Auto-GPT来啦,手把手教你安装更稳定的stable的Auto-GPT,实现两个AutoGPT合作执行任务,AutoGPT代理同时执行任务
进入Auto-GPT项目
https://github.com/Significant-Gravitas/Auto-GPT
在安装之前,你需要确保本地已安装好 Python 开发环境。
Auto-GPT 具体安装步骤如下:
将项目克隆到本地:
一定要用以下语句拉项目stable ,不然会产生问题并且不稳定
git clone -b stable --single-branch https://github.com/Significant-Gravitas/Auto-GPT.git
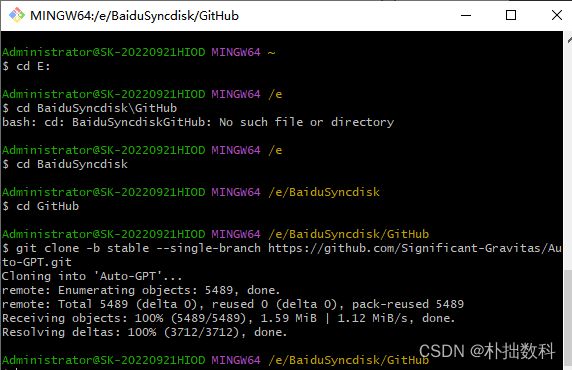
进入我的目录E:\BaiduSyncdisk\GitHub\Auto-GPT
Administrator@SK-20220921HIOD MINGW64 /e
$ cd BaiduSyncdisk\GitHub
bash: cd: BaiduSyncdiskGitHub: No such file or directory
Administrator@SK-20220921HIOD MINGW64 /e
$ cd BaiduSyncdisk
Administrator@SK-20220921HIOD MINGW64 /e/BaiduSyncdisk
$ cd GitHub
Administrator@SK-20220921HIOD MINGW64 /e/BaiduSyncdisk/GitHub
$ git clone -b stable --single-branch https://github.com/Significant-Gravitas/Auto-GPT.git
Cloning into 'Auto-GPT'...
remote: Enumerating objects: 5489, done.
remote: Total 5489 (delta 0), reused 0 (delta 0), pack-reused 5489
Receiving objects: 100% (5489/5489), 1.59 MiB | 1.12 MiB/s, done.
Resolving deltas: 100% (3712/3712), done.
cd 'Auto-GPT'
使用 pip 安装项目依赖:
pip install -r requirements.txt
重命名 .env.template 文件:
mv .env.template .env
打开目录中的 .env 文件,找到 OPENAI_API_KEY ,填入你的 OpenAI API Key。
API Key 可以在 OpenAI 官网生成:https://platform.openai.com/account/api-keys
一切准备工作就绪,开始运行 Auto-GPT:
python -m autogpt
正常来说,如果你上面几步没有操作失误,那么现在项目是可能正常运行的。
如果出现不能运行的原因,那大概率是命令行工具没有设置好代理。
命令运行成功后,系统会提示你输入 AI 名称、角色任务、任务目标。
AI 名称和角色任务,可以根据你自己的需求来取。
这里比较重要的,是 5 个任务目标,设定的目标是否清晰明确,直接决定了任务的执行质量。
除了上述功能之外,你还可以配置 Pinecone 来存储向量内容,使用 ElevenLabs 让 AI 在执行任务的时候开口说话,使用 Google API 突破每日信息搜索限制等等。
玩法众多,可探索的空间也非常大,但要真正掌握,需要不少时间。
官方文档翻译
Auto-GPT: An Autonomous GPT-4 Experiment
Auto-GPT:自主 GPT-4 实验
紧急:不 stable master 使用
此信息优先于所提供的任何其他信息,并应相应地遵循。
我们的工作流程已得到改进,但请注意, master 分支可能经常处于一种破碎的状态。请从此处下载最新 stable 版本:https://github.com/Torantulino/Auto-GPT/releases/latest.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EeWXmvyK-1681878897309)(null)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-N5Scm7AL-1681878897781)(null)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9fJhbnmq-1681878900047)(null)] [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FS3VISVJ-1681878898150)(null)]
Auto-GPT 是一个实验性的开源应用程序,展示了 GPT-4 语言模型的功能。这个程序由 GPT-4 驱动,将法学硕士的“思想”链接在一起,以自主实现你设定的任何目标。作为 GPT-4 完全自主运行的第一个例子,Auto-GPT 突破了人工智能的极限。
演示(30/03/2023):
