计算广告(十三)
Wide & Deep
Wide & Deep模型是一种结合了广度学习(wide learning)和深度学习(deep learning)方法的混合模型。它旨在解决推荐系统中的记忆(memorization)和泛化(generalization)问题。Wide & Deep模型由Google Research于2016年提出,并成功地应用于Google Play应用商店的推荐系统中。该模型旨在同时捕捉低阶特征交互(通过wide部分)和高阶特征交互(通过deep部分),从而充分利用大规模稀疏数据,实现准确且多样的推荐。
Wide部分: Wide部分主要用于捕捉不同特征之间的交互。它通常使用线性模型,如线性回归(Linear Regression)或逻辑回归(Logistic Regression),并采用大量的特征交叉组合。这些特征交叉组合有助于模型更好地理解特征之间的复杂关系。Wide部分的主要优势在于它可以很好地处理高维稀疏数据,并且具有很好的记忆能力,可以找到频繁出现的特征组合。
Deep部分: Deep部分主要用于捕捉特征之间的高阶关系和非线性关系。它通常使用深度神经网络(Deep Neural Networks,DNN),包括多个隐藏层。每个隐藏层的神经元都可以学习输入特征的不同抽象表示。Deep部分的主要优势在于它可以学习到数据中的高阶特征和泛化能力,这有助于预测不常出现的特征组合。
结合Wide和Deep部分: Wide & Deep模型将Wide部分和Deep部分的输出结合在一起,使用一个输出层(通常是sigmoid激活函数)进行最终预测。结合两者的优点使得Wide & Deep模型既能够处理稀疏高维数据,也能捕捉特征之间的复杂关系。这使得模型在推荐系统中表现尤为出色,可以在保证泛化性能的同时,捕获高频和低频特征组合。
应用场景: Wide & Deep模型主要应用于推荐系统,特别是那些需要处理大量高维稀疏数据的场景。例如,电影推荐、新闻推荐和电商推荐等领域。通过Wide & Deep模型,可以有效地平衡用户兴趣的多样性和推荐内容的准确性。
Wide & Deep模型在实际应用中有很多优点,下面列举了一些主要的优点:
记忆与泛化的平衡: Wide & Deep模型通过结合线性模型(Wide部分)和深度神经网络(Deep部分)实现了对记忆和泛化的平衡。Wide部分能够很好地捕捉频繁出现的特征组合,具有很强的记忆能力。而Deep部分则能够学习到数据中的高阶特征和泛化能力,有助于预测不常出现的特征组合。这种平衡使得Wide & Deep模型能够在推荐系统中实现高精度和多样性。
高维稀疏数据处理能力: Wide & Deep模型特别适合处理高维稀疏数据,如推荐系统中的用户和物品特征。通过特征交叉和深度神经网络,模型可以学习到特征之间的复杂关系,提高预测准确性。
端到端训练: Wide & Deep模型可以进行端到端的训练,即直接从输入特征到输出预测的整个过程都可以进行优化。这使得模型可以根据实际任务自动学习到最有用的特征表示,提高预测性能。
可解释性:尽管深度神经 部分的可解释性有限,但Wide部分的线性模型具有较好的可解释性。通过分析Wide部分的权重和特征交叉,可以了解不同特征之间的关系以及它们对最终预测的影响。
灵活性: Wide & Deep模型具有很高的灵活性,可以根据实际应用场景对Wide部分和Deep部分进行调整。例如,可以调整特征交叉的复杂程度或深度神经网络的层数,以满足不同的性能和计算资源需求。
Wide & Deep模型通过结合广度学习和深度学习方法,在推荐系统领域取得了显著的成功。该模型在处理高维稀疏数据、泛化能力和记忆能力方面具有优势,已经被广泛应用于电影推荐、新闻推荐和电商推荐等场景。
下面我们将详细介绍这两部分的数学推导。
Wide部分(线性模型):
Wide部分使用线性模型来捕捉特征之间的低阶交互。给定输入特征向量x,线性模型的输出可以表示为:
y_wide = w_0 + ∑[ w_i * x_i ] + ∑[ w_ij * x_i * x_j ]
其中,y_wide是wide部分的输出,w_0是偏置项,w_i是第i个特征的权重,x_i是第i个特征的值,w_ij是第i个特征和第j个特征交叉项的权重,x_i和x_j分别是第i个特征和第j个特征的值。在实际应用中,我们通常使用L1正则化(Lasso)来约束模型的复杂度,避免过拟合。
Deep部分(深度神经网络):
Deep部分使用深度神经网络(DNN)来捕捉特征之间的高阶交互。模型的输入通常是将原始特征通过embedding层转换为密集向量,然后将这些向量输入DNN。给定输入特征向量x,DNN的输出可以表示为:
y_deep = DNN(x_embed)
其中,y_deep是deep部分的输出,x_embed是经过embedding层转换后的输入特征向量,DNN()是深度神经网络函数。
y_deep = f_L(…f_2(f_1(x, W_1), W_2)…, W_L)
其中,f_l表示第l层的激活函数(如ReLU),W_l表示第l层的权重矩阵,L表示神经网络的层数。
Wide & Deep模型的组合:
将Wide部分和Deep部分组合起来,我们可以得到Wide & Deep模型的输出:
y = σ(w_wide * y_wide + w_deep * y_deep)
其中,σ表示激活函数(如sigmoid),w_wide和w_deep分别表示Wide部分和Deep部分的权重。在二分类问题中,我们可以将输出y解释为正类的概率。对于多分类问题,可以将激活函数σ替换为softmax,以获得每个类别的概率。
目标函数:
对于二分类问题,通常使用对数损失函数:
L(y, ŷ) = -∑[ y * log(ŷ) + (1 - y) * log(1 - ŷ) ]
其中,L(y, ŷ)是损失函数,y是真实值(0或1),ŷ是模型的预测值(点击概率)。
Wide & Deep模型的目标是最小化损失函数(如交叉熵损失)。给定训练样本(x_i, y_i),我们可以计算模型的损失:
L = ∑l(y_i * log(y_i_hat) + (1 - y_i) * log(1 - y_i_hat))
其中,y_i_hat表示模型的预测值,l表示正则化项(如L1或L2正则化)。
通过最小化损失函数,可以优化模型参数,我们可以使用随机梯度下降(SGD)或其他优化算法(如Adam)来最小化损失函数或其他优化算法来学习模型的参数(如wide部分的权重和deep部分的权重、偏置项等。)
总之,Wide & Deep模型通过组合线性模型(Wide部分)和深度神经网络(Deep部分)来实现对低阶和高阶特征交互的捕捉。通过最小化损失函数,模型可以学习到适当的权重,从而实现准确的预测。
在实际应用过程中也需要注意一些挑战和潜在的局限性:
特征工程的挑战: Wide部分依赖于特征交叉来捕捉特征之间的关系,这需要对特征进行大量的预处理和特征工程。合适的特征交叉对于提高模型性能至关重要,但寻找合适的特征交叉通常需要大量的领域知识和实验。此外,特征工程的复杂性可能导致模型的维度迅速增加,这可能会影响模型的训练速度和性能。
计算资源需求:尽管Wide & Deep模型可以处理高维稀疏数据,但深度神经网络部分可能需要大量的计算资源。随着神经网络层数的增加,模型的参数数量会急剧增加,这会导致训练和推理过程的计算复杂度上升。因此,在实际应用中可能需要权衡模型性能和计算资源需求。
超参数调优: Wide & Deep模型涉及许多超参数,如特征交叉的数量、神经网络层数和神经元数量等。这些超参数对模型性能有很大影响,但寻找合适的超参数组合通常需要大量的实验和调优。虽然可以通过自动调参方法(如贝叶斯优化和网格搜索)来简化调参过程,但这仍然需要消耗大量的计算资源和时间。
冷启动问题:与其他推荐系统模型一样,Wide & Deep模型也受到冷启动问题的影响。当系统面临全新的用户或物品时,模型可能无法获得足够的信息来进行准确的预测。为解决这一问题,可能需要结合其他技术(如基于内容的推荐或协同过滤)来提高冷启动时的推荐性能。
相关模型
DeepFM(Deep Factorization Machines): DeepFM模型结合了因子分解机(FM)和深度神经网络。FM部分用于捕捉低阶特征交互,而深度神经网络部分用于捕捉高阶特征交互。与Wide & Deep模型相比,DeepFM在特征交叉上具有更高的灵活性,能够自动学习有效的特征交叉组合。
NFM(Neural Factorization Machines): NFM模型将神经网络引入因子分解机,使得模型可以学习到更加复杂的特征交互。NFM采用了一种叫做Bi-Interaction Pooling的技术,可以自动发现高阶特征交互,同时保持计算效率。
xDeepFM(eXtreme Deep Factorization Machines): xDeepFM模型结合了DeepFM和Wide & Deep模型的优点,通过引入一种新的网络结构——Compressed Interaction Network(CIN),用于自动学习高阶特征交互。CIN结构可以有效地发现高阶特征交互,同时保持较低的计算复杂度。
AutoInt(Automatically Learning Feature Interactions): AutoInt模型采用了自注意力(Self-Attention)机制来自动发现特征交互。自注意力机制可以在不同特征之间建立关联,从而实现自动特征交叉。AutoInt模型旨在克服手动特征交叉的局限性,提高特征交互的学习效率。
