记一次视频抓包m3u8解密过程
情景:女友买的学习视频将在一个月后到期(到期后下载在本地也无法看),让我帮忙把视频下载下来,之前抓过m3u8文件下载过视频切片合成后是一个完整视频,以为这次的任务非常简单~
然鹅,查看一下app信息,已经被加固处理(伪加固)
已经加固了,暂时不考虑脱壳编译
于是开始抓包,我的安卓手机没有root,在抓取某课app时由于 检测到代理导致某课app里面没网络,之前在玩安卓逆向的时候偶然发现
部分APP可以放在容器中,通过抓取容器获得运行APP的抓包数据
也就是用把 xx 安装在 VirtualXposed 里面,黄鸟抓取VirtualXposed
VirtualXposed链接:点我
注意:这个方法只适用部分app,有的安装后会闪退
抓包部分截图:

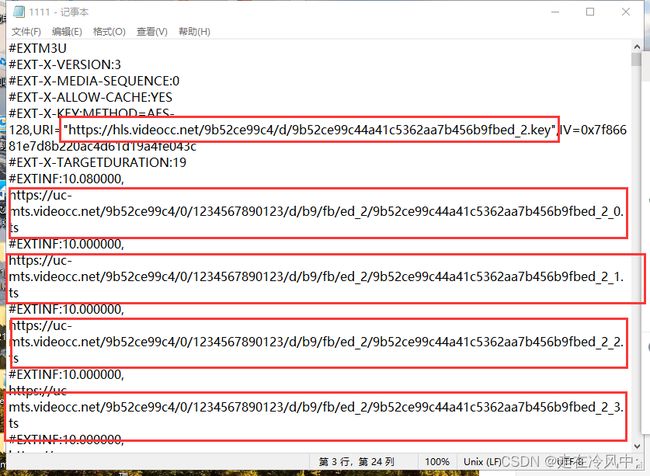
上面是抓到的m3u8信息,根据之前的到这一步应该是成功了,密钥和视频切片ts文件应该就可以合成完整视频
但是访问红色部分的key却是显示404,视频切片能下载但是无法解密
看到了一篇关于key被访问了一次就删除的博客,不得不让我猜想,是不是app客户端访问后拿下密钥文件,在app前端将下载的资源文件进行解析然后播放,既然访问了一次,我拿到的抓包数据也就是已经被访问过的了,在这里我已经将app的缓存目录看了下,乱码很多不知道密钥文件放在哪里,所以我将整个流程用python写下来了
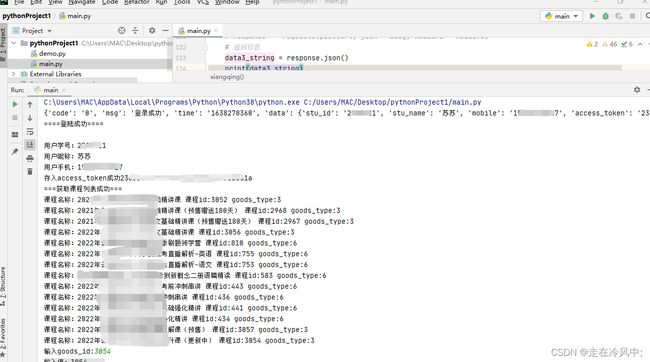
现在写到 登录->获取用户信息及token->获取所有课程->某个课程课程->视频id 编码
今晚就到这里,明天再看,目前发现拿到m3u8的链接由
https://api/userid/x/video_id.m3u8
x位置不确定,后面的did不用携带也可以
真实地址:https://hls.videocc.net/9b52ce99c4/d/9b52ce99c4df4d856f4b770a2e8112ad_2.m3u8?did=1638152451432X1376979
明天会上代码以及接口,如果对于我的个人见解有更好的意见、看法,或者新思路请评论一起交流,以上
import requests
import json
#爬取库课网课付费视频
#本人因为女友购买的付费视频即将到期,想将其下载下来,留作备份 慢慢看
def login(uuid,password):
host = "https://new6api.kuke99.com/user/login"
#
params = {
"password":password,
"mobile":'MTU5NjkxMTA5Mjc='
}
header = {
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "78",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(host, data=params,headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data_string=response.json()
print(data_string)
if(data_string['code']=='0'):
print("====登陆成功====\n")
print("用户学号:" + data_string['data']['stu_id'])
print("用户昵称:"+data_string['data']['stu_name'])
print("用户手机:" + data_string['data']['mobile'])
global access_token
access_token=data_string['data']['access_token']
print("存入access_token成功"+access_token)
return access_token
else:
print("!!!!!登录失败!!!!!!")