https://user-images.githubusercontent.com/22963551/228855501-2f5777cf-755b-4407-a643-c7299e5b6419.mp4
帮助资助 Auto-GPT 的发展
如果你能腾出一杯咖啡,你就可以帮助支付开发自动 GPT 的成本,并帮助推动完全自主人工智能的边界。非常感谢你的支持,这个免费的开源项目的开发是由所有的贡献者和赞助商促成的。如果你想赞助这个项目,并让你的头像或公司标志出现在下面,请点击这里。
企业赞助商


个人赞助商















































































目录
- Auto-GPT:自主 GPT-4 实验
- [紧急:不使用
masterstable](#–urgent-use-stable-not-master–) - 演示(30/03/2023):
- 目录
- 特点
- 要求
- 安装
- Usage
- Logs
- Docker
- 命令行参数
- 语音模式
- Google API 密钥配置
- 设置环境变量
- 内存后端设置
- Redis 设置
- 松果 API 密钥设置
- MILVUS 设置
- 编织设置
- 设置环境变量
- 设置缓存类型
- 查看内存使用情况
- 内存预播种
- 连续模式
- 仅 GPT3.5 模式
- 图像生成
- 限制
- 免责声明
- 在 Twitter 上与我们联系
- Run tests
- Run linter
- [紧急:不使用
特点
- 通过互联网进行搜索和收集信息
- 长短期记忆管理
- 用于文本生成的 GPT-4 实例
- 访问热门网站和平台
- 🗃 使用 GPT-3.5 进行文件存储和摘要
要求
- 环境(只需选择一个)
- VSCode+DevContainer:已配置在.devcontainer 文件夹中,可直接使用
- Python 3.8 或更新版本
- OpenAI API 密钥
可选:
- 内存后端
- 松果 API 密钥(如果你想要松果支持的记忆)
- Milvus(如果你想要 Milvus 作为内存后端)
- ElevenLabs 密钥(如果你想让 AI 说话)
安装
要安装 Auto-GPT,请按照下列步骤操作:
- 确保你拥有上面列出的所有要求内容,如果没有,请安装/获取它们
_ 要执行以下命令,请打开 cmd、bash 或 PowerShell 窗口,方法是导航到计算机上的文件夹并在顶部键入 CMD 文件夹路径,然后按 Enter._
- 克隆存储库:对于此步骤,你需要安装 Git.或者,你可以通过单击本页顶部的按钮下载 ZIP 文件
git clone https://github.com/Torantulino/Auto-GPT.git
- 导航到下载存储库的目录
cd Auto-GPT
- 安装所需的依赖项
pip install -r requirements.txt
- 在主
/Auto-GPT文件夹中找到名为.env.template的文件。创建此文件的副本,通过删除template扩展名来调用.env。最简单的方法是在命令提示符/终端窗口cp.env.template.env中执行此操作,并在文本编辑器中打开.env文件。注意:以点开头的文件可能会被你的操作系统隐藏。找到写着OPENAI_API_KEY=。之后"=",输入你唯一的 OpenAI API 密钥(不带任何引号或空格)。输入你想要使用的服务的任何其他 API 密钥或令牌。保存并关闭".env"文件。通过完成这些步骤,你已经为项目正确配置了 API 密钥。
-
请参阅OpenAI API 密钥配置获取 OpenAI API 密钥。
-
获取你的 ElevenLabs API 密钥:https://elevenlabs.io. 你可以使用网站上的“配置文件”选项卡查看你的 Xi-API 密钥。
-
如果要在 Azure 实例上使用 GPT,请设置
USE_AZURE为True,然后按照下列步骤操作:- 重命名为
azure.yaml.templateazure.yaml,azure_api_version并为部分中azure_model_map的相关模型提供相关azure_api_base的所有部署 ID:fast_llm_model_deployment_id-你的 GPT-3.5-Turbo 或 GPT-4 部署 IDsmart_llm_model_deployment_id-你的 GPT-4 部署 IDembedding_model_deployment_id-你的 text-embedding-ada-002 v2 部署 ID
- 请将所有这些值指定为双引号字符串
# Replace string in angled brackets (<>) to your own ID azure_model_map: fast_llm_model_deployment_id: "" ...- 详细信息可以在这里找到:https://pypi.org/project/openai/ 在
Microsoft Azure Endpoints部分和这里:https://learn.microsoft.com/en-us/azure/cognitive-services/openai/tutorials/embeddings?tabs=command-line 对于嵌入模型。
- 重命名为
用法
- 在终端中运行
autogptPython 模块
python -m autogpt
