Netty通信技术进阶二
Netty核心组件
-
- 1. Bootstrap
- 2 Channel
- 3. EventLoopGroup 和 EventLoop
-
- 3.1 eventLoopThreads 是多少?
- 4. ChannelHandler & ChannelHandlerContext & ChannelPipeline
-
- 4.1 复用Handler
- 4.2 ChannelInboundHandlerAdapter or SimpleChannelInboundHandler
- 5. ByteBuf
-
- 5.1 ByteBuf的三个指针
- 5.2 容量API
- 5.3 读写指针相关的API
- 5.4 丢弃、清理,释放API
- 5.5 Wrap
- 5.6 ByteBuf三类使用模式
- 5.7 ByteBuf 的分配器BufAllocator
- 5.8 ByteBuf 的释放
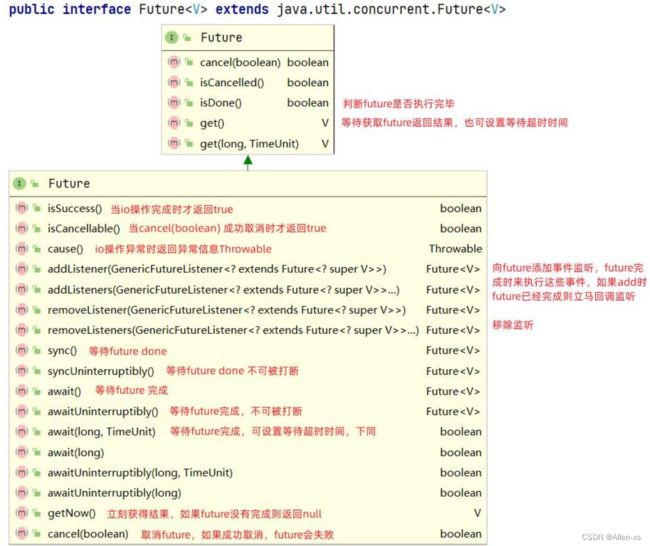
- 6. Netty的异步编程模型(Future & Promise)
-
- 6.1 Future
-
- 6.1.1 ChannelFuture
- 6.2 Promise
-
- 6.2.1 ChannelPromise
- 6. TCP 粘包,拆包(一次编码)
-
- 6.1 Netty拆包器
-
- 6.1.1 LineBasedFrameDecoder(分隔符解码器)\
- 6.1.2 LengthFieldBasedFrameDecoder(基于长度的域解码器)
- 6.1.3 自定义解码器
- 7. 序列化(二次编码)
-
- 7.1 ProtobufDecoder & ProtobufEecoder
- 8. Keepalive 与 idle监测
-
- 8.1 TCP Keepalvie
- 8.1 应用层Keepalvie
- 9. 高级特性,性能优化
-
- 9.1 System 参数
- 9.2. 应用诊断
-
- 9.2.1 完善线程组的线程名
- 9.2.2 添加Handler名称 & 日志
- 9.3 线程模型优化
-
- 9.3.1 CPU密集型:运算型
- 9.3.2 CPU密集型:运算型
- 9.4 零拷贝-Zero Copy
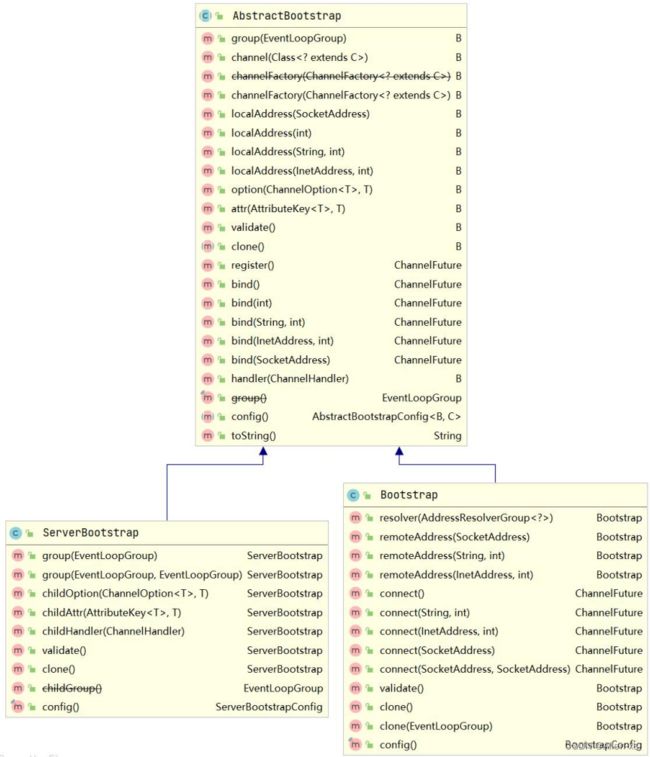
1. Bootstrap
Bootstrap是引导的意思,它的作用是配置整个Netty程序,将各个组件都串起来,最后绑定端口、启动Netty服务
Netty中提供了2种类型的引导类,一种用于客户端(Bootstrap),而另一种(ServerBootstrap)用于服务器,区别在于1、ServerBootstrap 将绑定到一个端口,因为服务器必须要监听连接,而 Bootstrap 则是由想要连接到远程节点的客户端应用程序所使用的
2、引导一个客户端只需要一个EventLoopGroup,但是一个ServerBootstrap则需要两个
2 Channel
