Day56 Hive的安装与JDBC基本命令
目录
Hive的安装
前提:
安装步骤:
上传
解压hive-3.1.2
重命名:
配置环境变量
配置HIVE文件
配置hive-site.xml
配置日志
修改默认配置文件
上传MySQL连接jar包
修改MySQL编码
初始化HIVE
进入Hive
后续配置
测试hive
hive中的几种存储格式
TextFile格式:文本格式
RCFile:
ORCFile:
Parquet:
其他格式:
配置JDBC连接
报错:
连接到JDBC
Hive基本语法
数据库定义语言DDL
创建数据库
查看数据库信息:
通过指定路径创建数据库:
删除数据库:
创建表:
删除表:
查看表:
各方法举例:
Hive的安装
前提:
安装hive所需要的虚拟机环境为虚拟机安装有Hadoop并且集群成功,同时Hadoop需要在启动状态下,同时需要安装有mysql。不需要有zookeeper和HA,由于HA中含有大量进程,启动会占用很多资源,建议不要有HA
安装步骤:
上传
将hive-3.1.2上传到虚拟机中的/usr/local/soft目录下

解压hive-3.1.2
输入命令:
tar -zxvf apache-hive-3.1.2-bin.tar.gz
解压文件:

重命名:
mv apache-hive-3.1.2-bin hive-3.1.2
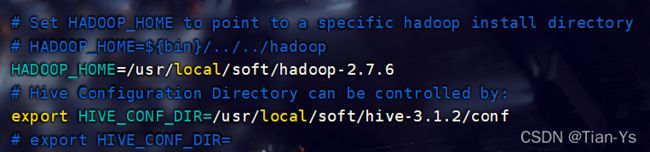
配置环境变量
vim /etc/profile 进入到环境变量中:添加以下内容:

保存退出,输入source /etc/profile使环境变量生效
配置HIVE文件
配置hive-env.sh
cd $HIVE_HOME/conf 进入到conf目录中
复制创建hive.env.sh
cp hive-env.sh.template hive-env.sh
输入命令:
vim hive-env.sh 进入到hive-env.sh中增加如下内容:
配置hive-site.xml
上传hive-site.xml到conf目录:
hive-site.xml文件内容:
hive.cli.print.header
true
hive.cli.print.current.db
true
hive.metastore.warehouse.dir
/user/hive/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
master
配置日志
创建日志目录:
在hive根目录hive-3.1.2下创建log日志目录:
mkdir log
设置日志配置
复制创建hive-log4j2.properties,输入命令:
cd conf
cp hive-log4j2.properties.template hive-log4j2.properties
进入到hive-log4j2.properties中:
vim hive-log4j2.properties
修改以下内容:
property.hive.log.dir = /usr/local/soft/hive-3.1.2/log

修改默认配置文件
复制创建hive-default.xml:
cp hive-default.xml.template hive-default.xml
上传MySQL连接jar包
上传 mysql-connector-java-5.1.37.jar 至 /usr/local/app/hive/lib目录中
修改MySQL编码
1、修改mysql编码为UTF-8
1.1 编辑配置文件
vim /etc/my.cnf
1.2 加入以下内容:
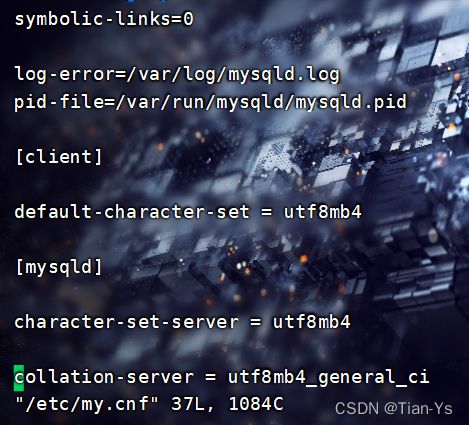
1.3 重启mysql
systemctl restart mysqld
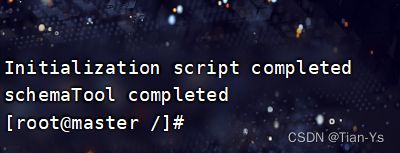
初始化HIVE
输入命令:
schematool -dbType mysql -initSchema
结果:成功截图
进入Hive
输入命令:hive
简单测试:在默认库中创建一个student表,向其中插入一条数据