这些模型都在各自的方式上尝试结合不同的学习策略,以实现更好的记忆和泛化能力。虽然这些模型在某些方面可能优于Wide & Deep模型,但在实际应用中,选择合适的模型需要根据具体问题和数据特征进行权衡。
以下是一些在推荐系统领域的其他相关研究方向:
强化学习在推荐系统中的应用:强化学习(Reinforcement Learning,RL)是一种学习方法,通过与环境的交互来学习最优策略。在推荐系统中,强化学习可以用来建立用户与推荐物品之间的动态交互,实现更个性化和长期有效的推荐。例如,强化学习可以用于序列推荐,通过学习用户的历史行为来推荐可能感兴趣的物品。
图神经网络在推荐系统中的应用:图神经网络(Graph Neural Networks,GNN)是一种基于图结构的深度学习方法,用于处理图数据。在推荐系统中,用户和物品之间的关系可以表示为图结构,GNN可以用来学习用户和物品之间的潜在关系,从而提高推荐的准确性。例如,GNN可以用于社交网络推荐,通过分析用户的社交关系来推荐可能感兴趣的物品。
生成模型在推荐系统中的应用:生成模型(Generative Models)是一种深度学习方法,可以学习数据的潜在分布。在推荐系统中,生成模型可以用于生成用户和物品的潜在表示,进一步提高推荐的准确性。例如,变分自编码器(Variational Autoencoder,VAE)和生成对抗网络(Generative Adversarial Networks,GAN)等生成模型可以应用于协同过滤和基于内容的推荐。
上下文感知推荐系统:上下文感知推荐系统考虑了上下文信息,如用户的地理位置、时间和设备等,以提高推荐的准确性和多样性。这种推荐系统可以更好地捕捉用户在不同上下文下的兴趣变化,从而实现更个性化的推荐。
多模态推荐系统:多模态推荐系统利用来自不同来源和类型的数据(如文本、图像、音频和视频等),以提高推荐的准确性和多样性。通过融合多模态信息,推荐系统可以更全面地理解用户和物品的属性,从而实现更精准的推荐。
这是一篇具有划时代意义的论文,于2016年由Google工程师向业界公布,介绍了一套个性化推荐的系统框架。目前,该框架已被广泛应用于搜索、推荐、广告等排序系统中。与传统搜索类似,推荐系统面临的一个挑战是如何在保证推荐结果准确性的同时,实现扩展性。精准推荐的内容可能使用户兴趣收敛,缺乏新鲜感,不利于长期留存;而泛化的推荐可能无法满足用户的具体兴趣,导致用户流失。相较于推荐准确性,扩展性更倾向于改善推荐系统的多样性。
论文仅有4页,思路简洁明了。作者设计了一种融合浅层(wide)模型和深层(deep)模型进行联合训练的框架,充分利用浅层模型的记忆能力和深层模型的泛化能力,实现单一模型在推荐系统准确性和扩展性方面的平衡。对于提出的W&D模型,论文从推荐效果和服务性能两方面进行了评价:
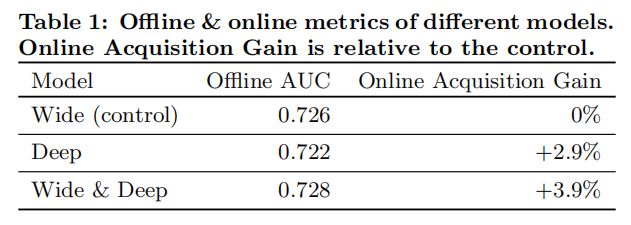
在推荐效果方面,通过在Google Play上进行线上A/B实验,W&D模型与经过高度优化的Wide浅层模型相比,app下载率提高了3.9%。与deep模型相比,也取得了一定程度的提升。
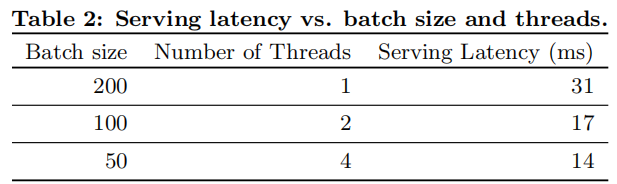
在服务性能方面,通过将一次请求需要处理的app的批量大小切分为更小的尺寸,并利用多线程并行请求,实现了处理效率的提高。单次响应耗时从31毫秒降低到了14毫秒。
正如我们在之前的文章中所提到的,广告系统实际上可以被看作是一种搜索排序系统。它以用户信息和用户浏览的上下文信息为输入,返回一个经过排序的序列。
正是基于这个原因,广告系统面临着与搜索排序系统相似的挑战:权衡记忆性和泛化性。记忆性可以简单地理解为对商品或特征间成对出现的学习。由于用户历史行为特征具有很强的相关性,记忆性可以带来更好的效果。然而,这也会带来一些问题,最典型的就是模型泛化能力不足。
泛化能力的主要来源是特征之间的相关性和传递性。可能特征A与特征B直接与label相关,或者特征A与特征B相关,特征B与label相关,这种现象称为传递性。通过利用特征间的传递性,我们可以探索历史数据中很少出现的特征组合,从而获得较强的泛化能力。
在大规模的在线推荐广告排序系统中,如LR(逻辑回归)等线性模型被广泛应用,因为它们简单、易扩展、性能优越且具有良好的可解释性。这些模型通常使用one-hot这样的二进制数据进行训练。例如,如果用户安装了Netflix,那么"user_installed_app=Netflix"这个特征值为1,否则为0。因此,一些二阶特征的可解释性非常强。
例如,如果用户还浏览了Pandora,那么"user_installed_app=Netflix,impression_app=Pandora"这个组合特征值为1。组合特征的权重实际上就反映了这两者之间的相关性。然而,这种特征需要大量的人工操作,而且由于样本稀疏性,对于那些在训练数据中未出现过的组合,模型将无法学习到它们的权重。
但是这个问题可以被基于embedding的模型解决,比如之前介绍过的FM模型,或者是深度神经网络。它可以通过训练出低维度下的embedding,用embedding向量去计算得到交叉特征的权重。然而如果特征非常稀疏的话,我们也很难保证生成的embedding的效果。在某些特殊情况下,如用户偏好明显或商品比较小众的场景,基于embedding的模型可能会导致过拟合和推荐效果不佳。这些用户-商品组合中的行为数据非常稀疏,即用户很少或从未与这些商品产生过互动。
在这种情况下,由于数据稀疏,embedding向量可能无法很好地表示这些特征组合,因此算出的权重可能不准确。权重大于0意味着这个用户-商品组合被认为具有一定的相关性,但实际上可能并没有相关性。这就可能导致过拟合现象,使得推荐结果不准确。
而线性模型在这种特殊情况下可能会表现得更好,因为它更容易拟合稀疏数据,并具有较好的泛化能力。线性模型通过简单地计算特征之间的线性关系来进行预测,相对来说更不容易受到过拟合的影响,因此在这种特殊情况下可能会表现得更好。
在这篇paper当中,我们将会介绍Wide & Deep模型,它在一个模型当中兼容了记忆性以及泛化性。它可以同时训练线性模型以及神经网络两个部分,从而达到更好的效果。
论文的主要内容有以下几点:
Wide & Deep模型,包含前馈神经网络embedding部分以及以及线性模型的特征转换,在广义广告系统当中的应用
Wide & Deep模型在Google Play场景下的实现与评估,Google Play是一个拥有超过10亿日活和100w App的移动App商店
Wide & Deep模型实践细节
构建样本:
要构建模型,我们需要从日志中获取样本。通常情况下,我们会通过埋点技术记录用户的行为数据,然后对这些日志进行清洗,以便获得用户的行为信息。样本通常采用三元组的格式:用户ID、项目ID和标签。至于相应的特征,我们需要根据用户ID和项目ID从相应的Hive表格中获取并整合。
正负样本:
正样本:用户点击的广告或商品。
负样本:用户在点击最大位置之上曝光但未点击的广告或商品;以及那些从未被点击过的用户部分曝光但未点击的广告或商品。
例如,有以下用户行为记录:
第一条:曝光
第二条:点击
第三条:曝光
第四条:点击
第五条:曝光
在这个例子中,我们可以看到用户在第二条和第四条记录中点击了广告或商品,因此这些可以作为正样本。然后,在第一条、第三条和第五条记录中,用户看到了广告或商品,但并未进行点击,这些可以作为负样本。
如何选择正负样本:
处理日志:
在处理日志时,我们需要区分Web端和App端,以避免增加无效的负样本。
用户点击最大位置以上曝光未点击的广告:
这种方法实际上被称为"Skip Above",即过滤掉最后一次点击。这样做的原因是,我们认为用户没有观察到之后的广告。
控制高度活跃用户对损失的影响:
为了降低高度活跃用户对损失的影响,我们在训练集中为每个用户提取相同数量的样本。
从未点击的用户部分曝光未点击的广告:
去除这部分用户可能导致模型仅学习活跃用户和有购买意向用户的行为习惯,导致线上和线下数据分布不一致。然而,如果保留这部分用户,这些无效用户可能会影响模型的推荐效果。为了解决这个问题,我们可以通过A/B测试来判断是否需要将这部分用户纳入样本,以及需要多少这样的用户。
避免特征穿越:
在构建特征时,需要确保特征是在样本时间之前生成的,以防止特征穿越问题。
总之,在选择正负样本时,我们需要综合考虑各种因素,包括数据来源、用户行为、样本数量以及特征选择。通过A/B测试,我们可以找到最佳的样本策略,从而优化模型的推荐效果。
如何解决样本不平衡问题:
在训练模型时,我们通常会遇到正负样本不平衡的问题,即未点击的广告(负样本)数量远多于点击的广告(正样本)。为了解决这个问题,我们可以采用以下方法:
下采样负样本:
通过从负样本中随机选择一部分样本,以减少负样本的数量,使正负样本数量更接近。
调整样本权重:
提高正样本的权重,以使正负样本在模型训练中具有更平衡的影响力。
然而,这些方法只能在一定程度上缓解类别不平衡问题,最根本的解决方案还是增加标注数据。需要注意的是,下采样和调整样本权重会改变样本分布,这可能导致训练样本分布与线上真实分布不一致。因此,在线上实际环境中模型是否能取得好的提升效果,还需要观察模型在真实数据上的表现。
处理噪声样本:
用户在不同时间可能对同一广告有不同的行为,导致收集到的样本中既有正样本(点击)也有负样本(未点击)。针对这种情况,我们可以采用以下方法处理:
如果两次行为之间的时间间隔较短,可以选择删除这些样本,或只保留其中一个。
如果两次行为之间的时间间隔较长,可以保留这些样本。因为可能用户的上下文环境发生了变化,时间特征能够在一定程度上区分样本的差异,帮助模型学习到用户短期兴趣的变化。
模型离线训练:
数据划分:使用7天的数据作为训练集,1天的数据作为测试集。
模型调优:
-
防止过拟合:添加Dropout和L2正则化。
-
加速收敛:使用Batch Normalization。
-
确保训练稳定和收敛:尝试不同的学习率(Wide部分为0.001,Deep部分为0.01效果较好)和批次大小(当前设置为2048)。
-
优化器:我们比较了SGD、Adam、Adagrad等优化器,最终选择了效果最好的Adagrad。
模型在线训练:也称为在线学习,是指模型在持续接收新数据的过程中不断更新和调整。Wide & Deep模型的在线训练可以采用以下策略:
在线模型更新:将模型部署在生产环境中,实时处理用户行为数据。每当收集到足够的新数据(例如,一定数量的用户点击或曝光),就对模型进行一次更新。
增量训练:每次收到新数据时,不需要从头开始训练模型,而是在当前模型的基础上继续训练。这可以大大提高训练效率。
学习率衰减:在线训练过程中,逐渐降低学习率。这有助于模型在初始阶段快速收敛,并在后期更稳定地微调。
数据窗口:为了保持模型的实时性,可以使用滑动窗口策略。只保留最近一段时间内的数据作为训练集,丢弃过旧的数据。这样可以确保模型关注最近的用户行为和趋势。
在线评估:定期评估模型在实时数据上的性能,以检测模型是否出现退化现象。如果发现性能下降,可以及时进行调整。
A/B测试:在线训练期间,可进行A/B测试,以便实时监测新模型相对于旧模型的性能。根据测试结果,可以决定是否应用新模型。
模型融合:在实际应用中,可以将多个在线训练的模型进行融合,以提高整体推荐性能。
请注意,在线训练可能会面临数据泄露、安全性和隐私等问题。因此,在实施在线训练时,请确保遵循相关法规和公司政策
Tensorflow1
# 导入所需的库
import numpy as np
import tensorflow as tf
# 这段代码定义了一个名为WideAndDeepModel的类,用于构建、训练和评估一个宽度和深度的神经网络模型。这个模型包含两个部分:宽度模型和深度模型。宽度模型是一个线性模型,深度模型是一个多层感知器(MLP)。
#
# __init__():初初始化方法,用于设置模型的参数,如向量维度、特征域长度、DNN层列表、学习率、正则化系数、提前停止轮数等。同时,它还调用build_graph()方法构建模型的计算图。
#
# build_graph:构建计算图方法,用于构建模型的计算图,包括输入、模型结构、损失函数、优化器等。这个方法调用了add_input()和inference()方法,并在最后设置了TensorBoard摘要。
#
# add_input:添加输入方法,用于创建特征域和标签的输入占位符。
#
# inference():定义模型的前向传播过程,包括广度(Wide)部分和深度(Deep)部分。广度部分使用FTRL优化器,深度部分使用Adam优化器。两部分的优化操作都被组合到self.train_op中。宽度模型是一个线性模型,深度模型是一个多层感知器(MLP)。同时设置损失函数、优化器以及其他评估指标。
#
# train():模型的训练方法。使用给定的训练数据和验证数据进行训练,支持批处理和最大迭代次数。在训练过程中,会对验证集进行评估,输出验证损失、验证准确率和验证AUC。这些性能指标将被用于判断模型是否过拟合或欠拟合。在验证集的AUC不再提高时,将触发提前停止。此外,还实现了早停(early stopping)策略。
#
# get_batches():一个生成器函数,用于从数据中生成批次。它将数据打乱,并按批次大小生成训练数据子集。这个方法在训练过程中被调用,以便在每个epoch中遍历训练数据。
# 定义 WideAndDeepModel 类
class WideAndDeepModel:
# 初始化方法
def __init__(self, vec_dim=None, field_lens=None, dnn_layers=None, wide_lr=0.001, l1_reg=0.1, deep_lr=0.01,
early_stopping_rounds=10, tensorboard_logdir=None, decay_steps=1000, decay_rate=0.95):
self.vec_dim = vec_dim # 向量维度
self.field_lens = field_lens # 特征域长度
self.field_num = len(field_lens) # 特征域数量
self.dnn_layers = dnn_layers # DNN层列表
self.wide_lr = wide_lr # 宽度模型学习率
self.l1_reg = l1_reg # L1正则化
self.deep_lr = deep_lr # 深度模型学习率
self.decay_steps = decay_steps # 学习率衰减步长
self.decay_rate = decay_rate # 学习率衰减率
self.early_stopping_rounds = early_stopping_rounds # 提前停止轮数
self.tensorboard_logdir = tensorboard_logdir # TensorBoard日志目录
assert isinstance(dnn_layers, list) and dnn_layers[-1] == 1
self.build_graph() # 构建计算图
# 构建计算图方法
def build_graph(self):
self.add_input() # 添加输入
self.inference() # 构建模型
# 添加评估指标:准确率和AUC
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(self.pred_label, tf.cast(self.y, tf.int32)), tf.float32))
_, self.auc = tf.metrics.auc(self.y, self.y_hat)
# TensorBoard摘要
if self.tensorboard_logdir:
tf.summary.scalar('loss', self.loss)
tf.summary.scalar('accuracy', self.accuracy)
tf.summary.scalar('auc', self.auc)
self.merged_summary = tf.summary.merge_all()
self.summary_writer = tf.summary.FileWriter(self.tensorboard_logdir)
# 添加输入方法
def add_input(self):
# 输入占位符:特征域和标签
self.x = [tf.placeholder(tf.float32, name='input_x-%d' % i) for i in range(self.field_num)]
self.y = tf.placeholder(tf.float32, shape=[None], name='input_y')
self.is_train = tf.placeholder(tf.bool)
# 构建模型方法
def inference(self):
# 宽度模型部分
with tf.variable_scope('wide_part'):
wo = tf.get_variable(name='bias', shape=[1], dtype=tf.float32)
linear_w = [tf.get_variable(name="linear_w-%d" % i, shape=[self.field_lens[i]], dtype=tf.float32) for i in
range(self.field_num)]
wide_part = wo + tf.reduce_sum(tf.concat(
[tf.reduce_sum(tf.multiply(self.x[i], linear_w[i]), axis=1, keepdims=True) for i in
range(self.field_num)], axis=1), axis=1, keepdims=True)
# 深度模型部分
with tf.variable_scope('dnn_part'):
emb = [tf.get_variable(name='emb_%d' % i, shape=[self.field_lens[i], self.vec_dim], dtype=tf.float32) for i
in range(self.field_num)]
emb_layer = tf.concat([tf.matmul(self.x[i], emb[i]) for i in range(self.field_num)], axis=1)
