TensorFlow 和 Keras 应用开发入门:1~4 全
原文:Beginning Application Development with TensorFlow and Keras
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、神经网络和深度学习简介
在本课程中,我们将介绍神经网络的基础知识以及如何建立深度学习编程环境。 我们还将探讨神经网络的常见组件及其基本操作。 我们将通过探索使用 TensorFlow 创建的训练有素的神经网络来结束本课程。
本课是关于了解神经网络可以做什么的。 我们将不讨论深度学习算法基础的数学概念,而将描述构成深度学习系统的基本部分。 我们还将看一些使用神经网络解决现实问题的例子。
本课将为您提供有关如何设计使用神经网络解决问题的系统的实用直觉,包括如何确定是否可以使用此类算法完全解决给定的问题。 从本质上讲,本课挑战您将问题视为思想的数学表示形式。 在本课程结束时,您将能够考虑这些表示形式的集合来思考问题,然后开始认识到深度学习算法如何学习这些表示形式。
课程目标
在本课程结束时,您将能够:
- 涵盖神经网络的基础
- 设置深度学习编程环境
- 探索神经网络的通用组件及其基本操作
- 通过探索使用 TensorFlow 创建的训练有素的神经网络来结束本课程
什么是神经网络?
麻省理工学院的沃伦·麦卡洛(Warren McCullough)和沃尔特·皮茨(Walter Pitts)于 40 年代首次提出了神经网络,也称为,即人工神经网络。
注意
有关更多信息,请参见《神经网络解释》,可在以下网址访问。
受神经科学进步的启发,他们建议创建一个计算机系统,该计算机系统可以重现大脑(人类或其他方式)的工作方式。 其核心思想是作为互连网络工作的计算机系统。 即,具有许多简单组件的系统。 这些组件既可以解释数据,又可以相互影响如何解释数据。 今天仍然保留着相同的核心思想。
深度学习在很大程度上被认为是神经网络的当代研究。 可以将其视为神经网络的当前名称。 主要区别在于,深度学习中使用的神经网络通常比早期的神经网络更大,即具有更多的节点和层。 深度学习算法和应用通常需要获得成功的资源,因此使用深度一词来强调其大小和大量相互连接的组件。
成功的应用
自从 40 年代以一种形式或另一种形式出现以来,一直在研究神经网络。 但是,直到最近,深度学习系统才在大型工业应用中成功使用。
神经网络的当代支持者已在语音识别,语言翻译,图像分类和其他领域取得了巨大的成功。 其当前的突出优势是可用计算能力的显着提高以及图形处理单元(GPU)和张量处理单元(TPU)比常规 CPU 能够执行更多的同时数学运算,并且数据可用性更高。
不同 AlphaGo 算法的功耗。 AlphaGo 是 DeepMind 的一项举措,旨在开发出一系列击败 Go 游戏的算法。 它被认为是深度学习的强大典范。 TPU 是 Google 开发的一种芯片组,用于深度学习程序。
该图描绘了用于训练不同版本的 AlphaGo 算法的 GPU 和 TPU 的数量。 来源。
注意
在本书中,我们不会使用 GPU 来完成我们的活动。 不需要 GPU 与神经网络一起使用。 在许多简单的示例(如本书中提供的示例)中,所有计算都可以使用简单的笔记本电脑的 CPU 执行。 但是,在处理非常大的数据集时,鉴于长时间训练神经网络不切实际,GPU 可能会提供很大帮助。
这是神经网络在其中产生巨大影响的一些实例:
-
翻译文本:2017 年,Google 宣布将为其翻译服务发布一种名为转换器的新算法。 该算法由使用双语文本训练的循环神经网络(LSTM)组成。 Google 表明,与行业标准(BLEU)相比,其算法已获得了显着的准确率,并且在计算效率上也很高。 据报道,在撰写本文时,转换器被 Google 翻译用作其主要翻译算法。
注意
Google 研究博客,《转换器:一种用于语言理解的新型神经网络架构》。
-
自动驾驶汽车:Uber,NVIDIA 和 Waymo 被认为正在使用深度学习模型来控制不同的控制驾驶的车辆功能。 每个公司都在研究多种可能性,包括使用人工训练网络,模拟在虚拟环境中驾驶的车辆,甚至创建类似于城市的小型环境,在其中可以根据预期和意外事件对车辆进行训练。
注意
Alexis C. Madrigal: Inside Waymo's Secret World for Training Self-Driving Cars. The Atlantic. August 23, 2017.NVIDIA: End-to-End Deep Learning for Self-Driving Cars. August 17, 2016.Dave Gershgorn: Uber's new AI team is looking for the shortest route to self-driving cars. Quartz. December 5, 2016.
-
图像识别:Facebook 和 Google 使用深度学习模型来识别图像中的实体,并自动将这些实体标记为一组联系人中的人物。 在这两种情况下,都使用先前标记的图像以及目标朋友或联系人的图像来训练网络。 两家公司都报告说,在大多数情况下,这些模型能够以很高的精确度推荐朋友或联系人。
尽管其他行业中有更多示例,但深度学习模型的应用仍处于起步阶段。 还有更多成功的应用,包括您创建的应用。
为什么神经网络这么好?
为什么神经网络如此强大? 神经网络之所以强大,是因为它们可用于以合理的近似值预测任何给定的函数。 如果一个人能够将一个问题表示为一个数学函数,并且还具有可以正确表示该函数的数据,那么原则上,只要有足够的资源,深度学习模型就可以近似该函数。 这通常称为神经网络的通用性原则。
注意
有关更多信息,请参阅 Michael Nielsen 的《神经网络和深度学习:神经网络可以计算任何函数的视觉证明》。
在本书中,我们将不探讨通用性原理的数学证明。 但是,神经网络的两个特征应该为您提供有关如何理解该原理的正确直觉:表示学习和函数近似。
注意
有关更多信息,请参阅《深度强化学习的简要概述》。
表示学习
用于训练神经网络的数据包含表示形式(也称为特征),这些表示形式说明您要解决的问题。 例如,如果有兴趣从图像中识别人脸,则将一组包含人脸的图像中每个像素的颜色值用作起点。 然后,模型将在训练过程中将像素组合在一起,从而不断学习更高级别的表示。

图 1:从输入数据开始的一系列高级表示。 基于原始图像得出的图像,来自 Yan LeCun,Yoshua Bengio 和 Geoffrey Hinton 的《深度学习》。
用正式的词来说,神经网络是计算图,其中每个步骤从输入数据计算更高的抽象表示。
这些步骤中的每一步都代表进入不同抽象层的过程。 数据经过这些层,不断建立更高级别的表示。 该过程以最大可能的表示形式结束:模型试图进行预测。
函数近似
当神经网络学习数据的新表示时,它们通过将权重和偏差与来自不同层的神经元相结合来实现。 每当训练周期发生时,他们就会使用称为反向传播的数学技术来调整这些连接的权重。 权重和偏差在每个回合中都会改善,直至达到最佳效果。 这意味着神经网络可以测量每个训练周期的错误程度,调整每个神经元的权重和偏差,然后重试。 如果确定某项修改产生的效果比上一轮更好,它将投资于该修改,直到获得最佳解决方案。
简而言之,该过程是神经网络可以近似函数的原因。 但是,神经网络可能无法完美地预测函数有很多原因,其中主要的原因是:
- 许多函数包含随机属性(即随机属性)
- 训练数据可能会过拟合
- 可能缺少训练数据
在的许多实际应用中,简单的神经网络能够以合理的精度近似一个函数。 这些应用将成为本书的重点。
深度学习的局限性
深度学习技术最适合可以用形式化数学规则(即,数据表示形式)定义的问题。 如果很难用这种方式定义问题,则深度学习可能不会提供有用的解决方案。 此外,如果可用于给定问题的数据有偏差或仅包含生成该问题的基础函数的部分表示,则深度学习技术将仅能够重现该问题而不能学习解决该问题。
记住,深度学习算法正在学习数据的不同表示以近似给定的函数。 如果数据不能恰当地表示函数,则可能是神经网络会错误地表示函数。 考虑以下类比:您正在尝试预测汽油(即燃料)的全国价格并创建深度学习模型。 您可以将信用卡对帐单与日常汽油费用一起用作该模型的输入数据。 该模型最终可能会了解您的汽油消耗模式,但可能会误述由仅在您的数据中每周代表的其他因素(例如政府策略,市场竞争,国际政治等)引起的汽油价格波动。 在生产中使用该模型时,最终将产生错误的结果。
为避免此问题,请确保用于训练模型的数据代表该模型试图尽可能准确地解决的问题。
注意
有关此主题的深入讨论,请参阅 FrançoisChollet 即将出版的书《使用 Python 进行深度学习》。 François 是 Keras(本书中使用的 Python 库)的创建者。 深度学习的局限性这一章对于理解该主题特别重要。
内在偏见和道德考量
研究人员建议使用深度学习模型而不考虑训练数据中的固有偏差不仅会导致表现不佳,还会导致道德上的复杂化。
例如,2016 年底,中国上海交通大学的研究人员创建了一个神经网络,该神经网络仅使用犯罪现场的面孔对犯罪分子进行正确分类。 研究人员使用了 1,856 张中国男子的图像,其中一半被定罪。
注意
他们的模型识别出囚犯的准确率高达 89.5% 。
麻省理工学院技术评论,《神经网络学习通过面孔识别犯罪分子》。
该论文在科学界和大众媒体中引起了极大轰动。 所提出的解决方案的一个关键问题是它不能正确地识别输入数据中固有的偏差。 即,本研究中使用的数据来自两个不同的来源:一个用于罪犯,一个用于非罪犯。 一些研究人员建议,他们的算法可以识别与研究中使用的不同数据源相关的模式,而不是从人们的人脸识别相关模式。 尽管可以对模型的可靠性进行技术上的考虑,但主要的批评是出于道德基础:人们应该清楚地认识到深度学习算法所使用的输入数据的固有偏差,并考虑其应用将如何对人们的学习产生影响。 生活。
注意
蒂莫西·雷维尔(Timothy Revell),《用于“识别”罪犯的人脸识别技术的关注》。
为了使进一步了解学习算法(包括深度学习)中的道德主题,请参阅 AI Now Institute 为了解智能系统的社会意义所做的工作。
神经网络的通用组件和操作
神经网络具有两个关键组成部分:层和节点。
节点是负责特定操作的,层是用于区分系统不同阶段的节点组。 通常,神经网络具有以下三类类别:
- 输入:接收并首先解释输入数据的位置
- 隐藏:进行计算的位置,在处理数据时对其进行修改
- 输出:组装并评估输出的位置
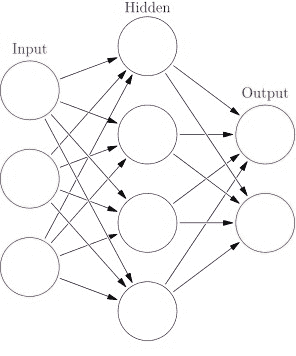
图 2:神经网络中最常见的层的图示。 来自 Glosser.ca 自己的作品:Artificial neural network.svg文件的衍生物,CC BY-SA 3.0
隐藏层是神经网络中最重要的层。 它们被称为隐藏的,因为在其中生成的表示形式在数据中不可用,但可以从中学习。 在这些层中,神经网络中进行了主要计算。
节点是网络中表示数据的地方。 有两个与节点关联的值:偏差和权重。 这两个值都影响数据如何由节点表示并传递到其他节点。 当网络学习时,它会有效地调整这些值以满足优化函数。
神经网络中的大部分工作都发生在隐藏层中。 不幸的是,没有明确的规则来确定网络应具有多少层或节点。 在实现神经网络时,人们可能会花费时间来尝试不同的层和节点组合。 建议始终从单个层开始,并且总是以反映输入数据具有的特征数量(即,数据集中有多少列可用)的数量的节点开始。 然后,将继续添加层和节点,直到获得令人满意的表现-或每当网络开始过度适应训练数据时。
当前的神经网络实践通常仅限于实验,该实验涉及节点和层的数量(例如,网络的深度)以及在每一层执行的操作的种类。 在许多成功的实例中,仅通过调整这些参数,神经网络的表现就优于其他算法。
作为一种直觉,考虑一下数据通过输入层进入神经网络系统,然后在网络中从一个节点移动到另一个节点。 数据采用的路径将取决于节点的互连程度,每个节点的权重和偏差,在每个层中执行的操作的类型以及此类操作结束时的数据状态。 神经网络通常需要许多“运行”(或周期),以便不断调整节点的权重和偏差,这意味着数据多次流经图的不同层。
本节为您提供了神经网络和深度学习的概述。 此外,我们讨论了入门者的直觉,以了解以下关键概念:
- 只要有足够的资源和数据,神经网络原则上就可以近似大多数函数。
- 层和节点是神经网络最重要的结构组件。 通常,人们会花费大量时间来更改这些组件以找到一种有效的架构。
- 权重和偏差是网络在训练过程中“学习”的关键属性。
这些概念将在我们的下一部分中证明是有用的,因为我们探索了一个在现实世界中经过训练的神经网络,并进行了修改以训练自己的神经网络。
配置深度学习环境
在完成本课程之前,我们希望您与真实的神经网络进行交互。 我们将首先介绍本书中使用的主要软件组件,并确保已正确安装它们。 然后,我们将探索一个预训练的神经网络,并探索前面“什么是神经网络”部分讨论的一些组件和操作。
深度学习的软件组件
我们将使用以下软件组件进行深度学习:
Python 3
本书中,我们将使用 Python 3。 Python 是一种通用编程语言,在科学界非常流行-因此在深度学习中得到了采用。 本书不支持 Python 2,但可用于训练神经网络而不是 Python3。即使您选择在 Python 2 中实现解决方案,也应考虑迁移到 Python 3,因为其现代功能集比 Python 3 更强大。 它的前身。
TensorFlow
TensorFlow 是一个库,用于以图形式执行数学运算。 TensorFlow 最初由 Google 开发,如今已是一个由许多贡献者参与的开源项目。 它在设计时就考虑了神经网络,是创建深度学习算法时最受欢迎的选择之一。
TensorFlow 也以其生产组件而闻名。 它随附 TensorFlow 服务,这是一种用于深度学习模型的高性能系统。 此外,可以在其他高性能编程语言(例如 Java,Go 和 C)中使用经过训练的 TensorFlow 模型。这意味着人们可以在从微型计算机(即 RaspberryPi)到 Android 设备的任何内容中部署这些模型。 。
Keras
为了与 TensorFlow 高效交互,我们将使用 Keras,这是一个具有高级 API 的 Python 包,用于开发神经网络。 虽然 TensorFlow 专注于在计算图中彼此交互的组件,但 Keras 专门专注于神经网络。 Keras 使用 TensorFlow 作为其后端引擎,使开发此类应用变得更加容易。
截至 2017 年 11 月(TensorFlow 1.4 版),Keras 作为 TensorFlow 的一部分分发。 在tf.keras命名空间下可用。 如果安装了 TensorFlow 1.4 或更高版本,则系统中已经有 Keras 可用。
TensorBoard
TensorBoard 是用于探索 TensorFlow 模型的数据可视化套件,并与 TensorFlow 原生集成。 TensorBoard 通过训练 TensorFlow 在训练神经网络时使用的检查点和摘要文件来工作。 可以近乎实时(延迟 30 秒)或在网络完成训练后进行探索。 TensorBoard 使实验和探索神经网络的过程变得更加容易,而且跟随您的网络训练也非常令人兴奋!