Netty中的Channel是与网络套接字相关的,可以理解为是socket连接,在客户端与服务端连接的时候就会建立一个Channel,它负责基本的IO操作,比如:bind()、connect(),read(),write() 等
不同协议、不同的I/O类型的连接都有不同的 Channel 类型与之对应
主要作用:
- 通过Channel可获得当前网络连接的通道状态。
- 通过Channel可获得网络连接的配置参数(缓冲区大小等)。
- Channel提供异步的网络I/O操作,比如连接的建立、数据的读写、端口的绑定等。

3. EventLoopGroup 和 EventLoop
Netty是基于事件驱动的,比如:连接注册,连接激活;数据读取;异常事件等等,有了事件,就需要一个组件去监控事件的产生和事件的协调处理,这个组件就是EventLoop(事件循环/EventExecutor)
在Netty 中每个Channel 都会被分配到一个 EventLoop。一个 EventLoop 可以服务于多个 Channel。每个EventLoop 会占用一个 Thread,同时这个 Thread 会处理 EventLoop 上面发生的所有 IO 操作和事件。
EventLoopGroup 是用来生成 EventLoop 的,包含了一组EventLoop(可以初步理解成Netty线程池)

3.1 eventLoopThreads 是多少?
核心线程数默认:cpu核数*2, 核心线程数在创建时可通过构造函数指定
对于boss group,我们其实也只用到了其中的一个线程,因为服务端一般只会绑定一个端口启动
4. ChannelHandler & ChannelHandlerContext & ChannelPipeline
4.1 复用Handler
每个客户端Channel创建后初始化时,均会向与该Channel绑定的Pipeline中添加handler,此种模式下,每个Channel享有的是各自独立的Handler
如果复用的handler对象不加@Sharable注解会报错, 另外存在线程安全问题, 内部全局变量线程安全问题要自己处理
4.2 ChannelInboundHandlerAdapter or SimpleChannelInboundHandler
入站处理器,可以选择继承ChannelInboundHandlerAdapter,也可以选择继承SimpleChannelInboundHandler
继承SimpleChannelInboundHandler需要重写channelRead0方法,且可以通过泛型指定msg类型, 内部会自动release释放占用的Bytebuffer资源
注意事项:服务端异步处理数据,服务端最好不要继承SimpleChannelInboundHandler, 因为内部会释放资源, 下一链路的handler获取不到数据
public abstract class SimpleChannelInboundHandler<I> extends ChannelInboundHandlerAdapter {
private final TypeParameterMatcher matcher;
private final boolean autoRelease;
...