x = emb_layer
in_node = self.field_num * self.vec_dim
# 构建DNN层
for i in range(len(self.dnn_layers)):
out_node = self.dnn_layers[i]
w = tf.get_variable(name='w_%d' % i, shape=[in_node, out_node], dtype=tf.float32)
b = tf.get_variable(name='b_%d' % i, shape=[out_node], dtype=tf.float32)
in_node = out_node
if out_node != 1:
x = tf.nn.relu(tf.matmul(x, w) + b)
else:
self.y_logits = wide_part + tf.matmul(x, w) + b
self.y_hat = tf.nn.sigmoid(self.y_logits)
self.pred_label = tf.cast(self.y_hat > 0.5, tf.int32)
self.loss = -tf.reduce_mean(
self.y * tf.log(self.y_hat + 1e-8) + (1 - self.y) * tf.log(1 - self.y_hat + 1e-8))
# 设置优化器
self.global_step = tf.train.get_or_create_global_step()
# 学习率衰减
self.wide_lr = tf.train.exponential_decay(self.wide_lr, self.global_step, self.decay_steps, self.decay_rate,
staircase=True)
self.deep_lr = tf.train.exponential_decay(self.deep_lr, self.global_step, self.decay_steps, self.decay_rate,
staircase=True)
wide_part_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='wide_part')
dnn_part_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='dnn_part')
# 宽度模型优化器
wide_part_optimizer = tf.train.FtrlOptimizer(learning_rate=self.wide_lr,
l1_regularization_strength=self.l1_reg)
wide_part_op = wide_part_optimizer.minimize(loss=self.loss, global_step=self.global_step,
var_list=wide_part_vars)
# 深度模型优化器
dnn_part_optimizer = tf.train.AdamOptimizer(learning_rate=self.deep_lr)
# 将全局步数设置为None,以便只将全局步数传递给宽度部分求解器
dnn_part_op = dnn_part_optimizer.minimize(loss=self.loss, global_step=None, var_list=dnn_part_vars)
# 合并宽度和深度优化器
self.train_op = tf.group(wide_part_op, dnn_part_op)
# 合并所有摘要以供TensorBoard使用
self.merged_summary = tf.summary.merge_all()
# 训练方法
def train(self, sess, train_data, valid_data, batch_size=256, max_epochs=100):
best_valid_auc = 0
stopping_step = 0
for epoch in range(max_epochs):
for batch_x, batch_y in self.get_batches(train_data, batch_size):
_, loss, accuracy, auc = sess.run([self.train_op, self.loss, self.accuracy, self.auc],
feed_dict=self.get_feed_dict(batch_x, batch_y, True))
# 在验证数据上进行评估
valid_loss, valid_accuracy, valid_auc = 0, 0, 0
n_valid = 0
for valid_batch_x, valid_batch_y in self.get_batches(valid_data, batch_size):
loss, accuracy, auc, summary = sess.run([self.loss, self.accuracy, self.auc, self.merged_summary],
feed_dict=self.get_feed_dict(valid_batch_x, valid_batch_y,
False))
valid_loss += loss
valid_accuracy += accuracy
valid_auc += auc
n_valid += 1
valid_loss /= n_valid
valid_accuracy /= n_valid
valid_auc /= n_valid
# 保存TensorBoard摘要
if self.tensorboard_logdir:
self.summary_writer.add_summary(summary, global_step=epoch)
# 提前停止
if valid_auc > best_valid_auc:
best_valid_auc = valid_auc
stopping_step = 0
else:
stopping_step += 1
print(f"Epoch {epoch}: valid_loss={valid_loss}, valid_accuracy={valid_accuracy}, valid_auc={valid_auc}")
if stopping_step >= self.early_stopping_rounds:
print("Early stopping triggered.")
break
def get_batches(self, data, batch_size):
X, y = data
n_samples = len(y)
indices = np.arange(n_samples)
np.random.shuffle(indices)
for start_idx in range(0, n_samples, batch_size):
end_idx = min(start_idx + batch_size, n_samples)
batch_indices = indices[start_idx:end_idx]
batch_x = [X[i][batch_indices] for i in range(self.field_num)]
batch_y = y[batch_indices]
yield batch_x, batch_y
这个类可以用于构建一个Wide & Deep模型,输入特征的维度、特征字段长度、DNN层次结构和学习率等参数可以通过初始化函数传递。
我们使用了Ftrl优化器作为Wide部分的优化器,而使用了Adam优化器作为Deep部分的优化器。我们通过组合两个优化器的操作来进行模型训练。
Wide & Deep Learning for Recommender Systems
摘要
广义线性模型结合非线性特征转换,在处理具有大规模稀疏输入的回归和分类问题中已被广泛应用。通过一系列交叉积特征转换来记忆特征交互既有效又具有解释性,然而要实现更好的泛化性能,需要投入更多的特征工程工作。相较于此,深度神经网络能够通过为稀疏特征学习低维度密集嵌入,以较少的特征工程来更好地泛化至未见过的特征组合。但是,在用户与项目互动稀疏且高秩的情况下,具有嵌入的深度神经网络可能过度泛化,导致推荐的项目相关性较低。
为了解决这一问题,本文提出了一种名为Wide & Deep学习的方法,它联合训练宽线性模型和深度神经网络,将记忆与泛化的优势结合到推荐系统中。我们将该方法应用于Google Play商店,这是一个拥有超过10亿活跃用户和100万应用的商业移动应用平台,并对其进行了评估。在线实验结果表明,与仅使用宽模型或深模型相比,Wide & Deep方法显著提高了应用的下载量。同时,我们还在TensorFlow框架中开源了我们的实现方法。
CCS概念: • 计算方法 → 机器学习;神经网络;监督学习; • 信息系统 → 推荐系统;
关键词: Wide & Deep学习,推荐系统。
引言
