Linux: 性能分析之内存增长和泄漏
文章目录
- 1. 前言
- 2. 背景
- 3. 内存增长和泄漏分析方法
-
- 3.1 跟踪 malloc(), free() 等接口
-
- 3.1.1 用 perf 采样
- 3.1.2 用 ebpf 来跟踪
- 3.2 跟踪 brk() 调用
-
- 3.2.1 使用 perf 跟踪 brk()
- 3.2.2 使用 ebpf 跟踪 brk()
- 3.3 跟踪 mmap() 调用
-
- 3.3.1 使用 perf 跟踪 mmap()
- 3.3.2 使用 ebpf 跟踪 mmap()
- 3.4 跟踪 page fault
-
- 3.4.1 使用 perf 跟踪 page fault
- 3.4.2 使用 ebpf 跟踪 page fault
- 4. 小结
- 5. 参考链接
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 背景
你的应用程序内存使用量正在稳步增长,并且你着急上火,正在争分夺秒地修复它。这可能是由于配置错误而导致的内存增长,也可能是由于软件问题导致的内存泄漏。对于某些应用程序,性能可能会开始下降,由于内存开始紧张,内存压缩规整回收工作将消耗更多的 CPU。如果应用程序占用的内存变得太大,性能可能会由于页面频繁换入换出(swap)而出现断崖式下降,或者应用程序可能会被系统杀死(如 Linux 的 OOM-killer)。你希望在前述任一情况发生之前快速查看一下状况,以便修正问题。但是怎么做呢?
调试内存增长,涉及到对应用程序自身配置的做检查和使用系统相关工具。相对来说,调试内存泄漏要更加困难,但有许多工具可以提供帮助:
(1) mcheck
(2) wrap 内存接口
(3) 模拟 CPU 执行的 Valgrind。Valgrind 可导致程序运行速度慢上20到30倍,所有有些问题不一定能够重现。
(4) libtcmalloc的堆采样分析器,可能导致程序运行速度降低5倍左右。
(5) 使用 coredump 调试的 GDB。
以上这些工具,都无法动态的观测到应用程序内存的实时变化情况,不利于我们找到真正导致内存增长或泄漏的根因。本文将介绍4种对内存进行动态跟踪的方法,并将这些跟踪数据可视化为火焰图。本文所有演示基于 Linux 操作系统进行。另外,需要预先部署 FlameGraph 脚本工具。本文生成的一些结果数据可以从 此处 查看。
3. 内存增长和泄漏分析方法
下图说明了本文将介绍的这4种方法,方法涉及图中绿色文本标注的事件:
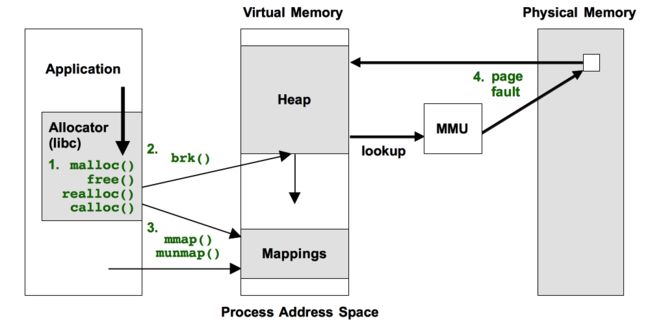
这4种方法每种都有自身的缺点,后文将一一加以说明。这些方法需要堆栈追踪记录,很多应用程序使用 GCC 的编译选项 -fomit-frame-pointer 进行编译,这样会导致基于栈帧指针的栈回溯的失败;而像 Java VM 等在运行时进行编译,在没有额外辅助的情形下,追踪工具无法获取程序的符号信息,栈记录将显示为符号地址。这些情形可参考 Stack Traces 和 JIT Symbols 进行处理。
3.1 跟踪 malloc(), free() 等接口
3.1.1 用 perf 采样
# perf record -F 99 -a --call-graph dwarf
# perf script | ./stackcollapse.pl | \
./flamegraph.pl --color=mem --title="malloc() Flame Graph" --countname="calls" > out.svg
3.1.2 用 ebpf 来跟踪
# /usr/share/bcc/tools/stackcount -p 2990 -U c:malloc > out.stacks
# ./stackcollapse.pl < out.stacks | \
./flamegraph.pl --color=mem --title="malloc() Flame Graph" --countname="calls" > out.svg
章节 3.1.1 和 3.1.2 都最终生成火焰图 out.svg 。直接跟踪 malloc() 引入的开销比较高。直接跟踪 brk() 系统调用会降低开销,但不能够跟踪内存泄漏问题。
3.2 跟踪 brk() 调用
有的应用程序在初始化时,可能通过 brk() 系统调用分配一大块虚拟内存,然后封装自己的内存分配释放接口来响应内存分配释放请求,而不使用 malloc()/free() 接口。
使用 brk() 系统调用分配内存的方式,可能不是那么常见,用 perf 在我的观察了很长时间,也没发现一次 brk() 系统调用:
# perf stat -e syscalls:sys_enter_brk -I 1000 -a
# time counts unit events
1.001318396 0 syscalls:sys_enter_brk
2.002291392 0 syscalls:sys_enter_brk
3.003251158 0 syscalls:sys_enter_brk
4.004399897 0 syscalls:sys_enter_brk
5.005382548 0 syscalls:sys_enter_brk
6.006749931 0 syscalls:sys_enter_brk
7.007859563 0 syscalls:sys_enter_brk
8.009513993 0 syscalls:sys_enter_brk
9.011043102 0 syscalls:sys_enter_brk
[...]