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
boolean release = true;
try {
if (this.acceptInboundMessage(msg)) {
this.channelRead0(ctx, msg);
} else {
release = false;
ctx.fireChannelRead(msg);
}
} finally {
if (this.autoRelease && release) {
ReferenceCountUtil.release(msg);
}
}
}
5. ByteBuf
Java NIO 提供了ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。Netty使用ByteBuf来替代ByteBuffer,它是一个强大的实现,既解决了JDK API 的局限性, 又为网络应用程序的开发者提供了更好的API
5.1 ByteBuf的三个指针
readerIndex: 指示读取的起始位置, 每读取一个字节, readerIndex自增累加1。 如果readerIndex 与writerIndex 相等,ByteBuf 不可读
writerIndex: 指示写入的起始位置, 每写入一个字节, writeIndex自增累加1, 达到capacity最大容量时自动扩容, 直到maxCapacity无法写入
maxCapacity 指示ByteBuf 可以扩容的最大容量
5.2 容量API
capacity(): ByteBuf底层在内存中占用的内存大小
maxCapacity(): ByteBuf 底层最大能够占用多少字节的内存
readableBytes() 与 isReadable(): readableBytes() 表示 ByteBuf 当前可读的字节数,它的值等于writerIndex-readerIndex,如果两者相等,则不可读,isReadable() 方法返回 false
writableBytes()、 isWritable() 、maxWritableBytes(): 第一个表示可写字节数。第二个表示是否可写。第三个表示最大可写字节数
5.3 读写指针相关的API
readerIndex() 与 readerIndex(int readerIndex): 前者表示返回当前的读指针 readerIndex, 后者表示设置读指针
writeIndex() 与 writeIndex(int writerIndex): 前者表示返回当前的写指针 writerIndex, 后者表示设置写指针
markReaderIndex() 与markWriterIndex(): 表示把当前的读指针/写指针保存起来,可用resetMarkReaderIndex和resetMarkWriterIndex进行恢复
writeBytes(byte[] src): 表示把字节数组 src 里面的数据全部写到 ByteBuf,src字节数组大小的长度通常小于等于writableBytes()
byte[] bytes = new byte[buf.writableBytes()];
buf.writableBytes(bytes);
readBytes(byte[] dst): 把 ByteBuf 里面的数据全部读取到 dst,dst 字节数组的大小通常等于readableBytes()
ByteBuf buf = (ByteBuf) msg;
byte[] bytes = new byte[buf.readableBytes()];
buf.readBytes(bytes);
writeByte(int value)、readByte(): writeByte() 表示往 ByteBuf 中写一个字节,而 readByte() 表示从 ByteBuf 中读取一个字节,类的 API 还有 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() 与 readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() 等等
5.4 丢弃、清理,释放API
discardReadBytes(): 丢弃已读取的字节空间,可写空间变多(瘦身)
clear(): 重置readerIndex 、 writerIndex 为0,需要注意的是,重置并没有删除真正的内容, 再次写入会进行覆盖
release(): 真正去释放bytebuf中的数据
ReferenceCountUtil.release(buf): 工具方法,内部还是调用release()
5.5 Wrap
通过Wrap操作可以快速转换或得到一个ByteBuf对象,Unpooled 工具类中提供了很多重载的wrappedBuffer方法
Unpooled 中wrappedBuffer方法不会发生数据的拷贝,而copiedBuffer会发生数据的拷贝
5.6 ByteBuf三类使用模式
堆缓冲区(HeapByteBuf): 内存分配在jvm堆, 分配和回收速度比较快,可以被JVM自动回收, 缺点是在进行IO操作时, 会将堆内存对应的缓冲区复制到内核Channel中, 多一次数据复制的过程
直接缓冲区(DirectByteBuf): 内存分配的是堆外内存(系统内存),相比堆内存,它的分配和回收速度会慢一些,但是将它写入或从Socket Channel中读取时,由于减少了一次内存拷贝,速度比堆内存块
复合缓冲区(CompositeByteBuf): 顾名思义就是将两个不同的缓冲区从逻辑上合并,让使用更加方便

Netty默认使用的是DirectByteBuf,如果需要使用HeapByteBuf模式,则需要进行系统参数的设置
设置HeapByteBuf模式,但ByteBuf 的分配器ByteBufAllocator要设置为非池化,否则不能切换到堆缓冲器模式
