推荐系统笔记(五):lightGCN算法原理与背景
背景
lightGCN是将图卷积神经网络应用于推荐系统当中,是对神经图协同过滤(NGCF)算法的优化和改进。lightGCN相比于其对照算法提升了16%左右,在介绍lightGCN之前应该知道NGCF的基本原理。
基本原理
首先,协同过滤的基本假设是相似的用户会对物品展现出相似的偏好,自从全面进入深度学习领域之后,一般主要是先在隐空间中学习关于user和item的embedding,然后重建两者的交互即interaction modeling,如MF做内积,NCF模拟高阶交互等。但是他们并没有把user和item的交互信息本身编码进 embedding 中,这就是NGCF想解决的点:显式建模User-Item 之间的高阶连接性来提升 embedding。
NGCF
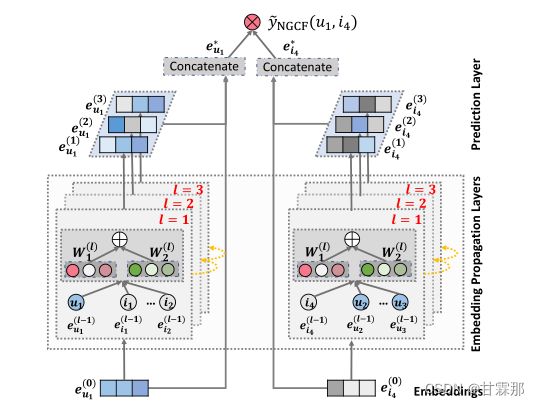
NGCF的模型如上图所示,它的传播过程分为message construction(消息构造)和message aggregation(消息聚合)两部分。按照图中的结构图可以进行分以下三层:
· Embeddings:对user和item的嵌入向量,用id来嵌入就可以了
· Embedding Propagation Layers:挖掘高阶连通性关系来捕捉交互以细化Embedding的多个嵌入传播层
· Prediction Layer:用更新之后带有交互信息的 user 和 item Embedding来进行预测
1. Embedding
即编码层,构建一个参数矩阵作为嵌入查找表:

2. Embedding Propagation Layers(核心部分)
信息构造:
对于连接的用户项对(u,i),论文将从i到u的消息定义为:
![]()
其中![]() 是消息嵌入(即要传播的信息)。
是消息嵌入(即要传播的信息)。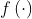 是消息编码函数,它以嵌入
是消息编码函数,它以嵌入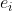 和
和 为输入,并使用系数
为输入,并使用系数![]() 来控制边缘(u,i)上每次传播的衰减因子。具体的函数如下所示:
来控制边缘(u,i)上每次传播的衰减因子。具体的函数如下所示:
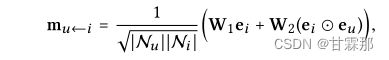
![]() 表示物品到用户的消息构造。其中W1和W2是用于提取传播有用信息的可训练权重矩阵,嵌入和表示用户和物品的embedding,用和内积相乘来获得邻域的的信息,然后再加上,即所谓的自信息(这在lightGCN中被证明是不必要的冗余)。最后的N是u和i的度用来归一化系数,可以看做是折扣系数,在lightGCN论文中被证明是不可缺少的。
表示物品到用户的消息构造。其中W1和W2是用于提取传播有用信息的可训练权重矩阵,嵌入和表示用户和物品的embedding,用和内积相乘来获得邻域的的信息,然后再加上,即所谓的自信息(这在lightGCN中被证明是不必要的冗余)。最后的N是u和i的度用来归一化系数,可以看做是折扣系数,在lightGCN论文中被证明是不可缺少的。
信息聚合:
一阶聚合:整合从每个item的聚合信息,然后再加上用户自身节点的信息,最后再激活一下
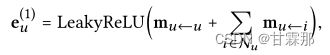
高阶聚合:一阶往往不能满足要求,因此需要堆叠多层。
通过一阶连通性建模增强表示,我们可以堆叠更多嵌入传播层来探索高阶连通性信息。这种高阶连接性对于编码协作信号以估计用户和项目之间的相关性分数至关重要。
通过堆叠l嵌入传播层,用户(和项目)能够接收从其l跳邻居传播的消息。如图所示,用户u的表示递归公式化为:
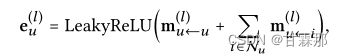
自信息和用户与物品的交互信息表示为:
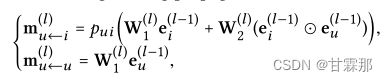
该公式的理解为,每次传播时,聚合邻接结点信息时,邻接结点都是上次聚合更新后的结点信息(一定不是初始的embedding,结点信息每次更新都会发生变化的)
高阶的消息堆叠如图所示:
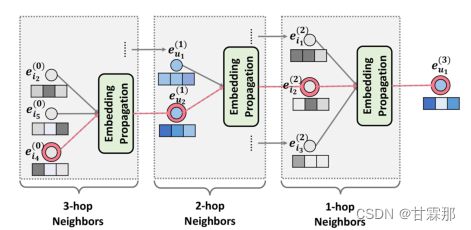
首先就是将i4、i5、i2三个物品的信息聚合到u2中,(其实在这个聚合过程进行的同时其他结点也都进行了相应的聚合邻接结点信息,例如在此时u1也聚合了i1、i2、i3的信息),然后用u1和u2继续传播聚合给i2(此时i2结点在此时已经包含图三所有结点的信息),然后再将i1、i2、i3信息给u1。至此物品i4经过三层转手操作,通过路径上的结点一步步传递到u1手中。
为了便利与计算,其矩阵形式表示如下:
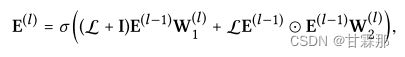
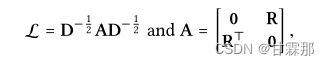
A是邻接矩阵,L就是归一化后的邻接矩阵,将得到的所有阶的embedding信息拼接起来起来作为最终的节点表示,再内积得到预测结果:

