4/16学习周报
文章目录
- 前言
- 文献阅读
-
- 摘要
- 简介
- 方法
- 评估标准
- 结果
- 结论
- 时间序列预测
-
- 支持向量机SVM
- 高斯过程GP
- RNN
- LSTM
- GRU
- transformer
- 总结
前言
本周阅读文献《Real-time probabilistic forecasting of river water quality under data missing situation: Deep learning plus post-processing techniques》,主要采用多元贝叶斯不确定性处理器(MBUP)对深度学习人工神经网络(ANN)的点预测与其相应的观测水质之间的关系进行概率建模,设计了TL-LSTM模型,与LSTM模型对比证明迁移学习算法对更准确的确定性预测的贡献,利用后处理技术(MBUP)进行探索,将确定性预测(即LSTM模型)转化为概率预测,降低河流水质预报的预测不确定性。另外,主要学习了时序预测的机器学习和深度学习模型。
This week,I read an article which introduced a novel methodology for probabilistic water quality forecasting conditional on point forecasts. A Multivariate Bayesian Uncertainty Processor (MBUP) was adopted to probabilistically model the relationship between the point forecasts made by a deep learning artificial neural network (ANN) and their corresponding observed water quality. Firstly, two deep learning ANNs (TL-LSTM and LSTM) were deployed to construct deterministic forecasting models. The comparison of TL-LSTM as well as LSTM models was to demonstrate the contributions of the transfer learning algorithm on more accurate deterministic forecasts. Then, the exploration of the post-processing technique (MBUP) was implemented for transforming the deterministic forecasting (i.e. LSTM models) into the probabilistic forecasting as well as upon decreasing the predictive uncertainty of river water quality forecasts.In addition,I mainly learn the machine learning and deep learning models of timing prediction.
文献阅读
题目:Real-time probabilistic forecasting of river water quality under data missing situation: Deep learning plus post-processing techniques
