Honggfuzz Linux arch_clone 源码阅读 (setjmp, clone)
Honggfuzz Linux arch_clone 源码阅读 (setjmp, clone)
阅读 Honggfuzz 系统架构相关源码,在创建子进程部分遇到了几个问题,经过研究得以解决,在此记录。
Source Code
代码节选自linux/arch.c,已添加注释,主要功能是以更细控制粒度(控制flags)创建子进程,而无参数的fork无法做到。
static uint8_t arch_clone_stack[128 * 1024] __attribute__((aligned(__BIGGEST_ALIGNMENT__)));
static __thread jmp_buf env;
HF_ATTR_NO_SANITIZE_ADDRESS
HF_ATTR_NO_SANITIZE_MEMORY
__attribute__((noreturn)) static int arch_cloneFunc(void* arg HF_ATTR_UNUSED) {
longjmp(env, 1);
}
/* Avoid problem with caching of PID/TID in glibc */
static pid_t arch_clone(uintptr_t flags) {
if (flags & CLONE_VM) { // if child proc share the same VM with parent (change visible)
LOG_E("Cannot use clone(flags & CLONE_VM)");
return -1;
}
if (setjmp(env) == 0) { // save the execution context
// return 0 if called directly, non-zero if indirectly (return from `longjmp`)
void* stack_mid = &arch_clone_stack[sizeof(arch_clone_stack) / 2];
/* Parent */
return clone(arch_cloneFunc, stack_mid, flags, NULL, NULL, NULL);
}
/* Child */
return 0;
}
Procedure
arch_clone检查flags中是否有CLONE_VM(父子进程共享同一个虚拟内存空间,相互影响),fuzz情景下不允许该方式setjmp设置longjmp的checkpoint ,后续会介绍- 如果在父进程中,就将预先分配的栈
arch_clone_stack取中间点 - 执行glibc封装的
clone
Q & A
setjmp / longjmp
C标准库函数,用于执行"nonlocal gotos"(非本地跳转),对应goto语句的函数中跳转,longjmp允许跳转到调用栈上的任意位置,并恢复执行上下文。
通过setjmp(env)保存当前点的执行上下文信息(包括栈指针、寄存器值等)到jmp_buf类型参数env中,当执行longjmp(env, r),将恢复到env保存处的执行状态,并从那里开始执行。
具体保存的上下文内容如下所示:

这种方法可以用于模拟C++ Exception,通过longjmp的返回值传递errno
注意:longjmp在非调用栈上的跳转行为未定义,如果执行setjmp保存上下文的函数已经返回,则不可使用longjmp恢复上下文
示例:
#include - 程序在主函数保存了执行上下文,并跳转到
foo函数执行 foo函数通过longjmp恢复执行流到main
过程如下,在执行setjmp前,各寄存器(主要关注栈)状态如下:
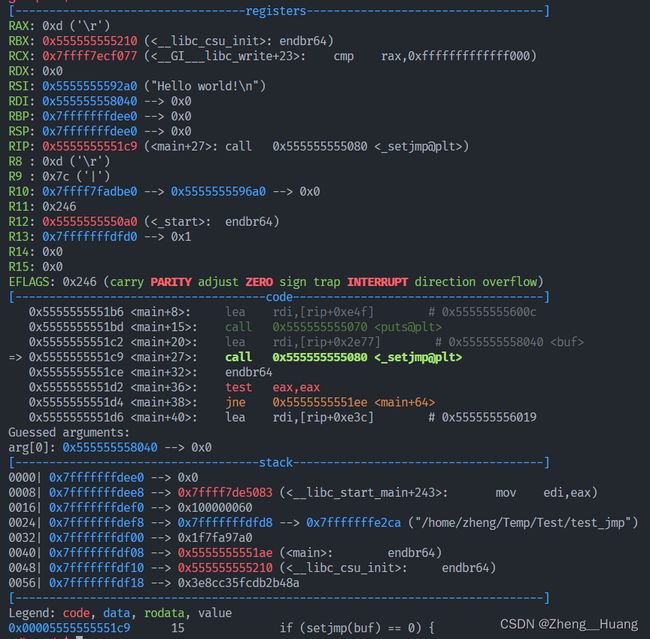
在执行longjmp前,各寄存器状态如下:
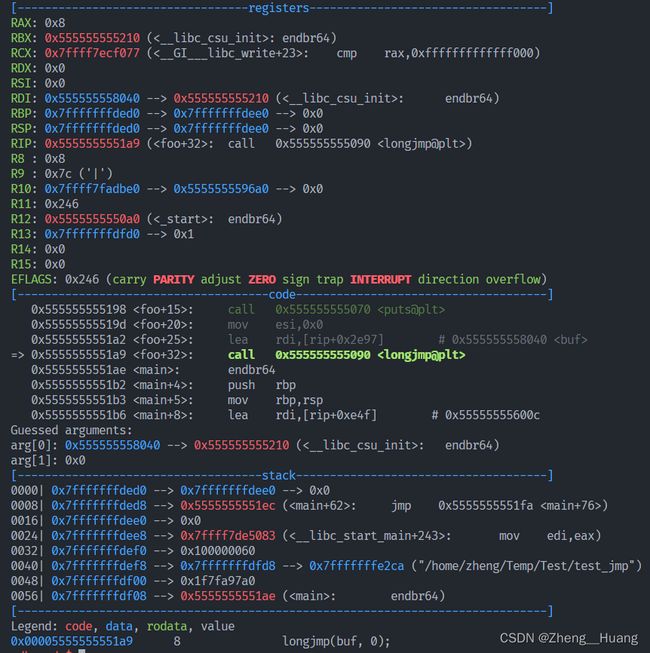
执行后,跳转到保存点,各寄存器的值也已经恢复:

clone stack参数
为什么需要在clone时附加stack参数呢?
- 在使用
CLONE_VM时,父子进程必不可以使用同一个栈,需要为子进程单独分配一个栈空间,这时候需要传入栈指针。
但是在这个场景下,没有使用CLONE_VM,也就不存在栈冲突的情况。这是因为代码使用了glibc封装的clone,stack参数会用于存储目标函数指针fn,返回后自动进入fn参数指定的函数。在arch_clone_func中,只用到了longjmp,恢复执行上下文,栈又恢复到了和父进程相同的状态,后续没有用到最初传入的arch_clone_stack。
为什么要传入stack参数的中间部分?
- 在
CLONE_VM时,当父子进程共享同一个栈空间,为了避免冲突,将原有栈空间分一半使用,父子进程各占一半 - 本场景没有启用
CLONE_VM,所以笔者猜测是用于避免栈指针越过buf边界导致错误,所以取中间作为传入指针(欢迎有兴趣的读者在评论区讨论)
那么,可以不创建和使用栈吗?
理论上应当是可行的,glibc为了方便clone后的子进程进行下一步栈初始化等操作,提供了一个初始的函数fn指针。如果我们没有指定CLONE_VM,则可以用raw clone (syscall)。返回后的子进程与fork类似(实际上,fork就是clone系统调用的一个特殊情景),从调用clone的位置后继续运行。以下是manual中指明的两者的区别:
C library/kernel differences
The raw clone() system call corresponds more closely to fork(2) in that execution in the child continues from the point of the call. As such, the fn and arg arguments of the clone() wrapper function are omitted.