JDBC概述
概述
JDBC(Java DataBase Connectivity)是一种用于执行SQL语句的Java API,是Java和数据库之间的一个桥梁,是一个规范而不是一个实现,能够交给数据库执行SQL语句。
它由一组用Java语言编写的类和接口组成。各种不同类型的数据库都有相应的实现,JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。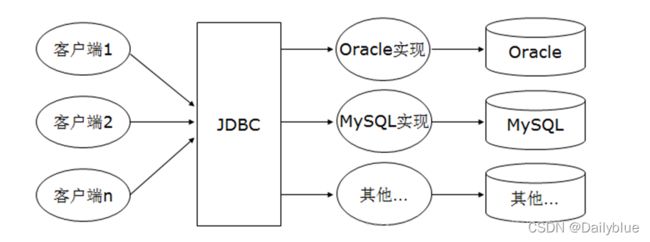
JDBC的组成
JDBC是由一组用Java语言编写的类和接口组成,主要有如下几个部分
- 驱动管理
- Connection接口
- Statement接口
- Statement:由createStatement创建,用于发送简单的SQL语句(不带参数)。
- PreparedStatement :继承自Statement接口,可发送含有参数的SQL语句。效率更高,并且可以防止SQL注入,建议使用。
- CallableStatement:继承自PreparedStatement接口,由方法prepareCall创建,用于调用存储过程。
- ResultSet接口
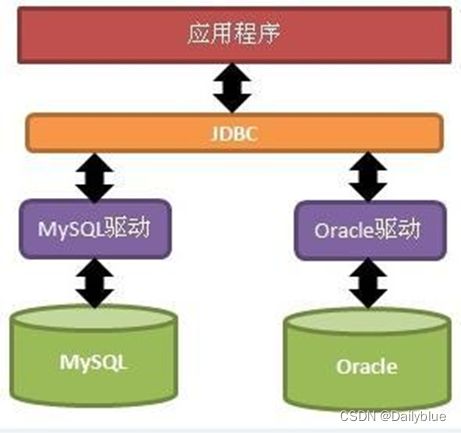
Connection接口
Jdbc程序中的Connection,它用于代表数据库的链接,Collection是数据库编程中最重要的一个对象,客户端与数据库所有交互都是通过connection对象完成的,创建方法为:
String url = "jdbc:mysql://localhost:3306/guanwei?
serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true";
String user = "guanwei";
String password = "guanwei";
Connection conn = DriverManager.getConnection(url, user, password);常见方法:
| 方法 |
描述 |
| createStatement() |
创建向数据库发送sql的statement对象。 |
| prepareStatement(sql) |
创建向数据库发送预编译sql的PrepareSatement对象。 |
| prepareCall(sql) |
创建执行存储过程的callableStatement对象。 |
| setAutoCommit(boolean autoCommit) |
设置事务是否自动提交。 |
| commit() |
在链接上提交事务。 |
| rollback() |
在此链接上回滚事务。 |
Statement接口
Jdbc程序中的Statement对象用于向数据库发送SQL语句,创建方法为:
Statement st = conn.createStatement();常见方法:
| 方法 |
含义 |
| executeQuery(String sql) |
用于向数据发送查询语句。 |
| executeUpdate(String sql) |
用于向数据库发送insert、update或delete语句 |
| execute(String sql) |
用于向数据库发送任意sql语句 |
| addBatch(String sql) |
把多条sql语句放到一个批处理中。 |
| executeBatch() |
向数据库发送一批sql语句执行。 |
PreperedStatement接口
PreperedStatement是Statement的子类,它的实例对象可以通过调用:
PreperedStatement st = conn.preparedStatement(sql);相比较父类,有如下优势:
- Statement会使数据库频繁编译SQL,可能造成数据库缓冲区溢出。PreparedStatement 可对SQL进行预编译,从而提高数据库的执行效率。
- 并且PreperedStatement对于sql中的参数,允许使用占位符的形式进行替换,简化sql语句的编写,可以避免SQL注入的问题。
ResultSet接口
Jdbc程序中的ResultSet用于代表Sql语句的执行结果。
Resultset封装执行结果时,采用的类似于表格的方式,ResultSet 对象维护了一个指向表格数据行的游标,初始的时候,游标在第一行之前,调用ResultSet.next() 方法,可以使游标指向具体的数据行,进行调用方法获取该行的数据。
常用方法是:
| 方法 |
含义 |
| next() |
移动到下一行。 |
| Previous() |
移动到前一行。 |
| absolute(int row) |
移动到指定行。 |
| beforeFirst() |
移动resultSet的最前面。 |
| afterLast() |
移动到resultSet的最后面。 |
面向过程的实现方式
1.在pom.xml中引入mysql的驱动文件
mysql
mysql-connector-java
8.0.28
2.加载驱动类
// Driver类是下载下来的jar中所带的类
Class.forName("com.mysql.cj.jdbc.Driver");3.建立Java同数据库中间的连接通道
String url = "jdbc:mysql://localhost:3306/guanwei?
serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true";
String user = "guanwei";
String password = "guanwei";
Connection conn = DriverManager.getConnection(url, user, password);4.产生负责'传递命令'的‘传令官’对象
String sql = "select * from emp where empState=1";
PreparedStatement ps = conn.prepareStatement(sql);5.接收结果集(只有查询有结果集)
ResultSet rs = ps.executeQuery();
while (rs.next()) { // 判断是否是空 并移动到下一行
// 这里可以通过columnIndex和columnLable来获取当前列的内容
int a = rs.getInt(1);
String b = rs.getString("ename");
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString("hireDate");
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
}6.关闭连接通道
rs.close();//查询有关闭,更新没有
ps.close();
conn.close();SQL语句中参数传递问题
拼接SQL方式传递
简单的说,就是通过字符串之间的拼接来产生一个符合要求的SQL语句
String sql = "insert into emp values(null,'" + name + "','" + job +
"','" + mgr + "',now()," + sal + "," + comm + "," + deptNo + ",1)";需要注意的是:拼接方式在传递字符串内容时不要忘记''
占位符方式传递
在SQL语句中以?来代表此位置有参数,在执行SQL之前需要给?号赋值
String sql = "insert into emp values(null,?,?,?,now(),?,?,?,1)";
PreparedStatement ps = conn.prepareStatement(sql);
// 在ps对象产生之后,执行之前 给SQL语句中的?(占位符)赋值
ps.setString(1, name);
ps.setString(2, job);
ps.setInt(3, mgr);
ps.setDouble(4, sal);
ps.setDouble(5, comm);
ps.setInt(6, deptNo);
// 执行SQL语句
ps.executeUpdate();使用占位符方式好处有:
- 可以有效避免SQL注入问题
- 自动根据赋值时的数据类型来决定是否引入''
面向对象JDBC方式
面向过程开发中JDBC时比较好理解,但是实际应用后发现重复代码过多,不符合Java“一次编写,多次运行”的原则,我下来将根据功能拆分成多个包来实现对数据库的CRUD操作
db包
db包中只需要一个类---DBManager(也有叫做JDBCUtil),这个类的主要作用就是负责管理数据库的连接
//负责连接和关闭数据库
public class DBManager {
/**
* 获取到数据库的连接
* user:root
* passwd:guanwei
* 数据库:test
* @return 数据库的连接conn
*/
public static Connection getConnection(){
Connection conn = null;
try{
Class.forName("com.mysql.cj.jdbc.Driver");
String url ="jdbc:mysql://localhost:3306/test?serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true";
String user = "root";
String password = "guanwei";
conn = DriverManager.getConnection(url,user,password);
}catch(ClassNotFoundException e){
System.out.println("没有找到驱动类!");
}catch(SQLException e){
System.out.println(e.getMessage());
}
return conn;
}
public static void close(Connection conn, PreparedStatement ps, ResultSet rs){
try{
if (rs!=null){
rs.close();
}
ps.close();
conn.close();
}catch(SQLException e){
System.out.println(e.getMessage());
}
}
}bean包
一般和数据库中的表对应,bean包中的类一般都和表名相同,首字母大写,驼峰。
import java.io.Serializable;
// 模拟数据库中的一张表(emp)
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp implements Serializable {
private Integer empNo;
private String ename;
private String job;
private Integer mgr;
private String hireDate;
private Double sal;
private Double comm;
private Integer deptNo;
private Integer empState;
}dao包
DAO是Data Access Object数据访问接口,顾名思义就是与数据库打交道。夹在业务逻辑与数据库资源中间。一般以bean包的类名为前缀,以DAO结尾,负责执行CRUD操作,一个dao类负责一个表的CRUD,也可以说成是对一个bean类的CRUD(增删改查)。
在核心J2EE模式中是这样介绍DAO模式的:为了建立一个健壮的J2EE应用,应该将所有对数据源的访问操作抽象封装在一个公共API中。
// 对emp表进行CRUD DAO:Data Access Object
public class EmpDAO {
private Connection conn;
private PreparedStatement ps;
private ResultSet rs;
public void save(Emp emp) {
String sql = "insert into emp values(null,?,?,?,now(),?,?,?,1)";
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
ps.setString(1, emp.getEname());
ps.setString(2, emp.getJob());
ps.setInt(3, emp.getMgr());
ps.setDouble(4, emp.getSal());
ps.setDouble(5, emp.getComm());
ps.setInt(6, emp.getDeptNo());
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
DBManager.close(conn, ps);
}
}
public void update(Emp emp) {
String sql = "update emp set ename=?,job=?,mgr=?,sal=?,comm=?,deptno=? where empno=?";
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
ps.setString(1, emp.getEname());
ps.setString(2, emp.getJob());
ps.setInt(3, emp.getMgr());
ps.setDouble(4, emp.getSal());
ps.setDouble(5, emp.getComm());
ps.setInt(6, emp.getDeptNo());
ps.setInt(7, emp.getEmpNo());
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
DBManager.close(conn, ps);
}
}
// 一般对于删除操作,都是进行更新状态将之隐藏
public void delete(int empNo) {
String sql = "update emp set empState=0 where empNo=" + empNo;
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
DBManager.close(conn, ps);
}
}
public List findAll() {
List list = new ArrayList<>();
String sql = "select * from emp where empState = 1";
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
while (rs.next()) {
int a = rs.getInt(1);
String b = rs.getString("ename");
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString("hireDate");
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
Emp emp = new Emp(a, b, c, d, e, f, g, h, i);
list.add(emp);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
DBManager.close(conn, ps, rs);
}
return list;
}
public Emp findById(int id) {
String sql = "select * from emp where empState=1 and empNo=" + id;
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
int a = rs.getInt(1);
String b = rs.getString("ename");
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString("hireDate");
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
Emp emp = new Emp(a, b, c, d, e, f, g, h, i);
return emp;
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
}
return null;
}
public List findByEname(String ename) {
List list = new ArrayList<>();
String sql = "select * from emp where empState = 1 and ename like ?";
conn = DBManager.getConnection();
try {
ps = conn.prepareStatement(sql);
ps.setString(1, "%" + ename + "%");
rs = ps.executeQuery();
while (rs.next()) {
int a = rs.getInt(1);
String b = rs.getString("ename");
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString("hireDate");
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
Emp emp = new Emp(a, b, c, d, e, f, g, h, i);
list.add(emp);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
DBManager.close(conn, ps, rs);
}
return list;
}
}
数据库连接池
在使用开发基于数据库的JDBC操作时,传统的模式基本是按如下步骤:
- 产生Connection对象,建立和数据库的连接
- 执行dao层的对应CRUD方法
- 使用完毕后,断开数据库连接
普通的JDBC连接使用DriverManager来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,再验证用户名和密码,这样会消耗一定的时间。当需要连接数据库时,就要获取一个Connection,执行完成后再断开连接。
这样的方式将会消耗大量的资源和时间,数据库的连接资源并没有得到很好的重复利用。若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
对于每一次连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。
开发这种无法控制连接对象数量的方式,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。
概述
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用,它允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
而连接的建立、断开都由连接池自身来管理。
同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
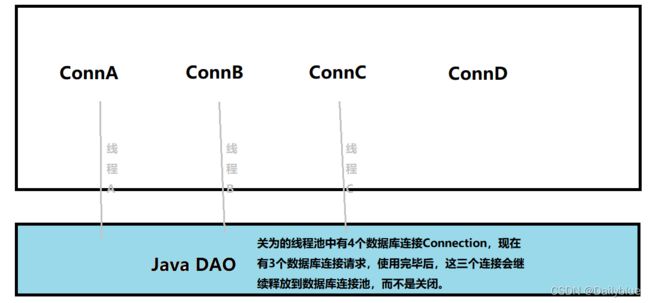
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
基本概念
1. 最小连接数
是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费。