作者:Yanlai Zhou a b
摘要
量化由缺失输入数据引起的概率水质预测的不确定性从根本上具有挑战性。本研究引入了一种以点预报为条件的概率水质预报方法。采用多元贝叶斯不确定性处理器(MBUP)对深度学习人工神经网络(ANN)的点预测与其相应的观测水质之间的关系进行概率建模。该方法在中国上海市的一个岛屿上使用每小时水质系列进行了测试。新颖性依赖于:首先,使用迁移学习算法来克服人工神经网络中提出的河流水质平坦和预测不足的瓶颈,其次,使用MBUP捕获观测和预测之间的依赖结构。两个深度学习ANN用于进行点预测。然后,以点预报为驱动的MBUP方法证明了其在显著提高概率水质预报精度方面的能力,其中在多步提前水质预报中遇到的预测分布有效地缩小到小范围。结果表明,深度学习结合后处理方法适当提取了模型输出与观测水质之间的复杂依赖结构,使模型可靠性(含比>85%,平均相对带宽<0.25)和预测精度(Nash-Sutcliffe效率系数>0.8和均方根误差<0.4 mg/l)显著提高。 即使输入数据丢失率达到1%。
简介
水质监测和预测成为关键问题,因为每年都有大量污染物排放到海洋环境中。点源(例如市政和工业污水排放等)和非点源(例如农田和牲畜,水产养殖作业等)是两类常见的水污染源。必须提前做出准确可靠的水质预测,以减轻健康风险并治理水污染源。许多研究致力于建立各种模型来预测水质。水质预测出现了两个基本的挑战主题,以满足公众对人类健康日益增长的意识。首先,缺少输入数据不仅会增加水质预测的难度,而且会限制影响评估的发现。其次,实时水质预测正逐渐从传统的确定性预报转向概率预测。由于设施等原因收集到的数据通常存在缺失的情况。数据插补(Yang等人,2017)和迁移学习(Che等人,2018)算法是用于减轻缺失值对预测影响的两种常用方法(Lepot等人,2017)。数据插补算法从数据时空尺度的角度直接填充缺失数据,迁移学习算法间接从模型和参数传递的角度估计缺失数据。尽管数据插补算法和预测模型的组合被广泛使用,但以前的研究表明,由于在多步提前预测中引起实质性偏差,这种组合很容易创建系统的扁平预测和预测不足结果。因此,集成迁移学习算法和预测模型进行多步提前水质预测的课题具有挑战。
创建概率预测区间可以作为量化不同不确定性对水质预测影响的有效方法之一。BUP是用于测量预测不确定性的概率后处理技术的重要组成部分。单变量BUP(UBUP)(Krzysztofowicz,2002)方法用于提取预测和观测之间的非线性双变量相关性,而多变量BUP(MBUP)(Krzysztofowicz和Maranzano,2004)方法用于量化预测和观测之间的非线性多变量(≥3)相关性(Krzysztofowicz和Maranzano,2004)。).贝叶斯多元概率后处理(即MBUP)不仅提出了挑战,也为概率水质预报带来了各种机遇。因此,通过提取预报与观测值之间的非线性多元相关性,对MBUP进行深入研究,以表征和降低多步提前水质预报的不确定性。
本研究提出了一种基于MBUP的深度学习ANN和MBUP混合方法,以缩短数据缺失情况下多步提前水质预报的预测间隔。
贡献:
1.将迁移学习和深度学习ANN无缝集成,以克服因缺少输入数据而导致的确定性河流水质预测趋于平缓/不足的问题。
2.进一步采用多元不确定性处理器(即MBUP)作为后处理技术,提高概率河流水质预报的可靠性。
利用基于迁移学习的LSTM(即TL-LSTM)和标准LSTM两种人工神经网络构建数据缺失情况下的水质预报模型,并采用创建更可靠、更准确的点预报模型进行概率预报。其次,采用MBUP概率后处理方法,将点水质预报转化为概率水质预报。
