五、helm部署 prometheus-operator
- 一、了解Prometheus概念
- 二、认识Prometheus Operator
-
- 1、安装Prometheus软件
-
- 1.1、利用helm3进行安装
- 1.2、发布prometheus和Grafana的svc
- 1.3、卸载方法
- 2、模拟业务监控
-
- 2.1、模拟发布业务pod
- 2.2、添加servicemonitors采集监控指标
- 2.3、可以通过prometheus查看
- 3、配置告警
-
- 3.1、告警模板文件 template.tmpl
- 3.2、config.yaml
- 3.3、创建webhook挂载configmap
- 3.4、配置alertmanager.yaml使用webhook
- 3.5、创建告警
- 3.5、group_wait和repeat_interval讲解
- 3.6、其他相关告警配置参数含义
- 3.7、告警状态含义
- 4、告警模板讲解
-
- 4.1、if/else语句
- 4.2、Range语法
- 4.3、比较语法
- 4.4、逻辑运算
- 4.5、内置函数
- 4.6、移除空格
- 4.7、模板数据结构介绍
- Prometheus是一个用于监控和告警的开源系统。
- 一开始由Soundcloud开发,后来在2016年,它迁移到CNCF并且称为Kubernetes之后最流行的项目之一。从整个Linux服务器到stand-alone web服务器、数据库服务或一个单独的进程,它都能监控。
- 在Prometheus术语中,它所监控的事物称为目标(Target)。每个目标单元被称为指标(metric)。它以设置好的时间间隔通过http抓取目标,以收集指标并将数据放置在其时序数据库(Time Series Database)中。
- 可以使用PromQL查询语言查询相关target的指标。
一、了解Prometheus概念
- 组成Prometheus生态的组件:
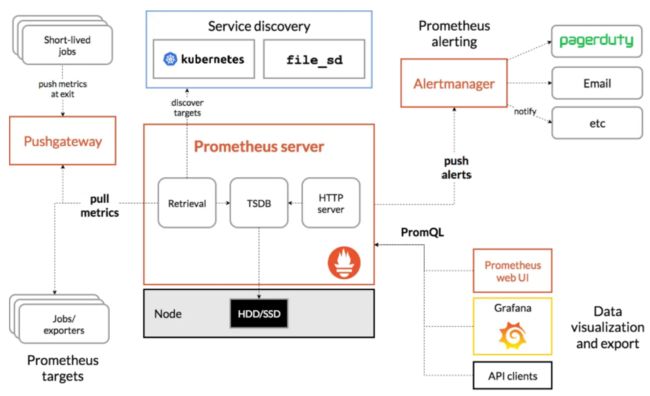
1、 了解prometheus相关术语:
-
Prometheus Server:在时序数据库中抓取和存储指标的主要组件
-
抓取:一种拉取方法以获取指标。它通常以10-60秒的时间间隔抓取。
-
Target:检索数据的server客户端
-
-
服务发现:启用Prometheus,使其能够识别它需要监控的应用程序并在动态环境中拉取指标
-
Alert Manager:负责处理警报的组件(包括silencing、inhibition、聚合告警信息,并通过邮件、PagerDuty、Slack等方式发送告警通知)。
-
数据可视化:抓取的数据存储在本地存储中,并使用PromQL直接查询,或通过Grafana dashboard查看。
二、认识Prometheus Operator
-
根据Prometheus Operator的项目所有者CoreOS称,Prometheus Operator可以配置原生Kubernetes并且可以管理和操作Prometheus和Alertmanager集群。
-
该Operator引入了以下Kubernetes自定义资源定义(CRDs):Prometheus、ServiceMonitor、PrometheusRule和Alertmanager。如果你想了解更多内容可以访问链接
1、安装: stable/prometheus-operator Helm chart来安装Prometheus Operator
下载链接:https://github.com/helm/charts/tree/master/stable/prometheus-operator
- 默认安装程序将会部署以下组件:prometheus-operator、prometheus、alertmanager、node-exporter、kube-state-metrics以及grafana。
- 默认状态下,Prometheus将会抓取Kubernetes的主要组件:kube-apiserver、kube-controller-manager以及etcd。
1、安装Prometheus软件
1.1、利用helm3进行安装
- 查看helm是否安装,这里使用的是helm3(helm2与helm3有很大区别,需要注意)
~]# helm version
version.BuildInfo{Version:"v3.0.0", GitCommit:"e29ce2a54e96cd02ccfce88bee4f58bb6e2a28b6", GitTreeState:"clean", GoVersion:"go1.13.4"}
- 添加helm仓库
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm search repo prometheus-community
- 部署prometheus
如果想要提前自定义配置,可以把chart包下载下来
# helm pull prometheus-community/prometheus-operator(可选)
kubectl create ns monitoring
helm install prometheus-operator --set rbacEnable=true --namespace=monitoring --wait prometheus-community/prometheus-operator
# 或者 helm install prometheus-operator --set rbacEnable=true --namespace=monitoring --wait stable/prometheus-operator
1.2、发布prometheus和Grafana的svc
- 可以通过nodeport或者ingress暴露grafana和prometheus
1、NodePort的方式发布
kubectl -n monitoring patch svc prometheus-operator-grafana -p '{"spec":{"type":"NodePort"}}'
kubectl -n monitoring patch svc prometheus-operator-prometheus -p '{"spec":{"type":"NodePort"}}'
2、ingress的方式发布
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: monitoring
spec:
rules:
- host: grafana.oper.com
http:
paths:
- backend:
serviceName: prometheus-operator-grafana
servicePort: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
