Java 输入输出流
应用程序经常需要访问文件和目录,读取文件信息或写入信息到文件,即从外界输入数据或者向外界传输数据,这些数据可以保存在磁盘文件、内存或其他程序中。在Java中,对这些数据的操作是通过 I/O 技术来实现的。所谓 I/O 技术,就是数据的输入(Input)、输出(Output)技术。
IO流概述
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输成为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。输入流和输出的读取和写入流程如图所示。

IO 流的分类
- 根据处理数据类型的不同分为:字符流和字节流。
- 根据数据流向不同分为:输入流和输出流。
- 根据同数据源之间的直接关系分为:节点流和处理流。
IO 流的体系结构

Java.io 包中的最重要的部分是由6个类和1个接口组成。6个类是指 File、RandomAccessFile、InputStream、OutputStream、Writer、Reader,1个接口指的是 Serializable。掌握了这些 I/O 的核心操作,那么对于Java 中的 I/O 体系也就有了一个初步的认识了。
总体上看,Java I/O 主要包括如下3个部分:
- 流式部分:I/O 的主体部分。
- 非流式部分:主要包含一些辅助流式部分的类,如 File 类、RandomAccessFile 类和 FileDescriptor 类等。
- 其他类:主要是文件读取部分的与安全相关的类(如 SerializablePermission 类),以及与本地操作系统相关的文件系统的类,如(FileSystem 类、Win32FileSystem 类和 WinNTFileSystem 类)。
这里,将 Java I/O 中主要的类简单介绍如下:
- File类:用于文件或者目录的描述信息等,如生成新目录、修改文件名、删除文件、判断文件所在路径等。
- InputStream类:基于字节输入操作的抽象类,是所有字节输入流的父类,定义了所有输入流都具有的共同特征。
- OutputStream类:基于字节输出操作的抽象类,是所有字节输出流的父类,定义了所有输出流都具有的共同特征。
- Reader类:抽象类,基于字符的输入操作。
- Writer类:抽象类,基于字符的输出操作。
- RandomAccessFile类:随机文件操作类,它的功能丰富,可以从文件的任意位置进行输入输出操作。
File 类
File 类可以用于处理文件和目录。在对一个文件进行输入/输出,必须先获取有关该文件的基本信息,如文件是否可以读取、能否被写入、路径是什么等。java.io.File 类不属于 Java 流系统,但它是文件流进行文件操作的辅助类,提供了获取文件基本信息以及操作文件的一些方法,通过调用 File 类提供的相应方法,能够完成创建文件、删除文件以及对目录的一些操作。
构造方法
File 类的对象是一个“文件或目录”的抽象,它并不打开文件或目录,而是指定要操作的文件或目录。File 类的对象一旦创建,就不能再修改。要创建一个新的 File 对象,需要使用它的构造方法,一般我们使用如下三种构造方法创建 File 类对象。
| 构造方法 | 功能描述 |
|---|---|
| public File(String filename) | 创建 File 对象,filename 表示文件或目录的路径。 |
| public File(String parent,String child) | 创建 File 对象,parent 表示上级目录,child 表示指定的子目录或文件名。 |
| public File(File obj,String child) | 创建 File 对象,obj 表示 File 对象,child 表示指定的子目录或文件名。 |
需要注意的是:创建出来的 File 类对象只是代表文件或目录的抽象表示,并不代表这个文件或者目录一定存在。
常用方法
创建 File 类的对象后,就可以使用 File 的相关方法来获取文件信息。
| Modifier and Type | Method and Description |
|---|---|
boolean |
canExecute() Tests whether the application can execute the file denoted by this abstract pathname. |
boolean |
canRead() Tests whether the application can read the file denoted by this abstract pathname. |
boolean |
canWrite() Tests whether the application can modify the file denoted by this abstract pathname. |
int |
compareTo(File pathname) Compares two abstract pathnames lexicographically. |
boolean |
createNewFile() Atomically creates a new, empty file named by this abstract pathname if and only if a file with this name does not yet exist. |
static File |
createTempFile(String prefix, String suffix) Creates an empty file in the default temporary-file directory, using the given prefix and suffix to generate its name. |
static File |
createTempFile(String prefix, String suffix, File directory) Creates a new empty file in the specified directory, using the given prefix and suffix strings to generate its name. |
boolean |
delete() Deletes the file or directory denoted by this abstract pathname. |
void |
deleteOnExit() Requests that the file or directory denoted by this abstract pathname be deleted when the virtual machine terminates. |
boolean |
equals(Object obj) Tests this abstract pathname for equality with the given object. |
boolean |
exists() Tests whether the file or directory denoted by this abstract pathname exists. |
File |
getAbsoluteFile() Returns the absolute form of this abstract pathname. |
String |
getAbsolutePath() Returns the absolute pathname string of this abstract pathname. |
File |
getCanonicalFile() Returns the canonical form of this abstract pathname. |
String |
getCanonicalPath() Returns the canonical pathname string of this abstract pathname. |
long |
getFreeSpace() Returns the number of unallocated bytes in the partition named by this abstract path name. |
String |
getName() Returns the name of the file or directory denoted by this abstract pathname. |
String |
getParent() Returns the pathname string of this abstract pathname's parent, or |
File |
getParentFile() Returns the abstract pathname of this abstract pathname's parent, or |
String |
getPath() Converts this abstract pathname into a pathname string. |
long |
getTotalSpace() Returns the size of the partition named by this abstract pathname. |
long |
getUsableSpace() Returns the number of bytes available to this virtual machine on the partition named by this abstract pathname. |
int |
hashCode() Computes a hash code for this abstract pathname. |
boolean |
isAbsolute() Tests whether this abstract pathname is absolute. |
boolean |
isDirectory() Tests whether the file denoted by this abstract pathname is a directory. |
boolean |
isFile() Tests whether the file denoted by this abstract pathname is a normal file. |
boolean |
isHidden() Tests whether the file named by this abstract pathname is a hidden file. |
long |
lastModified() Returns the time that the file denoted by this abstract pathname was last modified. |
long |
length() Returns the length of the file denoted by this abstract pathname. |
String[] |
list() Returns an array of strings naming the files and directories in the directory denoted by this abstract pathname. |
String[] |
list(FilenameFilter filter) Returns an array of strings naming the files and directories in the directory denoted by this abstract pathname that satisfy the specified filter. |
File[] |
listFiles() Returns an array of abstract pathnames denoting the files in the directory denoted by this abstract pathname. |
File[] |
listFiles(FileFilter filter) Returns an array of abstract pathnames denoting the files and directories in the directory denoted by this abstract pathname that satisfy the specified filter. |
File[] |
listFiles(FilenameFilter filter) Returns an array of abstract pathnames denoting the files and directories in the directory denoted by this abstract pathname that satisfy the specified filter. |
static File[] |
listRoots() List the available filesystem roots. |
boolean |
mkdir() Creates the directory named by this abstract pathname. |
boolean |
mkdirs() Creates the directory named by this abstract pathname, including any necessary but nonexistent parent directories. |
boolean |
renameTo(File dest) Renames the file denoted by this abstract pathname. |
boolean |
setExecutable(boolean executable) A convenience method to set the owner's execute permission for this abstract pathname. |
boolean |
setExecutable(boolean executable, boolean ownerOnly) Sets the owner's or everybody's execute permission for this abstract pathname. |
boolean |
setLastModified(long time) Sets the last-modified time of the file or directory named by this abstract pathname. |
boolean |
setReadable(boolean readable) A convenience method to set the owner's read permission for this abstract pathname. |
boolean |
setReadable(boolean readable, boolean ownerOnly) Sets the owner's or everybody's read permission for this abstract pathname. |
boolean |
setReadOnly() Marks the file or directory named by this abstract pathname so that only read operations are allowed. |
boolean |
setWritable(boolean writable) A convenience method to set the owner's write permission for this abstract pathname. |
boolean |
setWritable(boolean writable, boolean ownerOnly) Sets the owner's or everybody's write permission for this abstract pathname. |
Path |
toPath() Returns a java.nio.file.Path object constructed from the this abstract path. |
String |
toString() Returns the pathname string of this abstract pathname. |
URI |
toURI() Constructs a file: URI that represents this abstract pathname. |
URL |
toURL()Deprecated. This method does not automatically escape characters that are illegal in URLs. It is recommended that new code convert an abstract pathname into a URL by first converting it into a URI, via the toURI method, and then converting the URI into a URL via the URI.toURL method. |
出自于官方 JDK API:传送门 。
RandomAccessFile 类
Java 提供的 RandomAccessFile 类,允许从文件的任何位置进行数据的读写。它不属于流,是 Object 类的子类,但它融合了 InputStream 类和 OutStream 类的功能,既能提供 read()方法和 write()方法,还能提供更高级的直接读写各种基本数据类型数据的读写方法,如 readInt()方法和 writeInt()方法等。
RandomAccessFile 类的中文含义为随机访问文件类,随机意味着不确定性,指的是不需要从头读到尾,可以从文件的任意位置开始访问文件。使用RandomAccessFile 类,程序可以直接跳到文件的任意地方读、写文件,既支持只访问文件的部分数据,又支持向已存在的文件追加数据。
为支持任意读写,RandomAccessFile 类将文件内容存储在一个大型的 byte 数组中。RandomAccessFile 类设置指向该隐含的 byte 数组的索引,称为文件指针,通过从文件开头就开始计算的偏移量来标明当前读写的位置。
构造方法
- RandomAccessFile(File file, String mode)
- RandomAccessFile(String name, String mode)
mode值含义
- “r”:以只读的方式打开,如果试图对该 RandomAccessFile 执行写入方法,都将抛出 IOException 异常。
- “rw”:以读、写方式打开指定文件,如果该文件不存在,则尝试创建该文件。
- “rws”:以读、写方式打开指定文件,相较于“rw”模式,还需要对文件的内容或元数据的每个更新都同步写入到底层存储设备。
- “rwd”:以读、写方式打开指定文件,相较于“rw”模式,还要求对文件内容的每个更新都同步写入到底层存储设备。
相关方法
RandomAccessFile 包含三个方法来操作文件记录指针
- long getFilePointer():返回文件记录指针的当前位置
- void seek(long pos):将文件记录指针定位到pos位置
- skipBytes(int n)
skipBytes 方法用于尝试跳过输入的 n 个字节以丢弃跳过的字节(跳过的字节不读取),skipBytes 方法可能跳过一些较少数量的字节(可能包括0),这可能由任意数量的条件引起,在跳过 n 个字节之前已经到大文件的末尾只是其中的一种可能,该方法不抛出 EOFException ,返回跳过的实际字节数,如果 n 为负数,则不跳过任何字节。
其他方法:
- FileDescriptor getFD() : 可以返回这个文件的文件描述符
- native long length() : 可以返回文件的长度
- native void setLength(long newLength) : 还可以设置文件的长度
- close() : RandomAccessFile在对文件访问操作全部结束后,要调用close()方法来释放与其关联的所有系统资源
随机访问文件是由字节序列组成,一个称为文件指针的特殊标记定位这些字节中的某个字节的位置,文件的读写操作就是在文件指针所在的位置上进行的。打开文件时,文件指针置于文件的起始位置,在文件中进行读写数据后,文件指针就会移动到下一个数据项。
public class RandomAccessFileTest{
public static void main(String[] args) throws Exception {
File file = new File("D://guanwei//guanwei.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
// 从2号位置开始定位
raf.seek(2);
// 插入7个字母‘abcdefg’ 会覆盖其后的7个内容
raf.write("abcdefg".getBytes());
// 获取当前指针的位置
long pointer = raf.getFilePointer();
System.out.println("当前指针位置是:" + pointer);
// 读取,设置从0开始读取
raf.seek(0);
byte[] bs = new byte[100];
int len;
while ((len = raf.read(bs)) != -1) {
System.out.println(new String(bs, 0, len));
}
}
}字节流
在程序设计中,程序如果要读取或写入8位bit的字节数据,应该使用字节流来处理。字节流一般用于读取或写入二进制数据,如图片、音频文件等。一般而言,只要是“非文本数据”就应该使用字节流来处理。
字节流概述
在计算机中,无论是文本、图片、音频还是视频,所有的文件都能以二进制(bit,1字节为8bit)形式传输或保存。Java 中针对字节输入/输出操作提供了一系列流,统称为字节流。程序需要数据的时候要使用输入流来读取数据,而当程序需要将一些数据保存起来的时候就需要使用输出流来完成。在 Java 中,字节流提供了两个抽象基类 `InputStream` 和 `OutputStream`,分别用于处理字节流的输入和输出。因为抽象类不能被实例化,所以在实际使用中,使用的是这两个类的子类。
字节输入流:
InputStream 类及其子类的对象表示字节输入流,InputStream 类的常用子类如下:
- ByteArrayInputStream 类:将字节数组转换为字节输入流,从中读取字节。
- FileInputStream 类:从文件中读取数据。
- PipedInputStream 类:连接到一个 PipedOutputStream(管道输出流)。
- SequenceInputStream 类:将多个字节输入流串联成一个字节输入流。
- ObjectInputStream 类:将对象反序列化。
| 方法声明 | 功能描述 |
|---|---|
| int read() | 从输入流中读取一个 8 位的字节,并把它转换为 0~255 的整数,最后返回整数。如果返回 -1,则表示已经到了输入流的末尾。为了提高 I/O 操作的效率,建议尽量使用 read() 方法的另外两种形式。 |
| int read(byte[] b) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。 该方法返回读取的字节数。如果返回 -1,则表示已经到了输入流的末尾。 |
| int read(byte[] b, int off, int len) | 从输入流中读取若干字节,并把它们保存到参数 b 指定的字节数组中。其中,off 指定在字节数组中开始保存数据的起始下标;len 指定读取的字节数。该方法返回实际读取的字节数。如果返回 -1,则表示已经到了输入流的末尾。 |
| void close() | 关闭输入流。在读操作完成后,应该关闭输入流,系统将会释放与这个输入流相关的资源。注意,InputStream 类本身的 close() 方法不执行任何操作,但是它的许多子类重写了 close() 方法。 |
| int available() | 返回可以从输入流中读取的字节数。 |
字节数组输入流:
ByteArrayInputStream 类可以从内存的字节数组中读取数据,该类有如下两种构造方法重载形式。
- ByteArrayInputStream(byte[] buf):创建一个字节数组输入流,字节数组类型的数据源由参数 buf 指定。
- ByteArrayInputStream(byte[] buf,int offse,int length):创建一个字节数组输入流,其中,参数 buf 指定字节数组类型的数据源,offset 指定在数组中开始读取数据的起始下标位置,length 指定读取的元素个数。
使用 ByteArrayInputStream 实现从一个字节数组中读取数据,再转换为 int 型进行输出。
public class ByteArrayStream {
public static void main(String[] args) {
//1.创建字节数组
byte[] src="java bytes test,good luck for you!".getBytes();
//2.选择流,选择文件输入流
ByteArrayInputStream is=null;//方便在finally中使用,设置为全局变量
try {
is=new ByteArrayInputStream(src);
//3.操作,读文件
byte[] flush=new byte[5];//创建读取数据时的缓冲,每次读取的字节个数。
int len=-1;//接受长度;
while((len=is.read(flush))!=-1) {
//表示当还没有到文件的末尾时
//字符数组-->字符串,即是解码。
String str=new String(flush,0,len);//len是读到的实际大小
System.out.println(str);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
字节类型的 -1,二进制形式为 11111111,转换为 int 类型后的二进制形式为 00000000 00000000 0000000011111111,对应的十进制数为 255。
文件输入流
在创建 FileInputStream 类的对象时,如果找不到指定的文件将拋出 FileNotFoundException 异常,该异常必须捕获或声明拋出。
FileInputStream 常用的构造方法主要有如下两种重载形式。
- FileInputStream(File file):通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。
- FileInputStream(String name):通过打开一个到实际文件的链接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。