方法
迁移学习和 LSTM 模型 (TL-LSTM) 的混合
迁移学习算法可以将学习到的知识从一个类似的领域(参考)转移到另一个相关领域(目标)。迁移学习算法通常用于目标域的预测模型过于复杂或目标域具有长间隔数据缺失条件的情况。本研究引入迁移学习算法,将具有完整数据的参考时间序列(RTS)的知识学习和迁移到具有数据缺失情况的目标时间序列(TTS)。迁移学习机制分为三种不同的设置,即数据模式转移(例如趋势和统计特征),模型转移(例如模型结构和参数)和任务转移(例如关于分类和聚类的多任务学习)。由于它需要从RTS学习和建模模式,因此本研究将采用数据模式传递(统计特征)和模型传递(模型结构和参数)。
TL-LSTM和LSTM模型的区别在于:(1)前者使用迁移学习算法来处理数据丢失情况,而后者不使用;(2)两个模型在训练和验证阶段的输入数据差异显著。
多元贝叶斯不确定性处理器 (MBUP)
四个基本步骤构成了MBUP的一般实施程序:
步骤1:数据转换。使用元高斯策略将具有真实空间的观测和预测数据集转换为高斯数据
第 2 步:确定先验密度和似然函数。还采用元高斯策略计算先验密度函数和似然函数
步骤3:确定后密度函数。确定先验密度和似然函数后,相应地计算后验密度函数
第 4 步:概率预测。进行了蒙特卡罗模拟以创建概率预测。根据后验密度函数模拟了地平线m处观测的实现,并重复了K次蒙特卡罗模拟。K是蒙特卡罗模拟的次数,在本研究中设置为1000。采用90%置信区间来揭示水质概率预测的不确定性。然后,观测和预测数据集(例如DO,NH3-N,COD)与高斯空间一起变换为实空间,用于评估MBUP概率预测的性能。
评估标准
为了进行比较,引入了均方根误差(RMSE)和纳什-萨特克利夫效率系数(NSE)来评估确定性预测模型的性能。RMSE和NSE的指标如下:
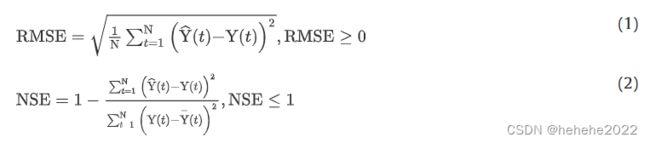
采用平均相对带宽(RB)和包含比(CR)来评估概率预测模型的性能,他们的数学公式描述如下:
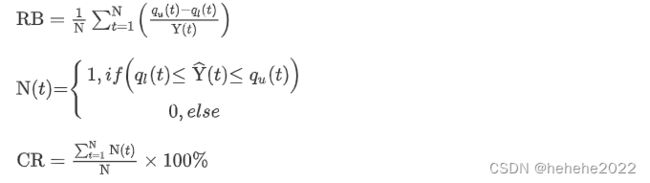
结果
利用LSTM和TL-LSTM模型独立对河流水质进行确定性预测,然后采用MBUP方法对河流水质进行概率预测。
确定性水质预测
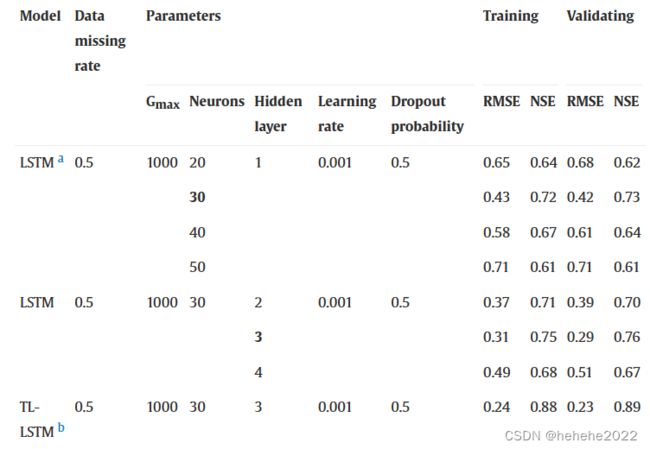
结果表明:此外,在相同的数据缺失率(=0.5)下,与其他LSTM模型相比,TL-LSTM模型产生的RMSE值最小,NSE值最大。
为了进一步评估不同水质站(S0 – S0)不同数据缺失率(9–1.10)对模型性能的影响,设计了四组比较实验来评估两种确定性预测模型的准确性。
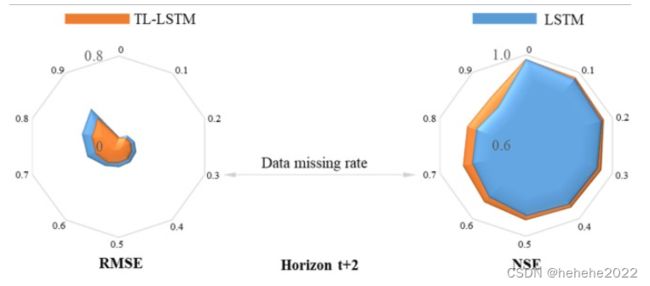
1)LSTM模型在各数据缺失率下水质预报性能较差;2)TL-LSTM模型不仅在单个数据丢失率方面,而且在每个层面都获得了最佳性能。很容易发现,与 LSTM 模型相比,TL-LSTM 模型在测试阶段的所有数据缺失率下创建的 NSE 指标值要高得多,但 RMSE 指标值要小得多。对于水平t+10和数据缺失率(=0.9),RMSE和NSE指标的改善率分别达到24.7%和23.3%。
概率水质预测

结果表明,TL-LSTM加MBUP方法在所有地平线和所有台站的预测精度较高,而LSTM加MBUP方法在大于t+6的视界处表现不佳(CR值低于89%,RB值高于0.15)。
结论