System.setProperty(“io.netty.noUnsafe”, “true”)
5.7 ByteBuf 的分配器BufAllocator
ByteBufAllocator alloc = ChannelHandlerContext: alloc();
Netty 提供了两种 ByteBufAllocator 的实现,分别是:
PooledByteBufAllocator:实现了 ByteBuf 的对象的池化,提高性能减少并最大限度地减少内存碎片,池化思想通过预先申请一块专用内存地址作为内存池进行管理,从而不需要每次都进行分配和释放
UnpooledByteBufAllocator:没有实现对象的池化,每次会生成新的对象实例
Netty默认使用了PooledByteBufAllocator,但可以通过引导类设置非池化模式 源码:DefaultChannelConfig种的allocator属性
//引导类中设置非池化模式
bootstrap.childOption(ChannelOption.ALLOCATOR, UnpooledByteBufAllocator.DEFAULT)
//或者通过系统参数设置
System.setProperty("io.netty.allocator.type", "pooled");
System.setProperty("io.netty.allocator.type", "unpooled");
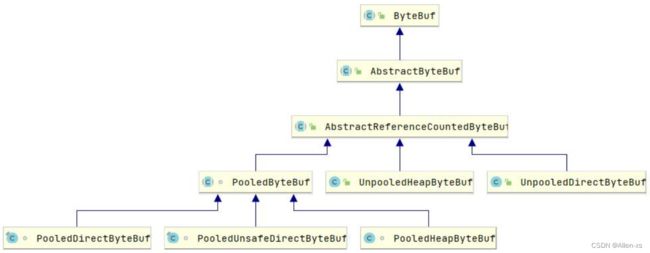
对于Pooled类型的ByteBuf,不管是PooledDirectByteBuf还是PooledHeapByteBuf都只能由Netty内部自己使用(构造是私有和受保护的),开发者可以使用Unpooled类型的ByteBuf。
Netty提供Unpooled工具类创建的ByteBuf都是unpooled类型,默认采用的Allocator是direct类型;当然用户可以自己选择创建UnpooledDirectByteBuf和UnpooledHeapByteBuf
5.8 ByteBuf 的释放
ByteBuf如果采用的是堆缓冲区模式的话,可以由GC回收,但是如果采用的是直接缓冲区,就不受GC的管理,就得手动释放,否则会发生内存泄露, Netty自身引入了引用计数,提供了ReferenceCounted接口,当对象的引用计数>0时要保证对象不被释放,当为0时需要被释放
关于ByteBuf的释放,分为手动释放与自动释放:
手动释放: 就是在使用完成后,调用ReferenceCountUtil.release(byteBuf); 进行释放,这种方式的弊端就是一旦忘记释放就可能会造成内存泄露
自动释放有三种方式: 入站的TailHandler(TailContext)、继承SimpleChannelInboundHandler、HeadHandler(HeadContext)的出站释放
入站消息:
对原消息不做处理,依次调用 ctx.fireChannelRead(msg)把原消息往下传,如果能到TailContext,那不用做什么释放,它会自动释放
将原消息转化为新的消息并调用 ctx.fireChannelRead(newMsg)往下传,那需要将原消息release掉
如果已经不再调用ctx.fireChannelRead(msg)传递任何消息,需要把原消息release掉
对于出站消息: 则无需用户关心,消息最终都会走到HeadContext,flush之后会自动释放
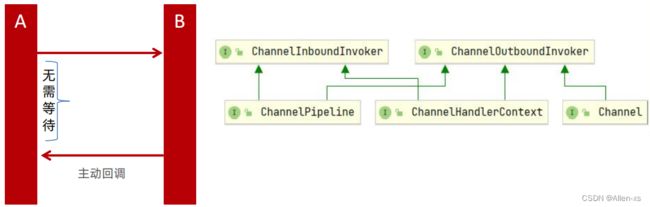
6. Netty的异步编程模型(Future & Promise)
future和promise,目的是将值(future)与其计算方式(promise)分离,从而允许更灵活地进行计算,特别是通过并行化。Future 表示目标计算的返回值,Promise 表示计算的方式,这个模型将返回结果和计算逻辑分离,目的是为了让计算逻辑不影响返回结果,从而抽象出一套异步编程模型。而计算逻辑与结果关联的纽带就是 callback
Netty中有非常多的异步调用,譬如:client/server的启动,连接,数据的读写等操作都是支持异步的
6.1 Future
ChannelFuture future = ctx.writeAndFlush(buffer);
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
future.get();
}
});
@Test
public void testFuture() throws InterruptedException, ExecutionException {
EventLoopGroup group = new NioEventLoopGroup();
Future<String> future = group.submit(() -> {
log.info("异步线程执行任务开始, time={}", LocalDateTime.now().toString());
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("异步线程执行任务结束, time={}", LocalDateTime.now().toString());
return "hello netty future";
});
//设置监听
future.addListener(future1 -> {
log.info("收到异步线程执行任务结果通知----执行结果是;{},time={}", future1.get(), LocalDateTime.now().toString());
});
log.info("---主线程----");
