Day41_Hadoop之Yarn
(一)Yarn概述
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。

(二)Yarn基本架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster(AM)和Container等组件构成,如图所示:
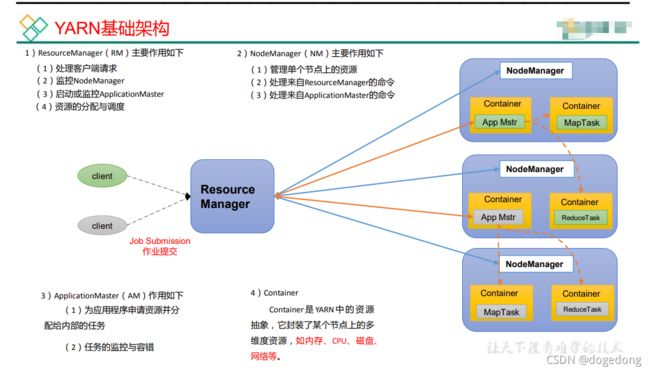
图:Yarn基本架构
(三)Yarn工作机制
Yarn运行机制,如图所示:
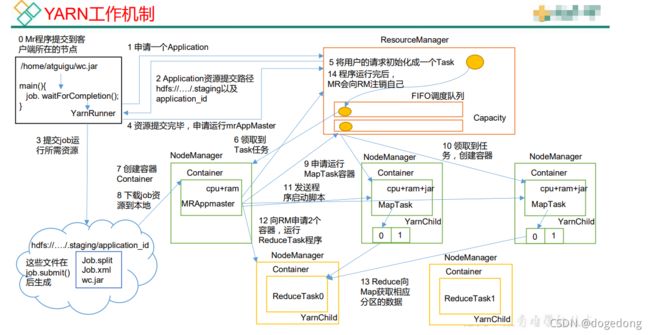
工作机制详解:
(1)Mr程序提交到客户端所在的节点。
(2)Yarnrunner向Resourcemanager申请一个Application。
(3)rm将该应用程序的资源路径返回给yarnrunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个task。
(7)其中一个NodeManager领取到task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行maptask资源。
(11)RM将运行maptask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动maptask,maptask对数据分区排序。
(13)MrAppMaster等待所有maptask运行完毕后,向RM申请容器,运行reduce task。
(14)reduce task向maptask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
注:MRAppMaster是MapReduce的ApplicationMaster实现,它能使MapReduce程序在Yarn上执行。
(四)调度器
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
目前,Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.2.1默认的资源调度器是Capacity Scheduler,可以在yarn-default.xml文件中查看。
1、先进先出调度器(FIFO)
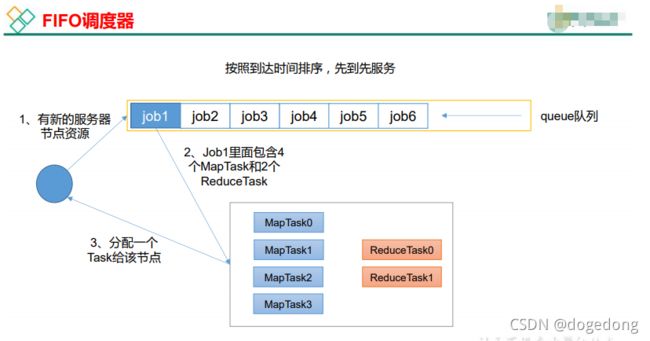
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,不需要做复杂的配置只需要在yarn-site.xml文件中设置即可,但它并不适用于共享集群(多人共同使用该集群)。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞,只能等到大任务执行完后释放了资源,才能执行。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。
在yarn-site.xml文件中添加如下设置:
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler
改完之后,将该文件分发到另外两台机器,并重启hdfs、yarn集群。
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-02:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-03:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
FIFO调度器特点:按照任务的提交顺序,先提交的任务优先满足其资源需求
可以将helloword案例中的输入文件准备200个,作为大任务先提交,再提交一个只有一个输入文件的小任务,发现小任务只能在大任务执行完后才能执行。
2、容量调度器(Capacity Scheduler)

在FIFO 调度器中,小任务会被先提交的大任务阻塞。那么有没有一种调度方式,可以同时运行先提交的大任务和后提交的小任务呢?有的,可以使用容量调度器,配置多个队列,把两个任务提交到不同队列就可以了。
Capacity 调度器允许创建多个队列分给多个组织以共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
在yarn-site.xml文件中添加如下设置:
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
然后,在etc/hadoop/capacity-scheduler.xml文件中进行多个队列的配置,配置说明如下:
yarn.scheduler.capacity.maximum-applications
10000
Maximum number of applications that can be pending and running.
yarn.scheduler.capacity.maximum-am-resource-percent
0.1
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
yarn.scheduler.capacity.resource-calculator
org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
yarn.scheduler.capacity.root.queues
test,dev
The queues at the this level (root is the root queue).
yarn.scheduler.capacity.root.dev.queues
java,bigdata
The queues at the this level (root is the root queue).
yarn.scheduler.capacity.root.test.capacity
40
Default queue target capacity.
yarn.scheduler.capacity.root.dev.capacity
60
Default queue target capacity.
yarn.scheduler.capacity.root.dev.maximum-capacity
75
The maximum capacity of the default queue.
yarn.scheduler.capacity.root.dev.java.capacity
50
Default queue target capacity.
yarn.scheduler.capacity.root.dev.bigdata.capacity
50
Default queue target capacity.
