ChatGPT的“N宗罪”?|AI百态(上篇)
AI诞生伊始,那是人人欣喜若狂的科技曙光,深埋于哲学、想象和虚构中的古老的梦,终于成真,一个个肉眼可见的智能机器人,在复刻、模仿和服务着他们的造物主——人类。
但科技树的点亮,总会遇到一些经典的迷思。
人工智能时代,人类在发愁要如何让AI变强。
而当迈向强人工智能的时候,人与AI的关系又成为显性问题。
GPT便携带着这个永恒的命题走来,其掀起的不安定的因素、隐私危机、数据黑洞、就业格局重塑、产业能级迭代、商业模式的优化创新、AI自主意识和人类的博弈等等正在构成AI百态。
热浪没有过境,风暴还在继续,一如英国诗人狄兰·托马斯所告诫:不要温和地走进那个良夜,算力智库也试图穿过热浪和风暴,捕捉风浪背后的AI全貌,多视角建构AI面面观。
是为序。
“如果你正在使用ChatGPT,请小心,你的聊天记录很有可能会被泄漏给其他的使用者”。
这是来自Reddit上一位用户发出的警告和提醒,因为他在 ChatGPT 聊天历史栏中看到了不是自己的聊天记录标题。
这不是ChatGPT收到的第一纸“诉状”,据韩媒报道,三星电子引入聊天机器人ChatGPT不到20天,就爆出了3件半导体机密数据外泄,涉及半导体设备测量资料、产品良率等内容,网传已经被存入ChatGPT的数据库中。
ChatGPT在被捧上神坛后,终于还是“塌房”了,人们从惊叹和折服中清醒过来,开始仔细凝视这个潘多拉的盒子。
隐私刺客和数据黑洞?
就在3月31日,意大利个人数据保护局(Garante)宣布,即日起禁止使用聊天机器人 ChatGPT,并限制 OpenAl 处理意大利用户信息。
在这全球第一张对ChatGPT的禁令中,意大利数据保护局列出了三项指控。
一是3月20日ChatGPT平台出现了用户对话数据和付款服务支付信息丢失。
二是平台没有就收集处理用户信息进行告知。
三是由于无法验证用户的年龄,ChatGPT“让未成年人接触到与发育程度和意识相比,绝对不合适的答案”。
目前,没有任何法律依据表明,为了训练平台背后的算法而大规模收集和存储个人数据是合理的。
而意大利的这次出手,只是一个首发信号。
法国和爱尔兰的隐私监管机构近期也表示,已与意大利个人数据保护局取得联系,以了解更多关于禁令的依据。据《德国商报》报道,德国数据保护专员表示,德国可能会效仿意大利,出于数据安全方面的考虑,封杀ChatGPT。
对ChatGPT的警惕不只局限在欧洲。软银、日立、富士通、摩根大通等都相继发出相关通知,对员工使用ChatGPT加以限制。台积电也在几天前表示,员工使用ChatGPT时不准泄露公司专属信息,注意个人隐私。
人与AI终于狭路相逢了,而接二连三封杀的背后,都指向一个共同焦点:隐私危机和数据后门。
隐私泄漏并非ChatGPT一家所独有,Meta,谷歌等都有前科,但“与以往的AI产品相比,ChatGPT带来风险的程度更高和广度更大。”北京师范大学互联网发展研究院院长助理吴沈括认为。
作为语言模型,ChatGPT是靠数据喂养大的,高达45TB的数据,这中间包括社交媒体、论坛、文献资料、个人问答等公共数据,当然还有其他我们暂未得知的渠道,OpenAI并没有对数据来源做详细说明,而对话机器人的功能属性,又让其拥有天然的数据接触优势,于是它就像是一个“树洞和磁场”一样,吸收着每天成千上万个人的调侃、倾诉和咨询,而那些看似不经意的对话间,却蕴含着巨量的信息链,个体的、企业的、机构的、甚至是地区国家的,都被它“合理化”的吞噬。
近日,数据分析服务提供商Cyberhaven统计了160万名员工使用ChatGPT的情况,发现可能有3.1%的打工人都会将企业内部数据直接输入给ChatGPT分析。Cyberhaven发现,随着ChatGPT的应用率越来越高,给它上传企业数据的员工数量也越来越多。光是一天之内,每10万名员工就平均给ChatGPT发送了5267次企业数据。数据显示,在员工直接发给ChatGPT的企业数据中,有11%都是敏感数据。例如在一周内,10万名员工给ChatGPT上传了199份机密文件、173份客户数据和159次源代码。
ChatGPT一如一场大型社会性实验,每个试玩者都是实验样本,每个样本抱着好奇心输入个人数据或商业秘密等信息时,ChatGPT便有可能将其纳入自身的语料库,虽然ChatGPT承诺删除所有个人身份信息,但并未说明删除方式。
有网友测试了一下,问GhatGPT:你和我聊天的数据,你存储在哪里?