TimeUnit.SECONDS.sleep(10);
}
6.1.1 ChannelFuture
ChannelFuture:跟Channel的操作有关,Netty中的Handler处理都是异步IO,通过ChannelFuture添加事件监听,可获取Channel异步IO操作的结果;当然也可等待获取,但最好不要在handler中通过future的sync或await来获取异步操作的结果
6.2 Promise
Netty的Future,只是增加了监听器。整个异步的状态,是不能进行设置和修改的,于是Netty的 Promise接口扩展了
Netty的Future接口,可以设置异步执行的结果(callable机制)。在IO操作过程,如果顺利完成、或者发生异常,都可以设置Promise的
结果,并且通知Promise的Listener
@Test
public void testPromise() throws InterruptedException {
EventLoopGroup group = new NioEventLoopGroup();
Promise<String> promise = new DefaultPromise<>(group.next()); //promise绑定到eventloop上
group.submit(() -> {
try {
// int i = 1/0;
TimeUnit.SECONDS.sleep(3);
promise.setSuccess("hello netty promise");
TimeUnit.SECONDS.sleep(3);
promise.setSuccess("hello netty promise2");
log.info("异步线程执行任务结束, time={}", LocalDateTime.now().toString());
log.info("finish");
} catch (Exception e) {
log.error("exception", e);
promise.setFailure(e);
}
});
//设置监听回调
promise.addListener(future -> {
future.get();
log.info("异步任务执行结果: {}", future.isSuccess());
});
log.info("主线程");
TimeUnit.SECONDS.sleep(100);
}
6.2.1 ChannelPromise
ChannelPromise接口,则继承扩展了Promise和ChannelFuture。所以,ChannelPromise既绑定了Channel,又具备
了设置监听回调的功能,还可以设置IO操作的结果,是Netty实际编程使用的最多的接口

6. TCP 粘包,拆包(一次编码)
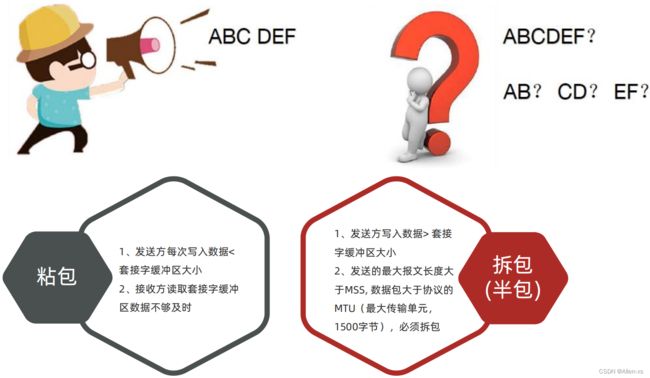
造成上述原因的根本原因: TCP 协议是面向连接的、可靠的、基于字节流的传输层通信协议,是一种流式协议,消息无边界
解决TCP粘包,半包问题的根本:找出消息的边界
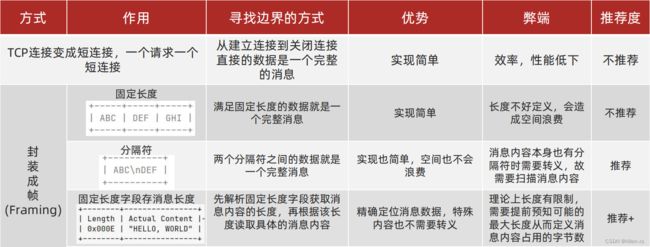
6.1 Netty拆包器
Netty提供了针对封装成帧这种形式下不同方式的拆包器,所谓的拆包其实就是数据的解码,所谓解码就是将网络中的一些原始数据解码成上层应用的数据,那对应在发送数据的时候要按照同样的方式进行数据的编码操作然后发送到网络中

6.1.1 LineBasedFrameDecoder(分隔符解码器)\
// 解码
// 默认以换行符进行分割, 参数最大解析长度, 一般Integer.MAX_VALUE
pipeline.addLast(new LineBasedFrameDecoder(65536));
// 指定分隔符
ByteBuf buf = ch.alloc().buffer().writeBytes("$".getBytes(StandardCharsets.UTF_8));
pipeline.addLast(new DelimiterBasedFrameDecoder(65536,buf));
编码代码中自定义设定
6.1.2 LengthFieldBasedFrameDecoder(基于长度的域解码器)
通过指定数组的边界, 有header和body, 如前4个字节存储的是内容的长度, 后面的标识内容
lengthFieldOffset:length域的偏移,正常情况下读取数据从偏移为0处开始读取,如果有需要可以从其他偏移量处开始读取
lengthFieldLength:length域占用的字节数
lengthAdjustment:在length域和content域中间是否需要填充其他字节数
initialBytesToStrip:解码后跳过的字节数
// 编码
pipeline.addLast(new LengthFieldPrepender(4));
// 解码
pipeline.addLast(new LengthFieldBasedFrameDecoder(65536, 0, 4, 0, 4));
6.1.3 自定义解码器
Netty中提供了ByteToMessageDecoder的抽象实现,自定义解码器只需要继承该类,实现decode()即可。Netty也提供了一些常用的解码器实现,用于数据入站的解码操作,基本都是开箱即用的;当然数据出站也需要采用对应的编码器
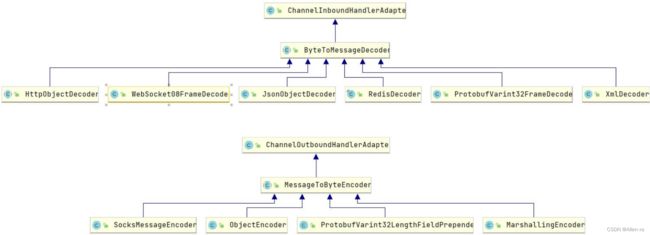
7. 序列化(二次编码)
我们把解决半包粘包问题的常用三种解码器叫一次解码器,其作用是将原始数据流(可能会出现粘包和半包的数据流)转换为用户数据(ByteBuf中存储),但仍然是字节数据,所以我们需要二次解码器将字节数组转换为java对象,或者将将一种格式转化为另一种格式,方便上层应用程序使用