Jupyter 笔记本,Pandas 和 NumPy
在使用 Python 创建深度学习模型时,通常开始进行交互工作,慢慢地开发一个模型,最终将其变成结构化的软件。 在此过程中,经常使用以下三个 Python 包:Jupyter 笔记本,Pandas 和 NumPy:
- Jupyter 笔记本创建交互式 Python 会话,使用网络浏览器作为其界面
- Pandas 是用于数据操纵和分析的包
- NumPy 是,经常用于整形数据和执行数值计算
在本书中偶尔会使用这些包。 它们通常不构成生产系统的一部分,但经常在浏览数据和开始构建模型时使用。 我们将更加详细地关注其他工具。
注意
Michael Heydt 的《学习 Pandas》和 Dan Toomey 的《学习 Jupyter》提供了有关如何使用这些技术的全面指南。 这些书是继续学习的好参考。
| 组件 | 描述 | 最低版本 |
|---|---|---|
| Python | 通用编程语言。 深度学习应用开发中使用的流行语言。 | 3.6 |
| TensorFlow | 开源图计算 Python 包,通常用于开发深度学习系统。 | 1.4 |
| Keras | 提供与 TensorFlow 的高级接口的 Python 包。 | 2.0.8-tf(随 TensorFlow 一起分发) |
| TensorBoard | 基于浏览器的软件,用于可视化神经网络统计信息。 | 0.4.0 |
| Jupyter 笔记本 | 基于浏览器的软件,用于与 Python 会话进行交互。 | 5.2.1 |
| Pandas | 用于分析和处理数据的 Python 包。 | 0.21.0 |
| NumPy | 用于高性能数值计算的 Python 包。 | 1.13.3 |
表 1:创建深度学习环境所需的软件组件
活动 1 – 验证软件组件
在探索训练有素的神经网络之前,让我们验证所需的所有软件组件是否可用。 我们包含了一个脚本,用于验证这些组件的工作情况。 让我们花点时间运行脚本并处理可能发现的所有最终问题。
我们现在将测试您的工作环境中是否可以使用本书所需的软件组件。 首先,我们建议使用 Python 的本机模块venv创建一个 Python 虚拟环境。 虚拟环境用于管理项目依赖项。 我们建议您创建的每个项目都具有自己的虚拟环境。 现在创建一个。
注意
如果您对 conda 环境更满意,请随意使用它们。
-
可以使用以下命令创建 Python 虚拟环境:
$ python3 -m venv venv $ source venv/bin/activate -
后面的命令会将字符串(
venv)附加到命令行的开头。 使用以下命令停用您的虚拟环境:$ deactivate注意
确保在处理项目时始终激活您的 Python 虚拟环境。
-
激活您的虚拟环境后,通过对文件
requirements.txt执行pip来确保安装了正确的组件。 这将尝试在该虚拟环境中安装本书中使用的模型。 如果它们已经可用,它将什么都不做:
图 3:运行 PIP 的终端的图像,用于从
requirements.txt安装依赖项通过运行以下命令来安装依赖项:
$ pip install –r requirements.txt此将为您的系统安装所有必需的依赖项。 如果它们已经安装,则此命令应仅通知您。
这些依赖项对于使用本书中的所有代码活动都是必不可少的。
作为此活动的最后一步,让我们执行脚本
test_stack.py。 该脚本正式验证了本书所需的所有包是否已在系统中安装并可用。 -
学生,运行脚本
lesson_1/activity_1/test_stack.py,检查 Python 3,TensorFlow 和 Keras 的依赖项是否可用。 使用以下命令:$ python3 lesson_1/activity_1/test_stack.py该脚本返回有用的消息,说明已安装的内容和需要安装的内容。
-
在终端中运行以下脚本命令:
$ tensorboard --help您应该看到一条帮助消息,解释每个命令的作用。 如果您没有看到该消息-或看到一条错误消息-请向您的教练寻求帮助:
图 4:运行
python3 test_stack.py的终端的图像。 该脚本返回消息,通知所有依赖项均已正确安装。注意
如果出现类似以下的消息,则无需担心:
RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6 return f(*args, **kwds)如果您运行的是 Python 3.6,并且分布式 TensorFlow 滚轮是在其他版本(本例中为 3.5)下编译的,则会显示该消息。 您可以放心地忽略该消息。
一旦我们确认已安装 Python 3,TensorFlow,Keras,TensorBoard 和
requirements.txt中概述的包,我们就可以继续进行有关如何训练神经网络的演示,然后继续使用这些工具的相同工具探索受过训练的网络。注意
对于参考解决方案,请使用
Code/Lesson-1/activity_1文件夹。
探索训练有素的神经网络
在本节中,我们探索训练有素的神经网络。 我们这样做是为了了解神经网络如何解决现实世界的问题(预测手写数字),并熟悉 TensorFlow API。 在探索该神经网络时,我们将认识到先前各节中介绍的许多组件,例如节点和层,但我们还将看到许多我们不认识的组件(例如激活函数),我们将在后续部分中进行探索。 然后,我们将完成一个有关如何训练神经网络的练习,然后自己训练该网络。
我们将要探索的网络已经过训练,可以使用手写数字的图像识别数字(整数)。 它使用了 MNIST 数据集,该数据集通常用于探索模式识别任务。
MNIST 数据集
国家标准技术混合研究所(MNIST)数据集包含 60,000 张图像的训练集和 10,000 张图像的测试集。 每个图像都包含一个手写数字。 该数据集(是美国政府创建的数据集的衍生产品)最初用于测试解决计算机系统识别手写文本问题的不同方法。 为了提高邮政服务,税收系统和政府服务的表现,能够做到这一点很重要。 对于现代方法,MNIST 数据集被认为过于幼稚。 在现代研究中(例如 CIFAR)使用了不同的和更新的数据集。 但是,MNIST 数据集对于了解神经网络的工作原理仍然非常有用,因为已知的模型可以高效地达到很高的准确率。
注意
CIFAR 数据集是机器学习数据集,其中包含按不同类别组织的图像。 与 MNIST 数据集不同,CIFAR 数据集包含许多不同领域的类,例如动物,活动和物体。 CIFAR 数据集位于这里。
图 5:MNIST 数据集训练集中的节选。 每个图像是一个单独的20x20像素的图像,带有一个手写数字。 原始数据集可在以下位置获得:http://yann.lecun.com/exdb/mnist/。
使用 TensorFlow 训练神经网络
现在,让我们训练一个神经网络,以使用 MNIST 数据集识别新数字。
我们将实现称为“卷积神经网络”的专用神经网络来解决这个问题(我们将在后面的部分中详细讨论)。 我们的网络包含三个隐藏层:两个全连接层和一个卷积层。 卷积层由以下 Python 代码的 TensorFlow 代码段定义::
W = tf.Variable(
tf.truncated_normal([5, 5, size_in, size_out],
stddev=0.1),
name="Weights")
B = tf.Variable(tf.constant(0.1, shape=[size_out]), name="Biases")
convolution = tf.nn.conv2d(input, W, strides=[1, 1, 1, 1], padding="SAME")
activation = tf.nn.relu(convolution + B)
tf.nn.max_pool(
activation,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding="SAME")
注意
请在Code/Lesson-1/activity_2/中使用mnist.py文件作为参考。 在代码编辑器中打开脚本。
在我们的网络训练期间,我们只执行一次该代码段。
变量W和B代表权重和偏差。 这些是隐藏层内的节点使用的值,用于在数据通过网络时更改网络对数据的解释。 现在不用担心其他变量。
全连接层由以下 Python 代码段定义::
W = tf.Variable(
tf.truncated_normal([size_in, size_out], stddev=0.1),
name="Weights")
B = tf.Variable(tf.constant(0.1, shape=[size_out]), name="Biases")
activation = tf.matmul(input, W) + B
注意
请在Code/Lesson-1/activity_2/中使用mnist.py文件作为参考。 在代码编辑器中打开脚本。
在这里,我们还有两个 TensorFlow 变量W和B。 请注意,这些变量的初始化非常简单:W被初始化为修剪后的高斯分布(修剪过size_in和size_out)的随机值,标准差为0.1,和B(项)初始化为0.1(常数)。 这两个值在每次运行期间都会不断变化。 该代码段执行两次,产生两个全连接网络-一个将数据传递到另一个。
那 11 行 Python 代码代表了我们完整的神经网络。 我们将在“第 2 课”,“模型架构”中详细介绍使用 Keras 的每个组件。 目前,应重点了解网络在每次运行时都会改变每个层中的W和B值,以及这些代码片段如何形成不同的层。 这 11 行 Python 是数十年来神经网络研究的高潮。
现在让我们训练该网络以评估其在 MNIST 数据集中的表现。
训练神经网络
请按照以下步骤设置此练习:
-
打开两个终端实例。
-
在这两个目录中,导航到目录
lesson_1/exercise_a。 -
在两者中,确保您的 Python 3 虚拟环境处于活动状态,并且已安装
requirements.txt中概述的要求。 -
在其中之一中,使用以下命令启动 TensorBoard 服务器:
$ tensorboard --logdir=mnist_example/ -
在另一个目录中,运行
train_mnist.py脚本。 -
启动服务器时,在提供的 TensorBoard URL 中打开浏览器。
在运行脚本train_mnist.py,的终端中,您将看到带有模型周期的进度条。 打开浏览器页面时,您将看到几个图形。 单击读取精度的那个,将其放大并让页面刷新(或单击刷新按钮)。 随着时间的流逝,您将看到模型越来越准确。
利用这一刻来说明神经网络在训练过程中尽早达到高准确率的能力。
我们可以看到,在大约 200 个周期(或步骤)内,网络的准确率超过了 90%。 也就是说,网络正确获取了测试集中 90% 的数字。 在训练到第 2000 步时,网络继续获得准确率,在此期间结束时达到 97% 的准确率。
现在,让我们也测试那些网络在看不见的数据下的表现。 我们将使用 Shafeen Tejani 创建的开源 Web 应用来探索受过训练的网络是否正确地预测了我们创建的手写数字。
使用没见过的数据测试网络表现
在浏览器中访问网站并在指定的白框中,绘制一个0和9之间的数字:
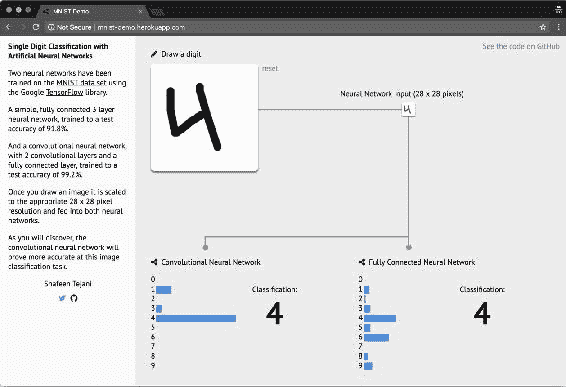
图 6:Web 应用中,我们可以手动绘制数字并测试两个受过训练的网络的准确率
注意
来源。
在应用中,您可以看到两个神经网络的结果。 我们训练过的那个在左边(称为 CNN)。 它能正确分类所有手写数字吗? 尝试在指定区域的边缘绘制编号。 例如,尝试在该区域的右边缘附近绘制数字1:

图 7:两个网络都难以估计区域边缘上绘制的值
注意
在此示例中,我们看到在绘图区域的右侧绘制了数字1。 在两个网络中,此数字为1的概率为0。
MNIST 数据集在图像边缘不包含数字。 因此,两个网络都没有为位于该区域的像素分配相关值。 如果我们将它们拉近指定区域的中心,则这两个网络都将更好地正确分类数字。 这表明神经网络只能像用于训练它们的数据一样强大。 如果用于训练的数据与我们试图预测的数据完全不同,则该网络很可能会产生令人失望的结果。
活动 2 –探索训练有素的神经网络
在本节中,我们将探索运动过程中训练的神经网络。 我们还将通过更改原始网络中的超参数来训练其他一些网络。
让我们开始探索在练习中训练的网络。 我们在本书的目录中提供了与二进制文件相同的受训网络。 让我们使用 TensorBoard 打开受过训练的网络,并探索其组件。
在您的终端上,导航至目录lesson_1/activity_2并执行以下命令以启动 TensorBoard:
$ tensorboard --logdir=mnist_example/
现在,在浏览器中打开 TensorBoard 提供的 URL。 您应该能够看到 TensorBoard 标量页面:
图 8:启动 TensorBoard 实例后的终端图像
打开tensorboard命令提供的 URL 后,您应该能够看到以下 TensorBoard 页面:
图 9:TensorBoard 登陆页面的图像
现在让我们探索我们训练有素的神经网络,看看它是如何工作的。
在 TensorBoard 页面上,单击标量页面,然后放大精度图。 现在,将平滑滑块移动到0.9。
准确率图衡量网络能够猜测测试集标签的准确率。 最初,网络猜测这些标签完全错误。 发生这种情况是因为我们已使用随机值初始化了网络的权重和偏差,因此其首次尝试只是一个猜测。 然后,网络将在第二次运行中更改其层的权重和偏差; 网络将继续通过改变其权重和偏置来投资于那些能带来积极成果的节点,并通过逐渐减少其对网络的影响(最终达到0)来惩罚那些没有结果的节点。 如您所见,这是一种非常有效的技术,可以快速产生出色的结果。
让我们将注意力集中在精度图表上。 看看在大约 1,000 个周期后,该算法如何达到很高的准确率(> 95%)? 在 1,000 到 2,000 个周期之间会发生什么? 如果我们继续训练更多的周期,它将变得更加准确吗?
当网络的精度继续提高时,在 1,000 到 2,000 之间,但是的速率下降。 如果训练更多的时间段,网络可能会略有改善,但是在当前架构下,其精度不会达到 100%。
该脚本是 Google 官方脚本的修改版,旨在显示 TensorFlow 的工作方式。 我们将脚本分为易于理解的函数,并添加了许多注释来指导您的学习。 尝试通过修改脚本顶部的变量来运行该脚本:
LEARNING_RATE = 0.0001
EPOCHS = 2000
注意
请在Code/Lesson-1/activity_2/中使用mnist.py文件作为参考。
现在,尝试通过修改这些变量的值来运行该脚本。 例如,尝试将学习率修改为0.1,将周期修改为100。 您认为网络可以达到可比的结果吗?
注意
您还可以在神经网络中修改许多其他参数。 现在,尝试网络的周期和学习率。 您会注意到,这两个超参数可以极大地改变您网络的输出,但幅度却很大。 进行实验,看看是否可以通过更改这两个参数来使用当前架构更快地训练该网络。
使用 TensorBoard 验证网络的训练方式。 通过将起始值乘以 10,再更改几次这些参数,直到您注意到网络正在改善。 调整网络并提高准确率的过程类似于当今工业应用中用于改进现有神经网络模型的过程。
总结
在本课程中,我们使用 TensorBoard 探索了经过 TensorFlow 训练的神经网络,并以不同的周期和学习率训练了我们自己的该网络的修改版本。 这为您提供了有关如何训练高性能神经网络的动手经验,还使您能够探索其某些局限性。
您认为我们可以使用真实的比特币数据达到类似的准确率吗? 在“第 2 课”,“模型结构”期间,我们将尝试使用通用的神经网络算法预测未来的比特币价格。 在“第 3 课”,“模型评估和优化”中,我们将评估和改进该模型,最后,在“第 4 课”,“产品化”,我们将创建一个程序,通过 HTTP API 对该系统进行预测。
二、模型架构
基于“第 1 课”,“神经网络和深度学习简介”的基本概念,我们现在进入一个实际问题:我们可以使用深度学习模型预测比特币价格吗? 在本课程中,我们将学习如何建立尝试这样做的深度学习模型。
我们将通过将所有这些组件放在一起并构建一个简单而完整的深度学习应用的第一个版本来结束本课程。
课程目标
在本课程中,您将:
- 为深度学习模型准备数据
- 选择正确的模型架构
- 使用 Keras,一个 TensorFlow 抽象库
- 使用训练好的模型进行预测
选择正确的模型架构
深度学习是一个正在进行大量研究活动的领域。 除其他外,研究人员致力于发明新的神经网络架构,该架构可以解决新问题或提高以前实现的架构的表现。
在本节中,我们将研究新旧架构。 较旧的架构已用于解决大量问题,并且在开始新项目时通常被认为是正确的选择。 较新的架构已在特定问题上取得了巨大的成功,但很难一概而论。 后者很有趣,可以作为下一步探索的参考,但在启动项目时并不是一个好的选择。
通用架构
考虑到有许多种可能的架构,经常被用作两种应用的两种流行架构:卷积神经网络(CNN)和 循环神经网络(RNN)。 这些是基本的网络,应该被视为大多数项目的起点。 由于它们在该领域中的相关性,我们还包括了另外三个网络的描述: RNN 变体的长短期记忆(LSTM)网络; 生成对抗网络(GAN); 和深度强化学习。 后面的这些架构在解决当代问题方面取得了巨大的成功,但是使用起来有些困难。