查看结果:

该表在创建后,数据会存放在hdfs上,在上述配置文件hive-site.xml中,有一个默认本地仓库的存储位置:/user/hive/warehouse
进入到其中查看:

后续配置
修改mysql元数据库hive,让其hive支持utf-8编码以支持中文,若在此之前mysql就已经修改过,则不需要。
登录mysql:
mysql -u root -p123456
切换到hive数据库:
use hive;
1).修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8

2).修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
3).修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table PARTITIONS default character set utf8;
alter table PARTITION_KEY_VALS default character set utf8;
alter table SDS default character set utf8;
4).修改索引注解(可选)
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
5).修改库注释字符集
alter table DBS modify column DESC varchar(4000) character set utf8;
若报错则去Navicat中更改hive库中对应DBS表的字段字符集和排序,排序没有要求,任意规则即可。
测试hive
启动hive,直接输入命令:hive
在hive中创建filetest数据库
命令: create database filetest;
切换filetest数据库:use filetest;
hive中的几种存储格式
TextFile格式:文本格式
以TextFile格式创建students表:

使用命令:desc students查看students表的各个字段:
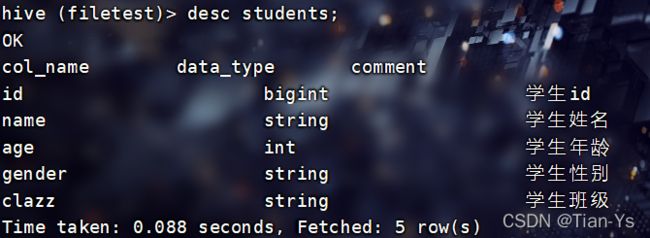
在hive根目录下创建一个文件夹data用于存放本地文件,将本地中的一个文本文件上传到hive根目录下的data中
向表中插入数据:
1、通过input命令将该data中的文本文件上传到hdfs中所创建的该表中,实现向该表中插入数据
在hive中可以使用hdfs中的命令:
查询结果:
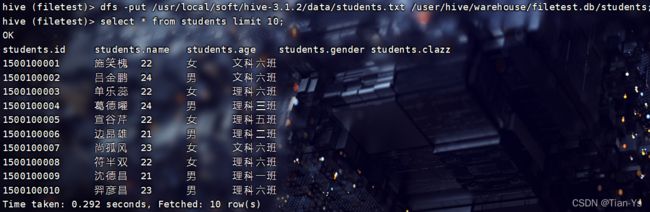
2、通过普通的格式对表中进行插入数据
创建一个新的表stduents2,使用普通格式进行插入数据:
load data local inpath "/usr/local/soft/hive-3.1.2/data/students.txt" into table students2;
结果:

进入到hdfs中查看:发现两种插入方式对数据大小没有变化,都是37M:

RCFile:
Hadoop中第一个列文件格式
RCFile通常写操作较慢,具有很好的压缩和快速查询功能。
创建RCFile格式的表:
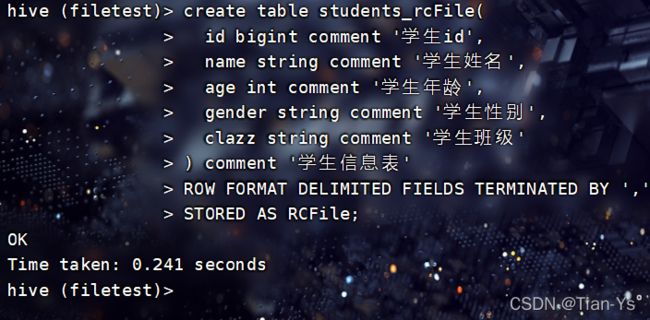
插入数据:
使用命令:
insert into table students_rcFile select * from students;