spec:
rules:
- host: prometheus.oper.com
http:
paths:
- backend:
serviceName: prometheus-operator-prometheus
servicePort: 9090
- 获取grafana admin用户密码
kubectl -n monitoring get secrets |grep Opaque|grep grafana|awk '{print $1}'|xargs kubectl -n monitoring get secrets -o yaml|grep admin-password|grep -v f:|awk -F "admin-password: " '{print $2}'|base64 -d && echo ''
1.3、卸载方法
1、正常卸载
helm -n monitoring delete prometheus-operator
2、若安装失败,执行下面命令进行清理
kubectl -n monitoring get deployments.apps|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete deployments.apps
kubectl -n monitoring get svc|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete svc
kubectl -n monitoring get sts|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete sts
kubectl -n monitoring get crd|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete crd
kubectl -n monitoring get servicemonitorings.monitoringing.coreos.com|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete servicemonitorings.monitoringing.coreos.com
kubectl -n monitoring get ds|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete ds
kubectl -n monitoring get job|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete job
kubectl -n monitoring get pod|tail -n +2|awk '{print $1}'|xargs kubectl -n monitoring delete pod
kubectl get PodSecurityPolicy|grep prome|awk '{print $1}'|xargs kubectl delete podsecuritypolicies.policy
kubectl get clusterrole|grep prometheus|awk '{print $1}'|xargs kubectl delete clusterrole
kubectl get clusterrolebindings.rbac.authorization.k8s.io|grep prometheus|awk '{print $1}'|xargs kubectl delete clusterrolebindings.rbac.authorization.k8s.io
kubectl -n kube-system get svc|grep prometheus|awk '{print $1}'|xargs kubectl -n kube-system delete svc
kubectl -n kube-system get mutatingwebhookconfigurations.admissionregistration.k8s.io|grep prometheus|awk '{print $1}'|xargs kubectl delete mutatingwebhookconfigurations.admissionregistration.k8s.io
kubectl -n kube-system get validatingwebhookconfigurations.admissionregistration.k8s.io|grep prometheus|awk '{print $1}'|xargs kubectl delete validatingwebhookconfigurations.admissionregistration.k8s.io
kubectl delete ns monitoring
2、模拟业务监控
2.1、模拟发布业务pod
- demo镜像构建参数:https://github.com/hnlq715/nginx-prometheus-metrics,该镜像会提供一个业务metric
- yaml文件如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-demo
labels:
app: nginx-demo
spec:
replicas: 1
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- name: nginx-demo
image: registry.baidubce.com/docker-hub/nginx-prometheus-metrics:latest
ports:
- name: http-metrics
containerPort: 9527
- name: web
containerPort: 80
- name: test
containerPort: 1314
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-demo
name: nginx-demo
namespace: default
spec:
ports:
- name: http-metrics
port: 9527
protocol: TCP
targetPort: 9527
- name: web
port: 80
protocol: TCP
targetPort: 80
- name: test
port: 1314
protocol: TCP
targetPort: 1314
selector:
app: nginx-demo
type: ClusterIP
2.2、添加servicemonitors采集监控指标
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: nginx-demo