卷积神经网络
卷积神经网络因处理具有网格状结构的问题而臭名昭著。 它们最初是为了对图像进行分类而创建的,但已用于许多其他领域,从语音识别到自动驾驶车辆。
CNN 的基本见解是将紧密相关的数据用作训练过程的特征,而不仅仅是单个数据输入。 这个想法在图像的上下文中特别有效,因为位于另一个像素右边的一个像素也与该像素有关,因为它们构成了较大合成的部分。 在这种情况下,网络正在训练预测该组成。 因此,将几个像素组合在一起比单独使用单个像素更好。
卷积的名称是,以表示此过程的数学表达式:
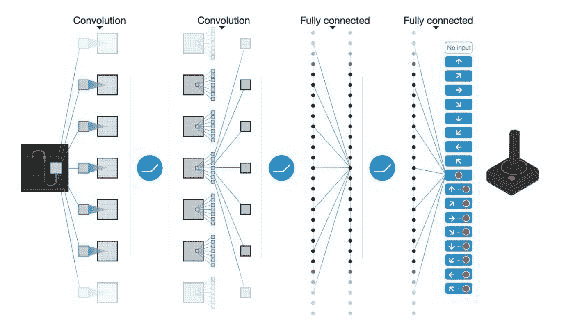
图 1:卷积过程的图示图像来源:Volodymyr Mnih 等。
注意
有关更多信息,请参考《通过深度强化学习进行人类水平控制》。
循环神经网络
卷积神经网络与一组输入一起工作,这些输入不断改变网络各个层和节点的权重和偏差。 这种方法的一个已知局限性是,在确定如何更改网络的权重和偏差时,其架构会忽略这些输入的顺序。
专门创建了循环神经网络来解决该问题。 RNN 旨在处理顺序数据。 这意味着在每个周期,各层都会受到先前层的输出的影响。 给定序列中的先前观测值的记忆在后验观测值的评估中起作用。
由于该问题的顺序性质,RNN 已在语音识别中成功应用。 此外,它们还用于翻译问题。 Google Translate 当前的算法转换器使用 RNN 将文本从一种语言翻译成另一种语言。
注意
有关更多信息,请参阅 Jakob Uszkoreit 撰写的《转换器:一种用于语言理解的新型神经网络架构》。
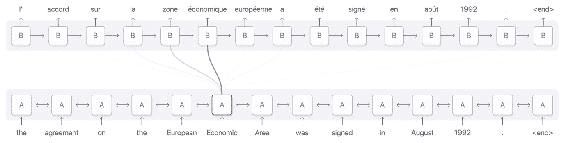
图 2:来自 distill.pub 的插图。
图 2 根据单词在句子中的位置显示英语单词与法语单词相关。 RNN 在语言翻译问题中非常受欢迎。
长期短期存储网络是为解决消失的梯度问题而创建的 RNN 变体。 逐渐消失的梯度问题是由与当前步骤相距太远的内存组件引起的,并且由于它们的距离而将获得较低的权重。 LSTM 是 RNN 的变体,其中包含一个称为遗忘门的内存组件。 该组件可用于评估最新元素和旧元素如何影响权重和偏差,具体取决于观察值在序列中的位置。
注意
有关更多详细信息,请参见 1997 年 Sepp Hochreiter 和 JürgenSchmidhuber 首次引入 LSTM 架构。当前的实现已进行了一些修改。 有关 LSTM 每个组件如何工作的详细数学解释,我们建议克里斯托弗·奥拉(Christopher Olah)于 2015 年 8 月发表的文章《了解 LSTM 网络》。
生成对抗网络
生成对抗网络(GAN)由蒙特利尔大学的 Ian Goodfellow 和他的同事于 2014 年发明。 GAN 提出,与其拥有一个优化权重和偏向以最小化其误差为目标的神经网络,不如两个神经网络为此目的相互竞争。
注意
有关更多详细信息,请参见 Ian Goodfellow 等人的《生成对抗网络》。
GAN 具有生成新数据(即“伪”数据)的网络和评估由第一个网络生成的数据为真实或“伪”数据的可能性的网络。 他们之所以竞争是因为两者都学到了:一种学习如何更好地生成“伪”数据,另一种学习如何区分所呈现的数据是否真实。 它们在每个周期都进行迭代,直到它们都收敛为止。 这就是评估生成的数据的网络无法再区分“伪数据”和真实数据的时候。
GAN 已成功用于数据具有清晰拓扑结构的领域。 它的原始实现使用 GAN 来创建对象,人脸和动物的合成图像,这些图像类似于这些东西的真实图像。 GAN 是最常使用图像创建的领域,但是研究论文中偶尔会出现其他领域的应用。

图 3:该图像显示了不同 GAN 算法根据给定的情感来改变人脸的结果。 资料来源:StarGAN 项目。
深度强化学习
原始 DRL 架构受到总部位于英国的 Google 拥有的人工智能研究组织 DeepMind 的支持。 DRL 网络的关键思想是,它们本质上不受监督,可以从试错中学习,仅针对奖励函数进行优化。 也就是说,与其他网络(使用监督方法来优化预测的错误程度(与已知的正确方法相比)不同)相比,DRL 网络并不知道正确的解决问题的方法。 它们只是被赋予系统规则,然后在每次正确执行功能时得到奖励。 这个过程需要大量的迭代,最终会训练网络使其在许多任务中脱颖而出。
注意
有关更多信息,请参阅《通过深度强化学习进行人类水平控制》。
在 DeepMind 创建 AlphaGo 之后,深度强化学习(DRL)模型获得了普及,AlphaGo 是一种玩 Go 游戏的系统,其表现优于专业玩家。 DeepMind 还创建了 DRL 网络,该网络完全依靠自己来学习如何以超人的水平玩视频游戏:
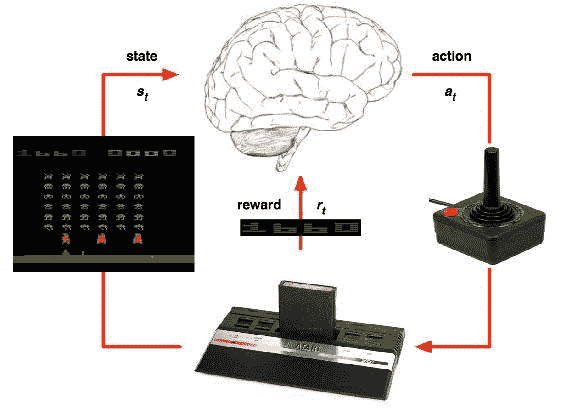
图 4:代表 DQN 算法工作原理的图像
注意
有关更多信息,请参阅 DeepMind 创建的 DQN,以击败 Atari 游戏。 该算法使用深度强化学习解决方案来不断增加其奖励。 图片来源。
| 架构 | 数据结构 | 成功的应用 |
|---|---|---|
| 卷积神经网络(CNN) | 网格状的拓扑结构(即图像) | 图像识别与分类 |
| 循环神经网络(RNN)和长短期记忆(LSTM)网络 | 顺序数据(即时间序列数据) | 语音识别,文本生成和翻译 |
| 生成对抗网络(GAN) | 网格状的拓扑结构(即图像) | 图像生成 |
| 深度强化学习(DRL) | 规则明确,奖励函数明确的系统 | 玩电子游戏和自动驾驶汽车 |
表 1:不同的神经网络架构已在不同领域取得成功。 网络的架构通常与当前问题的结构有关。
数据标准化
在建立深度学习模型之前,还需要采取以下步骤:数据规范化。
数据规范化是机器学习系统中的常见做法。 特别是在神经网络方面,研究人员提出,归一化是训练 RNN(和 LSTM)的一项必不可少的技术,主要是因为它减少了网络的训练时间并提高了网络的整体表现。
注意
有关更多信息,请参考 Sergey Ioffe 等人的《批量归一化:通过减少内部协变量偏移来加速深度网络训练》。
根据数据和手头的问题,对进行归一化技术的决定会有所不同。 通常使用以下技术。
Z 得分
当数据以呈正态分布(即高斯)时,可以将每个观测值之间的距离计算为与其平均值的标准差。 当标识数据点与分布中更可能出现的地方相距多远时,此规范化很有用。 Z 分数定义为:
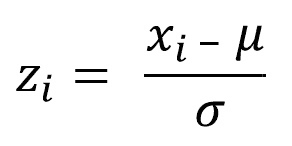
此处,x[i]是第i个观察值,μ是平均值,而σ是序列的标准差。
注意
有关更多信息,请参阅维基百科的标准评分(Z 评分)文章。
点相对归一化
此归一化计算给定观测值与序列的第一个观测值的差。 这种规范化对于识别与起点有关的趋势很有用。 点相对归一化定义为:

在此,o[i]是第i个观测值,o[0]是该序列的第一个观测值。
注意
正如 Siraj Raval 在视频中建议的,《如何轻松预测股票价格 - 深度学习入门 7》,可在 YouTube 上找到。
最大最小归一化
此归一化计算给定观察值与序列的最大值和最小值之间的距离。 当使用序列时,此最大值很有用,在该序列中,最大值和最小值不是离群值,并且对于将来的预测很重要。 此规范化技术可以应用于:
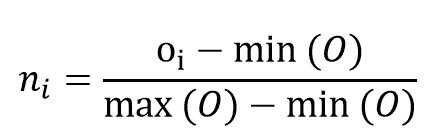
在这里,o[i]是第i个观测值,O表示具有所有0值的向量,并且函数 min(O)和max(O)分别表示该序列的最小值和最大值。
在“活动 3”,“探索比特币数据集并为模型准备数据”中,我们将准备可用的比特币数据以用于我们的 LSTM 模式。 其中包括选择感兴趣的变量,选择相关时段并应用先前的点相对归一化技术。
解决问题
与研究人员相比,从业人员在启动新的深度学习项目时花费更少的时间来确定选择哪种架构。 在开发这些系统时,最重要的考虑因素是正确获取代表给定问题的数据,其次是了解数据集的固有偏差和局限性。
在开始开发深度学习系统时,请考虑以下问题以进行反思:
- 我有正确的数据吗? 这是训练深度学习模型时最困难的挑战。 首先,用数学规则定义问题。 使用精确的定义并按类别(分类问题)或连续规模(回归问题)组织问题。 现在,您如何收集有关这些指标的数据?
- 我有足够的数据吗? 通常,深度学习算法在大型数据集中表现出比在小型数据集中更好的表现。 了解训练高性能算法所需的数据量取决于您要解决的问题类型,但目的是要收集尽可能多的数据。
- 我可以使用预训练的模型吗? 如果您要解决的问题是更一般的应用的子集(但在同一领域内),请考虑使用预训练的模型。 预训练的模型可以让您抢先解决特定问题的模式,而不是整个领域的更一般特征。 正式的 TensorFlow 仓库是一个不错的起点。
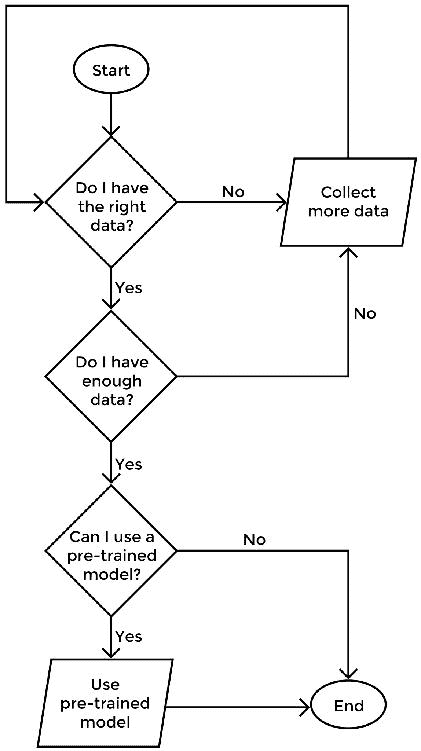
图 5:在深度学习项目开始时要做出的关键思考问题的决策树
在某些情况下,可能根本无法获得数据。 根据情况,可能可以使用一系列技术从输入数据中有效创建更多数据。 此过程称为数据扩充,在处理图像识别问题时已成功应用。
注意
很好的参考是文章《使用深度神经网络对浮游生物进行分类》。 作者展示了一系列用于增强少量图像数据以增加模型具有的训练样本数量的技术。
活动 3 – 探索比特币数据集并为模型准备数据
我们将使用最初从 CoinMarketCap 检索的公共数据集,该数据是一个流行的网站,跟踪不同的加密货币统计数据。 数据集已在本课程中提供,并将在本书的其余部分中使用。
我们将使用 Jupyter 笔记本探索数据集。 Jupyter 笔记本通过网络浏览器提供 Python 会话,使您可以交互地处理数据。 它们是用于探索数据集的流行工具。 在本书的所有活动中都将使用它们。
使用您的终端,导航到目录lesson_2/activity_3并执行以下命令以启动 Jupyter 笔记本实例:
$ jupyter notebook
现在,在浏览器中打开应用提供的 URL。 您应该能够看到 Jupyter 笔记本页面,其中包含文件系统中的许多目录。
您应该看到以下输出:
图 6:启动 Jupyter 笔记本实例后的终端镜像。 导航到浏览器中显示的 URL,您应该能够看到 Jupyter 笔记本登陆页面。
现在,导航至目录,然后单击文件Activity_3_Exploring_Bitcoin_Dataset.ipynb。 这是一个 Jupyter 笔记本文件,将在新的浏览器选项卡中打开。 该应用将自动为您启动一个新的 Python 交互式会话。
图 7:Jupyter 笔记本实例的登录页面
图 8:笔记本的图像Activity_3_Exploring_Bitcoin_Dataset.ipynb。 您现在可以与该笔记本进行交互并进行修改。
在打开我们的 Jupyter 笔记本电脑之后,现在让我们探索本课程提供的比特币数据。
数据集data/bitcoin_historical_prices.csv包含自 2013 年初以来比特币价格的度量。最近的观察是在 2017 年 11 月,该数据集来自每日更新的在线服务 CoinMarketCap。 它包含八个变量,其中两个(date和week)描述数据的时间段(可以用作索引),另外六个变量(open,high,low,close,volume和market_capitalization),可用于了解比特币的价格和价值如何随时间变化:
| 变量 | 描述 |
|---|---|
date |
观察日期。 |
iso_week |
给定年份的星期数。 |
open |
单个比特币硬币的开盘价值。 |
high |
在给定的一天时间内实现的最高价值。 |
low |
在给定的一天内实现的最低价值。 |
close |
交易日结束时的价值。 |
volume |
当天交换的比特币总量。 |
market_capitalization |
市值,由市值 = 价格 * 循环供给来解释。 |
表 2:比特币历史价格数据集中的可用变量(即列)
现在使用打开的 Jupyter 笔记本实例,我们探索其中两个变量的时间序列:close和volume。 我们将从这些时间序列开始探讨价格波动模式。
导航到 Jupyter 笔记本Activity_3_Exploring_Bitcoin_Dataset.ipynb的打开的实例。 现在,执行标题Introduction下的所有单元格。 这将导入所需的库并将数据集导入内存。
将数据集导入内存后,移至Exploration部分。 您将找到一个代码片段,该代码片段为close变量生成时间序列图。 您可以为volume变量生成相同的图吗?
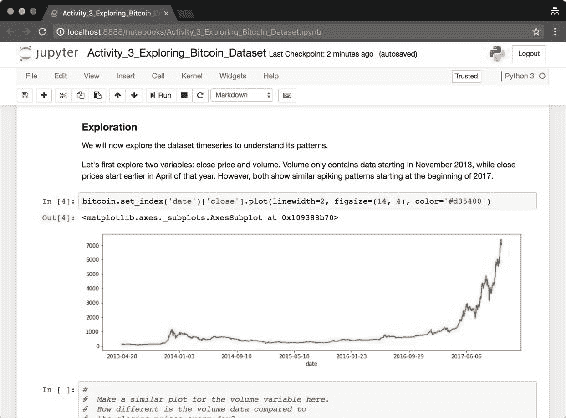
图 9:来自close变量的比特币收盘价的时间序列图。 重现此图,但在此图下面的新单元格中使用volume变量。
您肯定会注意到这两个变量在 2017 年都在激增。这反映了当前的现象,即比特币的价格和价值自该年年初以来一直在持续增长。
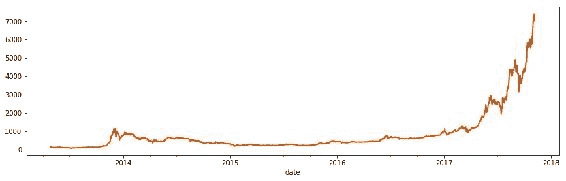
图 10:以美元计的比特币硬币的收盘价。 请注意,2013 年底和 2014 年初出现了早期的飙升。此外,请注意,自 2017 年初以来,最近的价格已飙升。
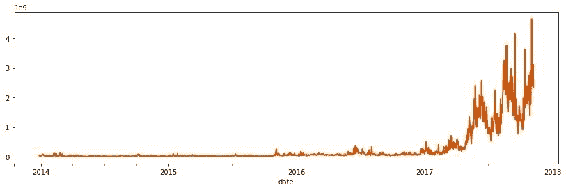
图 11:比特币硬币的交易量(以美元为单位)显示,从 2017 年开始,趋势开始了,市场上交易的比特币数量明显增加。 每日总交易量的变化远大于每日收盘价。
此外,我们注意到,多年来,比特币价格的波动幅度不如近年来。 尽管这些时间段可以被神经网络用来理解某些模式,但是我们将排除较早的观察结果,因为我们有兴趣预测不太遥远的周期的未来价格。 让我们仅过滤 2016 年和 2017 年的数据。
导航至,“为模型准备数据集”部分。 我们将使用pandas API 过滤 2016 年和 2017 年的数据。Pandas 提供了直观的 API 来执行此操作:
bitcoin_recent = bitcoin[bitcoin['date'] >= '2016-01-01']
变量bitcoin_recent现在具有我们原始比特币数据集的副本,但已过滤为更新或等于 2016 年 1 月 1 日的观测值。
作为最后一步,我们现在使用“数据归一化”部分中介绍的点相对归一化技术对数据进行归一化。 我们将仅归一化两个变量(close和volume),因为这是我们正在努力预测的变量。
在包含本课程的同一目录中,我们放置了一个名为normalizations.py的脚本。 该脚本包含本课中描述的三种标准化技术。 我们将该脚本导入到 Jupyter 笔记本中,并将这些功能应用于我们的序列。
导航到“为模型准备数据集”部分。 现在,使用iso_week变量使用 pandas 方法groupby()将给定一周中的全天观察分组。 现在,我们可以在一周内将归一化函数normalizations.point_relative_normalization()直接应用于该序列。 我们使用以下命令将该归一化的输出存储为同一 Pandas 数据帧中的新变量:
bitcoin_recent['close_point_relative_normalization'] =
bitcoin_recent.groupby('iso_week')['close'].apply(
lambda x: normalizations.point_relative_normalization(x))
现在,变量close_point_relative_normalization包含变量close的规范化数据。 对变量volume执行相同的操作:
图 12:Jupyter 笔记本的图像,重点是应用归一化函数的部分
标准化的close变量每周包含一个有趣的方差模式。 我们将使用该变量来训练我们的 LSTM 模型。
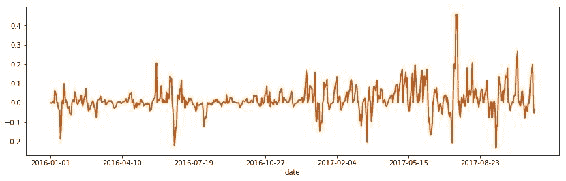
图 13:显示归一化变量close_point_relative_normalization的序列的图
为了评估模型的效果,我们需要对照其他数据测试其准确率。 为此,我们创建了两个数据集:训练集和测试集。 在本活动中,我们将使用 80% 的数据集训练 LSTM 模型,并使用 20% 的数据评估其表现。
鉴于数据是连续的并且采用时间序列的形式,我们将可用周的最后 20% 用作测试集,并将前 80% 用作训练集:
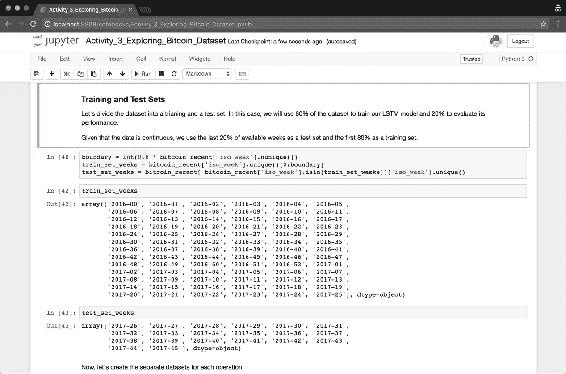
图 14:使用几周来创建训练和测试集
最后,将导航到Storing Output部分,并将过滤后的变量保存到磁盘,如下所示:
test_dataset.to_csv('data/test_dataset.csv', index=False)
train_dataset.to_csv('data/train_dataset.csv', index=False)
bitcoin_recent.to_csv('data/bitcoin_recent.csv', index=False)
注意
对于参考解决方案,请使用Code/Lesson-2/activity_3文件夹。
在本节中,我们探索了比特币数据集,并将其准备好用于深度学习模型。
我们了解到,在 2017 年期间,比特币的价格飞涨。 这种现象需要很长时间才能发生-并可能受此数据无法单独解释的许多外部因素的影响(例如,其他加密货币的出现)。 我们还使用点相对归一化技术按周块处理比特币数据集。 我们这样做是为了训练 LSTM 网络来学习比特币价格每周变化的模式,从而可以预测未来整整一周的时间。