一次解码器继承自:ByteToMessageDecoder;二次解码器继承自:MessageToMessageDecoder;但他们的本质都是继承ChannelInboundHandlerAdapter
7.1 ProtobufDecoder & ProtobufEecoder
protostuff是一个基于protobuf实现的序列化方法,它较于protobuf最明显的好处是,在几乎不损耗性能的情况下做到了不用我们
写.proto文件来实现序列化, github
/**
* protostuff编解码工具类
* @author: xxs
* @create:2023-04-17 19:31
*/
@Slf4j
public class ProtostuffUtil {
//存储因为无法直接序列化/反序列化 而需要被包装的类型Class
private static final Set<Class<?>> WRAPPER_SET = new HashSet<Class<?>>();
static {
WRAPPER_SET.add(List.class);
WRAPPER_SET.add(ArrayList.class);
WRAPPER_SET.add(CopyOnWriteArrayList.class);
WRAPPER_SET.add(LinkedList.class);
WRAPPER_SET.add(Stack.class);
WRAPPER_SET.add(Vector.class);
WRAPPER_SET.add(Map.class);
WRAPPER_SET.add(HashMap.class);
WRAPPER_SET.add(TreeMap.class);
WRAPPER_SET.add(LinkedHashMap.class);
WRAPPER_SET.add(Hashtable.class);
WRAPPER_SET.add(SortedMap.class);
WRAPPER_SET.add(Object.class);
}
//注册需要使用包装类进行序列化的Class对象
public static void registerWrapperClass(Class<?> clazz) {
WRAPPER_SET.add(clazz);
}
/**
* 将对象序列化为字节数组
* @param t
* @param useWrapper 为true完全使用包装模式 为false则选择性的使用包装模式
* @param
* @return
*/
public static <T> byte[] serialize(T t,boolean useWrapper) {
Object serializerObj = t;
if (useWrapper) {
serializerObj = SerializeDeserializeWrapper.build(t);
}
return serialize(serializerObj);
}
/**
* 将对象序列化为字节数组
* @param t
* @param
* @return
*/
public static <T> byte[] serialize(T t) {
//获取序列化对象的class
Class<T> clazz = (Class<T>) t.getClass();
Object serializerObj = t;
if (WRAPPER_SET.contains(clazz)) {
serializerObj = SerializeDeserializeWrapper.build(t);//将原始序列化对象进行包装
}
return doSerialize(serializerObj);
}
/**
* 执行序列化
* @param t
* @param
* @return
*/
public static <T> byte[] doSerialize(T t) {
//获取序列化对象的class
Class<T> clazz = (Class<T>) t.getClass();
//获取Schema
// RuntimeSchema schema = RuntimeSchema.createFrom(clazz);//根据给定的class创建schema
/**
* this is lazily created and cached by RuntimeSchema
* so its safe to call RuntimeSchema.getSchema() over and over The getSchema method is also thread-safe
*/
Schema<T> schema = RuntimeSchema.getSchema(clazz);//内部有缓存机制
/**
* Re-use (manage) this buffer to avoid allocating on every serialization
*/
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
byte[] protostuff = null;
try {
protostuff = ProtostuffIOUtil.toByteArray(t, schema, buffer);
} catch (Exception e){
log.error("protostuff serialize error,{}",e.getMessage());
}finally {
buffer.clear();
}
return protostuff;
}
/**
* 反序列化
* @param data
* @param clazz
* @param
* @return
*/
public static <T> T deserialize(byte[] data,Class<T> clazz) {