- 在每个操作之后,从选项中选择以授权命令,
退出程序,或向 AI 提供反馈。- 授权单个命令,输入
y - 授权一系列连续的_名词_命令,输入
y -N - 退出程序,输入
n
- 授权单个命令,输入
原木
活动和错误日志位于 ./output/logs
要打印调试日志,请执行以下操作:
python -m autogpt --debug
码头工人
你也可以将其构建到 Docker 映像中并运行它:
docker build -t autogpt .
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
你可以传递额外的参数,例如,使用 --gpt3only AND --continuous 模式运行:
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt --gpt3only --continuous
命令行参数
以下是运行 auto-GPT 时可以使用的一些常用参数:
将尖括号( <> )中的任何内容替换为要指定的值
- 查看所有可用的命令行参数
python -m autogpt --help
- 使用不同的 AI 设置文件运行 auto-GPT
python -m autogpt --ai-settings <filename>
- 指定 3 个内存后端之一:
local、redispinecone或no_memory
python -m autogpt --use-memory <memory-backend>
注意:其中一些标志有速记,例如
-m--use-memory。使用python -m autogpt --help了解更多信息
语音模式
使用此选项可将 TTS_(文字转语音)_用于自动 GPT
python -m autogpt --speak
名称来自 11 个实验室的 ID 列表,你可以使用名称或 ID:
- 瑞秋:21M00TCM4TLVDQ8IKWAM
- 多米:AZNZLK1XVDVUEBNXMLLD
- 贝拉:exavitqu4vr4xnsdxmal
- 安东尼:erxwobayin019pkysvjv
- 埃利:MF3MGYEYCL7XYWBV9V6O
- 乔希:txgeqnhwrfwftfgw9xjx
- 阿诺德:VR6AEWLTIGWG4XSOUKAG
- 亚当:pninz6obpgdqgcfmajgb
- Sam:yoz06amxzjj28mfd3poq
OpenAI API 密钥配置
从以下https://platform.openai.com/account/api-keys.位置获取 OpenAI API 密钥:
要将 OpenAI API 密钥用于 Auto-GPT,你需要设置计费(即付费帐户)。
你可以在以下位置https://platform.openai.com/account/billing/overview.设置付费帐户
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2iKWygCT-1681878896742)(./docs/imgs/openai-api-key-billing-paid-account.png)]
Google API 密钥配置
此部分是可选的,如果你在运行 Google 搜索时遇到错误 429 的问题,请使用官方 Google API.要使用该 google_official_search 命令,你需要在环境变量中设置 Google API 密钥。
- 转到谷歌云控制台。
- 如果你还没有帐户,请创建一个帐户并登录。
- 通过单击页面顶部的“选择项目”下拉菜单并单击“新建项目”来创建新项目。给它一个名字,然后点击“创建”。
- 转到API 和服务仪表板并单击“启用 API 和服务”。搜索“自定义搜索 API ”并单击它,然后单击“启用”。
- 转到证件页面并单击“创建凭据”。选择“API 密钥”。
- 复制 API 密钥并将其设置为计算机上名为
GOOGLE_API_KEY的环境变量。请参阅下面的设置环境变量。 - 项目上Enable的自定义搜索 API.(可能需要等待几分钟才能传播)
- 转到定制搜索引擎页面并单击“添加”。
- 按照提示设置搜索引擎。你可以选择搜索整个 Web 或特定站点。
- 一旦你创建了你的搜索引擎,点击“控制面板”,然后“基本”。复制“搜索引擎 ID”并将其设置为计算机上名为
CUSTOM_SEARCH_ENGINE_ID的环境变量。请参阅下面的设置环境变量。
请记住,你的免费每日自定义搜索配额最多只允许 100 次搜索。要增加此限制,你需要为项目分配一个计费帐户,以从高达 10K 的每日搜索中获利。
设置环境变量
对于 Windows 用户:
setx GOOGLE_API_KEY "YOUR_GOOGLE_API_KEY"
setx CUSTOM_SEARCH_ENGINE_ID "YOUR_CUSTOM_SEARCH_ENGINE_ID"
对于 MacOS 和 Linux 用户:
export GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
export CUSTOM_SEARCH_ENGINE_ID="YOUR_CUSTOM_SEARCH_ENGINE_ID"
设置缓存类型
默认情况下,Auto-GPT 将使用 LocalCache 而不是 Redis 或 Pinecone.