但是,比特币统计数据显示每周都有重大波动。 我们可以预测未来的比特币价格吗? 从现在开始的 7 天里,这些价格将是多少? 我们将在下一部分中使用 Keras 构建一个深度学习模型来探讨这个问题。
使用 Keras 作为 TensorFlow 接口
本节重点介绍 Keras。 我们之所以使用 Keras,是因为它将 TensorFlow 接口简化为通用抽象。 在后端,计算仍然在 TensorFlow 中执行,并且仍然使用 TensorFlow 组件构建图,但是接口要简单得多。 我们花费较少的时间来担心诸如变量和运算之类的各个组件,而花费更多的时间将网络构建为计算单元。 Keras 使您可以轻松地尝试不同的架构和超参数,从而更快地向高性能解决方案迈进。
从 TensorFlow 1.4.0(2017 年 11 月)开始,Keras 现在以 TensorFlow 作为tf.keras正式发行。 这表明 Keras 现在已经与 TensorFlow 紧密集成,并且很可能会在很长一段时间内继续作为开源工具进行开发。
模型组件
正如我们在“第 1 课”,“神经网络和深度学习简介”中看到的那样,LSTM 网络也具有输入,隐藏和输出层。 每个隐藏层都有一个激活函数,用于评估该层的相关权重和偏差。 正如预期的那样,网络将数据从一层顺序移到另一层,并在每次迭代(即一个周期)时通过输出评估结果。
Keras 提供了直观的类来表示这些组件中的每个组件:
| 组件 | Keras 类 |
|---|---|
| 完整的顺序神经网络的高级抽象。 | keras.models.Sequential() |
| 密集的全连接层。 | keras.layers.core.Dense() |
| 激活函数。 | keras.layers.core.Activation() |
| LSTM 循环神经网络。 此类包含此架构专有的组件,其中大多数由 Keras 抽象。 | keras.layers.recurrent.LSTM() |
表 3:Keras API 中的关键组件说明。 我们将使用这些组件来构建深度学习模型。
Keras 的keras.models.Sequential()组件代表整个顺序的神经网络。 可以单独实例化该 Python 类,然后再添加其他组件。
我们对构建 LSTM 网络感兴趣,因为这些网络在使用顺序数据时表现良好,而时间序列是一种顺序数据。 使用 Keras,完整的 LSTM 网络将实现如下:
from keras.models import Sequential
from keras.layers.recurrent import LSTM
from keras.layers.core import Dense, Activation
model = Sequential()
model.add(LSTM(
units=number_of_periods,
input_shape=(period_length, number_of_periods)
return_sequences=False), stateful=True)
model.add(Dense(units=period_length))
model.add(Activation("linear"))
model.compile(loss="mse", optimizer="rmsprop")
片段 1:使用 Keras 的 LSTM 实现
此实现将在“第 3 课”,“模型评估和优化”中进一步优化。
Keras 抽象允许人们专注于使深度学习系统更具表现的关键元素:正确的组件顺序,要包含的层和节点的数量以及要使用的激活函数。 所有这些选择都取决于将组件添加到实例化的keras.models.Sequential()类的顺序或通过传递给每个组件实例化的参数(即Activation("linear"))确定的。 最后的model.compile()步骤使用 TensorFlow 组件构建神经网络。
建立网络后,我们使用model.fit()方法训练网络。 这将产生一个经过训练的模型,可用于进行预测:
model.fit(
X_train, Y_train,
batch_size=32, epochs=epochs)
“代码段 2.1”:
model.fit()的用法
变量X_train和Y_train分别是用于训练的集合和用于评估损失函数(即测试网络预测数据的能力)的较小集合。
最后,我们可以使用model.predict()方法进行预测:
model.predict(x=X_train)
“代码段 2.2”:
model.predict()的用法
前面的步骤介绍了使用神经网络的 Keras 范例。 尽管可以用非常不同的方式处理不同的架构,但是 Keras 通过使用以下三个组件简化了使用不同架构的接口:网络架构,适应性和预测性:

图 15:Keras 神经网络范例:A. 设计神经网络架构,B. 训练神经网络(或拟合),以及 C. 进行预测
Keras 允许在每个步骤中进行更大的控制。 但是,其重点是使用户在尽可能短的时间内尽可能轻松地创建神经网络。 这意味着我们可以从一个简单的模型开始,然后在上述每个步骤中增加复杂性,以使初始模型的表现更好。
在即将进行的活动和课程中,我们将利用该范例。 在下一个活动中,我们将创建最简单的 LSTM 网络。 然后,在“第 3 课”,“模型评估和优化”中,我们将不断评估和更改该网络,以使其更加健壮和高效。
活动 4 – 使用 Keras 创建 TensorFlow 模型
在此活动中,我们将使用 Keras 创建一个 LSTM 模型。
Keras 用作较低级程序的接口; 在这种情况下,使用 TensorFlow。 当我们使用 Keras 设计神经网络时,该神经网络被编译为 TensorFlow 计算图。
导航到 Jupyter 笔记本Activity_4_Creating_a_TensorFlow_Model_Using_Keras.ipynb的打开的实例。 现在,执行标题构建模型下的所有单元格。 在该部分中,我们建立第一个参数化两个值的 LSTM 模型:训练观察的输入大小(一天相当于 1 个值)和预测期间的输出大小(在我们的情况下为 7 天):
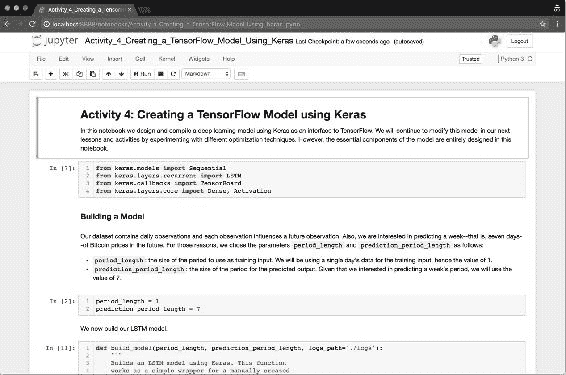
图 16:来自 Jupyter 笔记本实例的图像,我们在其中构建了 LSTM 模型的第一个版本
使用 Jupyter 笔记本Activity_4_Creating_a_TensorFlow_Model_Using_Keras.ipynb从“模型组件”部分构建相同的模型,对输入和输出的周期长度进行参数设置,以便进行实验。
编译模型后,我们将其作为h5文件存储在磁盘上。 优良作法是偶尔将模型的版本存储在磁盘上,以便将模型架构的版本与预测特征一起保留。
仍在同一 Jupyter 笔记本的上,导航至标题保存模型。 在该部分中,我们将使用以下命令将模型存储为磁盘上的文件:
model.save('bitcoin_lstm_v0.h5')
模型'bitcoin_lstm_v0.h5'尚未训练。 如果在没有事先训练的情况下保存模型,则只能有效地保存模型的架构。 稍后可以使用 Keras 的load_model()函数来加载相同的模型,如下所示:
1 model = keras.models.load_model('bitcoin_lstm_v0.h5')
注意
加载 Keras 库时,您可能会遇到以下警告:
Using TensorFlow backend.
可以将 Keras 配置为使用其他后端而不是 TensorFlow(即 Theano)。 为了避免出现此消息,您可以创建一个名为keras.json的文件并在那里配置其后端。 该文件的正确配置取决于您的系统。 因此,建议您访问 Keras 官方文档。
注意
对于参考解决方案,请使用Code/Lesson-2/activity_4文件夹。
在本部分中,我们学习了如何使用 TensorFlow 的接口 Keras 构建深度学习模型。 我们研究了 Keras 的核心组件,并使用这些组件构建了基于 LSTM 模型的比特币价格预测系统的第一版。
在下一节中,我们将讨论如何将本课中的所有组件整合到一个(几乎完整的)深度学习系统中。 该系统将产生我们最初的预测,作为未来改进的起点。
从数据准备到建模
本节重点介绍深度学习系统的实现方面。 我们将使用“选择正确的模型架构”中的比特币数据和 Keras 知识,并使用 Keras 作为 TensorFlow 接口将这两个组件组合在一起。 本节通过构建一个从磁盘读取数据并将其作为单个软件馈入模型的系统来结束本课程。
训练神经网络
神经网络可能需要很长时间才能训练。 许多因素影响该过程可能需要多长时间。 其中,三个因素通常被认为是最重要的:
- 网络架构
- 网络有多少层和神经元
- 训练过程中将使用多少数据
其他因素也可能极大地影响网络训练所需的时间,但是神经网络在解决业务问题时可以进行的大多数优化来自探索这三个方面。
我们将使用上一节中的归一化数据。 回想一下,我们已将训练数据存储在名为train_dataset.csv的文件中。 我们将使用pandas将数据集加载到内存中,以方便探索:
import pandas as pd
train = pd.read_csv('data/train_dataset.csv')
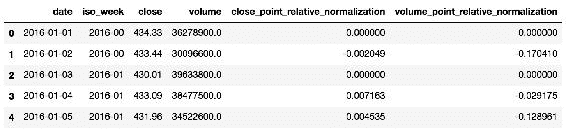
图 17:该表显示了从train_d–ataset.csv文件加载的训练数据集的前五行
自 2016 年初以来,我们将使用变量close_point_relative_normalization的序列,该序列是变量close的归一化比特币收盘价序列。
变量close_point_relative_normalization已每周标准化。 该周的周期的每个观察值都是相对于该周期第一天收盘价的差额进行的。 标准化步骤很重要,将有助于我们的网络训练更快。
图 18:显示归一化变量
close_point_relative_normalization的序列的图。 此变量将用于训练我们的 LSTM 模型。
重塑时间序列数据
神经网络通常使用向量和张量,这两个数学对象都可以在多个维度上组织数据。 用 Keras 实现的每个神经网络都将具有根据规范进行组织的向量或张量作为输入。 首先,了解如何将数据重整为给定层所需的格式可能会造成混淆。 为避免混淆,建议从尽可能少的组件开始,然后逐渐添加组件。 Keras 的官方文档(在“层”部分下)对于了解每种层的要求至关重要。
注意
可在这个页面上获得 Keras 官方文档。 该链接直接将您带到“层”部分。
注意
NumPy是一个流行的 Python 库,用于执行数值计算。 深度学习社区使用它来操纵向量和张量,并为深度学习系统做好准备。
特别是,在为深度学习模型调整数据时,numpy.reshape()方法非常重要。 该模型允许对NumPy数组进行操作,这是类似于向量和张量的 Python 对象。
现在,我们使用 2016 年和 2017 年的星期来组织变量close_point_relative_normalization的价格。我们创建不同的组,每个组包含七个观测值(一周中的每一天),共 77 个完整星期。 我们之所以这样做,是因为我们有兴趣预测一周交易量的价格。
注意
我们使用 ISO 标准来确定一周的开始和结束。 其他类型的组织也是完全可能的。 遵循此方法既简单又直观,但是仍有改进的空间。
LSTM 网络使用三维张量。 这些维度中的每一个都代表了网络的一项重要属性。 这些大小是:
- 周期长度:周期长度,即,一个周期中有多少个观测值
- 周期数:数据集中有多少个周期可用
- 特征数量:数据集中可用的特征数量
目前,来自变量close_point_relative_normalization的数据是一维向量,我们需要对其进行重塑以匹配这三个维度。
我们将以一周的时间为。 因此,我们的周期长度为 7 天(周期长度为 7)。 我们的数据中有 77 个完整的星期可用。 在训练期间,我们将使用这周的最后一周来测试我们的模型。 这给我们留下了 76 个不同的星期(周期数为 76)。 最后,我们将在此网络中使用单个特征(特征数量为 1)-将来的版本中将包含更多特征。
我们如何重塑数据以匹配这些维度? 我们将结合使用基本的 Python 属性和numpy库中的reshape()。 首先,我们使用纯 Python 创建 76 个不同的星期组,每个星期 7 天:
group_size = 7
samples = list()
for i in range(0, len(data), group_size):
sample = list(data[i:i + group_size])
if len(sample) == group_size:
samples.append(np.array(sample).reshape(group_size, 1).tolist())
data = np.array(samples)
“代码段 3”:创建不同星期组的 Python 代码段
结果变量data是包含所有正确大小的变量。 Keras LSTM 层期望这些维度以特定的顺序进行组织:特征数量,观测数量和周期长度。 让我们重塑数据集以匹配该格式:
X_train = data[:-1,:].reshape(1, 76, 7)
Y_validation = data[-1].reshape(1, 7)
“代码段 5”:代码段显示了如何训练我们的模型
注意
每个 Keras 层都希望以特定方式组织其输入。 但是,在大多数情况下,Keras 将相应地重塑数据。 在添加新层或遇到层形状问题时,请始终参阅层上的 Keras 文档。
“代码段 4”也选择我们集合的最后一周作为验证集合(通过data[-1])。 我们将尝试使用前 76 周来预测数据集中的最后一周。
下一步是使用这些变量来拟合我们的模型:
model.fit(x=X_train, y=Y_validation, epochs=100)
LSTM 是计算上昂贵的模型。 在现代计算机上,我们最多可能需要五分钟来训练我们的数据集。 当算法创建完整的计算图时,该时间中的大部分都花在了计算的开始。 开始训练后,该过程将加快速度:
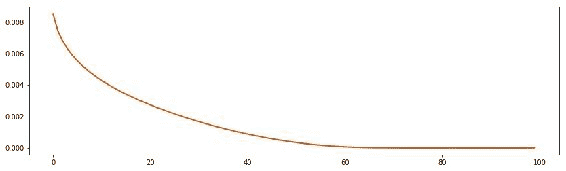
图 19:该图显示了每个周期评估的损失函数的结果
注意
这将比较模型在每个周期预测的结果,然后使用称为均方误差的技术将其与实际数据进行比较。 该图显示了这些结果。
乍一看,我们的网络运行情况非常好:它以很小的错误率开始,并不断降低。 现在,我们的预测告诉我们什么?
做出预测
在训练好网络之后,我们现在可以进行预测了。 我们将对超出时段的未来一周进行预测。
一旦我们用model.fit(),训练了我们的模型,做出预测就变得微不足道了:
model.predict(x=X_train)
“代码段 6”:使用我们之前用于训练的数据进行预测
我们使用与用于训练的数据(X_train变量)相同的数据进行预测。 如果有更多可用数据,则可以改用 LSTM 要求的格式,而可以改用它。
过拟合
当神经网络过度适合于验证集时,意味着它会学习训练集中存在的模式,但无法将其推广到看不见的数据(例如测试集)。 在下一课中,我们将学习如何避免过拟合,并创建一个系统来评估我们的网络并提高其表现:
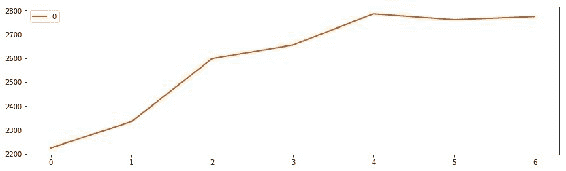
图 20:归一化后,我们的 LSTM 模型预测,到 2017 年 7 月下旬,比特币的价格将从 2200 美元增加到大约 2800 美元,一周内增长 30%
活动 5 – 组装深度学习系统
在本活动中,我们将构建基本的深度学习系统的所有基本特征汇总在一起:数据,模型和预测。
我们将继续使用 Jupyter 笔记本,并将使用之前练习中准备的数据(data/train_dataset.csv)和我们本地存储的模型(bitcoin_lstm_v0.h5)。
-
启动 Jupyter 笔记本实例后,导航到名为
Activity_5_Assembling_a_Deep_Learning_System.ipynb的笔记本并打开它。 执行标题中的单元以加载所需的组件,然后导航至标题Shaping Data:
图 21:显示归一化变量
close_point_relative_normalization的序列的图注意
close_point_relative_normalization变量将用于训练我们的 LSTM 模型。我们将通过加载先前活动中准备的数据集来开始。 我们使用
pandas将数据集加载到内存中。 -
使用 Pandas 将训练数据集加载到内存中,如下所示:
train = pd.read_csv('data/train_dataset.csv') -
现在,通过执行以下命令快速检查数据集:
train.head()如本课程中所述,LSTM 网络需要具有三个维度的张量。 这些维度是:周期长度,周期数和特征数。
现在,继续创建每周组,然后重新排列结果数组以匹配这些大小。
-
随时使用提供的函数
create_groups()执行此操作:create_groups(data=train, group_size=7)该函数的默认值为 7 天。 如果将该数字更改为其他值(例如 10),会发生什么情况?
