大数据任务调度器 —— Azkaban 3.0 进阶应用
文章目录
-
-
-
- 任务依赖
- 任务重试
- JavaProcess 进程任务提交
- 条件执行
-
- 自定义条件
- 预定义条件
- 定时执行
- 邮件警告
-
-
前言:Azkaban 搭建以及基础介绍,查看这篇博客 —— 大数据任务调度器 —— Azkaban 3.0 部署与简单应用
任务依赖
Azkaban 中的任务依赖设置十分简单,通过 dependsOn 参数完成,如下所示:
nodes:
- name: taskA
type: command
config:
command: echo "This is taskA!"
- name: taskB
type: command
config:
command: echo "This is taskB!"
- name: taskC
type: command
config:
command: echo "This is taskC!"
dependsOn:
- taskA
- taskB
如上示例中,taskC 任务依赖于 taskA 与 taskB,需要注意 dependsOn 参数的值为数组。
执行后如下所示:

任务重试
假设我们当前的任务执行失败了,如下场景:

我们可以点击右上角的 Prepare Execution 按钮进行手动重试。

在手动重试时,我们可以选择直接进行重试,也可以选择跳过某些任务进行重试,右击需要跳过重试的任务,选择 Disable,那么在重试时该任务将不会执行。
在 Azkaban 中还有自动重试,在 flow 文件中进行配置,如下所示:
nodes:
- name: test
type: command
config:
command: bash /test.sh
retries: 2
retry.backoff: 5000
其中 retries 表示重试的次数,retry.backoff 表示重试的时间间隔,单位是 ms 毫秒,注意缩进格式。
JavaProcess 进程任务提交
在 Azkaban 中,有两种任务类型,除了我们上面用的 command 命令行类型之外,还有 javaprocess 类型,用于提交 jar 包,其配置参数如下:
-
Xms:堆内存的初始大小,默认为物理内存的
1/64。 -
Xmx:堆内存的最大大小,默认为物理内存的
1/4~1/2。 -
classpath:类路径,默认和提交的flow文件在同一目录下。 -
java.class:要运行的 Java 对象,其中必须包含main方法 -
main.args:main方法的参数,多个参数用空格间隔。
我当前编写了如下 Java 程序用于测试。
public class hello_world {
public static void main(String[] args) {
String name = args[0];
String age = args[1];
System.out.printf("我叫%s\n今年%s岁了",name,age);
}
}
然后将该程序打成 jar 包,提交 Azkaban 进行运行。
编写 flow 配置文件:
nodes:
- name: test
type: javaprocess
config:
Xms: 64M
Xmx: 264M
java.class: hello_world
main.args: 张三 20
其余都用默认参数,和 jar 一起打入压缩包中,创建项目,进行提交。

执行完成后,日志结果如下所示:

条件执行
在 Azkaban 中实现条件流程控制功能,分为自定义条件和预定义条件。
自定义条件
使用 condition 配置项来指定设置的条件,通常会配合运行参数一起使用。
运行参数是 Azkaban 允许用户在同一个工作流中定义的环境变量,将其写入到 JOB_OUTPUT_PROP_FILE 文件中,提供给其它 Job 进行使用。例如:在 JobA 中定义的变量,能够在 JobB 中进行读取并使用。
假设我们当前要实现 JobA,JobB。其中 JobB 依赖于JobA ,且 JobB 必须在周日执行。
那么,根据需求,配置了如下 flow 文件:
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: echo "Today is happy day!"
dependsOn:
- JobA
# 判断是否为周日
condition: ${JobA:week} == 7
在 JobA 中执行的 JobA.sh 脚本文件内容如下:
echo "Today is happy day!"
# 获取周几
week=`date +%w`
# 以 JSON 格式写入 Azkaban 环境变量
echo "{\"week\":$week}" > $JOB_OUTPUT_PROP_FILE
将版本文件 azkaban.project、test.flow、JobA.sh 文件压缩到同一个包中,创建项目并提交运行。
在任务流程预览的界面,有一个 condition 标识,表示在执行 JobB 之前需要先进行条件判断。

执行完成后,显示如下:

我们再来看 flow 文件的执行日志:
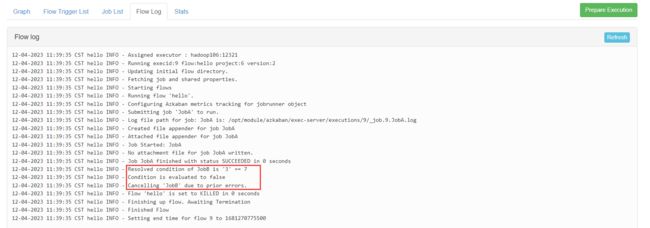
由于笔者今天是周三,所以经过条件判断后 JobB 被取消执行了。
预定义条件
通俗来说就是系统内置的一些条件,可以直接在 condition 配置项中进行使用。
一共有五个,如下所示:
-
all_success: 表示父 Job 全部成功才执行(默认) -
all_done:表示父 Job 全部完成才执行 -
all_failed:表示父 Job 全部失败才执行 -
one_success:表示父 Job 至少一个成功才执行 -
one_failed:表示父 Job 至少一个失败才执行
这里就随便测试一个,我这里选择 all_done,父 Job 全部完成才执行。
配置了如下 flow 文件:
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: sh JobB.sh
- name: JobC
type: command
config:
command: echo "Today is happy day!"
dependsOn:
- JobA
- JobB
condition: all_done
flow 解析: JobC 依赖于 JobA 与 JobB,且添加了一个预定义条件,当父 Job 全部完成后才执行。
那么我们将版本文件 azkaban.project、test.flow 文件压缩到同一个包中,不放 JobA.sh 和 JobB.sh 文件,让其运行失败。创建项目并提交运行。
运行预览图如下所示:

提交运行后,结果预览如下:
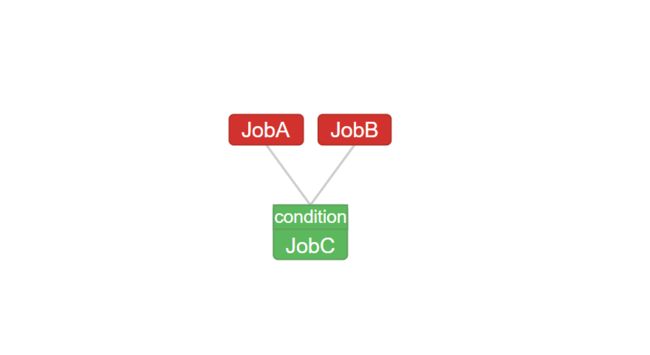
因为没有放入 JobA.sh 和 JobB.sh 文件,所以 JobA 和 JobB 固然会运行失败,那么 JobC 为什么会执行呢?
是因为我在 JobC 中添加了 all_done 的预定义条件,无论父 Job 执行的结果是否成功,只要父 Job 完成了就会执行。
这就是预定义条件中的一个,其它的可以根据其特性,自己去试试。
定时执行
在执行任务的时候,点击 Schedule 进入定时设置界面。

设置定时。

接下来 10 次执行该任务的时间点预览。

我这里设置了每分钟执行一次,效果如下所示:

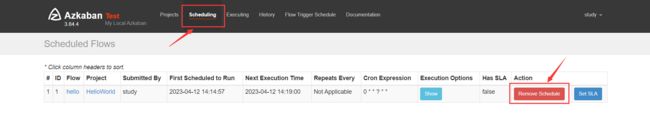
移除定时任务:
邮件警告
配置管理员邮件,我这里用的是网易 163 邮箱,进入邮箱设置,开启 SMTP 服务。
(这里贴不了图,会违规。)
开启后会有一个授权码,复制记录下来,用于第三方客户端登录,下面配置要用。
然后我们进入 Azkaban 的 web-server 安装目录下,配置管理员邮箱账号。
cd /opt/module/azkaban/web-server/conf
# 编辑 azkaban.properties 配置文件
vim azkaban.properties
找到邮件设置:
其中 mail.sender 设置发送邮件的账号,mail.host 设置邮件服务器。
不同的邮箱邮件发送的服务器不同,这个可以自行百度,我用的 163 邮箱是 smtp.163.com。
除了这两项之外,还需要添加两项:
-
mail.user:登录的账号 -
mail.password:授权码
配置完成后如下所示:

保存并退出,然后重启 Azkaban 的 web 服务。
# Azkaban 的 web 服务安装路径
cd /opt/module/azkaban/web-server/
# 重启服务
bin/shutdown-web.sh
bin/start-web.sh
我们刷新 Azkaban 的 WEB 界面,重新登录,随便跑一个 Job,设置邮件警告。

等待任务执行完成后,就会在对应邮箱收到邮件。