本研究探讨了采用MBUP方法的深度学习人工神经网络对概率水质预测进行建模。在大量缺失数据的水质监测站,如何提高预报的准确性和可靠性从根本上具有挑战性。此外,需要概率预报而不是确定性预报方法,这归因于实际业务预报的要求和降低水质预报的随机性。部署两个深度学习人工神经网络(TL-LSTM和LSTM)构建上海市海岛当地水质值的确定性预报模型;TL-LSTM和LSTM模型的比较是为了证明迁移学习算法对更准确的确定性预测的贡献。然后,利用后处理技术(MBUP)进行探索,将确定性预测(即LSTM模型)转化为概率预测。MBUP方法的贡献依赖于提取观测和预报之间的复杂非线性多变量(≥3)相关性,以及降低河流水质预报的预测不确定性。
时间序列预测
机器学习的时序预测方法
支持向量机SVM
SVM 支持向量机的详细内容可以看这篇文章:https://zhuanlan.zhihu.com/p/77750026
支持向量机(support vector machines,SVM)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。
模型主要包括三种:
当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机。
当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机。
当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机。
SVM算法的原理:
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。
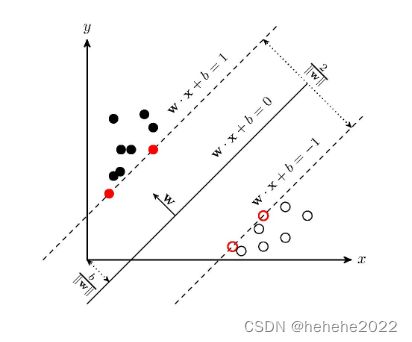
任意超平面可以用下面这个线性方程来描述:

几何间隔:对于给定的数据集 T 和超平面 w* x+b=0 ,定义超平面关于样本点 ( x_i,y_i) 的几何间隔为
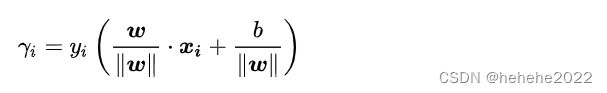
超平面关于所有样本点的几何间隔的最小值为
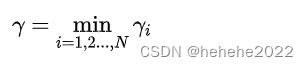 实际上这个距离就是我们所谓的支持向量到超平面的距离。
实际上这个距离就是我们所谓的支持向量到超平面的距离。
根据以上定义,SVM模型的求解最大分割超平面问题可以表示为以下约束最优化问题
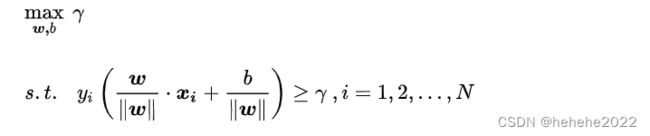
经过一系列变换,SVM模型的求解最大分割超平面问题又可以表示为以下约束最优化问题:
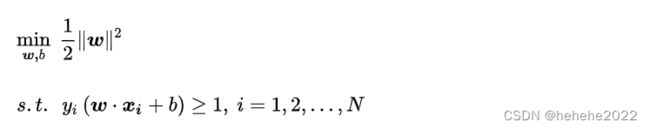
这是一个含有不等式约束的凸二次规划问题,可以对其使用拉格朗日乘子法得到其对偶问题(dual problem)。原约束问题等价于

要有 p*= d ^* ^ ,需要满足两个条件:
① 优化问题是凸优化问题
② 满足KKT条件
最终优化形式变成如下形式:
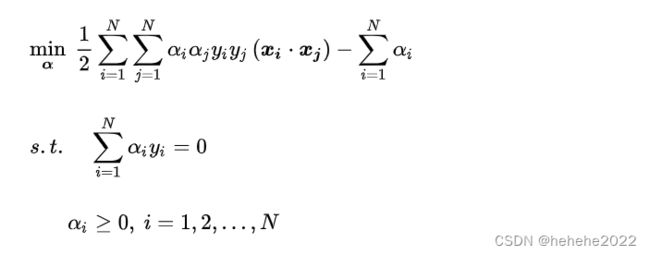
支持向量机的优点:
1.有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
2.能够处理不平衡数据,其中一个类的示例比另一个类多很多。这是因为支持向量机专注于寻找支持向量,这是数据中最重要的点,而不是试图对数据中的所有点进行分类。能找出对任务至关重要的关键样本(即:支持向量);
3.最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
缺点:
1.训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为 O(N) ,其中 N 为训练样本的数量;
2.模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务。
高斯过程GP
这部分内容之前的周报内容介绍过
深度学习的时序预测方法
RNN
循环神经网络(Rerrent Neural Network, RNN),RNN是神经网络的一种,类似的还有深度神经网络DNN,卷积神经网络CNN,生成对抗网络GAN,等等。RNN的特点就是RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
RNN的结构及原理:
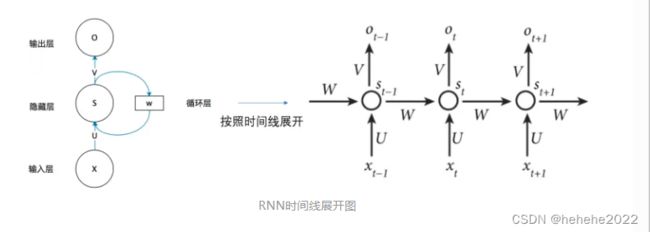
上图展开后,W一直没有变,W其实是每个时间点之间的权重矩阵,我们注意到,RNN之所以可以解决序列问题,是因为它可以记住每一时刻的信息,每一时刻的隐藏层不仅由该时刻的输入层决定,还由上一时刻的隐藏层决定,公式如下,其中 Ot 代表t时刻的输出, St 代表t时刻的隐藏层的值:

值得注意的一点是,在整个训练过程中,每一时刻所用的都是同样的W。
LSTM
LSTM(Long short-term memory)长短期记忆,是RNN的一种,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。LSTM是RNN的一种变体,更高级的RNN,那么它的本质还是一样的,可以有效的处理序列数据,
为什么会发生梯度爆炸和消失:
本质上是因为神经网络的更新方法,梯度消失是因为反向传播过程中对梯度的求解会产生sigmoid导数和参数的连乘,sigmoid导数的最大值为0.25,权重一般初始都在0,1之间,乘积小于1,多层的话就会有多个小于1的值连乘,导致靠近输入层的梯度几乎为0,得不到更新。梯度爆炸是也是同样的原因,只是如果初始权重大于1,或者更大一些,多个大于1的值连乘,将会很大或溢出,导致梯度更新过大,模型无法收敛。
LSTM内部主要有三个阶段:
1.忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
具体来说是通过计算得到的 Zf(f表示forget)来作为忘记门控,来控制上一个状态的 Ct-1 哪些需要留哪些需要忘。
2.选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 Xt 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 Z 表示。而选择的门控信号则是由 Zi(i代表information)来进行控制。
将上面两步得到的结果相加,即可得到传输给下一个状态的 Ct 。也就是上图中的第一个公式。
3. 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 Zo来进行控制的。并且还对上一阶段得到的 Co进行了放缩(通过一个tanh激活函数进行变化)。
LSTM内部结构:
如果把LSTM当成黑盒子看待,可以分为以下关键变量(参考题图):
输入:ht-1(t-1时刻的隐藏层)和 Xt(t时刻的特征向量)
输出: ht(加softmax即可作为真正输出,否则作为隐藏层)
主线/记忆: Ct-1 和 Ct
LSTM内部结构图:
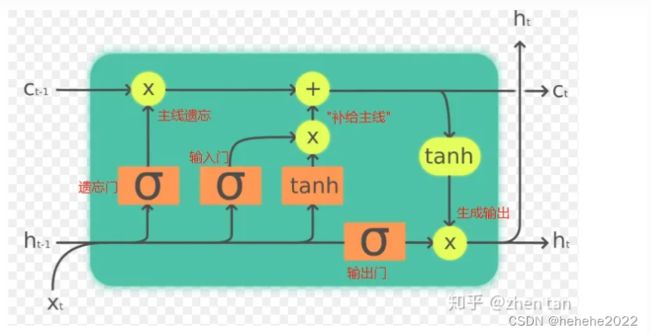
LSTM公式梳理

GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
GRU的输入输出结构与普通的RNN是一样的。有一个当前的输入Xt ,和上一个节点传递下来的隐状态(hidden state)ht-1,这个隐状态包含了之前节点的相关信息。
结合 Xt 和 ht-1,GRU会得到当前隐藏节点的输出 yt 和传递给下一个节点的隐状态 ht。
GRU的内部结构
GRU模型中有两个门,重置门和更新门,具体作用后面展开说。

符号说明:
Xt:当前时刻输入信息
h t-1 : 上一时刻的隐藏状态。隐藏状态充当了神经网络记忆,它包含之前节点所见过的数据的信息
h t : 传递到下一时刻的隐藏状态
h’t : 候选隐藏状态
rt : 重置门
Zt : 更新门
sigmoid函数,通过这个函数可以将数据变为0-1范围的数值。
tanh: tanh函数,通过这个函数可以将数据变为[-1,1]范围的数值
GRU的公式:
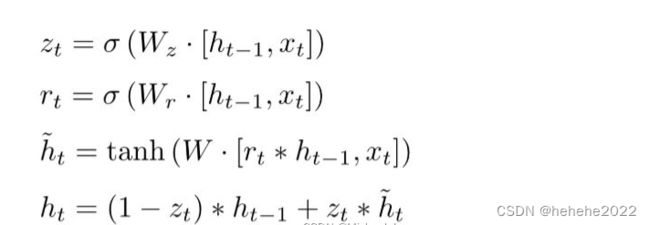
1.重置门
重置门决定了如何将新的输入信息与前面的记忆相结合,进一步介绍:
![]()
这里Wr并不是一个值,而是一个权重矩阵。
用这个权重矩阵对xt和ht-1拼接而成的矩阵进行线性变换(两个矩阵相乘)。然后将两个矩阵相乘得到的值投入sigmoide函数,会得到rt的值,比如:0.6 。这个值会用到候选隐藏状态的公式中,即下面这个公式:

将公式展开,
![]()
rt的值越小,它与ht-1哈达玛积出来的矩阵数值越小,再与权重矩阵相乘得到的值越小,也就是这个值越小,说明上一时刻需要遗忘的越多,丢弃的越多。
rt 的值越大,它与ht-1哈达玛积出来的矩阵数值越大,再与权重矩阵相乘得到的值越大,说明上一时刻需要记住的越多,新的输入信息(也就是当前的输入信息xt)与前面的记忆相结合的越多。
当rt的值接近0时,它与ht-1哈达玛积出来的矩阵数值越接近0,再与权重矩阵相乘得到的值越接近0,说明上一时刻的内容需要全部丢弃,只保留当前时刻的输入,所以可以用来丢弃与预测无关的历史信息。
当rt的值接近1时,它与ht-1哈达玛积出来的矩阵再与权重矩阵相乘得到的值越接近1,表示保留上一时刻的隐藏状态。
这就是重置门的作用,有助于捕捉时间序列里短期的依赖关系。
2.更新门
更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,也就是更新门帮助模型决定到底要将多少过去的信息传递到未来,简单来说就是用于更新记忆。结合下面两个公式比较好理解:
更新门公式:
![]()
更新记忆表达式:
![]()
zt越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
上面的等式,前半部分表示对上一时刻隐藏状态进行选择性“遗忘”。忘记ht-1中一些不重要的信息,把不相关的丢弃。后半部分表示对候选隐藏状态的进一步选择性”记忆“。会忘记 h’t中的一些不重要的信息。也就是对h’t中的某些信息进一步选择。
ht忘记传递下来的 ht-1中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
门控循环单元GRU不会随时间而清除以前的信息,它会保留相关的信息并传递到下一个单元。
transformer
transformer相关知识
总结
本周主要了解了机器学习和深度学习的时序模型,下周将学习环境类自然科学的时序。
参考博文:
https://www.zhihu.com/tardis/zm/art/31886934?source_id=1005
https://zhuanlan.zhihu.com/p/123211148 (rnn介绍)
https://zhuanlan.zhihu.com/p/338817680 (transformer的介绍)