面试题:互联网三高解决思路
1.什么是互联网三高
互联网的三高架构就是指设计互联网系统架构时需要满足高可用,高性能,高并发
但高并发系统和非高并发系统,算两个维度,在这两个维度下还有三高:
(1)高可用
(2)高性能
(3)高扩展
1.1 高性能解决思路:
- 缓存(分布式缓存,本地缓存)
- 地理位置相关(GSLB,异地多活,单元化,让用户更容易访问到数据)
- 读写分离
- 同步变异步
- 串行改并行
- 池化技术(线程池连接池)
- 合并IO(例如数据库多次操作合并成一次)
- 优化网络,升级硬件设备
- 负载均衡(内网(f5,lvs,nginx,haproxy),全局(GSLB))
- 前端(动静分离,静态资源放cdn)
设计经验(大文件传输先传对象存储,防止带宽被占用,职责分离)
1.2 扩展的解决思路
- 无状态服务水平扩展(容器会更方便+自动伸缩机制)
- 数据库分库分表
- 微服务拆分
akf扩展立方:
AKF扩展立方体(Scalability Cube),是《架构即未来》一书中提出的可扩展模型,这个立方体有三个轴线,每个轴线描述扩展性的一个维度,他们分别是产品、流程和团队:
X轴 —— 代表无差别的克隆服务和数据,工作可以很均匀的分散在不同的服务实例上;
Y轴 —— 关注应用中职责的划分,比如数据类型,交易执行类型的划分;
Z轴 —— 关注服务和数据的优先级划分,如分地域划分。

更多内容AKF相关内容参考《可扩展架构的方法论——AKF扩展立方体 - 简书 (jianshu.com)》
2.三高整体解决思路:
横向分层、纵向分割、分布式化、集群化、使用缓存、使用异步模式、使用冗余、自动化(发布、部署、监控)
2.1 不同层次常用的技术有:
前端:
- - 浏览器优化技术:合理布局,页面缓存,减少http请求数,页面压缩,减少 cookie 传输。
- - CDN
- - DNS[负载均衡](https://cloud.tencent.com/product/clb?from=10680)
- - 动静分离
- - 动态图片独立提供服务
- - 反向代理
应用层架构
- - 业务拆分
- - 负载均衡
- - 虚拟化服务器、容器化
- - 无状态(以及分布式 Session)
- - 分布式缓存
- - 异步、事件驱动架构、[消息队列](https://cloud.tencent.com/product/cmq?from=10680)
- - 多线程
- - 动态页面静态化
服务层架构
- - 分布式微服务(分级管理,超时设置,异步调用,服务降级,幂等性设计。)
- - 同应用层架构
存储层架构
- - DFS
- - 关系[数据库](https://cloud.tencent.com/solution/database?from=10680)路由
- - No SQL 数据库
- - 数据同步
- - 数据冗余
安全架构
- Web攻击(XSS、Sql Injection)
- 数据加密
- 密钥管理
发布、运维
- - 自动化测试与发布
- - 灰度发布
- - 浏览器数据采集
- - 服务器业务数据采集
- - 服务器性能数据采集
- - 系统监控
- - 系统报警
机房
散热、省电、定制服务器
2.2高可用的相关知识
网站高可用指的就是:'在绝大多的时间里,网站一直处于可以对外提供服务的正常状态。'
业界通常使用有多少个“9”来衡量网站的可用性指标,具体的计算公式也很简单,就是一段时间内(比如一年)网站可用的时间占总时间的百分比。
```
2.21 可用性等级
四种最常见的可用性等级指标,以及允许的系统不可用时长:
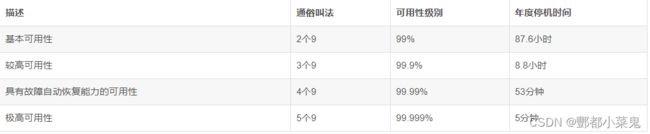
一般,我们以“年”为单位来统计网站的可用性等级。“9”的个数越多,一年中允许的不可用时间就越短,当达到 5 个“9”的时候,系统全年不可用时间只有区区 5 分钟,可想而知这个指标非常难达到。
所以一般来讲,业界的网站能做到 4 个“9”,也就是说在一年内只有 53 分钟的时间网站是处于不可用状态,就已经是算是非常优秀了。
2.22 造成不可用的原因
**造成网站不可用的主要原因有以下三大类:**
1. 服务器硬件故障;
2. 发布新应用的过程;
3. 应用程序本身的问题。
2.23 高可用架构设计方案
第一类方法是,从硬件层面加入必要的冗余;
第二类方法是,灰度发布;
第三类方法是,加强应用上线前的测试,或者开启预发布验证。
2.31 加入必要的冗余
```
对于硬件故障造成的网站不可用,最直接的解决方案就是从硬件层面加入必要的冗余,同时充分发挥集群的“牲口”优势。
```
2.32灰度发布
使用灰度发布的前提是,应用服务器必须采用集群架构。假定现在有一个包含 100 个节点的集群需要升级安装新的应用版本,那么这个时候的更新过程应该是:
1.首先,从负载均衡器的服务器列表中删除其中的一个节点;
2.然后,将新版本的应用部署到这台删除的节点中并重启该服务;
3.重启完成后,将包含新版本应用的节点重新挂载到负载均衡服务器中,让其真正接受外部流量,并严密观察新版本应用的行为;
4.如果没有问题,那么将会重复以上步骤将下一个节点升级成新版本应用。如果有问题,就会回滚这个节点的上一个版本。
5.如此反复,直至集群中这 100 个节点全部更新为新版本应用。
在这个升级的过程中,服务对外来看一直处于正常状态,宏观上并没有出现系统不可用的情况。就好比是为正在飞行中的飞机更换引擎,而飞机始终处于“正常飞行”的状态一样。
3. 设计一个高并发系统
思考维度:
1.系统拆分
2.缓存
3.MQ
4.分库分表
5.读写分离
3.1 系统拆分
将一个系统拆分为多个子系统,用 dubbo 来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,不也可以扛高并发么。
3.2缓存
缓存,必须得用缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家 redis 轻轻松松单机几万的并发。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
3.3MQ
MQ,必须得用 MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,你要是用 redis 来承载写那肯定不行,人家是缓存,数据随时就被 LRU 了,数据格式还无比简单,没有事务支持。所以该用 mysql 还得用 mysql啊。那你咋办?
用 MQ 吧,大量的写请求灌入 MQ 里,排队慢慢玩儿,后边系统消费后慢慢写,控制在 mysql 承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用MQ 来异步写,提升并发性。MQ 单机抗几万并发也是 ok 的
3.4分库分表
```
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来扛更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高 sql 跑的性能。
```
3.5读写分离
```
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可
以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
```
3.6 ElasticSearch
Elasticsearch,简称 es。es 是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来扛更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用 es 来承载,还有一些全文搜索类的操作,也可以考虑用 es 来承载。