推荐系统可以看作是一种搜索排名系统,它接收一组包含用户和上下文信息的输入查询,然后输出一个按照相关性排序的项目列表。在给定查询的情况下,推荐任务的目标是在数据库中找到相关的项目,并依据一定的目标(例如点击率或购买率)对这些项目进行排序。
与普通搜索排名问题类似,推荐系统面临的一个挑战是实现记忆和泛化的平衡。记忆可以简要地定义为学习项目或特征之间频繁共现的模式,并从历史数据中挖掘潜在的相关性。相对而言,泛化是基于相关性的传递性,旨在探索过去从未出现或很少出现的新特征组合。基于记忆的推荐通常更贴近用户兴趣,并与用户过去互动过的项目具有更直接的相关性。而与记忆相比,泛化更能够提高推荐项目的多样性,从而增加用户发现新内容的可能性。
本文主要关注Google Play商店的应用推荐问题,但所提出的方法同样适用于其他通用的推荐系统。
在实际应用中的大规模在线推荐和排名系统,广义线性模型(如逻辑回归)因其简单性、可扩展性和可解释性而被广泛采用。这些模型通常采用独热编码处理稀疏特征。以二进制特征“user_installed_app=netflix”为例,当用户安装了Netflix时,其值为1。有效地记忆特征可以通过在稀疏特征上进行交叉乘积转换来实现,例如AND(user_installed_app=netflix, impression_app=pandora)”,在用户安装了Netflix且后来安装了Pandora的情况下,其值为1。这表明特征对的共现与目标标签之间存在关联。通过使用较为宽泛的特征,例如AND(user_installed_category=video, impression_category=music),可以实现泛化,尽管可能需要进行手动特征工程。交叉乘积转换的局限在于,它们无法泛化到训练数据中未出现过的查询-项目特征对。
基于嵌入的模型,如因子分解机或深度神经网络,通过为每个查询和项目特征学习低维密集嵌入向量,减少了特征工程的负担,从而使模型能够泛化到之前未见过的查询-项目特征对。然而,在查询-项目矩阵稀疏且高秩的情况下(例如具有特定喜好的用户或只吸引少数人的小众项目),学习有效的低维表示可能会变得困难。在这种情况下,大部分查询-项目对之间实际上不存在交互,但密集嵌入可能导致所有查询-项目对都产生非零预测,从而导致过度泛化和不够相关的推荐结果。相比之下,采用交叉乘积特征转换的线性模型可以用更少的参数捕捉到这些“特殊规则”,从而更好地处理这种情况。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
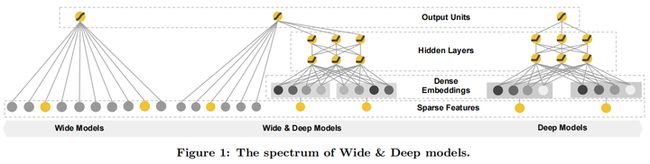
在本文中,我们提出了一种名为“Wide & Deep”学习框架,它能够在同一个模型中实现特征的记忆和泛化。该框架通过将线性模型组件与神经网络组件共同训练来实现这一目标,如图1所示。
本文的主要贡献如下: • 提出了Wide & Deep学习框架,该框架可以同时训练具有嵌入的前馈神经网络和带有特征转换的线性模型,适用于处理稀疏输入的通用推荐系统。 • 在Google Play上实现并评估了Wide & Deep推荐系统。Google Play是一个拥有超过10亿活跃用户和超过100万应用的移动应用商店。 • 我们已将实现及其高级API开源到TensorFlow1。
虽然这个想法看似简单,但我们证明了Wide & Deep框架在满足训练和服务速度度要求的同时,能够显著提高移动应用商店中应用的获取率。这表明该框架在实际应用中具有较高的价值。

编辑
添加图片注释,不超过 140 字(可选)
推荐系统简介
应用推荐系统的概述展示在图2中。当用户访问应用商店时,系统会根据各种用户和上下文特征生成一个查询请求。推荐系统会返回一个应用列表(亦称为展示项),在这些应用上,用户可以进行点击或购买等操作。这些用户操作,连同查询和展示项,都将记录在日志中,作为训练学习模型所需的数据。
鉴于数据库中拥有超过一百万款应用,要在满足服务延迟要求(通常为10毫秒级别)的前提下为每个查询逐一评分是不切实际的。因此,收到查询请求后的第一步便是检索。检索系统会利用各种信号(通常是机器学习模型与人工定义规则的结合)返回与查询最匹配的一小部分项目。在缩小候选项目范围后,排名系统会根据项目的得分对所有项目进行排序。得分通常基于P(y|x),即在给定特征x的条件下,用户操作标签y的概率。这些特征包括用户特征(如国家、语言、人口统计信息)、上下文特征(如设备、一天中使用的小时数、星期几使用)以及展示特征(如应用发布时长、应用的历史统计数据)。本文重点介绍了使用Wide & Deep学习框架的排名模型。
WIDE & DEEP
3.1 WIDE
WIDE是一种广义线性模型,其形式为 y = w^T x + b,如图1(左)所示。在这个模型中,y 代表预测值,x = [x1, x2, ..., xd] 是一个由 d 个特征组成的向量,w = [w1, w2, ..., wd] 是模型参数,b 是偏差项。特征集既包括原始输入特征,也包括经过变换的特征。其中一个最重要的变换就是交叉乘积变换,定义如下:
φk(x) = ∏ (i=1 to d) xi^cki, 其中 cki ∈ {0, 1}
在这个公式中,cki 是一个布尔变量。当第 i 个特征是第 k 个变换φk的一部分时,它的值为1;否则为0。对于二进制特征,交叉乘积变换(例如,“AND(gender=female, language=en)”)的值为1,当且仅当组成特征(如“gender=female”和“language=en”)都为1;否则为0。这样的交叉乘积变换捕捉了二进制特征之间的交互作用,并为广义线性模型引入了非线性。
通过引入交叉乘积变换,宽组件能够捕捉特征之间的复杂关系。这使得它在处理稀疏数据时具有较强的拟合能力,从而提高了推荐系统的表现。
3.2 DEEP
DEEP是一个前馈神经网络,如图1(右)所示。对于分类特征,原始输入是特征字符串(例如,“language=en”)。每一个这类稀疏的、高维的分类特征首先会被转换为低维且密集的实值向量,这通常被称为嵌入向量。嵌入向量的维度通常在 O(10) 到 O(100) 的数量级。嵌入向量最初是随机初始化的,然后在模型训练过程中调整其值以最小化最终损失函数。接下来,这些低维密集嵌入向量被输入到神经网络的隐藏层中。
具体而言,每个隐藏层执行以下计算:
A^(l+1) = f(W^(l) a^(l) + b^(l))
这里,l 表示层数,f 是激活函数,通常是(ReLU)。a^(l)、b^(l) 和 W^(l) 分别是第 l 层的激活值、偏差和模型权重。
通过这种方式,深度组件能够捕捉特征之间复杂的非线性关系。与宽度组件相结合,宽度和深度学习框架可以同时利用特征之间的线性关系(通过宽度组件)和非线性关系(通过深度组件)来提高模型的预测准确性。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在本文中,我们提出了一种宽度和深度学习框架,通过联合训练线性模型组件和神经网络组件,实现了在一个模型中同时具备记忆和泛化能力。与集成方法不同,联合训练在训练阶段同时考虑了宽度和深度部分以及它们之和的权重,从而优化了所有参数。在宽度和深度学习框架中,线性模型的宽度部分只需通过少量交叉乘积特征转换来弥补深度部分的不足,而不需要一个完整规模的宽度模型。
模型预测公式为:P(Y = 1|x) = σ(w_wide^T [x, φ(x)] + w_deep^T a^(lf) + b),其中Y是二元类标签,σ(·)是sigmoid函数,φ(x)表示原始特征x的交叉乘积变换,b是偏置项。w_wide是所有宽度模型权重的向量,w_deep是应用于最终激活a^(lf)的权重。
该框架将线性模型的宽度部分与神经网络的深度部分同时训练,使用小批量随机优化方法将梯度从输出反向传播到模型的宽度和深度部分。在实验中,我们使用带有L1正则化的FTRL算法作为宽度部分的优化器,使用AdaGrad作为深度部分的优化器。
简而言之,我们提出了一种宽度和深度学习框架,旨在实现一个模型中的记忆和泛化能力,通过联合训练线性模型组件和神经网络组件。这种方法在训练阶段同时考虑了模型各个部分,从而优化了所有参数。
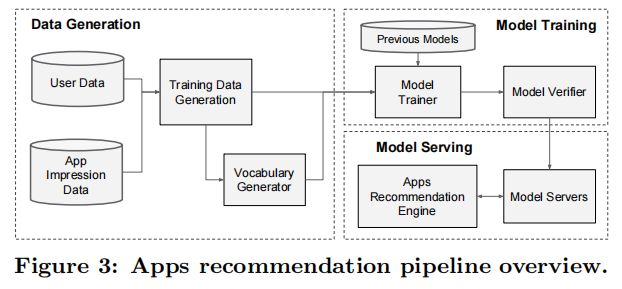
应用推荐系统的实现包括三个阶段:数据生成、模型训练和模型服务,如图3所示。
4.1 数据生成在这个阶段,利用一段时间内的用户和应用展示数据来生成训练数据。每个样本对应一个应用展示。标签表示应用安装:如果展示的应用被安装,则为1,否则为0。
此阶段还会生成词汇表,这是一个将分类特征字符串映射到整数ID的表。系统会计算出现次数超过最小阈值的所有字符串特征的ID空间。对于连续的实数特征,通过将特征值x映射到其累积分布函数P(X≤x)并将其划分为nq个分位数来将其归一化到[0,1]范围内。对于处于第i个分位数的值,归一化值为(i-1/nq - 1)。在数据生成过程中计算分位数边界。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
4.2 模型训练我们在实验中使用的模型结构如图4所示。训练过程中,输入层接收训练数据和词汇表,并一起生成稀疏和密集特征以及一个标签。宽模型部分包含了用户已安装应用与展示应用之间的交叉积变换。对于模型的深度部分,我们为每个分类特征学习一个32维的嵌入向量。我们将所有嵌入与密集特征连接在一起,形成一个大约1200维的密集向量。接着,将连接后的向量输入到3个ReLU层中,最后是逻辑输出单元。