release: prometheus-operator
name: nginx-demo
namespace: monitoring
spec:
endpoints:
- interval: 15s
port: http-metrics
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: nginx-demo
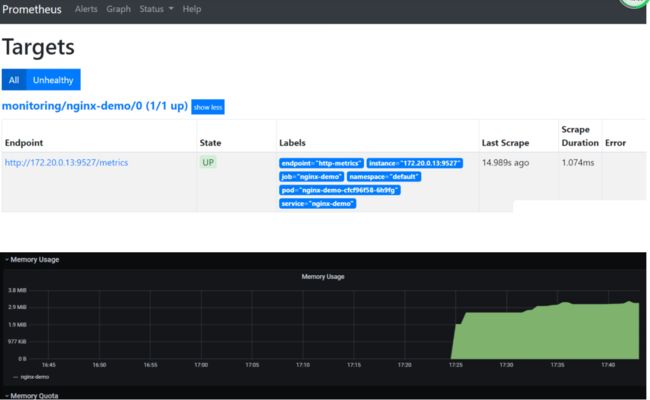
2.3、可以通过prometheus查看
3、配置告警
- 准备template.tmpl和config.yaml的configmap
- 创建webhook挂载上面的configmap
3.1、告警模板文件 template.tmpl
apiVersion: v1
kind: ConfigMap
metadata:
namespace: monitoring
name: dingtalk-webhook-template
data:
template.tmpl: |
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
**Labels**
{{ range .Labels.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Annotations**
{{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Source:** [{{ .GeneratorURL }}]({{ .GeneratorURL }})
{{ end }}{{ end }}
{{ define "default.__text_alert_list" }}{{ range . }}
---
**告警级别:** {{ .Labels.severity | upper }}
**运营团队:** {{ .Labels.team | upper }}
**触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**事件信息:**
{{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**事件标签:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{ define "default.__text_alertresovle_list" }}{{ range . }}
---
**告警级别:** {{ .Labels.severity | upper }}
**运营团队:** {{ .Labels.team | upper }}
**触发时间:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**结束时间:** {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
**事件信息:**
{{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**事件标签:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") (ne (.Name) "team") }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}
{{ end }}
{{/* Default */}}
{{ define "default.title" }}{{ template "__subject" . }}{{ end }}
{{ define "default.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ if gt (len .Alerts.Firing) 0 -}}
**====侦测到故障====**
{{ template "default.__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
{{ template "default.__text_alertresovle_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
{{/* Legacy */}}
{{ define "legacy.title" }}{{ template "__subject" . }}{{ end }}
{{ define "legacy.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{/* Following names for compatibility */}}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
3.2、config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: monitoring
name: dingtalk-webhook-config
data:
config.yml: |
# Request timeout
timeout: 5s
## Customizable templates path
templates:
- /etc/prometheus-webhook-dingtalk/templates/*.tmpl
## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
# default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook-dingtalk:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxx #钉钉webhook地址
message:
title: '{{ template "ding.link.title" . }}'
text: '{{ template "ding.link.content" . }}'
mention:
all: true
mobiles: ['135xxxxxxxx']
3.3、创建webhook挂载configmap
# cat webhook-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: monitoring
name: dingtalk-webhook
labels:
app: dingtalk-webhook
spec:
selector:
matchLabels:
app: dingtalk-webhook
replicas: 1
template:
metadata:
labels:
app: dingtalk-webhook
spec:
containers:
- name: dingtalk-webhook
image: registry.baidubce.com/docker-hub/timonwong/prometheus-webhook-dingtalk:v1.4.0
args:
- --config.file=/etc/prometheus-webhook-dingtalk/config.yml
ports:
- containerPort: 8060
protocol: TCP
volumeMounts:
- name: dingtalk-webhook-confing
mountPath: "/etc/prometheus-webhook-dingtalk"
- name: dingtalk-webhook-template
mountPath: "/etc/prometheus-webhook-dingtalk/templates"
volumes:
- name: dingtalk-webhook-confing
configMap:
name: dingtalk-webhook-config
- name: dingtalk-webhook-template
configMap:
name: dingtalk-webhook-template
---
apiVersion: v1
kind: Service
metadata:
namespace: monitoring
name: dingtalk-webhook
labels:
app: dingtalk-webhook
spec:
selector:
app: dingtalk-webhook
ports:
- name: http
port: 8060
targetPort: 8060
protocol: TCP
3.4、配置alertmanager.yaml使用webhook
- 获取alertmanager.yaml现有配置
kubectl -n monitoring get secrets alertmanager-prometheus-operator-alertmanager -o yaml|grep alertmanager.yaml|grep -v '{}'|awk -F ": " '{print $2}'|base64 -d >>alertmanager.yaml
- 修改alertmanager.yaml
############################ 钉钉告警 ############################
global:
resolve_timeout: 5m
receivers:
- name: dingtalk-webhook
webhook_configs:
- send_resolved: true
url: http://dingtalk-webhook:8060/dingtalk/webhook-dingtalk/send
route:
group_by:
- job
group_interval: 5m
group_wait: 30s
receiver: dingtalk-webhook
repeat_interval: 12h
routes:
- receiver: dingtalk-webhook
group_wait: 10s
############################ 邮件告警配置如下 ########################
cat alertmanager.yaml
global:
resolve_timeout: 5m
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: demo-alert
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- match:
alertname: DemoAlertName
receiver: 'demo-alert'
receivers:
- name: demo-alert
email_configs:
- to: your_email@gmail.com
from: from_email@gmail.com
# Your smtp server address
smarthost: smtp.gmail.com:587
auth_username: from_email@gmail.com
auth_identity: from_email@gmail.com
auth_password: 16letter_generated token # you can use gmail account password, but better create a dedicated token for this
headers:
From: from_email@gmail.com
Subject: 'Demo ALERT'
- 重新部署alertmanager.yaml
kubectl -n monitoring delete secret alertmanager-prometheus-operator-alertmanager
kubectl -n monitoring create secret generic alertmanager-prometheus-operator-alertmanager --from-file=alertmanager.yaml
3.5、创建告警
- 让我们移除所有默认告警并创建一个我们自己的告警:
- 注意:我们只保留一条规则是为了让demo更容易。但是有一条规则,你绝对不能删除,它位于monitoring-demo-prometheus-operator-general.rules.yaml中,被称为看门狗。该告警总是处于触发状态,其目的是确保整个告警流水线正常运转。
# 可以从CLI中检查我们留下的规则并将其与我们将在浏览器中看到的进行比较。
kubectl -n monitoring describe prometheusrule demo-prometheus-operator-alertmanager.rules
########################## 移除默认的告警(也可以不必移除) ##########################
kubectl -n monitoring delete prometheusrules $(kubectl -n monitoring get prometheusrules | grep -v alert)
kubectl -n monitoring get prometheusrules
########################## 创建自己的告警 ##########################
~]# vim demo-nginx-alertmanager.rules