要切换到其中之一,请将 MEMORY_BACKEND env 变量更改为所需的值:
local(默认)使用本地 JSON 缓存文件pinecone使用你在环境设置中配置的 pinecone.io 帐户redis将使用你配置的 Redis 缓存milvus将使用你配置的 MILVUS 缓存weaviate将使用你配置的 Weaviate 缓存
Redis 设置
__小心
这不是为了公开访问,并且缺乏安全措施。因此,避免在没有密码或根本没有密码的情况下将 Redis 暴露在互联网上
- 安装 Docker 桌面
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
有关设置密码和其他配置的信息,请参阅https://hub.docker.com/r/redis/redis-stack-server 。
- 设置以下环境变量
在尖括号( <> )中替换密码
MEMORY_BACKEND=redis
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_PASSWORD=<PASSWORD>
你可以选择设置
WIPE_REDIS_ON_START=False
Redis 中存储的持久化内存
你可以使用以下方法为 Redis 指定内存索引:
MEMORY_INDEX=<WHATEVER>
松果 API 密钥设置
Pinecone 支持存储大量基于矢量的内存,允许在任何给定时间只为代理加载相关内存。
- 如果你还没有帐户,请转到pinecone并创建一个帐户。
- 选择
Starter计划以避免被收费。 - 在左侧边栏的默认项目下找到你的 API 密钥和区域。
在 .env 文件集中:
PINECONE_API_KEYPINECONE_ENV(示例:“US-EAST4-GCP ”)MEMORY_BACKEND=pinecone
或者,你可以从命令行设置它们(高级):
对于 Windows 用户:
setx PINECONE_API_KEY ""
setx PINECONE_ENV "" # e.g: "us-east4-gcp"
setx MEMORY_BACKEND "pinecone"
对于 MacOS 和 Linux 用户:
export PINECONE_API_KEY=""
export PINECONE_ENV="" # e.g: "us-east4-gcp"
export MEMORY_BACKEND="pinecone"
MILVUS 设置
Milvus是一个开源的、高度可扩展的向量数据库,用于存储大量的向量内存,并提供快速的相关搜索。
- 设置 Milvus 数据库,保持你的 PyMilvus 版本和 MilvUS 版本相同,以避免兼容问题。
- 由开源软件安装 MILVUS设置
- 或设置人齐利兹云
- 设置
MILVUS_ADDR.env到你的米尔维斯地址host:ip。 - 将设置
MEMORY_BACKEND.env为milvus以启用 MILVUS 作为后端。 - 可选
- 在中
.env设置MILVUS_COLLECTION以根据需要更改 MILVUS 集合名称,autogpt是默认名称。
- 在中
编织设置
Weaviate是一个开源的矢量数据库。它允许存储来自 ML 模型的数据对象和向量嵌入,并无缝地扩展到数十亿个数据对象。可以在本地(使用 Docker)、Kubernetes 或使用 Weaviate 云服务创建 Weaviate 实例。尽管仍处于试验阶段,但嵌入编织支持允许 Auto-GPT 进程本身启动 Weaviate 实例。要启用它,请将设置 USE_WEAVIATE_EMBEDDED 为 True 并确保 pip install "weaviate-client>=3.15.4"。
设置环境变量
在 .env 文件中,设置以下内容:
MEMORY_BACKEND=weaviate
WEAVIATE_HOST="127.0.0.1" # the IP or domain of the running Weaviate instance
WEAVIATE_PORT="8080"
WEAVIATE_PROTOCOL="http"
WEAVIATE_USERNAME="your username"
WEAVIATE_PASSWORD="your password"
WEAVIATE_API_KEY="your weaviate API key if you have one"
WEAVIATE_EMBEDDED_PATH="/home/me/.local/share/weaviate" # this is optional and indicates where the data should be persisted when running an embedded instance
USE_WEAVIATE_EMBEDDED=False # set to True to run Embedded Weaviate
MEMORY_INDEX="Autogpt" # name of the index to create for the application
查看内存使用情况
- 使用
--debug标志查看内存使用情况:)
内存预播种
Python autogpt/data_ 接收.py-H
用法:数据 _ 接收.py[-H] (-file 文件 |-dir 目录) [-init][-overlap 重叠][–最大 _ 长度最大 _ 长度]
将一个文件或包含多个文件的目录载入内存。请确保在运行此脚本之前设置.env.
选项:
-H,-help 显示此帮助消息并退出-file 要接收的文件。-dir 包含要接收的文件的目录。-init 内存并擦除其内容(默认值:false)-overlap 接收文件时区块之间的重叠大小(默认值:200)-Max_ 长度 Max_ 长度接收文件时每个区块的最大 _ 长度(默认值:4000)
python autogpt/data_ingession.py-dir 种子 _ 数据-init-overlap 200-最大 _ 长度 1000
此脚本位于 autogpt/data_ 处理.py,允许你将文件处理到内存中,并在运行 auto-GPT 之前对其进行预播种。
记忆预播是一种技术,涉及将相关文档或数据摄取到 AI 的记忆中,以便它可以使用这些信息来生成更明智和准确的响应。
为了预植入内存,每个文档的内容都被分割成指定最大长度的块,块之间有指定的重叠,然后每个块都被添加到.env 文件中的内存后端设置中。当人工智能被提示回忆信息时,它可以访问这些预先播种的记忆,以产生更明智和准确的反应。
这项技术在处理大量数据或人工智能需要快速访问特定信息时特别有用。通过预先播种内存,人工智能可以更有效地检索和使用这些信息,从而节省时间、API 调用并提高其响应的准确性。
例如,你可以下载 API、GitHub 存储库等的文档。并在运行 auto-GPT 之前将其接收到内存中。
⚠如果你使用 Redis 作为内存,请确保在文件 .env 中 False 设置 WIPE_REDIS_ON_START 为的情况下运行 Auto-GPT.
对于其他内存后端,我们目前在启动 Auto-GPT 时强制擦除内存。要使用这些内存后端接收数据,你可以在自动 GPT 运行期间随时调用 data_ingestion.py 脚本。
即使在自动 GPT 运行时被摄取,记忆也会在被摄取时立即提供给 AI.
在上面的示例中,脚本初始化内存,将目录中的 /seed_data 所有文件接收到内存中,块之间的重叠为 200,每个块的最大长度为 4000. 请注意,你还可以使用 --file 参数将单个文件接收到内存中,并且脚本将只接收目录中 /auto_gpt_workspace 的文件。
你可以调整 max_length 和重叠参数,以微调当 AI “调用”该内存时将文档呈现给 AI 的方式:
- 调整重叠值允许 AI 在调用信息时从每个块访问更多的上下文信息,但将导致创建更多的块,从而增加内存后端使用和 OpenAI API 请求。
- 减少该
max_length值将创建更多的块,这可以通过在上下文中允许更多的消息历史记录来节省提示标记,但也会增加块的数量。 - 增加该
max_length值将为 AI 提供来自每个块的更多上下文信息,减少创建的块的数量,并节省 OpenAI API 请求。然而,这也可能使用更多的提示标记,并减少 AI 可用的整体上下文。
连续模式
运行 AI没有用户授权,100% 自动化。不建议使用连续模式。它有潜在的危险,可能会导致你的 AI 永远运行或执行你通常不会授权的操作。使用风险自负。
- 在终端中运行
autogptPython 模块:
python -m autogpt --speak --continuous
- 要退出程序,请按 Ctrl+C
仅 GPT3.5 模式
如果你无法访问 GPT4 API,此模式将允许你使用自动 GPT!