插入完成后,查看数据大小:为26.44M

ORCFile:
Hadoop0.11版本就存在的格式,不仅是一个列文件格式,而且有着很高的压缩比
创建ORCFile格式的表:

向表中插入数据:

查看数据大小:被压缩为220.38KB

同时观察插入数据所用时间,ORCFile格式与RCFile格式插入数据相差时间不大
Parquet:
这是一种嵌套结构的存储格式,他与语言、平台无关
创建Parquet格式的表:
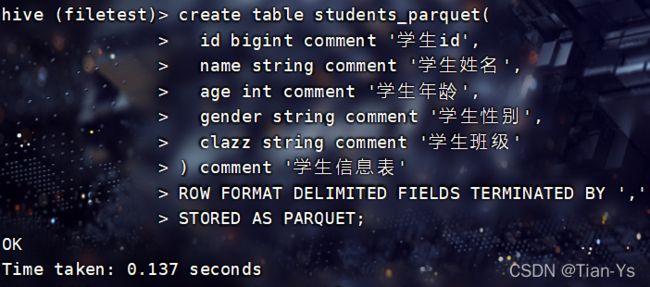
向表中插入数据:
insert into table students_parquet select * from students;

查看数据大小:为3M

同时发现该格式在插入数据时所花费的时间比ORC格式所花费的时间更少。
其他格式:
SEQUENCEFILE格式:这是一个Hadoop API提供的一种二进制文件格式,实际生产中不使用
AVRO:是一种支持数据密集型的二进制文件格式,他的格式更为紧凑
配置JDBC连接
Hive中有两种命令模式:CLi模式和JDBC模式
Cli模式就是Shell命令行
JDBC模式就是Hive中的Java,与使用传统数据库JDBC的方式类似
开启JDBC连接:
进入到/usr/local/soft/hive-3.1.2/bin目录下,在bin目录下有一个hiveserver2文件,通过该文件开启JDBC连接:

输入命令:hive --service hiveserver2开启JDBC连接
一般情况下当出现四个Hive Session时就说明JDBC连接被开启了,也可以通过命令查看是否开启:
进入到 /usr/local/soft/hive-3.1.2/bin目录下:
输入:netstat -nplt | grep 10000
该输入的端口号为hive-site.xml中的hiveserver2服务的端口号

报错:
若输入该命令报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000:
Failed to open new session: java.lang.RuntimeException:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate root (state=08S01,code=0)
解决办法:
先关闭Hadoop集群:stop-all.sh
再进入到Hadoop 中的core-site.xml中添加如下内容:
fs.trash.interval
1440
#以下是添加的内容:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
注意:这些内容需要添在加
重新启动集群:start-all.sh
再次启动hiveserver2
hive --service hiveserver2
该过程较慢,需要等待
连接到JDBC
当启动JDBC连接后,会开启一个进程RunJar,使用jps命令就可查看
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby
连接到JDBC命令:
进入到 /usr/local/soft/hive-3.1.2/bin下,输入命令:
beeline -u jdbc:hive2://master:10000 -n root连接JDBC:
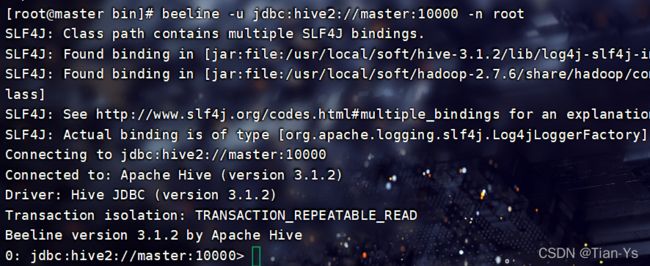
在JDBC中输入命令可以查看当前hive中的数据库:show databases;
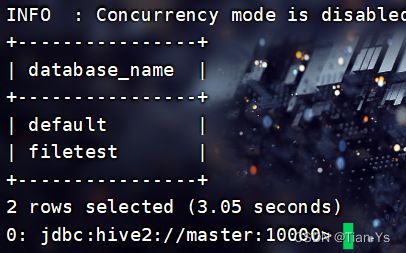
可以发现他与hive的区别在于他使用了一个表格式将databases显示出来
Hive中metastore是hive元数据的集中存放地,这里使用的是MySQL
Hive基本语法
在对一个数据库以及表进行操作时,会有中文字符存在,所以需要先进入到mysql中将上述后续配置中修改字符集的操作执行完毕,将字符集全部改为utf8,防止中文字符无法显示。
也可以通过Navicat连接到mysql,进入到其中的hive数据库中,找到对应的表,右击设计表,将其中对应的字段的字符集改为utf8即可
数据库定义语言DDL
创建数据库
简单创建一个数据库命令:
格式1:
CREATE DATABASE [IF NOT EXISTS] 数据库名称
表示创建一个数据库,当该数据库不存在的时候创建,若存在则不创建,也可以省略该判断条件
格式2:
CREATE DATABASE [IF NOT EXISTS] database_name COMMENT "数据库注释"
表示在创建一个数据库时加入一个该数据库的注释
举例:创建一个简单的数据库my_database