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
generation: 1
labels:
app: prometheus-operator
chart: prometheus-operator-9.3.2
heritage: Helm
release: prometheus-operator
managedFields:
- apiVersion: monitoring.coreos.com/v1
manager: Go-http-client
operation: Update
name: demo-prometheus-operator-alertmanager.rules
spec:
groups:
- name: demo-alertmanager.rules
rules:
- alert: Demo-test
annotations:
message: Alertmanager has found {{ $labels.instance }} with CPU too high
expr: rate (container_cpu_usage_seconds_total{pod=~"nginx-demo.*",image!="", container!="POD"}[1m]) > 0.04
for: 5m
labels:
severity: critical
FAQ: 发布告警规则报错如下
- 参考文档:https://github.com/helm/charts/issues/19928
[root@master prometheusrules]# kubectl apply -f demo-nginx-alertmanager.rules
Error from server (InternalError): error when creating "demo.yaml": Internal error occurred: failed calling webhook "prometheusrulemutate.monitoring.coreos.com": Post https://prometheus-operator-operator.monitoring.svc:443/admission-prometheusrules/mutate?timeout=30s: context deadline exceeded
解决办法:删除资源validatingwebhookconfigurations.admissionregistration.k8s.io和MutatingWebhookConfiguration,并且重新创建你的rules
# 查看这两种资源
[root@master prometheusrules]# kubectl get validatingwebhookconfigurations.admissionregistration.k8s.io
NAME WEBHOOKS AGE
prometheus-operator-admission 1 45m
[root@master prometheusrules]# kubectl get MutatingWebhookConfiguration
NAME WEBHOOKS AGE
prometheus-operator-admission 1 46m
# 删除后 重新发布规则
[root@master prometheusrules]# kubectl delete validatingwebhookconfigurations.admissionregistration.k8s.io prometheus-operator-admission
[root@master prometheusrules]# kubectl delete MutatingWebhookConfiguration prometheus-operator-admission
[root@master prometheusrules]# kubectl apply -f demo-nginx-alertmanager.rules
- 到prometheus Ui页面上查看新的告警规则,可以看到新建的告警规则
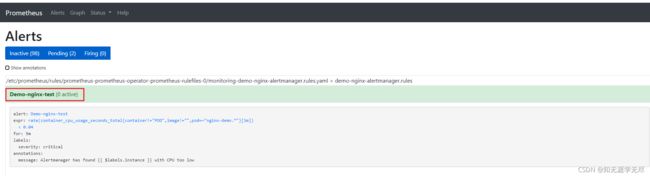
3.5、group_wait和repeat_interval讲解
- 1、告警从prometheus到alertmanger后缓存group_wait时间,聚合同类型不同机器的告警一个邮件发送
- 2、问题没有恢复间隔repeat_interval时间,发送第二次告警
- 3、第一次告警发出后等待group_interval时间,开始为该组触发新告警
- 4、告警解除resolve_timeout,告警问题解除后保持resolve_timeout时间,发送恢复邮件
示例:
cat alertmanager/alertmanager.yml
templates:
- '/usr/local/prometheus/alertmanager/template/default.tmpl'
route:
group_by: ['alertname']
# 告警合并
group_wait: 60s
group_interval: 5m
repeat_interval: 7m
resolve_timeout: 5m
receiver: 'default'
3.6、其他相关告警配置参数含义
- annotation:描述告警的信息标签集。
- expr:由PromQL写的表达式
- for:可选参数,设置了之后会告诉Prometheus在定义的时间段内告警是否处于active状态。仅在此定义时间后才会触发告警。
- label:可以附加到告警的额外标签。
了解更多关于告警的信息:
https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
3.7、告警状态含义
- 告警有3个阶段:
- Inactive:不满足告警触发条件
- Pending:条件已满足
- Firing:触发告警
4、告警模板讲解
- 告警模板是基于go语言的模板来写的,具体可参考官方文档:https://golang.org/pkg/text/template/
- 告警模板的使用类似helm中{{.Values}}这种调用方式
示例1:在模板中定义了变量后,在整个模板中都能使用
{{ $Name := "fei" }}
hello {{ $Name }}
示例2:定义模板,类似helm的_helpers.tpl文件内容
{{ define "this.is.template" }}
{{ if .Name }}
hello {{ .Name }}
{{ else }}
no one!!!
{{ end }}
{{ end }}
4.1、if/else语句
# 示例1
{{ if .Name }}
hello {{ .Name }}
{{ else }}
no one!!!