2. 最大连接数
是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之后的数据库操作。
3. 最小连接数与最大连接数差距
最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
Druid(德鲁伊)数据库连接池
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、Proxool等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池,可以说是目前最好的连接池之一。
1.引入jar包
com.alibaba
druid
1.2.1
2.通过数据源获取Connection对象
// 通过阿里的Druid连接数据库的方式
public static Connection getConnection() throws Exception {
// 创建一个读取properties文件的类
Properties properties = new Properties();
// 通过类加载器的方法读取这个文件
InputStream in = DBManager.class.getClassLoader().getResourceAsStream("druid.properties");
// 加载这个文件
properties.load(in);
// 产生一个数据源
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
Connection conn = dataSource.getConnection();
return conn;
}3.编写配置文件
# 基本配置
url=jdbc:mysql://localhost:3306/test?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true
username=root
password=guanwei
driverClassName=com.mysql.cj.jdbc.Driver
# 连接池其他选项
initialSize=10
maxActive=10
maxWait=2000多表联查
在实际应用中我们不仅仅使用一张表的查询情况,更多的是需要多张表的数据。以Oracle提供的emp、dept表为例。这里关为带给您两种从多张表获取数据的方式。
组装方式
分别查询EmpDAO和DeptDAO的数据,在通过service层将这些数据进行组装,这样做的好处是有效避免了表连接后的笛卡尔积,缺点也很明显,多次连接数据库是需要消耗时间。话不多说,上代码。
1.通过EmpDAO的findById(empNo)获取到员工信息
public Emp findById(int empNo) {
conn = DBManager.getConnection();
String sql = "select * from emp where empNo = " + empNo;
try {
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
int a = rs.getInt(1);
String b = rs.getString(2);
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString(5);
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
// 只负责员工信息
Emp emp = new Emp(a, b, c, d, e, f, g, h, i, null);
return emp;
}
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}2.通过DeptDAO的findById(deptNo)获取到部门信息
// 只负责查询部门信息
public Dept findDeptById(int deptNo) {
String sql = "select * from dept where deptNo=" + deptNo;
conn = DBManager.getConnection();
try {
ps =conn.prepareStatement(sql);
rs = ps.executeQuery();
if(rs.next()){
int a = rs.getInt(1);
String b = rs.getString(2);
String c = rs.getString(3);
return new Dept(a,b,c);
}
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}3.通过EmpService的findById(empNo)将两次查询的结果组装到一起。
public Emp findById1(int empNo) {
// 只有员工内容 没有部门内容
Emp emp = edao.findById1(empNo);
if (emp == null) {
return null;
}
// 查询出来了部门信息
Dept dept = ddao.findDeptById(emp.getDeptNo());
emp.setDept(dept);
return emp;
}这种方式就好比与早上我们要吃早餐,你要让关为去给你买豆浆包子,但是在一家小店中只有包子,另一家点只有豆浆,关为就需要跑2次分别购买,然后在一起给你打包送回来。
表连接方式
为了给你买包子,关为需要分别去两个不同的店面进行购买,太累人了,而有的店面这两种商品都有(只不过贵了些),这两天突然发现家里有矿(法律规定,水资源也是矿物质),那么下来我们使用表连接方式来完成多表信息获取。
在EmpDAO中通过表连接直接获取多表信息
public Emp findById(int id) {
String sql = "select * from emp e,dept d "
+ "where e.deptno=d.DEPTNO and empno=" + id;
conn = DBManager.getConnection();
ps = conn.prepareStatement(sql);
rs = ps.executeQuery();
if (rs.next()) {
int a = rs.getInt(1);
String b = rs.getString("ename");
String c = rs.getString(3);
int d = rs.getInt(4);
String e = rs.getString("hireDate");
double f = rs.getDouble(6);
double g = rs.getDouble(7);
int h = rs.getInt(8);
int i = rs.getInt(9);
Dept dept = new Dept();
dept.setDeptNo(rs.getInt(10));
dept.setDname(rs.getString(11));
dept.setLoc(rs.getString(12));
return new Emp(a, b, c, d, e, f, g, h, i, dept);
}
}这种方式虽说依次查询就可以了,但众所周知的是,多表联查会存在笛卡尔积情况。