//判断是否经过包装
if (WRAPPER_SET.contains(clazz)) {
SerializeDeserializeWrapper<T> wrapper = new SerializeDeserializeWrapper<T>();
ProtostuffIOUtil.mergeFrom(data,wrapper,RuntimeSchema.getSchema(SerializeDeserializeWrapper.class));
return wrapper.getData();
}else {
Schema<T> schema = RuntimeSchema.getSchema(clazz);
T newMessage = schema.newMessage();
ProtostuffIOUtil.mergeFrom(data,newMessage,schema);
return newMessage;
}
}
private static class SerializeDeserializeWrapper<T> {
//被包装的数据
T data;
public static <T> SerializeDeserializeWrapper<T> build(T data){
SerializeDeserializeWrapper<T> wrapper = new SerializeDeserializeWrapper<T>();
wrapper.setData(data);
return wrapper;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
}
@Slf4j
public class ProtoStuffDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {
try {
int length = msg.readableBytes();
byte[] bytes = new byte[length];
msg.readBytes(bytes);
UserInfo userInfo = ProtostuffUtil.deserialize(bytes, UserInfo.class);
out.add(userInfo);
} catch (Exception e) {
log.error("protostuff decode error, msg={}", e.getMessage());
throw new RuntimeException(e);
}
}
}
@Slf4j
public class ProtoStuffEncoder extends MessageToMessageEncoder<UserInfo> {
@Override
protected void encode(ChannelHandlerContext ctx, UserInfo msg, List<Object> out) throws Exception {
try {
byte[] bytes = ProtostuffUtil.serialize(msg);
ByteBuf buffer = ctx.alloc().buffer(bytes.length);
buffer.writeBytes(bytes);
out.add(buffer);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
8. Keepalive 与 idle监测
8.1 TCP Keepalvie

sysctl -algrep tcp_ keepalive
net.ipv4.tcp_ keepalive_ time = 7200
net.ipv4.tcp_ keepalive_ intvl= 75
net.ipv4.tcp_ keepalive_ probes= 9
TCP层的KEEPALIVE时间太长, 默认>2小时,虽然可改,但属于系统参数,改动影响所有应用
// server开启tcp keepalive
.option(ChannelOption.SO_BACKLOG,1024) // 设置连接队列大小
.childOption(ChannelOption.SO_KEEPALIVE,true)// 开始tcp keepalive
.childOption(ChannelOption.TCP_NODELAY,true)// Nagle算法是将小的数据包组装为更大的帧然后进行发送,会有延迟 false开启, trur关闭
.handler(new LoggingHandler(LogLevel.INFO))// 日志
8.1 应用层Keepalvie
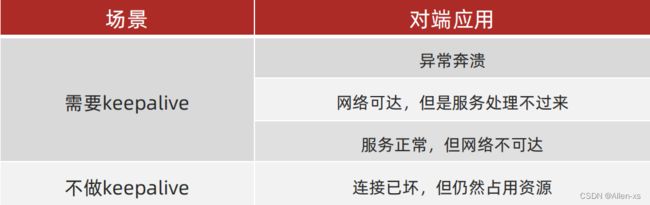
Idle 监测,只是负责诊断,诊断后,做出不同的行为,决定Idle 监测的最终用途,一般用来配合keepalive ,减少keepalive 消息
空闲监测+ 判定为Idle 时才发keepalive,有其他数据传输的时候,不发送keepalive ,无数据传输超过一定时间,判定为Idle,再发keepalive
服务器添加read idle check,10s接收不到channel数据就断掉连接,保护自己,瘦身
客户端添加write idle check + keepalive,5s不发送数据就发送一个keepalive,避免连接被断,也避免频繁keepalive
服务端
pipeline.addLast(new ServerReadIdleHandler());
@Slf4j
public class ServerReadIdleHandler extends IdleStateHandler {
public ServerReadIdleHandler() {