{{ end }}
# 示例2
{{ if .Name1 }}
hello {{ .Name1 }}
{{ else if .Name2 }}
hello {{ .Name2 }}
{{ else }}
no one
{{ end }}
4.2、Range语法
- 模板里使用range来进行遍历数据,类似于jinja2模板语言中的for
# 假设定义数据结构如下
type Info struct {
Name string
Age int
}
# 然后模板就如下
{{ range .Info }}
name: {{ .Name }}
age: {{ .Age }}
{{ end }}
4.3、比较语法
- eq 等于
- ne 不等于
- lt 小于
- le 小于等于
- gt 大于
- ge 大于等于
{{ if gt .Number1 .Number2 }}
{{ .Number1 }}大于{{ .Number2 }}
{{ end }}
4.4、逻辑运算
- and 全都满足,返回true
- not 取反
- or 有一个为true,即可返回true
{{ if and .Username .Passwd }}
begin login
{{ if gt (len .Passwd) 16 }}
passwd valid
{{ end }}
{{ else }}
login faild
{{ end }}
{{ if not .Authenticated }}
access deny
{{ end }}
4.5、内置函数
title: 将字符串转换为首字母大写toUpper: 所有字母转换成大写toLower: 所有字母转换成小写join: 拼接字符串safeHtml: 将字符串标记为不需要自动转义的htmllen: 获取长度
{{ "abcd" | toUpper }}
{{ "ABCD" | toLower }}
{{ .Values | join "," }}
4.6、移除空格
- 使用
-减号来做处理,移除空格
{{- }} #去掉左边的空格
{{ -}} #去掉右边的空格
{{- -}} #去掉两边所有的空格
4.7、模板数据结构介绍
.Receiver: 接收器的名称
.Status: 如果正在告警,值为firing,恢复为resolved
.Alerts: 所有告警对象的列表,是一个列表,
.Alerts.Firing: 告警列表
.Alerts.Resolved: 恢复列表
.GroupLabels: 告警的分组标签
.CommonLabels: 所有告警共有的标签
.CommonAnnotations: 所有告警共有的注解
.ExternalURL: 告警对应的alertmanager连接地址
- 具体可以看下报警出来的信息:
{
'receiver': 'webhook',
'status': 'firing',
'alerts': [{
'status': 'firing',
'labels': {
'alertname': '内存使用率',
'instance': '10.127.92.100',
'job': 'sentry',
'severity': 'warning',
'team': 'ops'
},
'annotations': {
'description': '内存使用率已超过55%,内存使用率:58%',
'summary': '内存使用率'
},
'startsAt': '2020-12-30T07:20:08.775177336Z',
'endsAt': '0001-01-01T00:00:00Z',
'generatorURL': 'http://prometheus-server:9090/graph?g0.expr=round%28%281+-+%28node_memory_MemAvailable_bytes%7Bjob%3D%22sentry%22%7D+%2F+%28node_memory_MemTotal_bytes%7Bjob%3D%22sentry%22%7D%29%29%29+%2A+100%29+%3E+55&g0.tab=1',
'fingerprint': '09f94bd1aa7da54f'
}],
'groupLabels': {
'alertname': '内存使用率'
},
'commonLabels': {
'alertname': '内存使用率',
'job': 'sentry',
'severity': 'warning',
'team': 'ops'
},
'commonAnnotations': {
'summary': '内存使用率'
},
'externalURL': 'http://alertmanager-server:9093',
'version': '4',
'groupKey': '{}:{alertname="内存使用率"}',
'truncatedAlerts': 0
}
模板示例:
- 官方模板参考:https://raw.githubusercontent.com/prometheus/alertmanager/master/template/default.tmpl
# ==注意:== 需要特别说明下告警信息里的时间是utc时间,需要转换为北京时间,也就是在utc时间的基础上加8小时,也就是28800秒,也就是这里写的28800e9
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}} // 判断报警列表的长度是否大于0,大于0说明有报警,否则没有
{{- range $index, $alert := .Alerts -}} // 遍历所有的告警列表,$index是索引,$alert是每一个报警元素
==========异常告警==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} // 调整为北京时间
{{- if gt (len $alert.Labels.instance) 0 }} // 判断下是否存在instance
实例信息: {{ $alert.Labels.instance }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}} // 判断恢复列表长度是否大于0,大于0说明有恢复信息,否则没有
{{- range $index, $alert := .Alerts -}} //遍历恢复列表
==========异常恢复==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} #调整为北京时间
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} #调整为北京时间
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- end }}
定义的接受者示例:其中wechat.default.message就是上面define的模板名称
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '接收告警的部门ID'
agent_id: '应用ID'
to_user: '用户ID'
api_secret: '部门secret'
参考文章:https://www.cnblogs.com/rancherlabs/p/12558140.html