Wide & Deep模型在超过5000亿个样本上进行了训练。每次收到新的训练数据时,都需要重新训练模型。然而,每次从头开始训练都会增加计算成本,延迟从数据到达到提供更新模型的时间。为了应对这个挑战,我们实现了一个热启动系统,该系统使用前一个模型的嵌入和线性模型权重初始化新模型。在将模型加载到模型服务器之前,进行一次干运行,以确保它不会在处理实时流量时出现问题。我们通过经验性地验证模型质量,将其与之前的模型进行对比,作为一个有效性检查。
“干运行”一般指在实际生产环境中,对某个系统或设备进行测试和验证,以确保其在正式使用前可以正常工作。这种测试可能涉及一系列的操作和流程,旨在模拟实际使用情况,以便在出现任何问题之前,能够及早发现和解决潜在的错误或缺陷。这种测试通常是在实际生产环境中进行,因为只有在实际使用情况下才能真正测试系统或设备的性能、可靠性和稳定性。
4.3 模型部署与服务当模型经过训练和验证后,我们将其加载到模型服务器中。对于每一个请求,服务器从应用检索系统中获取一组应用候选项,并利用用户特征对每个应用进行评分。接下来,根据评分将应用从高到低排序,按照这个顺序向用户展示。评分是通过在宽度和深度模型上执行一次前向推理计算得到的。
为了保证每个请求的响应时间在10毫秒以内,我们采用了多线程并行优化技术。通过并行执行较小批次,而非在单次大批量推理中为所有候选应用评分,从而提高了系统性能。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
实验结果为了评估 Wide & Deep 学习在实际推荐系统中的有效性,我们进行了在线实验,并从两个方面对系统进行了评估:应用获取和服务性能。
5.1 应用获取我们在 A/B 测试框架下进行了为期三周的在线实验。对于对照组,我们随机选择了1%的用户,向他们展示了由之前的排名模型生成的推荐。这个模型是一个高度优化的、仅基于宽度的逻辑回归模型,包含丰富的交叉特征转换。而对于实验组,我们向1%的用户展示了由 Wide & Deep 模型生成的推荐,该模型使用相同的特征集进行训练。如表1所示,与对照组相比,Wide & Deep 模型使应用商店首页的应用获取率相对提高了3.9%(具有统计显著性)。同时,我们还将结果与另一个仅使用相同特征和神经网络结构的深度模型的1%的用户组进行了比较,发现 Wide & Deep 模型相较于仅深度模型有1%的额外增益(具有统计显著性)。
除了在线实验,我们还在离线保留集上展示了接收者操作特征曲线下的面积(AUC)。尽管 Wide & Deep 在离线 AUC 方面略有提高,但其对在线流量的影响更为显著。这可能是因为离线数据集中的展示次数和标签是固定的,而在线系统可以通过将泛化与记忆相结合,生成新的探索性推荐,并从新的用户反馈中学习。
5.2 服务性能面对商业移动应用商店的高流量,实现高吞吐量和低延迟服务具有挑战性。在流量高峰期,我们的推荐服务器每秒需要为超过1000万个应用评分。使用单线程,在单个批次中为所有候选应用评分需要31毫秒。为了解决这个问题,我们采用了多线程并将每个批次拆分成较小的部分,显著降低了客户端延迟至14毫秒(包括服务开销),如表2所示。
相关研究将宽线性模型与交叉特征转换和深度神经网络与密集嵌入相结合的概念,受到了诸如因子分解机[5]等先前研究的启发。因子分解机通过将两个变量间的交互作用表现为两个低维嵌入向量间的点积,从而为线性模型增加泛化能力。在本文中,我们通过神经网络学习嵌入之间的高度非线性交互作用(而非点积),从而提高了模型的表达能力。
在语言模型方面,已提出联合训练递归神经网络(RNN)和具有n-gram特征的最大熵模型。通过学习输入和输出之间的直接权重,显著降低了RNN的复杂性[4]。在计算机视觉领域,通过使用快捷连接跳过一层或多层,深度残差学习[2]降低了训练更深模型的难度,并提高了准确性。神经网络与图模型的联合训练也被应用于从图像中估计人体姿态[6]。在本研究中,我们探索了前馈神经网络与线性模型的联合训练,以及稀疏特征与输出单元之间的直接连接,解决具有稀疏输入数据的通用推荐和排名问题。
在推荐系统文献中,已经探索了协同深度学习,它将深度学习用于内容信息处理,而协同过滤(CF)用于评分矩阵[7]。此外,还有一些关于移动应用推荐系统的研究,例如 AppJoy,它在用户的应用使用记录上使用 CF[8]。与之前基于 CF 或内容的方法不同,我们在应用推荐系统的用户和展示数据上联合训练 Wide & Deep 模型。
结论
对于推荐系统而言,记忆和泛化同等重要。宽线性模型通过交叉特征转换可以有效地记忆稀疏特征之间的交互,而深度神经网络则能通过低维嵌入实现对以往未见过的特征交互的泛化。我们提出了将这两种模型优势结合起来的 Wide & Deep 学习框架。我们将此框架应用于 Google Play 的推荐系统,并对这一大规模商业应用商店进行了实际评估。在线实验结果表明,与仅使用宽线性模型或深度神经网络的模型相比,Wide & Deep 模型在提高应用获取方面具有显著优势。
参考文献
-
J. Duchi, E. Hazan, 和 Y. Singer. 用于在线学习和随机优化的自适应梯度下降方法。机器学习研究杂志,12:2121–2159,2011年7月。
-
K. He, X. Zhang, S. Ren, 和 J. Sun. 深度残差学习用于图像识别。IEEE 计算机视觉和模式识别会议论文集,2016。
-
H. B. McMahan. 跟随正则化领导者和镜像下降:等价定理和 L1 正则化。在 AISTATS 论文集,2011。
-
T. Mikolov, A. Deoras, D. Povey, L. Burget, 和 J. H. Cernocky. 大规模神经网络语言模型的训练策略。在 IEEE 自动语音识别与理解研讨会,2011。
-
S. Rendle. 带有 libFM 的因子分解机。ACM 智能系统技术交易,3(3):57:1–57:22,2012年5月。
-
J. J. Tompson, A. Jain, Y. LeCun, 和 C. Bregler. 卷积网络和图形模型的联合训练用于人体姿态估计。在 Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence 和 K. Q. Weinberger 编辑,NIPS,页面 1799–1807。2014。
-
H. Wang, N. Wang, 和 D.-Y. Yeung. 用于推荐系统的协同深度学习。在 KDD 论文集,页面 1235–1244,2015。
[8] B. Yan 和 G. Chen. AppJoy:个性化的移动应用发现。在 MobiSys,页面 113–126,2011。
REFERENCES
[1] J. Duchi, E. Hazan, and Y. Singer. Adaptive
subgradient methods for online learning and stochastic
optimization. Journal of Machine Learning Research,
12:2121–2159, July 2011.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual
learning for image recognition. Proc. IEEE Conference
on Computer Vision and Pattern Recognition, 2016.
[3] H. B. McMahan. Follow-the-regularized-leader and
mirror descent: Equivalence theorems and l1
regularization. In Proc. AISTATS, 2011.
[4] T. Mikolov, A. Deoras, D. Povey, L. Burget, and J. H.
Cernocky. Strategies for training large scale neural
network language models. In IEEE Automatic Speech
Recognition & Understanding Workshop, 2011.
[5] S. Rendle. Factorization machines with libFM. ACM
Trans. Intell. Syst. Technol., 3(3):57:1–57:22, May 2012.
[6] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler. Joint
training of a convolutional network and a graphical
model for human pose estimation. In Z. Ghahramani,
M. Welling, C. Cortes, N. D. Lawrence, and K. Q.
Weinberger, editors, NIPS, pages 1799–1807. 2014.
