHERE orderyear > 2000. |
A confusing aspect of queries containing an OUTER JOIN clause is whether to specify a logical expression in the ON filter or in the WHERE filter. The main difference between the two is that ON is applied before adding outer rows (step 3), while WHERE is applied after step 3. An elimination of a row from the preserved table by the ON filter is not final because step 3 will add it back; while an elimination of a row by the WHERE filter is final. Bearing this in mind should help you make the right choice.
Tip
| There's a logical difference between the ON and WHERE clauses only when using an outer join. When using an inner join, it doesn't matter where you specify your logical expressions because step 3 is skipped. The filters are applied one after the other with no intermediate step between them. There's one exception that is relevant only when using the GROUP BY ALL option. I will discuss this option shortly in the next section, which covers the GROUP BY phase. |
Step 5: Grouping
The rows from the table returned by the previous step are arranged in groups. Each unique combination of values in the column list that appears in the GROUP BY clause makes a group. Each base row from the previous step is attached to one and only one group. Virtual table VT5 is generated. VT5 consists of two sections: the groups section that is made of the actual groups, and the raw section that is made of the attached base rows from the previous step.
As I mentioned earlier, the input to the GROUP BY phase is the virtual table returned by the previous step (VT4). If you specify GROUP BY ALL, groups that were removed by the fourth phase (WHERE filter) are added to this step's result virtual table (VT5) with an empty set in the raw section. This is the only case where there is a difference between specifying a logical expression in the ON clause and in the WHERE clause when using an inner join. If you revise our example to use the GROUP BY ALL C.customerid instead of GROUP BY C.customerid, you'll find that customer MRPHS, which was removed by the WHERE filter, will be added to VT5's groups section, along with an empty set in the raw section. The COUNT aggregate function in one of the following steps would be zero for such a group, while all other aggregate functions (SUM, AVG, MIN, MAX) would be NULL.
Example:
SELECT COUNT(NULL+1) FROM sys.tables --the result will be 0
SELECT SUM(NULL+1) FROM sys.tables --the result will be NULL
SELECT MIN(NULL+1) FROM sys.tables --the result will be NULL
SELECT MAX(NULL+1) FROM sys.tables --the result will be NULL
SELECT AVG(NULL+1) FROM sys.tables --the result will be NULL
SELECT COUNT(NULL) FROM sys.tables --the result will be an error like operand data type NULL is invalid for count operator
Note
| The GROUP BY ALL option is a nonstandard legacy feature. It introduces many semantic issues when Microsoft adds new T-SQL features. Even though this feature is fully supported in SQL Server 2005, you might want to refrain from using it because it might eventually be deprecated. |
Step 6: CUBE or ROLLUP Option
If CUBE or ROLLUP is specified, supergroups are created and added to the groups in the virtual table returned by the previous step. Virtual table VT6 is generated.(Group by column with CUBE|ROLLUP)
Step 7: HAVING Filter
The HAVING filter is applied to the groups in the table returned by the previous step. Only groups for which the <having_condition> is TRUE become part of the virtual table returned by this step (VT7). The HAVING filter is the first and only filter that applies to the grouped data.
Note
| It is important to specify COUNT(O.orderid) here and not COUNT(*). Because the join is an outer one, outer rows were added for customers with no orders. COUNT(*) would have added outer rows to the count, undesirably producing a count of one order for FISSA. COUNT(O.orderid) correctly counts the number of orders for each customer, producing the desired value 0 for FISSA. Remember that COUNT(<expression >) ignores NULLs just like any other aggregate function. SELECT NULL AS A ,1 AS B INTO #T UNION ALL SELECT 4 AS A ,2 AS B UNION ALL SELECT 2 AS A , 3 AS B SELECT COUNT(A) FROM #T -- Ignores NULLs and the result will be 2 SELECT MAX(A) FROM #T -- Ignores NULLs and the result will be 4 SELECT MIN(A) FROM #T -- Ignores NULLs and the result will be 2 SELECT SUM(A) FROM #T -- Ignores NULLs and the result will be 6 SELECT AVG(A) FROM #T -- Ignores NULLs and the result will be 3, it should be SUM(A)/COUNT(A) |
An aggregate function does not accept a subquery as an inputfor example, HAVING SUM((SELECT ...)) > 10.
SELECT NULL AS A ,1 AS B INTO #T
SELECT (SELECT 1) AS A FROM #T -- the result will be 1
SELECT MAX((SELECT 1)) AS B FROM #T --there will be an error like cannot perform an aggregate function on an expression containing an aggregate or a subquery
SELECT MAX(SUM(1)) AS B FROM #T --there will be an error like cannot perform an aggregate function on an expression containing an aggregate or a subquery
Step 8: SELECT List
Though specified first in the query, the SELECT list is processed only at the eighth step. The SELECT phase constructs the table that will eventually be returned to the caller. The expressions in the SELECT list can return base columns and manipulations of base columns from the virtual table returned by the previous step. Remember that if the query is an aggregate query, after step 5 you can refer to base columns from the previous step only if they are part of the groups section (GROUP BY list). If you refer to columns from the raw section, these must be aggregated. Base columns selected from the previous step maintain their column names unless you alias them (for example, col1 AS c1). Expressions that are not base columns should be aliased to have a column name in the result table for example, YEAR(orderdate) AS orderyear.