加入注释创建:

查看数据库信息:
格式:
show databases;查看当前所有数据库
desc database 数据库名称
举例:查看刚加入注释创建的数据库my_database 的信息

通过查看信息可以发现该数据库的默认存放位置在hdfs上的warehouse目录下
在hdfs上创建另一个目录testDatabase
查看数据库信息的第二种格式:查看数据库详细信息,包括所配置的参数
desc database extended 数据库名称;
通过指定路径创建数据库:
将创建的数据库存放到hdfs中的testDatabase中:
格式:
CREATE DATABASE [IF NOT EXISTS] database_name COMMENT "数据库注释" LOCATION "指定路径";
举例:
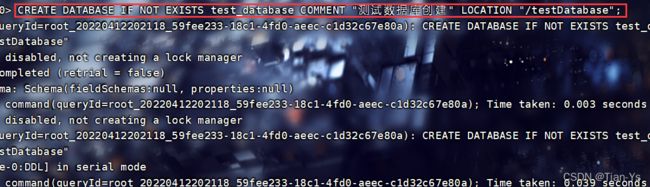
查看数据库信息:

在创建数据库时还可以增加一些配置信息 :
格式:
CREATE DATABASE IF NOT EXISTS test_database2 COMMENT "测试数据库创建" WITH DBPROPERTIES("author"="作者","application"="库中所包含信息");
删除数据库:
使用格式1:
DROP DATABASE 数据库名称;
举例:
 如果数据库不为空,删除会报错:message:Database my_database is not empty.
如果数据库不为空,删除会报错:message:Database my_database is not empty.
格式2:(慎用)
DROP DATABASE 数据库名称 cascade;
强制删除数据库,无论其中是否为空
创建表:
创建表中有很多创建方法:
ROW FORMAT:定义创建表时表中数据的分隔符号,若表中数据与分隔符不匹配则原始数据中的所有不匹配的数据会变成新表中的一列数据,hive中默认以制表符进行分隔
LOCATION:创建表时将表存储到指定路径下
EXTERNAL:表示创建表时,以外部表的形式创建
STORED AS:用于设置数据存储格式
TBLPROPERTIES:设置配置信息
PARTITIONED BY:构建分区表,包括列名 数据类型 注释信息
删除表:
格式:
DROP TABLE 表名;
当删除表时,hdfs上对应的该表的数据内容也会被删除
查看表:
查看表的字段信息:desc 表名;
查看表的详细信息:DESC FORMATTED 表名;
各方法举例:
ROW FORMAT:

这里设置分隔符号为制表符,数据存储格式为TextFile,指定存储路径到hdfs中的/testDatabase/total_score中。
使用本地文件加载表数据内容:
load data local inpath "/usr/local/soft/hive-3.1.2/data/total_score.txt" into table filetest.total_score1;
查询表内容十行:
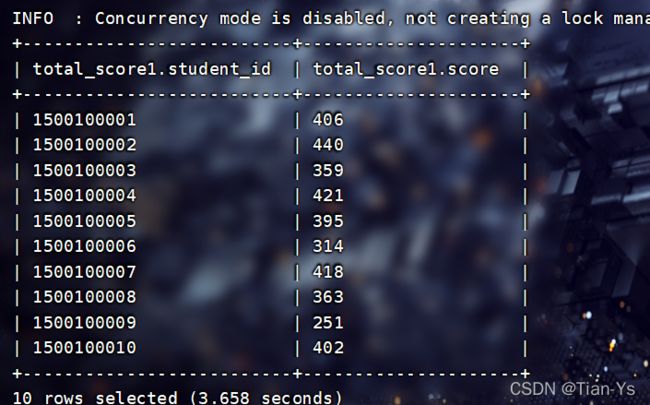
EXTERNAL:
若想要在删除表时,使得hdfs上对应的数据内容不被删除,仅仅删除表,可以创建一个外部表
创建一个外部表:
其余条件不变,加入一个EXTERNAL即可:

此时由于hdfs上的数据内容还未做删除操作,而该表的指定存储路径同之前的表的存储路径相同,所以创建该表后,该表自动加载其指定路径中的数据内容,不需要再重新加载数据内容。
直接查询就可以得到数据:

外部表与普通内部表的区别:外部表删除表时不会删除对应的数据 并且和表数据存储位置无关,
即当不指定数据内容存储路径时,所加载的数据内容会自动存储到默认路径中,当删除该表时,该数据内容仍然存在
STORED AS:
注意:以上创建表格式中指定存储格式为文本格式,若存储格式变为压缩格式ORC等,那么就不能直接将文本数据加载到表中
需要使用以下方式:
创建一个存储格式为ORC的表:

使用插入查询数据的方式加载数据内容:
INSERT INTO TABLE filetest.total_score3 SELECT * FROM filetest.total_score1;查看:
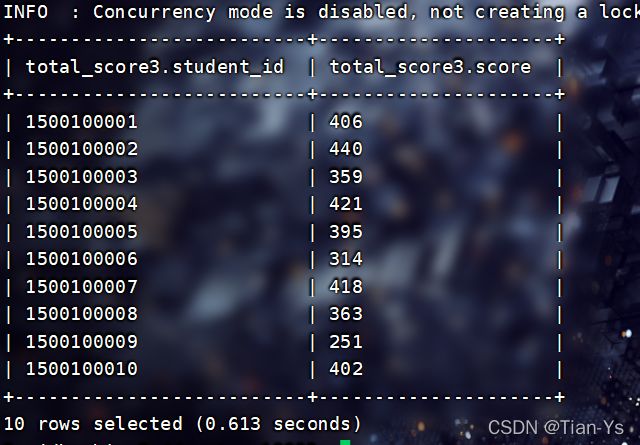
另一种格式:使用查询语句创建一个新表:

查看:前五行

TBLPROPERTIES:
在创建表时加入一些配置信息:

使用查看表的详细信息查看:其中application栏中可以看到配置信息:

PARTITIONED BY:
以指定字段分区保存数据
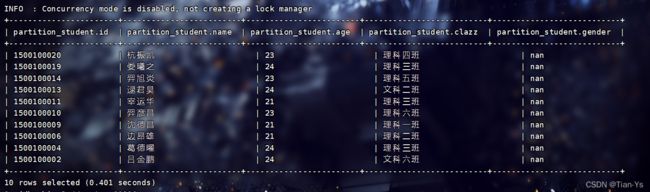
需求:将学生信息表中不同性别的学生进行分区保存
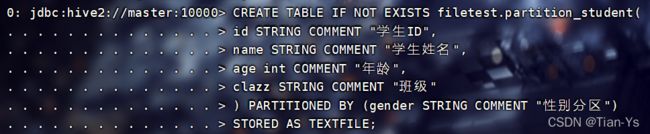
所设置的分区字段是一个单独字段:
查看字段信息:
 使用查询插入数据:
使用查询插入数据:
![]()
查看数据: