迁移学习常用数据集
目录
Office-31
PACS
Office-Caltech10
MNIST+USPS
迁移学习常用数据集
Office-31
Office-31 Dataset 即 Office Dataset 是视觉迁移学习中的主流基准数据集,该数据集包含了31类办公室环境中常见的目标物体,如笔记本电脑、文件柜、键盘等,共4652张图像。
这些图像主要源于Amazon(在线电商图片)、Webcam(网络摄像头拍摄的低解析度图片)、DSLR(单反相机拍摄的高解析度图片)。
该数据集包括:
Amazon:2817张图像,平均每类90张,图像背景单一
Webcam:795张图像,图像表现出明显的噪点,颜色和白平衡伪
DSLR:498张图像,每类5个对象,每个对象从不同视点平均拍摄3次
示例图像:

PACS
PACS,数据集是一个域自适应的图像数据集,包含4个域,照片(1670张),艺术画(2048张),动画片(2344张)和素描(3929张)。每个域里面包含7个种类。
PACS数据集划分:
训练集:8977张图片
测试集:1014张图片
验证集:9991张图片
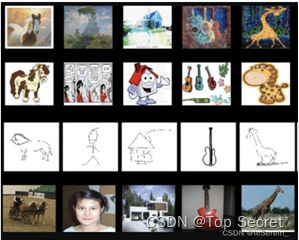
Office-Caltech10
该网站第一组:transferlearning/data at master · jindongwang/transferlearning · GitHub
Office-Caltech-10数据集包含有2533个样本,包含(C A W D)四种数据库的数据,C(Caltech), A(Amazon在线电商图片),W(Webcam网络摄像头拍摄的低解析度图片) 和D(DSLR单反相机拍摄的高解析度图片),其中C有1123个,A有958个,W有295个,D有157个,数据集提供了SURF特征和DeCAF特征。

该数据集有10类物体,是Office-31和Caltech-256数据集中相同的类:”backpack“,”bike“,”calculator“,”headphones“,”keyboard“,”laptop computer“,”monitor“,”mouse“,”mug“,”projector“。
Office-Caltech10的SURF特征和DeCAF特征:
Office-Caltech10是一个广泛使用的图像分类数据集,包含10个不同的物体类别,其中5个来自Office数据集,另外5个来自Caltech数据集。在Office-Caltech10数据集上,SURF特征和DeCAF特征都是常用的特征提取方法。
SURF特征:
SURF(Speeded Up Robust Features)特征是一种基于尺度空间的局部特征,它通过构建高斯金字塔来检测图像中的稳定特征点,并对这些特征点进行描述符计算。在Office-Caltech10数据集上,可以使用SURF算法提取每张图片的SURF特征。
对于每个图像中检测到的SURF关键点,SURF算法会计算其周围区域的Haar小波响应,并使用这些响应来计算SURF描述符。每个SURF描述符是一个64维的向量,其中包含了关键点的尺度、方向以及与周围像素的差分信息。
使用SURF算法提取的特征可以用来表示图像中的纹理、形状等低级特征,这些特征在物体分类任务中具有较好的表现。
DeCAF特征:
DeCAF(Deep Convolutional Activation Features)特征是一种基于卷积神经网络的特征提取方法,它使用预训练的CNN模型(如AlexNet)对每张图片进行前向传播,得到一组高维的特征向量表示。在Office-Caltech10数据集上,可以使用预训练的AlexNet模型来提取每张图片的DeCAF特征。AlexNet模型包含5个卷积层和3个全连接层,最后输出一个1000维的向量表示图片的分类概率分布。
对于每张图片,可以使用AlexNet模型的前8层对其进行前向传播,并提取第8层的特征向量作为DeCAF特征。这个特征向量通常具有4096个维度,可以用来表示图像的语义信息,例如图像中包含的物体、场景等。
使用DeCAF特征提取方法可以获得更高级别的特征表示,因为它是基于深度学习的特征提取方法,可以自动学习图像的特征表达。这种特征在物体分类任务中表现出色,尤其是在面对复杂的图像场景时。
特征表示方式:
Surf算法得到的特征点描述符是一个固定长度的向量,通常有64个维度。这些描述符可以用来表示图像的纹理、形状等低级特征。
DeCAF得到的特征向量是一个高维的向量,通常有4096个维度。这个向量可以用来表示图像的语义信息,比如图像中包含的物体、场景等。
适用场景:
Surf算法适用于需要快速检测图像中的稳定特征点的场景,比如目标跟踪、图像拼接等。
DeCAF算法适用于需要对图像进行高级语义分析的场景,比如图像分类、物体检测、图像搜索等。
总的来说,Surf和DeCAF是两种不同的特征提取算法,适用于不同的应用场景。Surf更适合用于低级别的图像处理任务,而DeCAF则更适合用于高级别的图像语义分析任务。
MNIST+USPS
手写体数字识别数据,随机从Mnist数据和USPS数据中选取的。Mnist每张图为28*28大小,一共70000张图片,10类数字。Usps数据集图片大小为16*16,共20000张图,10类数字。
数据的下载网站为:sam roweis : data

其他数据集参考地址:知乎传送门