def refresh(uid,accessTok):
url = "https://new6api.kuke99.com/learning/learning_list"
#
params = {
"subject_id": '0',
"cate_id": '0'
}
header = {
"accessToken": accessTok,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "22",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data2_string = response.json()
# print(data2_string)
if(data2_string['code']=='0'):
print("===获取课程列表成功===")
for keys in data2_string['data']['general']:
print("课程名称:"+keys['goods_title']+" 课程id:"+keys['goods_id']+" goods_type:"+keys['goods_type'])
else:
print("获取列表失败请重新登录,建议查看password uuid 正确性")
def xiangqing(g_id,g_type,access_oken,uuid):
url = "https://new6api.kuke99.com/goods_collation/detail"
#
params = {
"goods_id": g_id,
"goods_type": g_type,
"ac_type":''
}
header = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "22",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data3_string = response.json()
print(data3_string)
#视频详情页面
def get_m3u8(video_id,access_oken,uuid):
host = "https://hls.videocc.net/9b52ce99c4/f/"+video_id+".m3u8?did=1638275844261X1898885"
print(host)
params = {
}
headers = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "25",
"Host": "hls.videocc.net",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "polyv-android-sdk2.15.3-20210520 Dalvik/2.1.0 (Linux; U; Android 9; V1814T Build/PKQ1.180819.001)"
}
cookies = {
}
r = requests.get(host, data=params)
data3_string = r.json()
print(data3_string)
def download(g_id,g_type,access_oken,uuid):
url = "https://new6api.kuke99.com/download/node_list"
#
params = {
"goods_id": g_id,
"goods_type": g_type,
}
header = {
"accessToken": access_oken,
"clientType": "3",
'version': '6.2.13',
"Referer": "https://m.kuke99.com",
"UUID": uuid,
"Content-Type": "application/x-www-form-urlencoded",
"deviceType": "V1814T",
"osVersion": "9",
"Content-Length": "25",
"Host": "new6api.kuke99.com",
"Connection": "Keep-Alive",
"Accept-Encoding": "gzip",
"User-Agent": "okhttp/4.9.1"
}
cookies = {
# "acw_tc": acw_tc
}
response = requests.post(url, data=params, headers=header)
# 也可以直接将data字段换成json字段,2.4.3版本之后支持
# response = requests.post(url, json = body, headers = headers)
# 返回信息
data3_string = response.json()
# print(data3_string)
print(data3_string['code'])
if(data3_string['code']=='0'):
for keys in data3_string['data']:
print("选中的可下载的vdieo id:"+keys['video_id'])
else:
print("获取下载信息失败")
#视频下载页面信息
if __name__ == '__main__':
UUID=''#用户识别uid
password=""#密码
login(UUID,password)#登录账号密码获取token
# print(access_token)
refresh(UUID,access_token)#读取购买所有课程信息(学习列表)
#用户手动输入数据
goods_id = input("输入goods_id:")
print('输入值:' + goods_id)
goods_type = input("goods_type:")
print('输入值:' + goods_type)
# xiangqing(goods_id,goods_type,access_token,UUID)#视频详情
download(goods_id, goods_type, access_token, UUID) # 得到下载列表
video_id = input("输入video_id:")
print('输入值:' + video_id)
get_m3u8(video_id,access_token,UUID)#获得m3u8链接