yarn.scheduler.capacity.root.dev.java.state
STOPPED
The state of the queue. State can be one of RUNNING or STOPPED.
yarn.scheduler.capacity.root.default.user-limit-factor
1
Default queue user limit a percentage from 0.0 to 1.0.
yarn.scheduler.capacity.root.default.acl_submit_applications
*
The ACL of who can submit jobs to the default queue.
yarn.scheduler.capacity.root.default.acl_administer_queue
*
The ACL of who can administer jobs on the default queue.
yarn.scheduler.capacity.node-locality-delay
40
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of nodes in the cluster, By default is setting
approximately number of nodes in one rack which is 40.
yarn.scheduler.capacity.queue-mappings
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
yarn.scheduler.capacity.queue-mappings-override.enable
false
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
改完之后,将该文件分发到另外两台机器,并重启hdfs、yarn集群。
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-02:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-03:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml bd-offcn-02:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml bd-offcn-03:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
我们可以看到,dev队列又被分成了java和bigdata两个相同容量的子队列。dev的maximum-capacity属性被设置成了75%,所以即使test队列完全空闲dev也不会占用全部集群资源,也就是说,test队列仍有25%的可用资源用来应急。我们注意到,java和bigdata两个队列没有设置maximum-capacity属性,也就是说java或bigdata队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%)。而类似的,test由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
Capacity调度器特点:
- 可以配置多个队列,各个队列可以配置一定资源量
- 各个队列采用FIFO的方式调度
- 各个队列上提交的job可以同时调用
- 如果某个队列的资源无法满足本队列job的需求,可以抢占其他队列的资源(弹性队列),为避免其它队列无资源可用,可以通过设置该队列最大资源量限制抢占
测试:可以把刚刚准备的大任务提交到bigdata队列,小任务提交到test队列,发现能够同时执行。
注意:在将mr程序提交到容量调度器的队列时,必须给mr程序指定要提交的队列名称,而且队列的名称不能写队列的全名称,例如root.bigdata,而只能写bigdata。
注意:此设置一定要在Job.getInstance(conf)之前设置,否则不生效
Configuration conf = new Configuration();
conf.set("mapreduce.job.queuename", "bigdata");
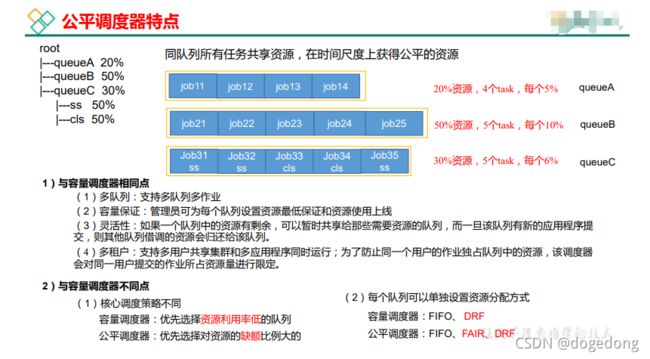
3、公平调度器(Fair Scheduler)
在FIFO 调度器中,小任务会被大任务阻塞。
而对于Capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
在yarn-site.xml文件中进行修改。
Fair Scheduler调度器设置如下:
The class to use as the resource scheduler.
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
公平调度器支持多个队列,每个队列也支持多种调度方式,需要手动创建配置文件 etc/hadoop/fair-scheduler.xml并添加如下配置。
在这里配置的所有队列都是root的子队列,每个队列都可以单独指定
fair
40
fifo
60
改完之后,将该文件分发到另外两台机器,并重启hdfs、yarn集群。
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-02:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/yarn-site.xml bd-offcn-03:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/fair-scheduler.xml bd-offcn-02:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
[offcn@bd-offcn-01 hadoop-3.2.1]# scp /home/offcn/apps/hadoop-3.2.1/etc/hadoop/fair-scheduler.xml bd-offcn-03:/home/offcn/apps/hadoop-3.2.1/etc/hadoop/
用户提交的任务进入哪个队列,根据queuePlacementPolicy里面规则来判断。
如果任务明确指定了队列,则进入指定的队列,否则根据用户的名字临时创建一个队列,这个用户的所有应用共享这个队列。
或者采取如下方式设置,所有应用都进入到default队列,实现所有用户的所有应用共享这个队列。
缺额:每个队列中的job按照优先级分配资源,优先级越高分配的资源越多,在资源有限的情况下,每个job理想情况下获得的计算资源与实际获得的计算资源存在一种差距,这个差距就叫做缺额。
Fair调度器特点:
- 支持多队列并发调度,每个队列都可以配置一定量的资源量
- 所有的队列都是root的子队列
- 每个队列可以单独设置调度方式,否则采用默认的调度方式(公平调度)
- 采用公平调度时,在同一个队列中,job的资源缺额越大,越先获得资源优先执行。作业是按照缺额的高低来先后执行的。
(五)任务推测执行机制
发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。
1、执行推测任务的前提条件
(1)每个task只能有一个备份任务;
(2)当前job已完成的task必须不小于0.05(5%)
(3)开启推测执行参数设置。Hadoop3.2.1的mapred-site.xml文件中默认是打开的。
mapreduce.map.speculative
true
If true, then multiple instances of some map tasks may be executed in parallel.
mapreduce.reduce.speculative
true
If true, then multiple instances of some reduce tasks may be executed in parallel.
2、不能启用推测执行机制情况
(1)任务间存在严重的负载倾斜;
(2)特殊任务,比如任务向数据库中写数据。