【大数据】Hbase
文章目录
-
-
- 1.概述
-
-
- HBase和elasticsearch
- 行式存储和列式存储
-
- 1.行式存储
- 2.列式存储
- Hbase和Hive的不同
- 二 什么时候用Hbase
- 三 Hbase难点
-
- 1.表结构设计
- 2.hbase优化
- 四 Hbase数据模型
- 五 HLOG
- 六 HBASE体系结构
-
- 1.基本流程
- 2.zookeeper(2181)
- 3.master
- 4.regionServer
- 5.region
- 6.memstore 和 storefile
- 7.HFile
- 8.WAL日志系统
- 9.概述
- 七 Hbase优化
-
- 0 Hbase本身做的优化
- 1.表的设计
- 2.rowkey设计
-
- ⑴字典排序
- ⑵热点问题
- ⑶rowkey长度问题
- ⑶rowkey查询策略
- 3.column family
- 4.in menmory
- 5.maxversion
- 6.time to live设置表中数据的存储生命期。
- 7.compact & split
-
-
1.概述
Apache HBase是基于Hadoop构建的一个面向列的,分布式的、可伸缩的海量数据存储的数据库。和mapreduce不同,它是实时的。它的数据也存在于hdfs之上,可以做到交互式。主要用来存储非结构化,半结构化的松散数据
Hbase的设计思想来源于LSM树
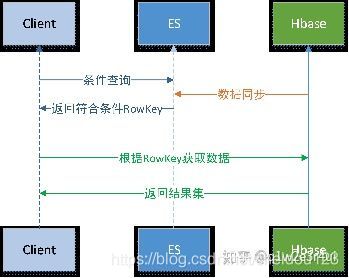
HBase和elasticsearch
hbase做搜索不如ES,但是HBASE更适合大批量的存储,如果ES把很多不需要查询的字段也都存进去了,那么会显著降低查询的性能,我们可以在ES存储查询的字段,然后把真正的数据存到hbase里面。
行式存储和列式存储
1.行式存储
以行位单位,底层每一行存储在一起。
行式存储维护大量索引,随机读效率高。最大的特点对事务支持好。
表与表之间关联,且数据量不大。线性扩展性不高,数据量不超过1亿。
2.列式存储
以列为单位,第一列存储完之后存第二列。
列式存储将每一列数据聚合在一起,利用列的相似性原理,便于压缩。查找不同列可以使用并行查询。
获取单列,多列可以使用并行,更新不多,对事务不高。
Hbase和Hive的不同
Hive是不能支持交互式查询的,Hbase是支持实时查询的.Hive不支持更新操作.
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase适合非常大量数据的实时查询
二 什么时候用Hbase
HBase常被用来存放一些海量的(通常在TB级别以上)结构比较简单的数据,如历史订单记录,日志数据,监控Metris数据等等,HBase提供了简单的基于Key值的快速查询能力。
三 Hbase难点
1.表结构设计
2.hbase优化
四 Hbase数据模型

- 每个表有且仅有一列是rowkey,rowkey相同的是一行。
- timestamp是描述版本的,hbase不能做修改,所以使用时间戳来记录版本,可以清理过时的数据,用这种方式hbase是可以做删除的。
- CF1 CF2 CF3叫做列族,HBASE表中每个列都属于某个列族,创建表的时候必须创建列族,但是不需要创建列。如create ‘test’,‘course’;HBASE同一列族里面的数据存储在同一目录下,由几个文件保存。权限控制,存储,调优都是以列族为单位,列族不超过2-3个。
- 列名以列族为前缀,每个列族都可以拥有多个列成员。如course:math,course:english,列族的列可以动态增减。
- CF2:q1=val3所在的单元格由rowkey,timestamp以及列族决定,和列没有关系,因为列是可以动态定义的。它是未解析的字节数组

时间戳:
64位整型,可以由HBASE在插入的时候自动赋值。
五 HLOG
记录了对hbase数据库的读写日志。
六 HBASE体系结构
上面的图有个问题:hlog是属于hregionserver的,不是图上属于hregion的
1.基本流程
客户端请求zookeeper,hbase的主节点就是hmaster,。每个store相当于一个列族。memstore是内存store,刚写进来放内存中,然后写到storeFile(磁盘),storeFile数据保存在HDFS上的,即HFile。storeFile存储HFile的元数据。
我们不断写,会产生大量的小文件,不利于HDFS,所以HBASE提供了一种新的机制,可以合并小文件。
client 包含访问hbase的接口并维护缓存来加快访问速度。
2.zookeeper(2181)
⑴保证任何时候集群只有一个master
⑵存储所有region的寻址入口
⑶实时监控region server的上线和下线信息。并实时通知master
⑷存储hbase的schema和table的元数据。
3.master
⑴为region server分配region
⑵为region server的负载均衡,把新增的region放到少的region server上去。
⑶发现失效的region server 并重新分配其上的region
⑷管理用户对table的增删改操作
4.regionServer
⑴维护region,处理这些region的io请求。
⑵负责切分在运行过程中变得过大的region,
如果我们要增加hbase的并发量,可以增加region server.