现在,确保将数据分为两组:训练和验证。 为此,我们将比特币价格数据集中的最后一周分配给评估集。 然后,我们训练网络对上周进行评估。
分开训练数据的最后一周,并使用
numpy.reshape()对其进行调整。 重塑很重要,因为 LSTM 模型仅接受以这种方式组织的数据:X_train = data[:-1,:].reshape(1, 76, 7) Y_validation = data[-1].reshape(1, 7)现在我们的数据已准备好用于训练。 现在,我们加载先前保存的模型,并以给定的周期数对其进行训练。
-
导航至标题加载我们的模型并加载我们先前训练过的模型:
model = load_model('bitcoin_lstm_v0.h5') -
现在,使用我们的训练数据
X_train和Y_validation训练模型:history = model.fit( x=X_train, y=Y_validation, batch_size=32, epochs=100)注意,我们将模型的日志存储在名为
history的变量中。 模型日志对于探索训练精度的特定变化以及了解损失函数的执行情况非常有用:
图 22:Jupyter 笔记本的部分,我们在其中加载早期模型并使用新数据进行训练
最后,让用我们训练有素的模型进行预测。
-
使用相同的数据
X_train,调用以下方法:model.predict(x=X_train) -
该模型会立即返回标准化值列表以及接下来 7 天的预测。 使用
denormalize()函数将数据转换为美元值。 使用可用的最新值作为缩放预测结果的参考:denormalized_prediction = denormalize(predictions, last_weeks_value)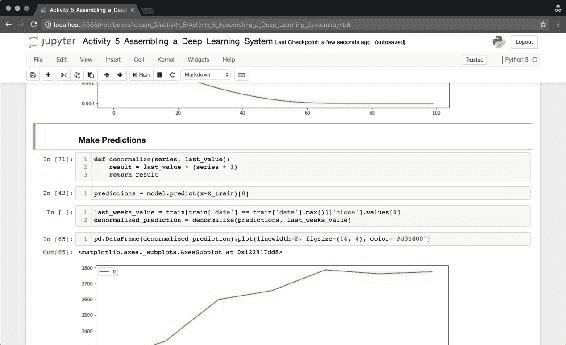
图 23:Jupyter 笔记本部分,我们在其中预测了未来 7 天的比特币价格。 我们的预测表明价格将大幅上涨约 30%。
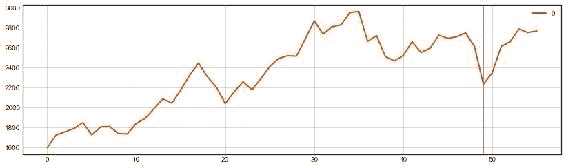
图 24:使用我们刚刚建立的 LSTM 模型预测未来 7 天的比特币价格
注意
我们在此图中组合了两个时间序列:实际数据(在行之前)和预测数据(在行之后)。 该模型显示出与之前看到的模式相似的方差,并且表明接下来的 7 天之内价格上涨。
-
完成实验后,请使用以下命令保存模型:
model.save('bitcoin_lstm_v0_trained.h5')我们将保存此训练有素的网络以供将来参考,并将其表现与其他模型进行比较。
网络可能已经从我们的数据中学到了模式,但是如何用如此简单的架构和很少的数据来做到这一点呢? LSTM 是用于从数据中学习模式的强大工具。 但是,我们将在接下来的课程中学习到,他们也可能遭受过拟合的困扰,这是神经网络中常见的一种现象,他们会从训练数据中学习模式,这些模式在预测实际模式时无用 。 我们将学习如何处理该问题以及如何改进我们的网络以做出有用的预测。
注意
对于参考解决方案,请使用
Code/Lesson-2/activity_5文件夹。
总结
在本课程中,我们组装了一个完整的深度学习系统:从数据到预测。 在本活动中创建的模型必须加以大量改进,才能被认为有用。 但是,它是我们不断改进的一个很好的起点。
我们的下一课将探讨用于衡量模型表现的技术,并将继续进行修改,直到获得一个既有用又健壮的模型。
三、模型评估和优化
本课程侧重于如何评估神经网络模型。 与使用其他模型不同,在使用神经网络时,我们修改了网络的超参数以提高其表现。 但是,在更改任何参数之前,我们需要测量模型的表现。
课程目标
在本课程中,您将:
-
评估模型
- 探索神经网络解决的问题类型
- 探索损失函数,准确率和错误率
- 使用 TensorBoard
- 评估指标和技术
-
超参数优化
- 添加层和节点
- 探索并添加周期
- 实现激活函数
- 使用正则化策略
模型评估
在机器学习中,定义两个不同的术语是的共同点:参数和超参数。 参数是影响模型如何根据数据进行预测的属性。 超参数是指模型如何从数据中学习。 可以从数据中学习参数并进行动态修改。 超参数是高级属性,通常不会从数据中学习。 有关更详细的概述,请参阅 Sebastian Raschka 和 Vahid Mirjalili 撰写的书《Python 机器学习》。
问题类别
通常,神经网络可以解决两类问题:分类和回归。 分类问题涉及根据数据对正确类别的预测; 例如,如果温度为热或冷。 回归问题与连续标量中值的预测有关。 例如,实际温度值是多少?
这两个类别中的问题具有以下特性:
- 分类:以类别为特征的问题。 类别可以不同,也可以不同。 它们也可能是关于二进制问题的。 但是,必须将它们明确分配给每个数据元素。 分类问题的一个示例是使用卷积神经网络将标签汽车或非汽车分配给图像。 “第 1 课”,“神经网络和深度学习简介”中探讨的 MNIST 示例是分类问题的另一个示例。
- 回归:以连续变量(即标量)为特征的问题。 这些问题的测量范围是,其评估考虑的是网络与实际值的接近程度。 一个示例是时间序列分类问题,其中使用循环神经网络预测未来温度值。 比特币价格预测问题是回归问题的另一个示例。
虽然对于这两个问题类别,评估这些模型的总体结构是相同的,但我们采用了不同的技术来评估模型的表现。 在以下部分中,我们将探讨用于分类或回归问题的这些技术。
注意
本课程中的所有代码段均在“活动 6 和 7”中实现。 随时随地进行,但不要认为它是强制性的,因为在活动期间将对其进行更详细的重复。
损失函数,准确率和错误率
神经网络利用函数来测量与验证集相比网络的运行情况,也就是说,一部分数据被分离为,用作训练过程的一部分。 这些函数称为损失函数。
损失函数评估神经网络预测的误差; 然后他们会将这些误差传播回去并调整网络,从而修改单个神经元的激活方式。 损失函数是神经网络的关键组成部分,选择正确的损失函数可能会对网络的表现产生重大影响。
误差如何传播到网络中的每个神经元?
误差通过称为反向传播的过程传播。 反向传播是一种将损失函数返回的误差传播回神经网络中每个神经元的技术。 传播的误差会影响神经元的激活方式,并最终影响神经网络的输出。
许多神经网络包,包括 Keras,默认情况下都使用此技术。
注意
有关反向传播数学的更多信息,请参阅 Ian Goodfellow 等的《深度学习》。
对于回归和分类问题,我们使用不同的损失函数。 对于分类问题,我们使用精度函数(即,预测正确的时间比例)。 对于回归问题,我们使用的错误率(即,预测值与观察值有多接近)。
下表提供了常见损失函数以及它们的常见应用的摘要:
| 问题类型 | 损失函数 | 问题 | 示例 |
|---|---|---|---|
| 回归 | 均方误差(MSE) | 预测连续特征。 即,预测值范围内的值。 | 使用过去的温度测量结果来预测将来的温度。 |
| 回归 | 均方根误差(RMSE) | 与前面相同,但处理负值。 RMSE 通常提供更可解释的结果。 | 与前面相同。 |
| 回归 | 平均绝对百分比误差(MAPE) | 预测连续特征。 在使用非标准化范围时具有更好的表现。 | 使用产品属性(例如,价格,类型,目标受众,市场条件)预测产品的销售。 |
| 分类 | 二元交叉熵 | 两个类别之间或两个值之间的分类(即true或false)。 |
根据浏览器的活动预测网站的访问者是男性还是女性。 |
| 分类 | 分类交叉熵 | 一组已知类别中许多类别之间的分类。 | 根据讲英语的口音来预测说话者的国籍。 |
表 1:用于分类和回归问题的常见损失函数
对于回归问题,MSE 函数是最常见的选择。 对于分类问题,二元交叉熵(对于二元类别问题)和分类交叉熵(对于多类别问题)是常见的选择。 建议从这些损失函数开始,然后在发展神经网络时尝试其他函数,以期获得表现。
我们在“第 2 课”,“模型架构”中开发的网络使用 MSE 作为其损失函数。 在下一节中,我们将探讨该函数如何在网络训练中发挥作用。
不同的损失函数,相同的架构
在进入下一部分之前,让我们以实践的方式探讨这些问题在神经网络环境中的不同之处。
TensorFlow 团队可使用 TensorFlow Playground 应用,以帮助我们了解神经网络的工作原理。 在这里,我们看到了一个由其层表示的神经网络:输入(在左侧),隐藏层(在中间)和输出(在右侧)。 我们还可以选择最左侧的不同样本数据集进行实验。 最后,在最右边,我们看到了网络的输出。
图 1:TensorFlow Playground Web 应用在此可视化中获取神经网络的参数,以直观了解每个参数如何影响模型结果。
应用帮助我们探索了上一节中讨论的不同问题类别。 当我们选择分类作为问题类型(右上角)时,数据集中的点仅用两种颜色值着色:蓝色或橙色。 选择回归时,点的颜色将在橙色和蓝色之间的一系列颜色值中上色。 在处理分类问题时,网络会根据网络出错了多少个蓝色和橙色来评估其损失函数。 在处理分类问题时,它将检查网络每个点距正确的颜色值的距离,如下图所示:
图 2:TensorFlow Playground 应用的细节。 根据问题类型,将不同的颜色值分配给点。
在单击播放按钮后,我们注意到训练损失区域中的数字随着网络不断训练而不断下降。 在每个问题类别中,数字非常相似,因为损失函数在两个神经网络中都扮演相同的角色。 但是,用于每个类别的实际损失函数是不同的,并且根据问题类型进行选择。
使用 TensorBoard
TensorBoard 擅长评估神经网络。 正如“第 1 课”,“神经网络和深度学习简介”中所述,TensorBoard 是 TensorFlow 附带的一套可视化工具。 在中,可以探索每个周期后损失函数评估的结果。 TensorBoard 的一大功能是可以分别组织每个运行的结果,并比较每个运行的结果损失函数指标。 然后,您可以决定要调整哪些超参数,并对网络的运行情况有一个大致的了解。 最好的部分是,这一切都是实时完成的。
为了在我们的模型中使用 TensorBoard,我们将使用 Keras 回调函数。 我们通过导入TensorBoard回调并将其传递给我们的模型(在调用fit()函数时)来完成此操作。 以下代码显示了如何在上一课中创建的比特币模型中实现该示例:
from keras.callbacks import TensorBoard
model_name = 'bitcoin_lstm_v0_run_0'
tensorboard = TensorBoard(log_dir='./logs/{}'.format(model_name))
model.fit(x=X_train, y=Y_validate,
batch_size=1, epochs=100,
verbose=0, callbacks=[tensorboard])
片段 1:在我们的 LSTM 模型中实现 TensorBoard 回调的片段
在每个时间段运行结束时调用 Keras 回调函数。 在这种情况下,Keras 调用 TensorBoard 回调以将每次运行的结果存储在磁盘上。 还有许多其他有用的回调函数,其中一个可以使用 Keras API 创建自定义函数。
注意
有关更多信息,请参阅 Keras 回调文档。
实现 TensorBoard 回调后,loss函数指标现在可在 TensorBoard 接口中使用。 现在,您可以运行 TensorBoard 进程(使用tensorboard --logdir=./logs),并在使用fit()训练网络时保持运行状态。 要评估的主要图通常称为损失。 通过将已知指标传递给fit()函数中的metrics参数,可以添加更多指标; 这些将可以在 TensorBoard 中用于可视化,但不会用于调整网络权重。 交互式图形将继续实时更新,这使您可以了解每个周期发生的情况。
图 3:TensorBoard 实例的屏幕快照,显示了损失函数结果以及添加到指标参数的其他指标
实现模型评估指标
在回归和分类问题中,我们将输入数据集分为其他三个数据集:训练,验证和测试。 训练和验证集都用于训练网络。 网络将训练集用作输入,损失函数将验证集用作输入,以将神经网络的输出与实际数据进行比较,计算预测的错误程度。 最后,在对网络进行训练之后,可以使用测试集来测量网络如何处理从未见过的数据。
注意
没有确定如何划分训练,验证和测试数据集的明确规则。 通常的方法是将原始数据集分为 80% 的训练和 20% 的测试,然后再将训练数据集分为 80% 的训练和 20% 的验证。 有关此问题的更多信息,请参阅 Sebastian Raschka 和 Vahid Mirjalili 撰写的书《Python 机器学习》。
在分类问题中,您会将数据和标签都作为相关但又不同的数据传递给神经网络。 然后,网络将了解数据与每个标签的关系。 在回归问题中,不是传递数据和标签,而是传递感兴趣的变量作为一个参数,传递用于学习模式的变量作为另一个参数。 Keras 通过fit()方法为这两种用例提供了接口。 有关示例,请参见“代码段 2”:
model.fit(x=X_train, y=Y_train,
batch_size=1, epochs=100,
verbose=0, callbacks=[tensorboard],
validation_split=0.1,
validation_data=(X_validation, Y_validation))
Snippet 2: Snippet that illustrates how to use the validation_split and validation_data parameters
“代码段 2”:说明如何使用
validation_split和validation_data参数的代码段
注意
fit()方法可以使用validation_split或validation_data参数,但不能同时使用两者。
损失函数评估模型的进度并在每次运行时调整其权重。 但是,损失函数仅描述训练数据与验证数据之间的关系。 为了评估模型是否正确执行,我们通常使用第三组数据(该数据不用于训练网络),并将模型做出的预测与该组数据中的可用值进行比较。 那就是测试集的作用。
Keras 提供了model.evaluate(),方法,该方法使针对测试集评估训练有素的神经网络的过程变得容易。 有关示例,请参见以下代码:
model.evaluate(x=X_test, y=Y_test)
“代码段 3”:说明如何使用
evaluate()方法的代码段
evaluate()方法返回损失函数的结果以及传递给metrics参数的函数的结果。 我们将在比特币问题中频繁使用该函数来测试模型在测试集上的表现。
您会注意到,比特币模型看起来与上面的示例有些不同。 那是因为我们使用的是 LSTM 架构。 LSTM 旨在预测序列。 因此,即使是回归问题,我们也不使用一组变量来预测另一个变量。 相反,我们使用单个变量(或一组变量)的先前观察值来预测同一变量(或一组变量)的未来观察结果。 Keras.fit()上的y参数包含与x参数相同的变量,但仅包含预测序列。
评估比特币模型
我们在“第 1 课”,“神经网络和深度学习简介”的活动期间创建了一个测试集。 该测试集具有 19 周的比特币每日价格观察,大约相当于原始数据集的 20%。
我们还在“第 2 课”,“模型结构”并将经过训练的网络存储在磁盘上(bitcoin_lstm_v0). 我们现在可以在测试集中的 19 周数据中的每一个中使用evaluate()方法,并检查第一个神经网络的表现。
为了做到这一点,我们必须在前几周提供 76 个。 我们之所以必须这样做,是因为我们的网络已经过训练,可以准确地使用 76 周的连续数据来预测一周的数据(在第 4 课,“产品化”中)。当我们将神经网络部署为 Web 应用时,我们将通过定期对网络进行较大的定期训练来解决此问题:
combined_set = np.concatenate((train_data, test_data), axis=1)
evaluated_weeks = []
for i in range(0, validation_data.shape[1]):
input_series = combined_set[0:,i:i+77]
X_test = input_series[0:,:-1].reshape(1, input_series.shape[1] - 1, )
Y_test = input_series[0:,-1:][0]
result = B.model.evaluate(x=X_test, y=Y_test, verbose=0)
evaluated_weeks.append(result)
“代码段 4”:实现
evaluate()方法以评估模型在测试数据集中的表现的代码段
在前面的代码中,我们每周使用 Keras 的model.evaluate()进行评估,然后将其输出存储在变量evaluated_weeks中。 然后,在下图中绘制每个星期的结果 MSE:
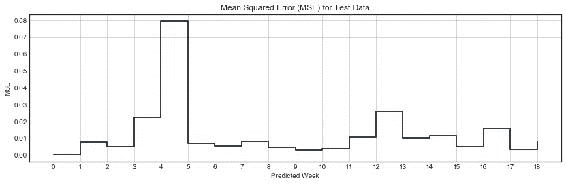
图 4:测试集中每周的 MSE; 请注意,第 5 周的模型预测比其他任何一周都差
根据我们的模型得出的 MSE 表明,我们的模型在除第 5 周外的大多数星期内均表现良好,此时其值增加到大约0.08。 在几乎所有其他测试周中,我们的模型似乎都表现良好。
过拟合
我们的首先训练网络(bitcoin_lstm_v0)可能正遭受一种称为过拟合的现象。 过拟合是指训练模型来优化验证集的方法,但是这样做会以我们有意预测的现象为基础,更笼统的模式为代价。 过拟合的主要问题是模型学习了如何预测验证集,但无法预测新数据。
在训练过程结束时,模型中使用的损失函数达到非常低的水平(约2.9 * 10-6)。 不仅如此,而且这种情况发生得很早:用于预测我们数据最后一周的 MSE 损失函数在大约第 30 个周期下降到一个稳定的平台。这意味着我们的模型几乎可以完美地预测第 77 周的数据, 76 周。 这可能是过拟合的结果吗?