Important
| Aliases created by the SELECT list cannot be used by earlier steps. In fact, expression aliases cannot even be used by other expressions within the same SELECT list. The reasoning behind this limitation is another unique aspect of SQL, being an all-at-once operation. For example, in the following SELECT list, the logical order in which the expressions are evaluated should not matter and is not guaranteed: SELECT c1 + 1 AS e1, c2 + 1 AS e2. Therefore, the following SELECT list is not supported: SELECT c1 + 1 AS e1, e1 + 1 AS e2. You're allowed to reuse column aliases only in steps following the SELECT list, such as the ORDER BY stepfor example, SELECT YEAR(orderdate) AS orderyear ... ORDER BY orderyear. |
The concept of an all-at-once operation can be hard to grasp. For example, in most programming environments, to swap values between variables you use a temporary variable. However, to swap table column values in SQL, you can use:UPDATE dbo.T1 SET c1 = c2, c2 = c1;
Logically, you should assume that the whole operation takes place at once. It is as if the table is not modified until the whole operation finishes and then the result replaces the source. For similar reasons, this UPDATE UPDATE dbo.T1 SET c1 = c1 + (SELECT MAX(c1) FROM dbo.T1);
would update all of T1's rows, adding to c1 the maximum c1 value from T1 when the update started. You shouldn't be concerned that the maximum c1 value would keep changing as the operation proceeds because the operation occurs all at once.
Step 9: DISTINCT Clause
If a DISTINCT clause is specified in the query, duplicate rows are removed from the virtual table returned by the previous step, and virtual table VT9 is generated.
Step 10: Applying the ORDER BY Clause
The rows from the previous step are sorted according to the column list specified in the ORDER BY clause returning the cursor VC10. This step is the first and only step where column aliases created in the SELECT list can be reused.
According to both ANSI SQL:1992 and ANSI SQL:1999, if DISTINCT is specified, the expressions in the ORDER BY clause have access only to the virtual table returned by the previous step (VT9). That is, you can sort by only what you select. ANSI SQL:1992 has the same limitation even when DISTINCT is not specified. However, ANSI SQL:1999 enhances the ORDER BY support by allowing access to both the input and output virtual tables of the SELECT phase. That is, if DISTINCT is not specified, in the ORDER BY clause you can specify any expression that would have been allowed in the SELECT clause. Namely, you can sort by expressions that you don't end up returning in the final result set.
Example:
SELECT NULL AS A ,1 AS B,2 AS C INTO #T
SELECT A,B FROM #T ORDER BY C -- That will be working well
SELECT DISTINCT A,B FROM #T ORDER BY C--that will be an error like ORDER BY items must appear in the select list if SELECT DISTINCT is specified.
There is a reason for not allowing access to expressions you're not returning if DISTINCT is specified. When adding expressions to the SELECT list, DISTINCT can potentially change the number of rows returned. Without DISTINCT, of course, changes in the SELECT list don't affect the number of rows returned. T-SQL always implemented the ANSI SQL:1999 approach.
In the ORDER BY clause, you can also specify ordinal positions of result columns from the SELECT list. For example, the following query sorts the orders first by customerid, and then by orderid: SELECT orderid, customerid FROM dbo.Orders ORDER BY 2, 1;
However, this practice is not recommended because you might make changes to the SELECT list and forget to revise the ORDER BY list accordingly. Also, when the query strings are long, it's hard to figure out which item in the ORDER BY list corresponds to which item in the SELECT list.