[7] H. Wang, N. Wang, and D.-Y. Yeung. Collaborative
deep learning for recommender systems. In Proc. KDD,
pages 1235–1244, 2015.
[8] B. Yan and G. Chen. AppJoy: Personalized mobile
application discovery. In MobiSys, pages 113–126, 2011.
TensorFlow (Google):TensorFlow是Google开发的一个开源深度学习框架,其中也包含了Wide & Deep的官方实现。你可以参考这个链接了解更多:https://github.com/tensorflow/models/tree/master/official/recommendation/wide_deep
PyTorch (Facebook):PyTorch是Facebook开发的一个开源深度学习框架,尽管官方没有提供Wide & Deep的实现,但社区中有一些实现。例如,你可以参考这个GitHub仓库中的实现:https://github.com/jrzaurin/Wide-and-Deep-PyTorch
Keras:Keras是一个基于Python的高级神经网络API,可以与TensorFlow、CNTK和Theano等深度学习框架一起使用。你可以在Keras中实现Wide & Deep模型,这里有一个示例:https://github.com/entron/entity-embedding-rossmann/blob/master/wide_and_deep_keras.py
DeepCTR:DeepCTR是一个易于使用的深度学习点击率预测库,它提供了许多点击率预测模型的实现,包括Wide & Deep模型。GitHub仓库:GitHub - shenweichen/DeepCTR: Easy-to-use,Modular and Extendible package of deep-learning based CTR models .
大规模广告场景下
TensorFlow:
TensorFlow是谷歌开源的一个强大的机器学习库,支持多种平台,包括移动设备和分布式系统。TensorFlow提供了用于构建Wide & Deep模型的高级API,如tf.estimator和tf.feature_column。
优势:
成熟的社区和丰富的资源
良好的性能优化和GPU加速
分布式训练支持
强大的可视化工具(TensorBoard)
劣势:
学习曲线较陡峭
部分高级功能实现复杂
PyTorch:
PyTorch是一个基于Python的开源机器学习库,具有动态计算图和简洁的API。在PyTorch中,可以使用nn.Module自定义Wide & Deep模型。
优势:
灵活的动态计算图
易于调试和理解
与Python生态系统兼容性好
社区活跃,资源丰富
劣势:
相对较新,某些功能可能不如TensorFlow成熟
分布式训练支持较弱
DeepCTR:
DeepCTR是一个基于TensorFlow和Keras的开源库,专门用于点击率预估任务。它提供了多种预定义的深度CTR模型,包括Wide & Deep模型。
优势:
高度专注于CTR预估任务
易于使用和定制
提供多种预定义模型
基于TensorFlow和Keras,性能优化和社区支持良好
劣势:
可能不如原生TensorFlow或PyTorch灵活
社区规模较小
总结: Wide & Deep模型在CTR预估场景中具有很好的性能。根据您的需求和技能水平,可以选择适合您的库。TensorFlow和PyTorch是两个广泛使用的通用机器学习库,拥有庞大的社区和丰富的资源,而DeepCTR专注于CTR预估任务,易于使用且提供预定义的模型。不过,DeepCTR社区规模相对较小,可能不如前两者灵活。
Keras + Tensorflow Tensorflow2
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Dense, concatenate, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import train_test_split
def load_data():
# 数据集应包含类别特征和数值特征,以及点击率(CTR)标签
data = pd.read_csv('sample_data.csv')
# 分类特征和数值特征的列名
categorical_columns = ['cat1', 'cat2', 'cat3']
numerical_columns = ['num1', 'num2', 'num3']
# 标签列名
label_column = 'click'
# 对类别特征进行编码
for col in categorical_columns:
lbl = LabelEncoder()
data[col] = lbl.fit_transform(data[col])
# 对数值特征进行归一化
scaler = MinMaxScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
return train_data, test_data, categorical_columns, numerical_columns, label_column
def build_wide_and_deep_model(categorical_columns, numerical_columns):
# 输入层
categorical_inputs = [Input(shape=(1,), name=col) for col in categorical_columns]
numerical_inputs = Input(shape=(len(numerical_columns),), name='numerical')
# 嵌入层
embeddings = [Embedding(input_dim=100, output_dim=8)(cat_input) for cat_input in categorical_inputs]
# Deep部分
deep = concatenate(embeddings)
deep = Flatten()(deep)
deep = Dense(64, activation='relu')(deep)
deep = Dense(32, activation='relu')(deep)
# Wide部分
wide = concatenate(categorical_inputs + [numerical_inputs])
# 输出层
output = concatenate([deep, wide])
output = Dense(1, activation='sigmoid')(output)
# 构建模型
model = Model(inputs=categorical_inputs + [numerical_inputs], outputs=output)
model.compile(optimizer=Adam(lr=0.001), loss='binary_crossentropy', metrics=['accuracy'])
return model
def train_model(model, train_data, test_data, categorical_columns, numerical_columns, label_column, epochs=10, batch_size=128):
X_train_cat = [train_data[col].values for col in categorical_columns]
X_train_num = train_data[numerical_columns].values
y_train = train_data[label_column].values
X_test_cat = [test_data[col].values for col in categorical_columns]
X_test_num = test_data[numerical_columns].values
y_test = test_data[label_column].values
# 训练模型
history = model.fit(
x=X_train_cat + [X_train_num],
y=y_train,
validation_data=(X_test_cat + [X_test_num], y_test),
epochs=epochs,
batch_size=batch_size,
)
return history
def evaluate_model(model, test_data, categorical_columns, numerical_columns, label_column):
X_test_cat = [test_data[col].values for col in categorical_columns]
X_test_num = test_data[numerical_columns].values
y_test = test_data[label_column].values
# 评估模型
loss, accuracy = model.evaluate(x=X_test_cat + [X_test_num], y=y_test)
return loss, accuracy
def main():
train_data, test_data, categorical_columns, numerical_columns, label_column = load_data()
model = build_wide_and_deep_model(categorical_columns, numerical_columns)
history = train_model(
model,
train_data,
test_data,
categorical_columns,
numerical_columns,
label_column,
epochs=10,
batch_size=128,
)
# 评估模型
loss, accuracy = evaluate_model(model, test_data, categorical_columns, numerical_columns, label_column)
print(f"模型评估结果:\n损失: {loss:.4f}\n准确率: {accuracy:.4f}")
if __name__ == "__main__":
main()
Tensorflow1
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
def load_data():
# 数据集应包含类别特征和数值特征,以及点击率(CTR)标签
data = pd.read_csv('sample_data.csv')
# 分类特征和数值特征的列名
categorical_columns = ['cat1', 'cat2', 'cat3']
numerical_columns = ['num1', 'num2', 'num3']
# 标签列名
label_column = 'click'
# 对类别特征进行编码
for col in categorical_columns:
lbl = LabelEncoder()
data[col] = lbl.fit_transform(data[col])
# 对数值特征进行归一化
scaler = MinMaxScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
return train_data, test_data, categorical_columns, numerical_columns, label_column
def input_fn(data, categorical_columns, numerical_columns, label_column, num_epochs, shuffle, batch_size):
# 将数据集转换为TensorFlow数据集
dataset = tf.data.Dataset.from_tensor_slices((dict(data[categorical_columns + numerical_columns]), data[label_column]))
if shuffle:
dataset = dataset.shuffle(buffer_size=len(data))
dataset = dataset.repeat(num_epochs).batch(batch_size)
return dataset
def build_wide_and_deep_model(categorical_columns, numerical_columns):
# 定义特征列
categorical_feature_columns = [
tf.feature_column.categorical_column_with_identity(key=col, num_buckets=100)
for col in categorical_columns
]
numerical_feature_columns = [
tf.feature_column.numeric_column(key=col)
for col in numerical_columns
]
# 定义Wide部分
wide_columns = categorical_feature_columns + numerical_feature_columns
# 定义Deep部分
deep_columns = [
tf.feature_column.embedding_column(cat_col, dimension=8)
for cat_col in categorical_feature_columns
] + numerical_feature_columns
# 构建Estimator
estimator = tf.estimator.DNNLinearCombinedClassifier(
linear_feature_columns=wide_columns,
dnn_feature_columns=deep_columns,
dnn_hidden_units=[64, 32],
dnn_optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
)
return estimator
def train_and_evaluate_model(estimator, train_data, test_data, categorical_columns, numerical_columns, label_column, epochs=10, batch_size=128):
# 定义训练和评估的输入函数
train_input_fn = lambda: input_fn(
train_data, categorical_columns, numerical_columns, label_column, num_epochs=epochs, shuffle=True, batch_size=batch_size
)
eval_input_fn = lambda: input_fn(
test_data, categorical_columns, numerical_columns, label_column, num_epochs=1, shuffle=False, batch_size=batch_size
)
# 训练模型
estimator.train(input_fn=train_input_fn)
# 评估模型
eval_result = estimator.evaluate(input_fn=eval_input_fn)
return eval_result
def main():
train_data, test_data, categorical_columns, numerical_columns, label_column = load_data()
estimator = build_wide_and_deep_model(categorical_columns, numerical_columns)
eval_result = train_and_evaluate_model(