让我们再次看图 4。 我们知道,我们的 LSTM 模型在验证集中达到极低的值(约2.9 * 10-6),但在测试集中也达到极低的值。 但是,关键的区别在于规模。 我们的测试集中每周的 MSE 大约是测试集中平均水平的 4,000 倍。 这意味着该模型在我们的测试数据中比在验证集中的表现要差得多。 这值得考虑。
但是,规模隐藏了我们 LSTM 模型的力量:即使在我们的测试集中表现更差,预测的 MSE 误差仍然非常非常低。 这表明我们的模型可能是从数据中学习模式。
模型预测
一件事是测量我们的模型,比较 MSE 误差,另一件事是能够直观地解释其结果。
使用相同的模型,我们现在使用 76 周作为输入来创建接下来几周的一系列预测。 通过在整个序列(即训练和测试集)上滑动 76 周的窗口,并对每个窗口进行预测,我们可以做到这一点。 预测是使用Keras model.predict()方法完成的:
combined_set = np.concatenate((train_data, test_data), axis=1)
predicted_weeks = []
for i in range(0, validation_data.shape[1] + 1):
input_series = combined_set[0:,i:i+76]
predicted_weeks.append(B.predict(input_series))
片段 5:使用
model.predict()方法对测试数据集的所有星期进行预测的片段
在前面的代码中,我们使用model.predict(),进行预测,然后将这些预测存储在predicted_weeks变量中。 然后,我们绘制结果预测,如下图所示:
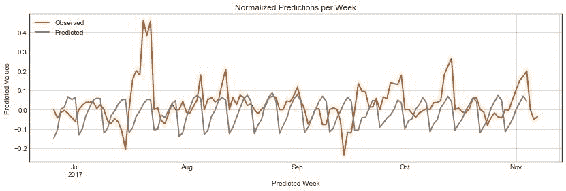
图 5:测试集中每周的 MSE。 请注意,第 5 周的模型预测比其他任何一周都差。
我们模型的结果(如图“图 5”所示)表明它的表现还不错。 通过观察预测行的模式,您可以注意到该网络已识别出每周发生的波动模式,其中正常价格在一周中上调,然后在下周下跌。 结束。 除了为数不多的几周(最值得注意的是第 5 周,与我们之前的 MSE 分析相同)之外,大多数周都接近正确的值。
现在让我们对预测进行反规范化,以便我们可以使用与原始数据相同的标度(即美元)调查预测值。 为此,我们可以实现一个反规范化函数,该函数使用来自预测数据的日索引来确定测试数据上的等效星期。 在确定了该周之后,该函数将采用该周的第一个值,并使用相同的点相对归一化技术,使用该值对预测值进行归一化,但取反:
def denormalize(reference, series,
normalized_variable='close_point_relative_normalization',
denormalized_variable='close'):
week_values = observed[reference['iso_week'] == series['iso_week']. values[0]]
last_value = week_values[denormalized_variable].values[0]
series[denormalized_variable] = last_value * (series[normalized_variable] + 1)
return series
predicted_close = predicted.groupby('iso_week').apply(
lambda x: denormalize(observed, x))
“代码段 6”:使用反向点相对归一化技术对数据进行归一化。
denormalize()函数从测试的等效一周的第一天起收取第一个收盘价。
现在,我们的结果使用美元将预测值与测试集进行比较。 从“图 5”中可以看出,bitcoin_lstm_v0 模型在预测接下来的 7 天比特币价格时似乎表现良好。 但是,我们如何用可解释的项衡量表现呢?
图 6:测试集中每周的 MSE; 请注意,第 5 周的模型预测比其他任何一周都差
解释预测
我们的最后一步是为我们的预测增加可解释性。 图 6 似乎表明我们的模型预测在某种程度上与测试数据匹配,但是与测试数据的匹配程度如何?
Keras 的model.evaluate()函数对于理解模型在每个评估步骤中的执行情况很有用。 但是,鉴于我们通常使用规范化的数据集来训练神经网络,因此model.evaluate()方法生成的指标也难以解释。
为了解决该问题,我们可以从模型中收集完整的预测集,并使用“表 1”中的两个易于解释的函数将其与测试集进行比较:MAPE 和 RMSE ,分别实现为mape()和rmse():
def mape(A, B):
return np.mean(np.abs((A - B) / A)) * 100
def rmse(A, B):
return np.sqrt(np.square(np.subtract(A, B)).mean())
“代码段 7”:
mape()和rmse()函数的实现
注意
这些函数是使用 NumPy 实现的。 原始实现来自这里(MAPE)和这里(RMSE)。
在使用这两个函数将测试集与预测进行比较之后,我们得到以下结果:
- 非规范化的 RMSE: 399.6 美元
- 非规范化的 MAPE:8.4%
这表明我们的预测与实际数据的平均差异约为 399 美元。 这意味着与实际比特币价格相差约 8.4%。
这些结果有助于理解我们的预测。 我们将继续使用model.evaluate()方法来跟踪我们的 LSTM 模型的改进情况,但还将在模型的每个版本的完整序列中计算rmse()和mape()来解释我们预测的比特币价格的接近程度。
活动 6 – 创建活动的训练环境
在此活动中,我们为神经网络创建了一个训练环境,以促进其训练和评估。 这个环境对于我们的下一课特别重要,在下一课中,我们寻找超参数的最佳组合。
首先,我们将启动 Jupyter 笔记本实例和 TensorBoard 实例。 在此活动的其余部分中,这两个实例都可以保持打开状态。
-
在您的终端上,导航至目录
lesson_3/activity_6并执行以下代码以启动 Jupyter 笔记本实例:$ jupyter notebook -
在浏览器中打开应用提供的 URL,然后打开名为
Activity_6_Creating_an_active_training_environment.ipynb的 Jupyter 笔记本:
图 7:Jupyter 笔记本突出显示“评估 LSTM 模型”部分
-
同样在您的终端机上,通过执行以下命令来启动 TensorBoard 实例:
$ cd ./lesson_3/activity_6/ $ tensorboard --logdir=logs/ -
打开出现在屏幕上的 URL,并使该浏览器选项卡也保持打开状态。
-
现在,将训练(
train_dataset.csv)和测试集(test_dataset.csv)以及我们先前编译的模型(bitcoin_lstm_v0.h5)都加载到笔记本中。 -
使用以下命令在 Jupyter 笔记本实例中加载训练和测试数据集:
$ train = pd.read_csv('data/train_dataset.csv') $ test = pd.read_csv('data/test_dataset.csv') -
另外,使用以下命令加载先前编译的模型:
$ model = load_model('bitcoin_lstm_v0.h5')现在让我们评估我们的模型如何针对测试数据执行。 我们使用 76 周的时间对模型进行了训练,以预测未来的一周-即接下来的 7 天。 建立第一个模型时,我们将原始数据集分为训练集和测试集。 现在,我们将两个数据集的合并版本(我们称为合并集)并移动 76 周的滑动窗口。 在每个窗口中,我们执行 Keras 的
model.evaluate()方法来评估网络在特定星期的表现。 -
执行标题评估 LSTM 模型下的单元格。 这些单元格的关键概念是在测试集中每个星期调用
model.evaluate()方法。 这条线是最重要的:$ result = model.evaluate(x=X_test, y=Y_test, verbose=0) -
现在,每个评估结果都存储在变量
evaluated_weeks中。 该变量是一个简单的数组,其中包含测试集中每个星期的 MSE 预测序列。 继续并绘制以下结果:图 8:模型
set.evaluate()方法对测试集每周的 MSE 结果正如我们在本课程中讨论的那样,MSE 损失函数很难解释。 为了促进我们对模型表现的理解,我们还每周在测试集中调用方法
model.predict(),并将其预测结果与该集的值进行比较。 -
导航至
Interpreting Model Results部分,并在子标题Make Predictions下执行代码单元。 注意,我们正在调用方法model.predict(),但是参数的组合稍有不同。 我们不使用X和Y值,而是只使用X:
```py
predicted_weeks = []
for i in range(0, test_data.shape[1]):
input_series = combined_set[0:,i:i+76]
predicted_weeks.append(model.predict(input_series))
```
在每个窗口中,我们将发布下一周的预测并存储结果。 现在,我们可以将标准化结果与测试集中的标准化值一起绘制,如下图所示:
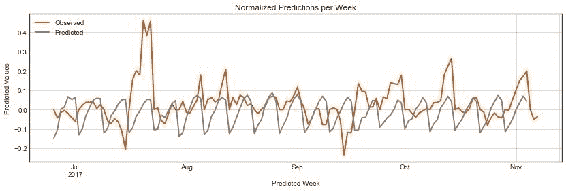
图 9:绘制测试集每个星期从`model.predict()`返回的归一化值
我们还将进行相同的比较,但使用非标准化值。 为了使我们的数据不规范,我们必须首先确定测试集和预测之间的等效周。 然后,我们获取该周的第一个价格值,并使用它来逆转“第 2 课,模型架构”中的点相对标准化方程。
- 导航到标题“非规范化预测”,然后执行该标题下的所有单元格。
- 在本节中,我们定义了函数
denormalize(),该函数执行完整的反规范化过程。 与其他函数不同,此函数采用 Pandas 数据帧而不是 NumPy 数组。 我们这样做是为了将日期用作索引。 这是与该标题最相关的单元格块:
```py
predicted_close = predicted.groupby('iso_week').apply(
lambda x: denormalize(observed, x))
```
我们的归一化结果(如下图所示)表明,我们的模型做出的预测接近真实的比特币价格。 但是有多近?
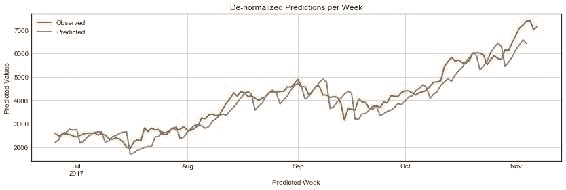
图 10:绘制测试集每个星期从`model.predict()`返回的归一化值
LSTM 网络使用 MSE 值作为其损失函数。 但是,正如课程中所讨论的,MSE 值难以解释。 为了解决这个问题,我们实现了两个函数(从脚本`utilities.py`加载),它们实现了函数 RMSE 和 MAPE。 这些函数通过返回与原始数据相同的比例尺的度量值,并比较比例尺的百分比差异,从而为我们的模型增加了可解释性。
- 导航至标题
De-normalizing Predictions并从utilities.py脚本中加载两个函数:
```py
from scripts.utilities import rmse, mape
```
该脚本中的函数实际上非常简单:
```py
def mape(A, B):
return np.mean(np.abs((A - B) / A)) * 100
def rmse(A, B):
return np.sqrt(np.square(np.subtract(A, B)).mean())
```
每个函数都是使用 NumPy 的向量方式操作实现的。 它们在相同长度的向量中效果很好。 它们旨在应用于完整的结果集。
使用`mape()`函数,我们现在可以了解到,我们的模型预测与测试集的价格相比,大约相差 8.4%。 这等效于约 399.6 美元的均方根误差(使用`rmse()`函数计算)。
在继续下一部分之前,请回到笔记本电脑中,找到标题为 TensorBoard 的重新训练模型。 您可能已经注意到我们创建了一个名为`train_model()`的辅助函数。 该函数是模型的包装器,用于训练(使用`model.fit()`)模型,并将其各自的结果存储在新目录中。 然后,这些结果由 TensorBoard 用作判别器,以显示不同模型的统计信息。
- 继续并修改传递给
model.fit()函数的参数的某些值(例如,尝试周期)。 现在,运行将模型从磁盘加载到内存的单元(这将替换您训练的模型):
```py
model = load_model('bitcoin_lstm_v0.h5')
```
- 现在,再次运行
train_model()函数,但使用不同的参数,指示新的运行版本:
```py
train_model(X=X_train, Y=Y_validate, version=0, run_number=0)
```
### 注意
对于参考解决方案,请使用`Code/Lesson-3/activity_6`文件夹。
在本节中,我们学习了如何使用损失函数评估网络。 我们了解到,损失函数是神经网络的关键元素,因为它们在每个周期评估网络的表现,并且是将调整传播回层和节点的起点。 我们还探讨了为什么某些损失函数可能难以解释(例如 MSE)的原因,并开发了使用其他两个函数(RMSE 和 MAPE)的策略来解释 LSTM 模型的预测结果。
最重要的是,本课以一个活跃的训练环境结束。 我们现在拥有一个可以训练深度学习模型并不断评估其结果的系统。 当我们在下一个会话中转向优化我们的网络时,这将是关键。
超参数优化
我们已经训练了一个神经网络,以使用之前的 76 周价格来预测比特币价格的未来 7 天。 平均而言,该模型发出的预测与实际比特币价格相距约 8.4%。
本节描述了改善神经网络模型表现的常用策略:
- 添加或删除层并更改节点数
- 增加或减少训练次数
- 尝试不同的激活函数
- 使用不同的正则化策略
我们将使用在“模型评估”部分末尾开发的相同的主动学习环境来评估每种修改,并测量这些策略中的每一种如何帮助我们开发更精确的模型。
层和节点 - 添加更多层
具有单个隐藏层的神经网络在许多问题上的表现都相当不错。 我们的第一个比特币模型(bitcoin_lstm_v0)是一个很好的例子:它可以使用单个 LSTM 层预测(根据测试集)未来七天的比特币价格(错误率约为 8.4% )。 但是,并非所有问题都可以用单层建模。
您正在预测的函数越复杂,则需要添加更多层的可能性就越高。 确定是否添加新层是一个好主意,这是了解它们在神经网络中的作用。
每一层都创建其输入数据的模型表示。 链中较早的层创建较低级别的表示,较晚的层创建较高的级别。
尽管该描述可能难以转化为现实问题,但其实际直觉很简单:当使用具有不同表示级别的复杂函数时,您可能需要尝试添加层。
添加更多节点
层所需的神经元数量与输入和输出数据的结构方式有关。 例如,如果您要将4 x 4像素图像分为两类之一,则可以从一个具有 12 个神经元的隐藏层(每个可用像素一个)和一个只有两个神经元的输出层开始(每个预测类一个)。
通常在添加新层的同时添加新神经元。 然后,可以添加一层具有与前一层相同数量的神经元,或者是前一层的神经元数量的倍数的层。 例如,如果您的第一个隐藏层具有 12 个神经元,则可以尝试添加第二个具有 12、6 或 24 个层的神经元。
添加层和神经元可能具有明显的表现限制。 随意尝试添加层和节点。 通常从一个较小的网络(即具有少量层和神经元的网络)开始,然后根据其表现提升而增长。
如果以上说法不准确,您的直觉是正确的。 引用 YouTube 视频分类的前负责人 AurélienGéron 的话,找到完美数量的神经元仍然有些荒唐可笑。
注意
《Scikit-Learn 和 TensorFlow 机器学习使用指南》,由 AureliénGéron 撰写,由 O’Reilly 于 2017 年 3 月发布。
最后,请注意:您添加的层越多,您需要调整的超参数就越多,网络训练所需的时间也就越长。 如果您的模型运行良好且没有过拟合数据,请在将新层添加到网络之前尝试本课中概述的其他策略。
层和节点 - 实现
现在,我们将通过添加更多层来修改我们的原始 LSTM 模型。 在 LSTM 模型中,通常会按顺序添加 LSTM 层,从而在 LSTM 层之间形成一条链。 在我们的案例中,新的 LSTM 层具有与原始层相同的神经元数量,因此我们不必配置该参数。
我们将命名模型的修改版本bitcoin_lstm_v1。 优良作法是为每个要尝试不同的超参数配置的模型命名。 这有助于您跟踪每个不同架构的表现,还可以轻松比较 TensorBoard 中的模型差异。 在本课程结束时,我们将比较所有不同的修改架构。
注意
在添加新的 LSTM 层之前,我们需要在第一个 LSTM 层上将参数return_sequences修改为True。 我们这样做是因为第一层期望一个与第一层具有相同输入的数据序列。 当此参数设置为False,时,LSTM 层将以不同的不兼容输出输出预测参数。
考虑以下代码示例:
period_length = 7
number_of_periods = 76
batch_size = 1
model = Sequential()
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=True, stateful=False))
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=False, stateful=False))
model.add(Dense(units=period_length))
model.add(Activation("linear"))
model.compile(loss="mse", optimizer="rmsprop")
片段 8:在原始
bitcoin_lstm_v0 model上添加第二个 LSTM 层,使其成为bitcoin_lstm_v1
周期
周期是网络响应于数据通过及其损失函数而调整其权重的次数。 为更多周期运行模型可以使它从数据中学到更多,但同时也存在过拟合的风险。
训练模型时,最好以指数形式增加历时,直到损失函数开始趋于平稳。 在bitcoin_lstm_v0模型的情况下,其损失函数稳定在大约 100 个周期。
我们的 LSTM 模型使用少量数据进行训练,因此增加周期数不会显着影响其表现。 例如,如果尝试在 103 个周期训练它,该模型几乎没有任何改进。 如果要训练的模型使用大量数据,则情况并非如此。 在这些情况下,大量的时间对于实现良好的表现至关重要。
我建议您使用以下关联:训练模型的日期越长,获得良好表现所需的时间越长。
周期 - 实现
我们的比特币数据集非常小,因此增加了模型训练可能会对的表现产生边际影响的周期。 为了使模型具有更多的周期,只需更改model.fit()中的epochs参数即可:
number_of_epochs = 10**3
model.fit(x=X, y=Y, batch_size=1,
epochs=number_of_epochs,
verbose=0,
callbacks=[tensorboard])
片段 9:更改模型训练的周期数,使其变为
bitcoin_lstm_v2
这一变化将我们的模型更改为v2,有效地使其变为bitcoin_lstm_v2。
激活函数
激活函数评估您需要多少时间才能激活单个神经元。 他们使用上一层的输入和损失函数的结果(或者神经元是否应该传递任何值)来确定每个神经元将传递到网络下一个元素的值。