Important
| This step is different than all other steps in the sense that it doesn't return a valid table; instead, it returns a cursor. Remember that SQL is based on set theory. A set doesn't have a predetermined order to its rows; it's a logical collection of members, and the order of the members shouldn't matter. A query that applies sorting to the rows of a table returns an object with rows organized in a particular physical order. ANSI calls such an object a cursor. Understanding this step is one of the most fundamental things in correctly understanding SQL. |
Usually when describing the contents of a table, most people (including me) routinely depict the rows in a certain order. In depicting the rows one after the other, unintentionally I help cause some confusion by implying a certain order. A more correct way to depict the content of the Customers and Orders tables would be the one shown in Figure 1-1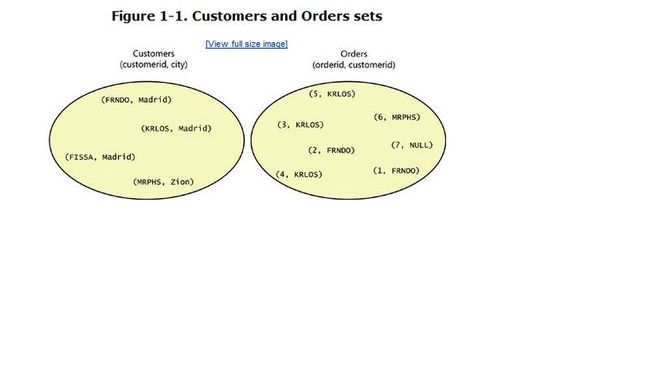
Note
| Although SQL doesn't assume any given order to a table's rows, it does maintain ordinal positions for columns based on creation order. Specifying SELECT * (although a bad practice for several reasons that I'll describe later in the book) guarantees the columns would be returned in creation order. |
Because this step doesn't return a table (it returns a cursor), a query with an ORDER BY clause cannot be used as a table expressionthat is, a view, inline table-valued function, subquery, derived table, or common table expression (CTE). Rather, the result must be returned to the client application that expects a physical record set back. For example, the following derived table query is invalid and produces an error:
SELECT *
FROM (SELECT orderid, customerid
FROM dbo.Orders
ORDER BY orderid) AS D;
Similarly, the following view is invalid:
CREATE VIEW dbo.VSortedOrders AS SELECT orderid, customerid FROM dbo.Orders ORDER BY orderid GO
In SQL, no query with an ORDER BY clause is allowed in a table expression. In T-SQL, there is an exception to this rule that is described in the following stepapplying the TOP option.
So remember, don't assume any particular order for a table's rows. Conversely, don't specify an ORDER BY clause unless you really need the rows sorted. Sorting has a cost SQL Server needs to perform an ordered index scan or apply a sort operator.
The ORDER BY step considers NULLs as equal. That is, NULLs are sorted together. ANSI leaves the question of whether NULLs are sorted lower or higher than known values up to implementations, which must be consistent. T-SQL sorts NULLs as lower than known values (first).
Step 11: TOP Option
The TOP option allows you to specify a number or percentage of rows (rounded up) to return. In SQL Server 2000, the input to TOP must be a constant, while in SQL Server 2005, the input can be any self-contained expression. The specified number of rows is selected from the beginning of the cursor returned by the previous step. Table VT11 is generated and returned to the caller.
Note
| The TOP option is T-SQL specific and is not relational. |
This step relies on the physical order of the rows to determine which rows are considered the "first" requested number of rows. If an ORDER BY clause with a unique ORDER BY list is specified in a query, the result is deterministic. That is, there's only one possible correct result, containing the first requested number of rows based on the specified sort. Similarly, when an ORDER BY clause is specified with a non-unique ORDER BY list but the TOP option is specified WITH TIES, the result is also deterministic. SQL Server inspects the last row that was returned physically and returns all other rows from the table that have the same sort values as the last row.
However, when a non-unique ORDER BY list is specified without the WITH TIES option, or ORDER BY is not specified at all, a TOP query is nondeterministic. That is, the rows returned are the ones that SQL Server happened to physically access first, and there might be different results that are considered correct. If you want to guarantee determinism, a TOP query must have either a unique ORDER BY list or the WITH TIES option.
As you can surmise, TOP queries are most commonly used with an ORDER BY clause that determines which rows to return. SQL Server allows you to specify TOP queries in table expressions. It wouldn't make much sense to allow TOP queries in table expressions without allowing you to also specify an ORDER BY clause. (See the limitation in step 10.) Thus, queries with an ORDER BY clause are in fact allowed in table expressions only if TOP is also specified. In other words, a query with both a TOP clause and an ORDER BY clause returns a relational result. The ironic thing is that by using the nonstandard, nonrelational TOP option, a query that would otherwise return a cursor returns a relational result. Support for nonstandard, nonrelational features (as practical as they might be) allows programmers to exploit them in some absurd ways that would not have been supported otherwise. Here's an
example:
SELECT *
FROM (SELECT TOP 100 PERCENT orderid, customerid
FROM dbo.Orders
ORDER BY orderid) AS D;
Or:
CREATE VIEW dbo.VSortedOrders AS SELECT TOP 100 PERCENT orderid, customerid FROM dbo.Orders ORDER BY orderid
Others:
A CASE expression with no ELSE clause has an implicit ELSE NULL.
The OVER clause allows you to request window-based calculations. In SQL Server 2005, this clause is a new option for aggregate functions (both built-in and custom Common Language Runtime [CLR]-based aggregates) and it is a required element for the four new analytical ranking functions (ROW_NUMBER, RANK, DENSE_RANK, and NTILE). When an OVER clause is specified, its input, instead of the query's GROUP BY list, specifies the window of rows over which the aggregate or ranking function is calculated.
The OVER clause is applicable only in one of two phases: the SELECT phase (8) and the ORDER BY phase (10). This clause has access to whichever virtual table is provided to that phase as input..
Listing 1-5. OVER clause in logical query processing
(8) SELECT (9) DISTINCT (11) TOP <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) WITH {CUBE | ROLLUP} (7) HAVING <having_condition> (10) ORDER BY <order_by_list> |