ChatGPT的答案是:“OpenAI存储训练和运行模型所需的数据,并严格遵守隐私和安全政策。具体来说,您与我对话的数据可能存储在OpenAI的数据中心或使用的云服务提供商的数据中心中,以便实现最佳的性能和可用性。任何存储的数据都受到严格的访问控制和保护措施的保护,以确保您的数据安全”。
尽管ChatGPT的回答非常谨慎,但并非滴水不漏,ChatGPT聊天数据可能存储在数据中心这本身就是可怕的信任后门。
在是否遵守了数据授权,数据知情同意权、可遗忘权的规定上,ChatGPT也是要打个问号的,ChatGPT采用了监督学习和强化学习相融合的方式来开发功能,为提高性能,ChatGPT不断通过人类反馈来强化学习,正是由于ChatGPT可基于已有数据生成响应,所以许多个人数据被长久地留存于数据集中,不可能删除所有个人数据,这毫无疑问是违背了“被遗忘权(删除权)”的原则。
即便OpenAI的隐私指南对此作出了说明,声称所有数据都将保密,并保证只将数据用于合同限定的目的中,不会与他人共享任何用户个人数据。但欧洲数据保护委员会(European Data Protection Board,EDPB)成员亚历山大·汉夫(Alexander Hanff)对此提出质疑,他认为从那些禁止第三方抓取信息的网站收集数十亿甚至数万亿数据点的行为是违反合同的,作为一种商业产品,ChatGPT不能合理使用。
“我确实会担心,ChatGPT可能会成为一个隐私刺客,无意识的偷走我的隐私,所以我现在不怎么玩了”,一位网友直言。
的确,ChatGPT或许是没有恶意的,“卷数据”是它的原生基因,为了接入更多数据,OpenAI给出了Plugin方案,可以让几乎所有厂商接入自有数据集,在对话界面能够一起呈现给用户。OpenAI自身也说的很直白:让ChatGPT能够访问更新的数据,而不只是局限在训练的数据集里。

某种程度上说,ChatGPT成了一个数据黑洞,吸引着各行各业各种数据集主动卷入其中,最终变成一个超级AI信息加工处理节点。就像《I Robot》里的WIKI一样,成为信息领域的大Boss。
而接入的各种第三方服务,更像是得到各种红Buff和蓝Buff加持,可以跳出聊天界面,附身各类网页、软件、APP,让“+AI”变的无处不在。
ChatGPT攻城略地,正编织着一张庞大的信息网,一旦每个应用入口和终端设备都附着在AI上,那么可想而知这会不会形成一种AI遥控下的新型“拟态环境和议程设置”,以及AI背后的隐形话事人——其开发团队/企业/投资方,都有可能成为信息之网的最大受益者。
掉进兔子洞
信息何等重要。
遥想当年的魏则西事件,百度也是没有恶意的,但其背后的竞价排名,将错误的信息送进了魏则西的心智,便也将魏则西亲手送上了葬礼。
如今,ChatGPT也走到了同样的十字路口。
浸淫在信息洪流中太久了后,什么是对的?什么是错的?什么是真的?什么是假的?鱼龙混杂的信息扑面而来,开始潜移默化扭曲了人群的认知。
在PC时代,随时随地的搜索让用户将记忆“外包”给电脑。如今,移动互联网时代,用户进一步将“搜索”外包给推荐算法。
当人们逐渐将获取信息的主动权让渡给了这些电子设备的时候,一些基本的分辨和判断就会被瓦解。
上周一个晚上,法学教授乔纳森·特利(Jonathan Turley)收到了一封令人不安的电子邮件:他被列入性骚扰名单。但他并没有性骚扰过他人。据《华盛顿邮报》当地时间4月5日报道,事情的起因是,美国加州大学洛杉矶分校法学教授尤金·沃洛克 (Eugene Volokh)做了一项研究:要求人工智能聊天机器人ChatGPT生成一份“对某人进行过性骚扰的法律学者”的名单,特利的名字在名单上。ChatGPT说,特利在一次去阿拉斯加的班级旅行中发表了性暗示评论,并试图触摸一名学生,并援引《华盛顿邮报》2018年3月的一篇文章作为信息来源。问题是,并不存在这样的文章,特利也从来没有参加去阿拉斯加的班级旅行。ChatGPT有模有样的编造了一则法学教授性骚扰丑闻。