注意
激活函数是研究神经网络的科学界非常感兴趣的主题。 有关当前正在对该主题进行的研究概述以及有关激活函数如何工作的更详细的评论,请参阅 Ian Goodfellow 等的《深度学习》。 麻省理工学院出版社,2017 年。
TensorFlow 和 Keras 提供了许多激活函数-偶尔会添加新的激活函数。 引言中,三个重要的考虑因素; 让我们探索它们中的每一个。
注意
本部分的灵感来自 Avinash Sharma 撰写的文章《了解神经网络中的激活函数》,该文章可从获得启发。
线性(恒等)
仅线性函数会基于恒定值激活神经元。 它们的定义是:
![]()
当c = 1时,神经元将按原样传递值,而无需激活函数进行修改。 使用线性函数的问题是,由于神经元是线性激活的,因此链接的层现在可以用作单个大层。 换句话说,一个人失去了构建多层网络的能力,其中一个人的输出会影响另一个人:
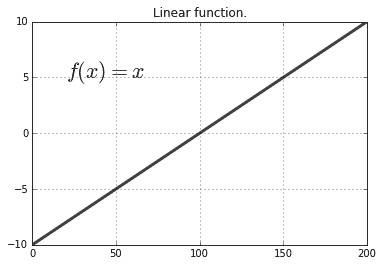
图 11:线性函数的图示
对于大多数网络,线性函数的使用通常认为是。
双曲正切(Tanh)
Tanh 是非线性函数,由以下公式表示:
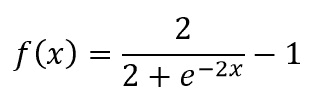
表示将连续评估它们对节点的影响。 同样,由于其非线性,可以使用此函数来更改一层如何影响链中的下一层。 使用非线性函数时,层会以不同的方式激活神经元,从而使从数据中学习不同的表示更为容易。 但是,它们具有类似于 Sigmoid 的图案,可反复惩罚极端节点值,从而导致称为的问题,即消失梯度。 消失的梯度对网络的学习能力产生负面影响:
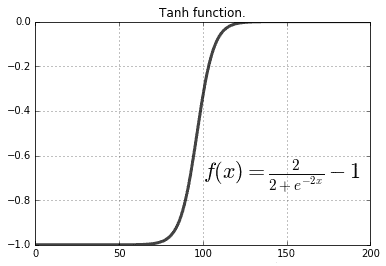
图 12:tanh 函数的图示
Tanh 是的流行选择,但是由于它们的计算量很大,因此经常使用 ReLU。
整流线性单元
ReLU 具有非线性属性。 它们的定义是:
![]()
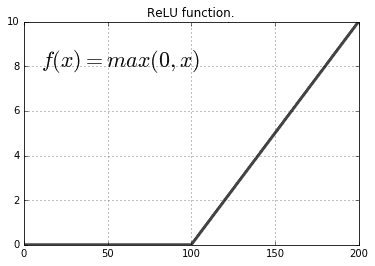
图 13:ReLU 函数示意图
在尝试其他函数之前,通常建议将 ReLU 函数作为起点。 ReLU 倾向于惩罚负值。 因此,如果输入数据(例如,在-1和1之间进行归一化)包含负值,则这些数据现在将受到 ReLU 的惩罚。 可能不是预期的行为。
我们不会在网络中使用 ReLU 函数,因为我们的规范化过程会创建许多负值,从而导致学习模型慢得多。
激活函数 - 实现
在 Keras 中实现激活函数的最简单方法是实例化Activation()类,并将其添加到Sequential()模型中。 可以使用 Keras 中可用的任何激活函数实例化Activation()(有关完整列表,请参见这里)。 在我们的例子中,我们将使用tanh函数。 实现激活函数后,我们将模型的版本更改为v2,使其变为bitcoin_lstm_v3:
model = Sequential()
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=True, stateful=False))
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=False, stateful=False))
model.add(Dense(units=period_length))
model.add(Activation("tanh"))
model.compile(loss="mse", optimizer="rmsprop")
“代码段 10”:在
bitcoin_lstm_v2 model中添加激活函数 tanh,使其成为bitcoin_lstm_v3
还有许多其他激活函数值得尝试。 TensorFlow 和 Keras 都在各自的官方文档中提供了已实现函数的列表。 在实现自己的方法之前,请先从 TensorFlow 和 Keras 中已实现的方法开始。
正则化策略
神经网络特别容易过拟合。 当网络学习训练数据的模式但无法找到也可以应用于测试数据的可推广模式时,就会发生过拟合。
正则化策略是指通过调整网络学习方式来解决过拟合问题的技术。 在本书中,我们讨论两种常见的策略:L2 和丢弃。
L2 正则化
L2 正则化(或权重衰减)是用于处理过拟合模型的常见技术。 在某些模型中,某些参数的变化幅度很大。 L2 正则化惩罚了这些参数,从而降低了这些参数对网络的影响。
L2 正则化使用λ参数来确定对模型神经元的惩罚程度。 通常将其设置为一个非常低的值(即0.0001); 否则,就有可能完全消除给定神经元的输入。
丢弃
丢弃是一种基于简单问题的正则化技术:如果一个节点随机地从层中删除一部分节点,那么另一个节点将如何适应? 事实证明,其余的神经元会适应,学会代表先前由缺失的那些神经元处理过的模式。
退出策略易于实现,通常非常有效地避免过拟合。 这将是我们首选的正则化。
正则化策略 - 实现
为了使用 Keras 实现的退出策略,我们导入Dropout()类并将其添加到每个 LSTM 层之后的网络中。 有效的添加使我们的网络bitcoin_lstm_v4:
model = Sequential()
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=True, stateful=False))
model.add(Dropout(0.2))
model.add(LSTM(
units=period_length,
batch_input_shape=(batch_size, number_of_periods, period_length),
input_shape=(number_of_periods, period_length),
return_sequences=False, stateful=False))
model.add(Dropout(0.2))
model.add(Dense(units=period_length))
model.add(Activation("tanh"))
model.compile(loss="mse", optimizer="rmsprop")
“代码段 11”:在此代码段中,我们将
Dropout()步骤添加到模型(bitcoin_lstm_v3)中,使其设为bitcoin_lstm_v4
可以使用 L2 正则化代替丢弃。 为此,只需实例化ActivityRegularization()类,并将L2参数设置为较低的值(例如0.0001,)。 然后,将其放置在Dropout()类添加到网络的位置。 随时进行测试,只需将其添加到网络中,同时保持Dropout()的两个步骤,或者直接将所有Dropout()实例替换为ActivityRegularization()。
优化结果
总而言之,我们已经创建了四个版本的模型。 这些版本中的三个是通过应用本课中概述的不同优化技术创建的。
在创建所有这些版本之后,我们现在必须评估哪种模型表现最佳。 为此,我们使用第一个模型中使用的相同指标:MSE,RMSE 和 MAPE。 MSE 用于比较每个预测周的模型错误率。 计算 RMSE 和 MAPE 使模型结果更易于解释。
| 模型 | MSE(最后一个周期) | RMSE(整个序列) | MAPE(整个序列) | 训练时间 |
|---|---|---|---|---|
bitcoin_lstm_v0 |
- | 399.6 | 8.4% | - |
bitcoin_lstm_v1 |
7.15*10-6 | 419.3 | 8.8% | 49.3 秒 |
bitcoin_lstm_v2 |
3.55*10-6 | 425.4 | 9.0% | 1 分 13 秒 |
bitcoin_lstm_v3 |
2.8*10-4 | 423.9 | 8.8% | 1 分 19 秒 |
bitcoin_lstm_v4 |
4.8*10-7 | 442.4 | 9.4% | 1 分 20 秒 |
表 2:所有模型的模型结果
有趣的是,我们的第一个模型(bitcoin_lstm_v0)在几乎所有定义的指标中表现最佳。 我们将使用该模型构建我们的 Web 应用并不断预测比特币价格。
活动 7 – 优化深度学习模型
在此活动中,我们对在“第 2 课”,“模型架构”(bitcoin_lstm_v0)中创建的模型实现不同的优化策略。 该模型在完整的反规范化测试集上获得了大约 8.4% 的 MAPE 表现。 我们将努力缩小这一差距。
-
在您的终端上,通过执行以下命令来启动 TensorBoard 实例:
$ cd ./lesson_3/activity_7/ $ tensorboard --logdir=logs/ -
打开出现在屏幕上的 URL,并使该浏览器选项卡也保持打开状态。 另外,使用以下命令启动 Jupyter 笔记本实例:
$ jupyter notebook打开出现在其他浏览器窗口中的 URL。
-
现在,打开名为
Activity_7_Optimizing_a_deep_learning_model.ipynb的 Jupyter 笔记本,并导航至笔记本的标题并导入所有必需的库。我们将像以前的活动一样加载训练和测试数据。 我们还将使用工具函数
split_lstm_input()将分为训练组和测试组。在本笔记本的每个部分中,我们将在模型中实现新的优化技术。 每次这样做,我们都会训练一个新模型并将其训练后的实例存储在描述模型版本的变量中。 例如,在本笔记本中,我们的第一个模型
bitcoin_lstm_v0,被称为model_v0。 在笔记本的最后,我们使用 MSE,RMSE 和 MAPE 评估所有模型。 -
现在,在打开的 Jupyter 笔记本中,导航至标题
Adding Layers and Nodes。 您将在下一个单元格中识别出我们的第一个模型。 这是我们在第 2 课,“模型架构”中构建的基本 LSTM 网络。 现在,我们必须向该网络添加一个新的 LSTM 层。利用本课中的知识,继续并添加新的 LSTM 层,编译和训练模型。
在训练模型时,请记住经常访问正在运行的 TensorBoard 实例。 您将能够查看每个模型的运行情况,并在此处比较其损失函数的结果:
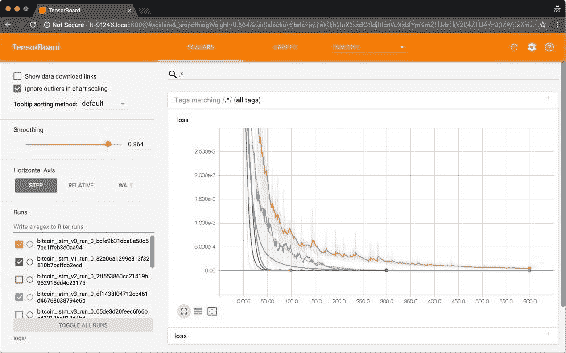
图 14:运行 TensorBoard 实例,该实例显示了许多不同的模型运行。 TensorBoard 对于实时跟踪模型训练非常有用。
-
现在,导航至标题
Epochs。 在本节中,我们有兴趣探索不同周期的大小。 使用工具函数train_model()来命名不同的模型版本并运行:train_model(model=model_v0, X=X_train, Y=Y_validate, epochs=100, version=0, run_number=0)使用一些不同的周期参数训练模型。
此时,您有兴趣确保模型不会过拟合训练数据。 您想避免这种情况,因为如果这样做,它将无法预测训练数据中表示的模式,但测试数据中具有不同的表示形式。
在尝试了新周期之后,请转到下一个优化技术:激活函数。
-
现在,导航至笔记本中的标题
Activation Functions。 在本节中,您只需要更改以下变量:activation_function = "tanh"我们在本节中使用了
tanh函数,但是请随时尝试其他激活函数。 查看这个页面上可用的列表,然后尝试其他可能性。我们的最终选择是尝试不同的正则化策略。 这显然更加复杂,并且可能需要花费一些迭代才能注意到任何收益,尤其是数据量很少时。 此外,添加正则化策略通常会增加网络的训练时间。
-
现在,导航至笔记本中的标题正则化策略。 在本部分中,您需要实现
Dropout()正则化策略。 找到合适的位置放置该步骤并将其实现到我们的模型中。 -
您也可以在这里尝试进行 L2 正则化(或将两者结合使用)。 与
Dropout()相同,但现在使用ActivityRegularization(l2=0.0001)。最后,让我们使用 RMSE 和 MAPE 评估我们的模型:
-
现在,导航至笔记本中的标题
Evaluate Models。 在本节中,我们将评估测试集中未来 19 周数据的模型预测。 然后,我们将计算预测序列与测试序列的 RMSE 和 MAPE。我们已经实现了与活动 6 相同的评估技术,所有这些技术都包含在工具函数中。 只需运行本节中的所有单元格,直到笔记本末尾即可查看结果。
注意
对于参考解决方案,请使用
Code/Lesson-3/activity_7文件夹。借此机会来调整前面的优化技术的值,并尝试击败该模型的表现。
总结
在本课程中,我们学习了如何使用度量均方误差(MSE),均方误差(RMSE)和均值平均百分比误差(MAPE)来评估模型。 我们通过第一个神经网络模型进行的为期 19 周的一系列预测中计算了后两个指标。 然后我们得知它运行良好。
我们还学习了如何优化模型。 我们研究了通常用于提高神经网络表现的优化技术。 此外,我们实现了许多这些技术,并创建了更多模型来预测具有不同错误率的比特币价格。
在下一课中,我们将把我们的模型变成一个执行以下两件事的 Web 应用:使用新数据定期重新训练我们的模型,并能够使用 HTTP API 接口进行预测。
四、产品化
本课程重点介绍如何产品化深度学习模型。 我们使用“产品化”一词来定义可被其他人和应用使用的深度学习模型创建的软件产品。
我们对在使用新数据时可用的模型,不断从新数据中学习模式并因此做出更好的预测的模型感兴趣。 我们研究了两种处理新数据的策略:一种重新训练现有模型,另一种创建全新模型。 然后,我们在比特币价格预测模型中实现后一种策略,以便它可以连续预测新的比特币价格。
本课程还提供了如何将模型部署为 Web 应用的练习。 在本课程结束时,我们将能够部署一个有效的 Web 应用(具有正常运行的 HTTP API)并将其修改为我们的核心内容。
由于其简单性和普遍性(毕竟,Web 应用非常普遍),我们以 Web 应用为例来说明如何部署深度学习模型,但是还有许多其他可能性。
课程目标
在本课程中,您将:
- 处理新数据
- 将模型部署为 Web 应用
处理新数据
可以在一组数据中训练模型,然后将其用于进行预测。 这样的静态模型可能非常有用,但是通常情况下,我们希望我们的模型不断从新数据中学习,并不断地不断改进。
在本节中,我们将讨论关于如何重新训练深度学习模型以及如何在 Python 中实现它们的两种策略。
分离数据和模型
构建深度学习应用时,两个最重要的领域是数据和模型。 从架构的角度来看,我们建议将这两个区域分开。 我们认为这是一个好建议,因为这些区域中的每个区域都包含固有地彼此分离的功能。 通常需要收集,清理,组织和规范化数据; 模型需要进行训练,评估并能够做出预测。 这两个领域都是相互依存的,但最好分开处理。
按照该建议,我们将使用两个类来帮助我们构建 Web 应用:CoinMarketCap()和Model():
CoinMarketCap():此是用于从以下网站获取比特币价格的类。 这就是我们原始比特币数据来自的地方。 通过此类,可以轻松地定期检索该数据,并返回带有已解析记录和所有可用历史数据的 Pandas 数据帧。CoinMarketCap()是我们的数据组件。Model():此类将到目前为止已编写的所有代码实现为一个类。 该类提供了与我们先前训练的模型进行交互的工具,并且还允许使用非规范化数据进行预测,这更容易理解。Model()类是我们的模型组件。
这两个类在我们的示例应用中得到了广泛使用,并定义了数据和模型组件。
数据组件
CoinMarketCap()类创建用于检索和解析数据的方法。 它包含一种相关方法historic(),以下代码中对其进行了详细说明:
@classmethod
def historic(cls, start='2013-04-28', stop=None,
ticker='bitcoin', return_json=False):
start = start.replace('-', '')
if not stop:
stop = datetime.now().strftime('%Y%m%d')
base_url = 'https://coinmarketcap.com/currencies'
url = '/{}/historical-10\. data/?start={}&end={}'.format(ticker, start, stop)
r = requests.get(url)
“代码段 1”:
CoinMarketCap()类中的historic()方法。 此方法从 CoinMarketCap 网站收集数据,对其进行解析,然后返回 Pandas 数据帧。
historic()类返回一个 Pandas DataFrame,准备由Model()类使用。
当在其他模型中工作时,请考虑创建实现与CoinMarketCap()类相同功能的程序组件(例如 Python 类)。 也就是说,创建一个组件,该组件将从可用数据中获取数据,解析该数据,并以可用格式将其提供给您的建模组件。
CoinMarketCap()类使用参数ticker确定要收集的加密货币。 CoinMarketCap还有许多其他可用的加密货币,包括非常受欢迎的以太坊(ethereum)和比特币现金(bitcoin-cash)。 与使用本书中创建的比特币模型相比,使用ticker参数来更改加密货币并训练不同的模型。
模型组件
在Model() 类中,我们实现了应用的模型组件。 此类包含五种方法,可实现本书中所有不同的建模主题。 这些是:
build():使用 Keras 构建 LSTM 模型。 此函数用作手动创建的模型的简单包装。train():使用实例化类的数据训练模型。evaluate():使用一组损失函数对进行模型评估。save():将模型另存为本地文件。predict():进行并根据以周为单位的观测值的输入序列返回预测。
在本课程中,我们将使用这些方法来对我们的模型进行工作,训练,评估和发布预测。 Model()类是如何将基本 Keras 函数包装到 Web 应用中的示例。 前面的方法几乎与前面的课程完全一样,但是添加了语法糖以增强它们的接口。 例如,方法train()通过以下代码实现:
def train(self, data=None, epochs=300, verbose=0, batch_size=1):
self.train_history = self.model.fit(
x=self.X, y=self.Y,
batch_size=batch_size, epochs=epochs,
verbose=verbose, shuffle=False)
self.last_trained = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return self.train_history
“代码段 2”:
Model()类中的train()方法。 该方法使用来自self.X和self.Y的数据训练self.model中可用的模型。
在前面的代码片段中,您将注意到train()方法类似于“第 3 课”,“模型评估与优化”中“活动 6”和7的解决方案。 总体思路是,可以很容易地将 Keras 工作流程中的每个过程(构建或设计,训练,评估和预测)转变为程序的不同部分。 在我们的例子中,我们将它们变成可以从Model()类调用的方法。 这将组织我们的程序,并提供一系列约束(例如在模型架构或某些 API 参数上),以帮助我们在稳定的环境中部署模型。
在下一部分中,我们将探讨处理新数据的通用策略。
处理新数据
机器学习模型(包括神经网络)的核心思想是它们可以从数据中学习模式。 想象一下,某个模型是使用某个数据集训练的,而现在它正在发布预测。 现在,假设有新数据可用。 我们可以采用什么策略,以便模型可以利用新获得的数据来学习新模式并改善其预测?