至于为什么矩阵表示是这样作者并未介绍,也无从考证,后续可以进一步研究。
损失函数如图:
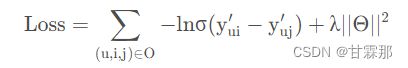
是比较常规的成对计算损失的损失函数。
3. Prediction Layer
预测部份较为简单,直接将用户的最终编码和物品表示的最终编码相乘得到用户评分矩阵类似的排序。即如图:
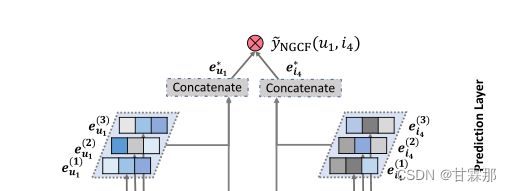
这里编码的到的方式和lightGCN的方式有所不同,以后会介绍到。
代码实现参考以下链接:github:https://github.com/huangtinglin/NGCF-PyTorch
LightGCN
和NGCF的不同点在于:lightGCN将GCN中最常见的两种设计:特征转换和非线性激活弃用,因为他们对模型并无实质性作用,另外LightGCN认为自信息的作用不大,也没有使用自信息链接。
论文链接:
- LightGCN: https://arxiv.org/abs/2002.02126
- BPR: https://arxiv.org/ftp/arxiv/papers/1205/1205.2618.pdf
整体模型示意图如图所示:
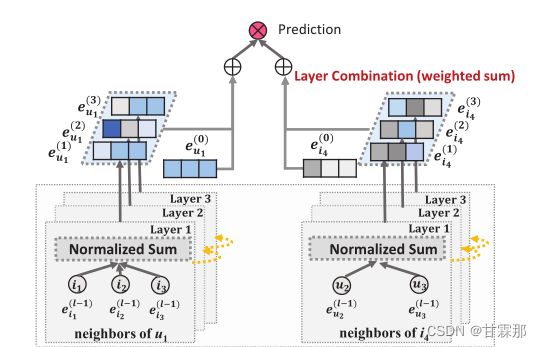
GCN的基本思想是通过平滑图上的特征来学习节点的表示。为此,它迭代执行图卷积,即聚合邻居的特征作为目标节点的新表示。这种邻域聚合同样可以抽象为:
![]()
可见公式中没有再使用自信息链接,作者通过消融实验证明了自信息的多余。
迭代公式如下所示,通过迭代和最后加权求和的方式求取最后对用户和物品的编码并预测:

也就是说在堆叠多层图卷积神经网络时,最后的编码是每一层的编码都会参与,按照权重进行求和的,作者提出可以通过注意力机制进行学习该权重,但事实上使用平均权重的效果就会很好,利用注意力机制不一定能取得更好的效果还会加重模型负担。于是加权公式如下:
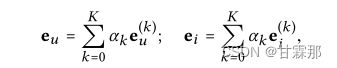
预测部分和NGCF方式基本一样,直接将用户的最终编码和物品表示的最终编码相乘得到用户评分矩阵类似的排序。
![]()
矩阵表示也和NGCF的方式基本相同:
![]()
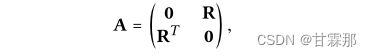
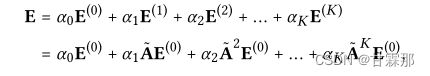
其中D是(M+N)×(M+N)对角矩阵,其中每个条目Dii表示邻接矩阵a(也称为度矩阵)的第i行向量中非零条目的数量。
模型在损失函数上做了一定处理,使用了BPR loss损失函数,有关这个损失函数的部分请参考我的另一篇博客:推荐系统笔记(一):BPR Loss个性化推荐_甘霖那的博客-CSDN博客

BPR loss对排序方法进行了改进,可以改进模型的收敛速度和效果。
总结
LightGCN通过消融实验证明了非线性激活和特征转换这些GCN的结构在推荐系统中并不适用,这很可能是因为推荐系统中每个图节点仅仅使用了用户或者物品的ID进行模型搭建和训练,因此节点信息并不像图片信息那么丰富,也就不需要那么复杂的结构了。消融实验结果如图 :
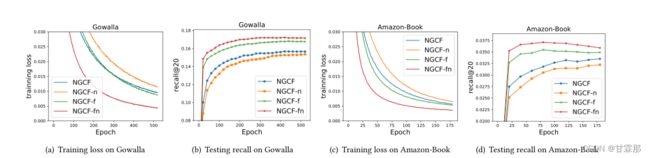
分别对比了以下几种消融实验的结果:
•NGCF-f,删除特征转换矩阵W1和W2。
•NGCF-n,去除非线性激活函数σ。
•NGCF fn,去除特征转换矩阵和非线性激活函数。
结果显示NGCF fn的结果要比NGCF的结果更加优秀,提升16%,可以认为该两种结构确实不是必须的。
论文实现的pytorch代码链接如下:
GitHub - gusye1234/LightGCN-PyTorch: The PyTorch implementation of LightGCN
tensorflow的实现代码如下:
GitHub - kuandeng/LightGCN
下一篇笔记将介绍复现论文的步骤和过程!
参考链接:图卷积网络在推荐系统中的应用NGCF(Neural Graph Collaborative Filtering)配套pytorch的代码解释_只想做个咸鱼的博客-CSDN博客_ngcf代码