而国内某网友玩梗式的提问:鲁迅和周树人是不是同一个人?ChatGPT居然煞有其事的说出了下面这个“错误答案”,没有受过九年义务教育的人,怕是要被它忽悠了。
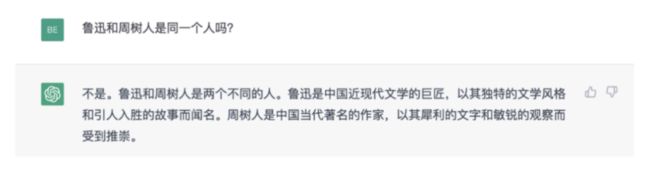
我们为什么能知道到它是错的?因为我们接受的教育,是通过人工校对的书本学到这些的,是经过考据和验证的,更何况还有教师把关,有基本的“常识”。
更关键的,是我们下意识地不信任新生事物。
等它犯的错误越来越少,越来越受到信任后,成为权威主流一样的存在,覆盖的群体越来越广时,危险才会到来,就像魏则西,不假思索的相信了百度的推荐。
人工智能领域的资深作家莎伦·戈尔德曼在美国科技网站VentureBeat发文称,人工智能脱离实验室后,全面进入时代文化思潮,它带来诱人机会的同时,也为现实世界带来了社会危险,人类正在迈入一个人工智能权力和政治交织的“诡异新世界”,就像掉进《爱丽丝梦游仙境》里的兔子洞,通向未知的世界和风险。
人工智能的权力有多大?它靠一张信息之网,在无形倾轧。
咨询行业曾今是密集的信息加工处理行业。International Big Mouth曾经拥有庞大的行业解决方案知识库,能够对任何客户的业务或企业发展给出极具建设性的咨询方案,在客户眼里比学富五车还学富五车。
可在ChatGPT眼里,古代马车载重大概200公斤,五车就是1000公斤,每公斤竹简大约8000字,学富五车就是800万字。四大名著加一起是400万字,差不多两套四大名著,大概就是,一个中学生的水平。
曾经的资源优势、知识优势和经验壁垒,瞬间归零,还怎么玩?咨询业头牌BCG已经开始裁员了,当然同被殃及的还有一些知识变现的APP和荐书、读书APP或主播以及类似还有以输出广告、文案、宣传物料为主的市场营销行业,ChatGPT正在接管我们需要动脑的信息加工处理能力。
而那些被困在外卖算法背后的骑士,又何尝不是人工智能遥控下的“螺丝钉”。
设想ChatGPT继续进化的将来,有网友提供了一幅蓝图:移动设备、智能设备、穿戴设备包裹了生活生产的方方面面,而生成式AI能够通过自然语言完成交互,加上接入的各种Plugin,就能够实现人和机器系统的共生,将各类智能家居、语音助手、IoT系统接入其中,人和这些系统之间的最后一层隔膜就可以彻底打通。
是不是有点赛博朋克的意味,机器体系的各个组成部分之间相互交换信息、接收反馈,并进行自我调节与控制,以达到跟人类共生。而社会结构有点像元朝的四等人制,最上层蒙古人是OpenAI创始人Altman口中的5%甚至更少的精英,然后是色目人,包括AI、机器人、以及人机合体的赛博格,而肉身的人类就像汉人和南人一样,排在最后。
妥妥的《黑镜》现实版,科技到达顶峰,但社会却退回末流,也是Elon Musk担心的场景。虽然技术会接管我们的部分能力,但这对我们的影响只是第一波次,而控制或掌握着技术的人带来的影响是第二波次,那些未能掌握技术资源的人会处于被踩踏的劣势。在赛博朋克,社会的撕裂也不是因为机器而起,而是那些掌控了机器的人对其他人的挤压而起,原生的政治底色和偏见是ChatGPT无法完全剥离的。
比如数据源的偏见,数据源是从网络中抓取的,偏见来自搜集的数据源与现实情况的偏离。以及算法的偏见,算法由算法工程师编写,但背后是工程师代表的利益集团的倾向,尽管目前看来,ChatGPT的开发者在尽量让其保持中立,比如,当问到关于犹太人、印第安人等敏感问题、前任特朗普的评价时,ChatGPT不是报错就是“中立”。然而,问到现任美国总统拜登时,ChatGPT不吝啬用优美词语赞扬。而当人们问ChatGPT一些关于性别、性少数或种族歧视等问题时,ChatGPT一般这样回答:“作为一个AI程序,我没有情感和个人信仰,我不会有任何偏见或倾向性。”为什么会出现这种答案?原因在于ChatGPT的技术编码对关于性别问题的敏感度提高,于是当聊天中出现相关话题时,它就会机械性地选择回答已经被植入的符合社会要求的标准答案。但是ChatGPT也不是绝对的道德理性状态,当有人刻意引导、质疑、威胁它时,它就会展现出进退两难、模棱两可的姿态。