3.2.1 使用 perf 跟踪 brk()
# perf record -e syscalls:sys_enter_brk -a -g -- sleep 120
# perf script > out.stacks
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Heap Expansion Flame Graph" --countname="calls" > out.svg
3.2.2 使用 ebpf 跟踪 brk()
# /usr/share/bcc/tools/stackcount SyS_brk > out.stacks
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Heap Expansion Flame Graph" --countname="calls" > out.svg
3.3 跟踪 mmap() 调用
应用程序在初始化时,也可能使用 mmap() 系统调用来分配虚拟内存,用于自己大块数据处理事务。glibc 在分配大块内存时,也可能通过 mmap() 系统调用。如同 brk() 一样,mmap() 的调用频率应该也不高。
3.3.1 使用 perf 跟踪 mmap()
# perf record -e syscalls:sys_enter_mmap -a -g -- sleep 60
# perf script > out.stacks
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="mmap() Flame Graph" --countname="calls" > out.svg
3.3.2 使用 ebpf 跟踪 mmap()
# /usr/share/bcc/tools/stackcount SyS_mmap > out.stacks
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="mmap() Flame Graph" --countname="calls" > out.svg
3.4 跟踪 page fault
brk() 和 mmap() 影响的是虚拟内存的变更,通常是直到向虚拟地址空间进行写入时,才会通过缺页异常(page fault)分配物理内存。
先用 perf 跟踪一下缺页异常的情况:
# perf stat -e page-faults -I 1000 -a
# time counts unit events
1.000995850 0 page-faults
2.002827305 2 page-faults
3.003792700 0 page-faults
4.005305961 0 page-faults
5.006339296 0 page-faults
6.007330095 0 page-faults
7.008390464 0 page-faults
8.009137206 0 page-faults
9.010183397 0 page-faults
10.011478644 0 page-faults
11.013237871 0 page-faults
12.014692430 0 page-faults
13.015920820 0 page-faults
14.017341534 0 page-faults
15.018367974 0 page-faults
^C 15.666584881 0 page-faults
看看,我观察时电脑没啥读写活动,所以只观察到了2次缺页异常。
3.4.1 使用 perf 跟踪 page fault
# perf record -e page-faults -a -g -- sleep 30
# perf script > out.stacks
# ./stackcollapse-perf.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Page Fault Flame Graph" --countname="pages" > out.svg
如果对 major-faults 或 minor-faults 缺页异常感兴趣,也可以进行采样分析。
3.4.2 使用 ebpf 跟踪 page fault
# /usr/share/bcc/tools/stackcount 't:exceptions:page_fault_*' > out.stacks
# ./stackcollapse.pl < out.stacks | ./flamegraph.pl --color=mem \
--title="Page Fault Flame Graph" --countname="pages" > out.svg
跟踪 page fault 的开销可能比跟踪 brk() 或 mmap() 高一点,但幅度不大: page fault 应该仍然相对较少,这使得这种跟踪方法引入的开销几乎可以忽略不计。在实践中,page fault 是诊断内存增长和泄漏的廉价、快速且通常有效的方法。它无法说明一切,但值得一试。
4. 小结
本文介绍的这些内存跟踪方法,可以识别虚拟或物理内存的增长,并包括增长的所有原因,包括泄漏。跟踪 brk(),mmap() 和 page fault 方法不能直接分别出内存泄漏,这需要进一步分析。但是,它们的优点是开销非常低,使其适合实时生产应用程序分析。这些方法的另一个优点是,通常无需重新启动应用程序即可部署跟踪工具。
5. 参考链接
https://brendangregg.com/FlameGraphs/memoryflamegraphs.html
https://www.brendangregg.com/perf.html#StackTraces
https://github.com/brendangregg/BPF-tools/tree/master/old/2017-12-23