5.region
hbase自动把表水平划分成多个区域(region),每个region会保存一个表某段连续的数据,
每个表一开始只有一个region,随着数据不断插入表,region不断增大,增大到一个阈值时,region就会等分成两个新的region。
rowkey会按照字典顺序自动排序。hbase所有数据都是字节数组,rowkey其实也是字节数组,rowkey是不能相同的。
hregion是hbase中负载均衡的最小单元,但不是存储的最小单元。不同的hregion可以分布在不同的hregion server上region数量一定不要低于集群中节点的数量。
hregion由一个或者多个store组成,每个store保存一个columns family。
region有三个属性 table name,startrowkey,createtime
region拆分策略:
切分后要讲region信息写到元信息。
RegionServer和Region之间的关系:
Region是HBase数据存储和管理的基本单位。一个表中可以包含一个或多个Region。每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
regionServer 其实是hbase的服务,部署在一台物理服务器上,region有一点像关系型数据的分区
6.memstore 和 storefile
一个region由多个store组成,一个store对应一个CF(列族)
先写memstore,达到一个阈值,启动flashcache进程写入storefile,每次写入形成单独的一个storefile.
storefile数量增长到一个阈值时,系统会进行合并,合并分minor,major两种,major会合并和删除,minor不会。列族越多,store越多,合并次数越多,性能下降,任何一张表不超过三个列族,一般一个列族够了。
当region所有的storefile超过一定阈值,会分割成两个,并由Hmaster分配知道对应的regionserver服务器。实现负载均衡,所有hmaster可以保证新插数据的负载均衡。
客户端检索数据,会先找memstore,找不到找storefile
每个store又由一个memstore和0至多个storefile组成,storefile以hfile格式保存在hdfs上。
7.HFile
hflie是hbase的一种存储格式,hbase最终保存形态是hfile,hfile刷写成功不能修改,如果删除,我们底层数据有个keytype,标志位删除。
8.WAL日志系统
主要是为了灾难恢复,相当于mysql的binlog,log同步到远程机器上
通过hlog实现,每一个regionserver对应一个hlog,hlog最核心的append方法。
有时候为了性能,会将日志先保存内存中,有定时和内存阈值两种方式hlogsyncer
9.概述
先横向切分成region,再纵向切分成store.,根据rowkey定位region,然后根据列族定位store.,测试版可以把hbase数据保存到本地磁盘,而不是hdfs上
七 Hbase优化
0 Hbase本身做的优化
存储优化:
memstore和预写日志
获取优化:
hbase利用布隆过滤器来提高随机读而不是顺序读的速度。开启布隆过滤器会有一定的存储和内存开销。
1.表的设计
⑴ 预分区 解决数据倾斜问题
HBase表在刚刚被创建时,只有1个分区(region),当一个region过大(达到hbase.hregion.max.filesize属性中定义的阈值,默认10GB)时,表将会进行split,分裂为2个分区。表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
创建hbase表,要防止数据不对等,我们要创建表没有插入数据前,预先对表进行分区。可以在java里进行预分区。
假设我们要记录网站记录,我们以客户端ip地址作为rowkey。ip地址是12位,我们可以以start ,为 000000000000,end 256256256256 然后将它们平均分成N个区,这个N我们根据总数据量预估出来,然后算出每一个分区startrow和endrow.
为了防止有的区段ip地址访问量太大,造成数据不均衡。
可以不做预分区,先进行抽样。然后进行分区。100.101 – 100.205 访问量大,我们把它分为10个,前面和后面的各分成一个。分区只能裂变不能合并
2.rowkey设计
rowkey设计可以说是hbase最重要的地方之一
⑴字典排序
Rowkey排序时会先比对两个Rowkey的第一个字节,如果相同,然后会比对第二个字节,依次类推… 对比到第X个字节时,已经超出了其中一个Rowkey的长度,短的Rowkey排在前面
⑵热点问题
在Hbase中的row是按照字典排序的,将经常一起读取的数据存储到一块,将最近可能被访问的数据放在一起。但是这样的话容易导致热点问题,导致一些机器利用率过高而另外一些机器利用率低
-
使用前缀解决热点问题
Salting是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标,比如加上abcd, -
使用hash解决热点问题
使用hash可以保证一个rowkey永远在一台机器上 -
反转rowkey
反转Rowkey的例子通常以手机举例,可以将手机号反转后的字符串作为Rowkey,这样的就避免了以手机号那样比较固定开头(137x、15x等)导致热点问题,缺点是牺牲了Rowkey的有序性
热点问题还有其它解决方式要具体问题具体分析,要结合使用方式来做
⑶rowkey长度问题
越短越好
⑶rowkey查询策略
可以有以什么开始,以什么结尾,以及包含多种查询策略
3.column family
列族,不要再一张表定义太多列族。不超过2-3个。
4.in menmory
可以setinmemory(true)可以给regionserver开启缓冲区。这是服务端缓存。
5.maxversion
设置列族的最大版本。
6.time to live设置表中数据的存储生命期。
7.compact & split
compact minor compact
major compact
hbase为了防止小文件过多,有时候会将小的store file合并成相对较大的。
减少自动裂变可以减少IO,提高效率。在每个区的数据每一个列族一个store
每个表先横着来一刀,分区,然后竖着来一刀,store.
major compact :将分区下某个store下所有storefile合并成一个。各自做各自的合并。会占用大量的资源。
1.通过命令
2.通过api
3.通过配置自动运行
最好由程序员手动去控制。系统默认是24小时会合并一次,这样会影响hbase效率。
minor compact:选取小的storefile,相邻的合并,合并成多个。