super(10, 0, 0, TimeUnit.SECONDS);
}
@Override
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) throws Exception {
log.info("server channel idle");
if (evt == IdleStateEvent.FIRST_READER_IDLE_STATE_EVENT) {
ctx.close();
log.info("server read idle , close channel...");
return;
}
super.channelIdle(ctx, evt);
}
}
客户端
pipeline.addLast(new ClientWriterIdleHandler());
@Slf4j
public class ClientWriterIdleHandler extends IdleStateHandler {
public ClientWriterIdleHandler() {
super(0, 5, 0, TimeUnit.SECONDS);
}
@Override
protected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) throws Exception {
if (evt == IdleStateEvent.FIRST_WRITER_IDLE_STATE_EVENT) {
//发送keepalive消息
UserInfo userInfo = new UserInfo();
userInfo.setName("keeepalive");
ctx.channel().writeAndFlush(userInfo);
}
super.channelIdle(ctx, evt);
}
}
9. 高级特性,性能优化
9.1 System 参数
针对ServerScoketChannel,通过.childOption设置:
1、SO_KEEPALIVE,tcp层keepalvie,默认关闭,一般选择关闭tcp keepalive 而使用应用keepalive
2、TCP_NODELAY:设置是否启用nagle算法,该算法是tcp在发送数据时将小的、碎片化的数据拼接成一个大的报文一起发送,以此来提高效率,默认是false(启用),如果启用可能会导致有些数据有延时,如果业务不能忍受,小报文也需要立即发送则可以禁用该算法
3、SO_BACKLOG:最大等待连接数量,netty在linux下该值的获取是通过:io.netty.util.NetUtil完成的
9.2. 应用诊断
9.2.1 完善线程组的线程名
EventLoopGroup boss = new NioEventLoopGroup(1, new DefaultThreadFactory("boss"));
EventLoopGroup worker = new NioEventLoopGroup(0, new DefaultThreadFactory("worker"));
9.2.2 添加Handler名称 & 日志
pipeline.addLast("protoStuffDecoder", new ProtoStuffDecoder());
9.3 线程模型优化
9.3.1 CPU密集型:运算型
保持当前线程模型:
1、Runtime.getRuntime().availableProcessors() * 2
2、io.netty.availableProcessors *2 【docker】
3、io.netty.eventLoopThreads
还需要具体调优,根据业务执行时间不断调整找到一个合适的值
9.3.2 CPU密集型:运算型
需要整改线程模型:需要独立的“业务线程池”来处理业务(执行handler)
1、在handler内部使用JDK Executors
2、向pipeline中添加handle时使用netty提供的UnorderedTheadPoolEventExector
EventExecutorGroup business = new UnorderedThreadPoolEventExecutor(NettyRuntime.availableProcessors() * 2, new DefaultThreadFactory("business"));
// 执行业务
pipeline.addLast(business, "tcptesthandler", new TcpStickHalfHandler());
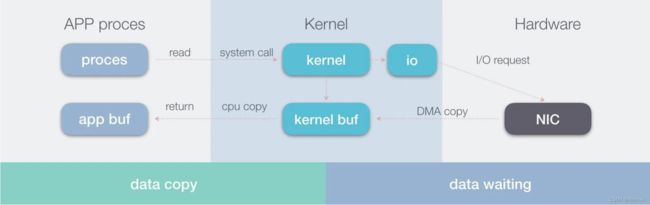
9.4 零拷贝-Zero Copy
系统内核处理 IO 操作分为两个阶段:等待数据和拷贝数据:
1、等待数据,就是系统内核在等待网卡接收到数据后,把数据写到内核中。
2、拷贝数据,就是系统内核在获取到数据后,将数据拷贝到用户进程的空间中。
1、Netty接收和发送ByteBuffer采用DirectBuffer,使用堆外直接内存进行Socket读写,不需要进行字节缓冲区的二次拷贝
2、Netty提供CompositeByteBuf组合缓冲区类,可以将多个 ByteBuf合并为一个逻辑上的ByteBufer,避免了各个ByteBufer之间的拷贝,将几个小buffer合并成一个大buffer的繁琐操作
3、通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作
4、通过 FileRegion 包装的FileChannel.tranferTo (Java nio)实现文件传输, 可以直接将文件缓冲区的数据发送到目标
Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题