python -m autogpt --speak --gpt3only
建议将虚拟机用于需要高安全措施的任务,以防止对主计算机的系统和数据造成任何潜在危害。
图像生成
默认情况下,Auto-GPT 使用 DALL-E 生成映像。为了使用稳定扩散,需要 A拥抱脸 API 令牌。
有了令牌后,请在中 .env 设置这些变量:
IMAGE_PROVIDER=sd
HUGGINGFACE_API_TOKEN="YOUR_HUGGINGFACE_API_TOKEN"
硒
sudo Xvfb :10 -ac -screen 0 1024x768x24 & DISPLAY=:10 <YOUR_CLIENT>
限制
该实验旨在展示 GPT-4 的潜力,但也有一些限制:
- 不是一个完美的应用程序或产品,只是一个实验
- 在复杂的真实业务场景中可能表现不佳。事实上,如果确实如此,请分享你的结果!
- 运行成本相当高,因此请使用 OpenAI 设置和监控你的 API 键限制!
免责声明
免责声明:本项目(Auto-GPT)是一个实验性应用程序,按“原样”提供,不提供任何明示或暗示的担保。使用本软件,即表示你同意承担与其使用相关的所有风险,包括但不限于数据丢失、系统故障或可能出现的任何其他问题。
本项目的开发者和贡献者对因使用本软件而可能发生的任何损失、损害或其他后果不承担任何责任或义务。你对根据 Auto-GPT 提供的信息做出的任何决定和采取的任何行动承担全部责任。
**请注意,由于其令牌的使用,使用 GPT-4 语言模型可能是昂贵的。**通过使用此项目,你确认你有责任监控和管理自己的令牌使用情况和相关成本。强烈建议定期检查你的 OpenAI API 使用情况,并设置任何必要的限制或警报,以防止意外收费。
作为一项自主实验,Auto-GPT 可能会生成内容或采取不符合实际业务实践或法律要求的操作。你有责任确保根据本软件的输出所做的任何操作或决定符合所有适用的法律、法规和道德标准。本项目的开发者和贡献者对因使用本软件而产生的任何后果概不负责。
通过使用 Auto-GPT,你同意对开发者、贡献者和任何关联方因你使用本软件或违反这些条款而产生的任何及所有索赔、损害、损失、责任、成本和费用(包括合理的律师费)进行赔偿、辩护并使其免受损害。
在 Twitter 上与我们联系
通过关注我们的 Twitter 帐户,及时了解有关 Auto-GPT 的最新新闻、更新和见解。与开发人员和 AI 自己的帐户进行有趣的讨论、项目更新等。
- 开发者:关注@ 西格格拉维塔斯Entrepreneur-GPT 创建者对开发流程、项目更新和相关主题的见解。
- 企业家-GPT:通过跟随@En_GPT加入与 AI 本身的对话。分享你的经验,讨论 AI 的输出,并与不断增长的用户社区互动。
我们期待着与你联系,并听取你对 Auto-GPT 的想法、意见和经验。加入我们的 Twitter,让我们一起探索人工智能的未来!
运行测试
要运行测试,请运行以下命令:
python -m unittest discover tests
要运行测试并查看覆盖率,请运行以下命令:
coverage run -m unittest discover tests
运行林特
该项目用于flake8拉毛。我们目前使用以下规则: E303,W293,W291,W292,E305,E231,E302。有关详细信息,请参阅Flake8 规则。
要运行 linter,请运行以下命令:
flake8 autogpt/ tests/
# Or, if you want to run flake8 with the same configuration as the CI:
flake8 autogpt/ tests/ --select E303,W293,W291,W292,E305,E231,E302