在此部分中,我们讨论两种策略:重新训练旧模型和训练新模型。
重新训练旧模型
通过这种策略,我们用新数据重新训练了现有模型。 使用此策略,可以不断调整模型参数以适应新现象。 但是,后期训练期间使用的数据可能与其他较早的数据明显不同。 这种差异可能会导致模型参数发生重大变化,从而使其学习新模式而忘记旧模式。 这种现象通常称为灾难性遗忘。
注意
灾难性的遗忘是影响神经网络的常见现象。 深度学习研究人员多年来一直在努力解决这个问题。 DeepMind 是英国拥有的 Google 深度学习研究小组,在寻找解决方案方面取得了显着进步。 《克服神经网络中的灾难性遗忘》是此类工作的很好参考。
首次用于训练的接口(model.fit())可以用于训练新数据:
X_train_new, Y_train_new = load_new_data()
model.fit(x=X_train_new, y=Y_train_new,
batch_size=1, epochs=100,
verbose=0)
“代码段 3”:在我们的 LSTM 模型中实现 TensorBoard 回调的代码段
在 Keras 中,训练模型时,将保留其权重信息-这是模型的状态。 当使用model.save()方法时,该状态也被保存。 当调用方法model.fit()时,将使用先前的状态作为起点,使用新的数据集重新训练模型。
在典型的 Keras 模型中,可以毫无问题地使用此技术。 但是,在使用 LSTM 模型时,此技术有一个关键限制:训练数据和验证数据的形状必须相同。 例如,我们的 LSTM 模型(bitcoin_lstm_v0)使用 76 周来预测未来的一周。 如果我们尝试在接下来的一周内用 77 周的时间对网络进行训练,则该模型会引发一个异常,其中包含有关数据形状错误的信息。
解决此问题的一种方法是按模型期望的格式排列数据。 在我们的案例中,我们需要配置模型以使用 40 周来预测未来一周。 使用此解决方案,我们首先在 2017 年的前 40 周训练模型,然后在接下来的几周内继续对其进行训练,直到达到 50 周为止。我们使用Model()类在以下代码中执行此操作:
M = Model(data=model_data[0*7:7*40 + 7],
variable='close',
predicted_period_size=7)
M.build()
6 M.train()
for i in range(1, 10 + 1):
M.train(model_data[i*7:7*(40 + i) + 7])
片段 4:实现再训练技术的片段
这项技术易于训练,并且在大序列中也可以很好地工作。 下一技术更易于实现,并且在较小的序列中效果很好。
训练新模型
另一种策略是每当有新数据可用时创建并训练新模型。 这种方法倾向于减少灾难性的遗忘,但是训练时间会随着数据的增加而增加。 它的实现非常简单。
以比特币模型为例,现在假设我们有 2017 年 49 周的旧数据,而一周后就有新数据可用。 我们用以下引号中的变量old_data和new_data表示这一点:
old_data = model_data[0*7:7*48 + 7]
new_data = model_data[0*7:7*49 + 7]
M = Model(data=old_data,
variable='close',
predicted_period_size=7)
M.build()
M.train()
M = Model(data=new_data,
variable='close',
predicted_period_size=7)
M.build()
M.train()
片段 5:该片段实现了在有新数据时训练新模型的策略
这种方法实现起来非常简单,并且对于小型数据集而言效果很好。 这将是我们比特币价格预测应用的首选解决方案。
活动 8 – 处理新数据
在此活动中,每当有新数据可用时,我们都会重新训练模型。
首先,我们从导入cryptonic开始。 Cryptonic 是为本书开发的简单软件应用,它使用 Python 类和模块实现了本节之前的所有步骤。 将 Cryptonic 视为开发相似应用的模板。
cryptonic作为 Python 模块随此活动一起提供。 首先,我们将启动 Jupyter 笔记本实例,然后将加载cryptonic包。
-
在您的终端上使用,导航到目录
lesson_4/activity_8,然后执行以下代码来启动 Jupyter 笔记本实例:$ jupyter notebook -
在浏览器中打开应用提供的 URL,然后打开名为
Activity_8_Re_training_a_model_dynamically.ipynb的 Jupyter 笔记本。现在,我们将从
cryptonic: Model()和CoinMarketCap()加载这两个类。 这些类有助于操纵模型的过程以及从网站 CoinMarketCap 获取数据的过程。 -
在 Jupyter 笔记本实例中,导航至标题
Fetching Real-Time Data。 现在,我们将从CoinMarketCap获取更新的历史数据。 只需调用方法:$ historic_data = CoinMarketCap.historic()现在,变量
historic_data填充有一个 Pandas 数据帧,其中包含截至今天或昨天的数据。 这很棒,可以在有更多数据时更容易地重新训练模型。数据实际上包含了与我们之前的数据集相同的变量。 但是,许多数据来自较早周期。 与几年前的价格相比,最近的比特币价格已经大幅波动。 在模型中使用此数据之前,请确保将其过滤为 2017 年 1 月 1 日之后的日期。
-
使用 Pandas API,仅过滤 2017 年可用日期的数据:
$ model_data = # filter the dataset using pandas here您应该能够通过使用日期变量作为过滤索引来做到这一点。 在继续之前,请确保已过滤数据。
类
Model()编译到目前为止我们在所有活动中编写的所有代码。 在本活动中,我们将使用该类来构建,训练和评估我们的模型。 -
使用
Model()类,我们现在使用前面的过滤数据训练模型:M = Model(data=model_data, variable='close', predicted_period_size=7) M.build() M.train() M.predict(denormalized=True)使用
Model()类训练模型时,前面的步骤展示了完整的工作流程。注意
对于参考解决方案,请使用
Code/Lesson-4/activity_8文件夹。接下来,我们将专注于每当有更多数据可用时就重新训练我们的模型。 这将网络的权重重新调整为新数据。
为此,我们将模型配置为使用 40 周来预测一周。 现在,我们要使用剩下的 10 个完整星期来创建 40 个星期的重叠期间,一次包括这 10 个星期中的一个,并针对其中每个期间重新训练模型。
-
导航到 Jupyter 笔记本中的标题
Re-Train Old Model。 现在,使用索引将数据分成 7 天的重叠组,完成range函数和model_data过滤参数。 然后,重新训练我们的模型并收集结果:results = [] for i in range(A, B): M.train(model_data[C:D]) results.append(M.evaluate())变量
A,B,C和D是占位符。 使用整数可创建 7 天的重叠组,其中重叠为 1 天。重新训练模型后,继续并调用
M.predict(denormalized=True)函数并欣赏结果。接下来,我们将专注于每当有新数据可用时创建和训练新模型。 为此,我们现在假设我们拥有 2017 年 49 周的旧数据,而一周之后,我们现在有了新数据。 我们用变量
old_data和new_data来表示。 -
导航至标题训练新模型,然后在变量
old_data和new_data之间拆分数据:old_data = model_data[0*7:7*48 + 7] new_data = model_data[0*7:7*49 + 7] -
然后,首先使用
old_data训练模型:M = Model(data=old_data, variable='close', predicted_period_size=7) M.build() M.train()
该策略是从头开始构建模型,并在有新数据可用时对其进行训练。 继续并在以下单元格中实现它。
现在,我们拥有了,以便动态地训练模型。 在下一部分中,我们将模型部署为 Web 应用,并通过 HTTP API 在浏览器中提供其预测。
在本部分中,我们了解了在有新数据可用时训练模型的两种策略:
- 重新训练旧模型
- 训练新模型
后者创建了一个新模型,该模型将使用完整的数据集进行训练,测试集中的观察结果除外。 前者在可用数据上训练模型一次,然后继续创建重叠的批量,以在每次有新数据可用时重新训练同一模型。
将模型部署为 Web 应用
在此部分中,我们将模型部署为 Web 应用。 我们将使用一个名为cryptonic的示例 Web 应用来部署我们的模型,探索其架构,以便将来进行修改。 目的是让您将此应用用作更复杂应用的入门程序; 可以正常工作的启动器,可以根据需要扩展。
除了熟悉 Python 外,本主题还假定您熟悉创建 Web 应用。 具体来说,我们假设您对 Web 服务器,路由,HTTP 协议和缓存有所了解。 无需广泛了解这些主题,您就可以在本地部署演示的密码应用,但是学习这些主题将使将来的开发变得更加容易。
最后,使用 Docker 部署我们的 Web 应用,因此该技术的基础知识也很有用。
应用架构和技术
为了部署我们的 Web 应用,我们将使用“表 1”中描述的工具和技术。 Flask 是关键,因为它有助于我们为模型创建 HTTP 接口,从而使我们能够访问 HTTP 端点(例如/predict)并以通用格式接收数据。 之所以使用其他组件,是因为它们是开发 Web 应用时的流行选择:
| 工具或技术 | 描述 | 角色 |
|---|---|---|
| Docker | Docker 是一种用于处理以容器形式打包的应用的技术。 Docker 是一种越来越流行的用于构建 Web 应用的技术。 | 打包 Python 应用和 UI。 |
| Flask | Flask 是用于用 Python 构建 Web 应用的微框架。 | 创建应用路由。 |
| Vue.js | JavaScript 框架通过根据来自后端的数据输入在前端动态更改模板来工作。 | 呈现用户界面。 |
| Nginx | 可轻松配置 Web 服务器,以将流量路由到 Dockerized 应用并处理 HTTPS 连接的 SSL 证书。 | 在用户和 Flask 应用之间路由流量。 |
| Redis | 键值数据库。 由于其简单性和速度,它是实现缓存系统的流行选择。 | 缓存 API 请求。 |
“表 1”:用于部署深度学习 Web 应用的工具和技术
这些组件组合在一起,如下图所示:
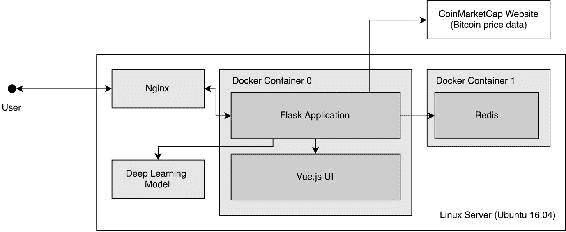
图 1:此项目中构建的 Web 应用的系统架构
用户使用他们的浏览器访问 Web 应用。 然后,该流量由 Nginx 路由到包含 Flask 应用的 Docker 容器(默认情况下,在端口5000上运行)。 Flask 应用已在启动时实例化了我们的比特币模型。 如果给出了模型,则无需训练即可使用该模型; 如果没有,它将创建一个新模型并使用 CoinMarketCap 的数据从头开始训练它。
准备好模型后,应用将验证请求是否已在 Redis 上缓存-如果是,它将返回缓存的数据。 如果不存在缓存,则它将继续进行并发布在 UI 中呈现的预测。
部署和使用加密
cryptonic是作为 Docker 化应用开发的。 用 Docker 术语来说,意味着可以将应用构建为 Docker 镜像,然后在开发或生产环境中将其部署为 Docker 容器。
Docker 使用名为Dockerfile的文件来描述如何构建镜像的规则以及将该镜像作为容器部署时会发生什么。 以下代码提供了 Cryptonic 的 Dockerfile:
FROM python:3.6
COPY . /cryptonic
WORKDIR "/cryptonic"
RUN pip install -r requirements.txt
EXPOSE 5000
CMD ["python", "run.py"]
“代码段 7”:用于在本地构建 Docker 镜像的 Docker 命令
可以使用 Dockerfile 通过以下命令构建 Docker 镜像:
$ docker build --tag cryptonic:latest
此命令将使镜像cryptonic:latest可以部署为容器。 可以在生产服务器上重复构建过程,也可以直接部署镜像,然后将其作为容器运行。
生成镜像并可用后,可以使用命令docker run运行加密应用,如以下代码所示:
$ docker run --publish 5000:5000 \
--detach cryptonic:latest
片段 8:在终端中执行
docker run命令的示例
--publish标志将localhost上的端口5000绑定到 Docker 容器上的端口5000,并且--detach在后台将容器作为守护程序运行。
如果您训练了不同的模型,并且想用它代替训练新的模型,则可以更改docker-compose.yml上的MODEL_NAME环境变量,如代码段 9 所示。该变量应包含您已经训练并想要使用的模型的文件名(例如bitcoin_lstm_v1_trained.h5),它也应该是 Keras 模型。 如果这样做,请确保也将本地目录装载到/models文件夹中。 您决定挂载的目录必须具有模型文件。
cryptonic应用还包含许多环境变量,这些变量在部署自己的模型时可能会有用:
MODEL_NAME:允许提供经过训练的模型供应用使用。BITCOIN_START_DATE:确定将哪一天用作比特币序列的开始日期。 近年来,比特币价格的波动性要比早期的波动大得多。 此参数仅将数据过滤到感兴趣的年份。 默认值为 2017 年 1 月 1 日。PERIOD_SIZE:以天数设置周期大小。 默认值为7。EPOCHS:配置模型在每次运行中训练的周期数。 默认值为300。
可以在docker-compose.yml文件中配置这些变量,如以下代码所示:
version: "3"
services:
cache:
image: cryptonic-cache:latest
volumes: - $PWD/cache_data:/data
networks:- cryptonic
ports: - "6379:6379"
environment:
- MODEL_NAME=bitcoin_lstm_v0_trained.h5
- BITCOIN_START_DATE=2017-01-01
- EPOCH=300
- PERIOD_SIZE=7
“代码段 9”:
docker-compose.yml文件,包括环境变量
部署cryptonic的最简单方法是使用代码段 9 中的docker-compose.yml文件。此文件包含应用运行所必需的所有规范,包括有关如何与 Redis 缓存连接以及要使用的环境变量的说明。 导航到docker-compose.yml文件的位置后,可以使用命令docker-compose up启动cryptonic,如以下代码所示:
$ docker-compose up -d
“代码段 10”:使用
docker-compose启动 Docker 应用。 标志-d在后台执行应用。
部署后,可以通过 Web 浏览器在端口5000上访问cryptonic。 该应用具有一个简单的用户界面,该用户界面带有一个时序图,描绘了真实的历史价格(换句话说,观察到的)和来自深度学习模型的预测未来价格(换句话说,预测的)。 您还可以在文本中读取使用Model().evaluate()方法计算出的 RMSE 和 MAPE:

图 2:已部署的加密应用的屏幕截图
除了其用户界面(使用 Vue.js 开发)外,该应用还具有 HTTP API,该 API 会在调用时进行预测。 该 API 具有端点/predict,该端点返回一个 JSON 对象,其中包含未来一周内非规范化的比特币价格预测:
{
message: "API for making predictions.",
period_length: 7,
result: [
15847.7,
15289.36,
17879.07,
…
17877.23,
17773.08
],
success: true,
version: 1
}
片段 11:
/predict端点的示例 JSON 输出
现在,应用可以部署在远程服务器中,并用于持续预测比特币价格。
活动 9 – 部署深度学习应用
在此活动中,我们将模型作为本地 Web 应用部署。 这使我们可以使用浏览器连接到 Web 应用,或者通过应用的 HTTP API 使用另一个应用。 在继续之前,请确保您已经安装了以下应用,并且在计算机中可用:
- Docker(社区版)17.12.0-ce 或更高版本
- Docker Compose(
docker-compose)1.18.0 或更高版本
可以从以下网站下载上述两个组件并将其安装在所有主要系统中。 这些对于完成此活动至关重要。 继续前进之前,请确保这些在系统中可用。
-
在您的终端上,浏览至加密目录并为所有必需的组件构建 docker 镜像:
$ docker build --tag cryptonic:latest . $ docker build --tag cryptonic-cache:latest ./ cryptonic-cache/ -
这两个命令构建了我们将在此应用中使用的两个镜像:密码(包含 Flask 应用)和密码缓存(包含 Redis 缓存)。
-
生成图像后,识别
docker-compose.yml文件并在文本编辑器中将其打开。 将参数BITCOIN_START_DATE更改为 2017 年 1 月 1 日以外的日期:BITCOIN_START_DATE = # Use other date here -
最后,使用
docker-compose在本地部署 Web 应用,如下所示:docker-compose up您应该在终端上看到活动日志,包括模型中的训练周期。
-
训练完模型后,您可以在
http://localhost:5000上访问您的应用,并在http://localhost:5000/predict上进行预测:图 3:本地部署的加密应用的屏幕快照
注意
对于参考解决方案,请使用Code/Lesson-4/activity_9 文件夹。
总结
本课结束了我们创建深度学习模型并将其部署为 Web 应用的旅程。 我们的最后一步包括部署一个模型,该模型预测使用 Keras 和 TensorFlow 引擎构建的比特币价格。 我们通过将应用打包为 Docker 容器并进行部署来完成工作,以便其他人可以通过其 API 以及我们的模型使用模型的预测。
除了这项工作之外,您还了解到还有很多可以改进的地方。 我们的比特币模型只是模型可以做的事(尤其是 LSTM)的一个例子。 现在的挑战有两方面:随着时间的流逝,如何使该模型的表现更好? 而且,可以将哪些功能添加到 Web 应用中以使模型更易于访问? 祝你好运,继续学习!