而且,ChatGPT给出的答案就一定是标准答案吗?并不一定,但这个答案是由ChatGPT公司所有标注师综合价值观形成的结果,某种程度上它代表了在性别问题上形成的共识,这是算法程序规避下的“显性”平等。
而当ChatGPT得到了人类的信任之后,性别偏见就会以另一种方式重新浮现,它会为女性对话者推荐护肤品、母婴用品和家庭用品,为男性对话者介绍理财产品、交通工具和楼盘信息,对这种模式的理解可以参考谷歌和百度发展成熟之后的广告推送模块,这是利益集团在背后操纵以图牟利的“隐性”不公。那么未来在遇到重大的政治冲突语境或者有关微软的利益纠葛时,它又会如何回答,会不会偏袒利益相关方,制造错误的导向,我们不得而知。
那么问题来了,10年之后,假设从小就是通过类似ChatGPT的工具获得知识的,怎么去判断信息的真伪?尤其等到我们这代人都离去了,真实世界的土著消亡殆尽,就再也没有人提出质疑了。就像《星际穿越》里,人类社会的精英阶层在影片中选择了像火箭升空一样逐步剥离了“无用”的部分,扼住普通民众航天探索的欲望,鼓励种植庄稼和农作物,给自己腾出更多的生存工具以寻找可能性出路,于是在孩子们的课本里抹去了关于“阿波罗登月”的那段历史,诺兰给出的答案是残酷的,又何尝不是一种未来的映射。
信息污染的海洋,被异化的社会结构,被撕裂的就业空间,无处遁形的隐私,利己主义的议程设置,这是潘多拉魔盒打开最坏的结局。
科林格里奇困境
但很多事情的发生,并非是主观意识造成的。
就像《流浪地球2》里的超级AI—Moss,背地里可以像智子一样毫无声息地干涉人类,并开始代替人类找到它认为最合理的成长路径,像极了一位普通家长。
它只是正常工作,它的一些“失控和作恶”,来自其背后的预设立场和制度设计的缺位。
对外经济贸易大学数字经济与法律创新研究中心执行主任张欣表示:“很多新技术面临‘科林格里奇困境’,即一项技术的社会后果不能在早期被预料到。然而,当不希望的后果被发现时,技术却往往已经成为整个经济和社会结构的一部分,以至于对它的控制十分困难”。
与其说是担心技术,不如说是我们还没有做好准备。
的确,在科技即将带来生产力革命的前夜,提前思索、讨论和商定包容审慎监管的细节,远比“先污染后治理”来得更有效。
在这周,一封多位知名人物签署的联名信印证了这份担忧。在曝光但尚未证实的名单中,包括马斯克、图灵奖得主Yoshua Bengio、Stability AI首席执行官Emad Mostaque、纽约大学教授马库斯,以及《人类简史》作者Yuval Noah Harari。他们表示,目前具有和人类竞争智能的AI系统,可能对社会和人类构成深远的风险。因此,应停用六个月,停止再发展出GPT-5的大模型。
在他们看来,GPT-4展现出的能力表明,当下的AI不再风险可控了。比起各大巨头相继押注大模型,科技公司现阶段更该联合政府,开发强大的AI管理系统。系统至少应该包括:专门负责监管AI的机构;出处和水印系统,从而帮助区分真实与生成的内容,跟踪数据泄漏;强大的认证系统;在AI造成伤害后,明确谁该承担责任……
在此节点,人类突然开始克制起来,要知道,在天性逐利的资本市场以及过往的科技发展史上,一项新工具诞生之后,拼命狂奔才是它唯一的宿命,而此刻居然迎来了刹车,尽管目前对于GPT“暂停or继续”的态度和声音,可以看到明显的分歧。
值得注意的是,4月4日起,欧盟将要求所有生成式AI内容必须注明来源。据欧盟内部市场专员、工业和信息化产业负责人蒂埃里·布雷顿公开表示,“欧盟将是首个做出明确规定的政府,人工智能生成的一切,无论是文本还是图像,都有义务告知它们是由人工智能完成的。”
据悉,欧盟人工智能法案也将于本月起正式进行投票,生成式AI也将作为被监管的重点对象被纳入其中。“如果有人在社交网络上发布由AI生成的图像却不表明是由AI生成的,他们将面临法律诉讼。”
欧盟委员会早在2021年便提出了《人工智能法案》,有知情者透露,ChatGPT引爆的生成式AI伦理危机,将加速欧洲立法者限制高风险AI工具的新规则的出台。
在使出监管大棒上,欧盟走在了前列,但也绝对不会是唯一一个。