estimator, train_data, test_data, categorical_columns, numerical_columns, label_column, epochs=10, batch_size=128
)
# 输出评估结果
print("模型评估结果:")
for key, value in eval_result.items():
print(f"{key}: {value:.4f}")
if __name__ == "__main__":
main()
Pytorch
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
def load_data():
# 加载数据(这里使用一个样本数据集,你需要替换为实际的数据集)
# 数据集应包含类别特征和数值特征,以及点击率(CTR)标签
data = pd.read_csv('sample_data.csv')
# 分类特征和数值特征的列名
categorical_columns = ['cat1', 'cat2', 'cat3']
numerical_columns = ['num1', 'num2', 'num3']
# 标签列名
label_column = 'click'
# 对类别特征进行编码
for col in categorical_columns:
lbl = LabelEncoder()
data[col] = lbl.fit_transform(data[col])
# 对数值特征进行归一化
scaler = MinMaxScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
return train_data, test_data, categorical_columns, numerical_columns, label_column
#构建PyTorch数据集
class CTRDataset(Dataset):
def __init__(self, data, categorical_columns, numerical_columns, label_column):
self.categorical_data = data[categorical_columns].values.astype(np.int64)
self.numerical_data = data[numerical_columns].values.astype(np.float32)
self.labels = data[label_column].values.astype(np.float32)
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.categorical_data[idx], self.numerical_data[idx], self.labels[idx]
#构建Wide&Deep模型
class WideAndDeep(nn.Module):
def __init__(self, train_data, categorical_columns, numerical_columns, embedding_size=8, hidden_units=[64, 32], output_units=1):
super(WideAndDeep, self).__init__()
self.categorical_columns = categorical_columns
self.numerical_columns = numerical_columns
self.embedding_size = embedding_size
# Wide侧
self.wide = nn.Linear(len(categorical_columns) + len(numerical_columns), output_units)
# Deep侧
self.embeddings = nn.ModuleList([
nn.Embedding(train_data[col].nunique(), embedding_size) for col in categorical_columns
])
self.deep = nn.Sequential(
nn.Linear(embedding_size * len(categorical_columns) + len(numerical_columns), hidden_units[0]),
nn.ReLU(),
*[
layer for hidden_unit in hidden_units[1:] for layer in (nn.Linear(hidden_unit[0], hidden_unit[1]), nn.ReLU())
],
nn.Linear(hidden_units[-1], output_units)
)
def forward(self, x_cat, x_num):
# Wide侧
wide_out = self.wide(torch.cat([x_cat, x_num], dim=1))
# Deep侧
embeddings = [embedding(x_cat[:, i]) for i, embedding in enumerate(self.embeddings)]
x_cat_embed = torch.cat(embeddings, dim=1)
deep_out = self.deep(torch.cat([x_cat_embed, x_num], dim=1))
# 结合Wide侧和Deep侧
out = wide_out + deep_out
# 使用sigmoid激活函数得到CTR预估
ctr_prediction = torch.sigmoid(out)
return ctr_prediction
#训练模型
def train_model(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for batch in dataloader:
x_cat, x_num, y = [item.to(device) for item in batch]
optimizer.zero_grad()
y_pred = model(x_cat, x_num)
loss = criterion(y_pred.squeeze(), y)
loss.backward()
optimizer.step()
running_loss += loss.item() * x_cat.size(0)
return running_loss / len(dataloader.dataset)
#评估模型
def evaluate_model(model, dataloader, criterion, device):
model.eval()
running_loss = 0.0
with torch.no_grad():
for batch in dataloader:
x_cat, x_num, y = [item.to(device) for item in batch]
y_pred = model(x_cat, x_num)
loss = criterion(y_pred.squeeze(), y)
running_loss += loss.item() * x_cat.size(0)
return running_loss / len(dataloader.dataset)
#主函数
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data, test_data, categorical_columns, numerical_columns, label_column = load_data()
train_dataset = CTRDataset(train_data, categorical_columns, numerical_columns, label_column)
test_dataset = CTRDataset(test_data, categorical_columns, numerical_columns, label_column)
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)
model = WideAndDeep(train_data, categorical_columns, numerical_columns).to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 10
for epoch in range(epochs):
train_loss = train_model(model, train_dataloader, criterion, optimizer, device)
test_loss = evaluate_model(model, test_dataloader, criterion, device)
print(f"Epoch {epoch + 1}/{epochs} - Train loss: {train_loss:.4f}, Test loss: {test_loss:.4f}")
if __name__ == "__main__":
main()
DeepCTR
import pandas as pd
import numpy as np
from sklearn.metrics import log_loss, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import WDL
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
# 加载和预处理数据
def load_data():
# 数据集应包含类别特征和数值特征,以及点击率(CTR)标签
data = pd.read_csv('sample_data.csv')
# 分类特征和数值特征的列名
categorical_columns = ['cat1', 'cat2', 'cat3']
numerical_columns = ['num1', 'num2', 'num3']
# 标签列名
label_column = 'click'
# 对类别特征进行编码
for col in categorical_columns:
lbl = LabelEncoder()
data[col] = lbl.fit_transform(data[col])
# 对数值特征进行归一化
scaler = MinMaxScaler()
data[numerical_columns] = scaler.fit_transform(data[numerical_columns])
# 划分训练集和测试集
train_data, test_data = train_test_split(data, test_size=0.2, random_state=42)
return train_data, test_data, categorical_columns, numerical_columns, label_column
# 构建特征列
def build_feature_columns(train_data, categorical_columns, numerical_columns):
# SparseFeat用于类别特征,DenseFeat用于数值特征
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=train_data[feat].nunique(), embedding_dim=8) for feat in categorical_columns]
dense_feature_columns = [DenseFeat(feat, 1) for feat in numerical_columns]
return sparse_feature_columns, dense_feature_columns
# 构建模型
def build_wdl_model(sparse_feature_columns, dense_feature_columns):
model = WDL(linear_feature_columns=sparse_feature_columns + dense_feature_columns,
dnn_feature_columns=sparse_feature_columns + dense_feature_columns,
dnn_hidden_units=[64, 32],
l2_reg_linear=1e-4,
l2_reg_embedding=1e-4,
l2_reg_dnn=1e-4,
task='binary')
return model
# 训练模型
def train_model(model, train_data, test_data, sparse_feature_columns, dense_feature_columns, label_column, epochs=10, batch_size=128):
# 获取所有特征列的名称
feature_names = get_feature_names(sparse_feature_columns + dense_feature_columns)
# 准备训练和测试数据
X_train = train_data[feature_names].values
y_train = train_data[label_column].values
X_test = test_data[feature_names].values
y_test = test_data[label_column].values
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['binary_crossentropy', 'AUC', 'accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, y_test))
return model
# 评估模型
def evaluate_model(model, test_data, sparse_feature_columns, dense_feature_columns, label_column):
feature_names = get_feature_names(sparse_feature_columns + dense_feature_columns)
X_test = test_data[feature_names].values
y_test = test_data[label_column].values
y_pred = model.predict(X_test)
y_pred_label = np.round(y_pred)
loss = log_loss(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred_label)
return loss, accuracy
# 主函数
def main():
train_data, test_data, categorical_columns, numerical_columns, label_column = load_data()
sparse_feature_columns, dense_feature_columns = build_feature_columns(train_data, categorical_columns, numerical_columns)
model = build_wdl_model(sparse_feature_columns, dense_feature_columns)
trained_model = train_model(model, train_data, test_data, sparse_feature_columns, dense_feature_columns, label_column, epochs=10, batch_size=128)
loss, accuracy = evaluate_model(trained_model, test_data, sparse_feature_columns, dense_feature_columns, label_column)
print(f"模型评估结果:\n损失: {loss:.4f}\n准确率: {accuracy:.4f}")
if __name__ == "__main__":