public class FileInputStream {
public static void main(String[] args) {
File file = new File("D:\\guanwei.txt");
int len = 0;
//字节数组,一次读取10个字节
byte[] bytes = new byte[10];
FileInputStream fis = null;
try {
//创建 FileInputStream 对象,用于读取文件
fis = new FileInputStream(file);
//如果返回-1,表示读取完毕
//如果读取正常,返回实际读取的字节数
while ((len = fis.read(bytes)) != -1){
//转成字符串
System.out.print(new String(bytes,0,len));
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//关闭文件流,释放资源
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}管道流
Java 里的管道输入流 PipedInputStream 与管道输出流 PipedOutputStream 实现了类似管道的功能,用于不同线程之间的相互通信。
Java 的管道输入与输出实际上使用的是一个循环缓冲数组来实现,这个数组默认大小为1024字节。输入流 PipedInputStream 从这个循环缓冲数组中读数据,输出流 PipedOutputStream 往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流 PipedOutputStream 所在的线程将阻塞;当这个缓冲数组首次为空的时候,输入流 PipedInputStream 所在的线程将阻塞。但是在实际用起来的时候,却会发现并不是那么好用。
Java 在它的 jdk 文档中提到不要在一个线程中同时使用 PipeInpuStream 和 PipeOutputStream ,这会造成死锁。
字节输出流
OutputStream 类及其子类的对象表示一个字节输出流。OutputStream 类的常用子类如下。
- ByteArrayOutputStream 类:向内存缓冲区的字节数组中写数据。
- FileOutputStream 类:向文件中写数据。
- PipedOutputStream 类:连接到一个 PipedlntputStream(管道输入流)。
- ObjectOutputStream 类:将对象序列化。
字节数组输出流
ByteArrayOutputStream 类可以向内存的字节数组中写入数据,该类的构造方法有如下两种重载形式。
- ByteArrayOutputStream():创建一个字节数组输出流,输出流缓冲区的初始容量大小为 32 字节。
- ByteArrayOutputStream(int size):创建一个字节数组输出流,输出流缓冲区的初始容量大小由参数 size 指定。
ByteArrayOutputStream 类中除了有前面介绍的字节输出流中的常用方法以外,还有如下两个方法:
- intsize():返回缓冲区中的当前字节数。
- byte[] toByteArray():以字节数组的形式返回输出流中的当前内容。
//字节数组输出流
public class ByteArrayStream {
public static void main(String[] args) {
// TODO Auto-generated method stub
//1.创建源
byte[] dest=null;//在字节数组输出的时候是不需要源的。
// 2.选择流
ByteArrayOutputStream os=null;
try {
//3.操作
os=new ByteArrayOutputStream();
//将内容写出
String smg="java welcome!\r\n";//将内容写入字节数组
byte[] datas=smg.getBytes();//将字符创转化成字节数组
//将内容写入
os.write(datas,0,datas.length);//
os.flush();//表示刷新缓冲,避免数据驻留在内存中,一般在输出数据的时候都要将数据刷新。
//可以通过toByteArray或者toString方法获得字节数组的内容。
dest=os.toByteArray();
System.out.println(new String(dest));
}catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
//4.释放资源
try {
if (null != os) {
os.close();
}
} catch (Exception e) {
// TODO: handle exception
}
}
}
}
文件输出流
FileOutputStream 类继承自 OutputStream 类,重写和实现了父类中的所有方法。FileOutputStream 类对象表示一个文件字节输出流,可以向流中写入一个字节或一批字节。在创建 FileOutputStream 类的对象时,如果指定的文件不存在,则创建一个新文件;如果文件已存在,则清除原文件的内容重新写入。
FileOutputStream 类的构造方法主要有如下 4 种重载形式。
- FileOutputStream(File file):创建一个文件输出流,参数 file 指定目标文件。
- FileOutputStream(File file,boolean append):创建一个文件输出流,参数 file 指定目标文件,append 指定是否将数据添加到目标文件的内容末尾,如果为 true,则在末尾添加;如果为 false,则覆盖原有内容;其默认值为 false。
- FileOutputStream(String name):创建一个文件输出流,参数 name 指定目标文件的文件路径信息。
- FileOutputStream(String name,boolean append):创建一个文件输出流,参数 name 和 append 的含义同上。
注:目标文件可以不存在,但是路径必须存在。目标文件不能是文件夹路径(不能是已存在的目录),否则均会抛异常。
public class FileOutputStream {
public static void main(String[] args) {
File file = new File("D://guanwei.txt");
FileOutputStream fos = null;
try {
// true 代表是否追加
fos = new FileOutputStream(file,true);
//写入一个字符串
String str = "hello,world!";
fos.write(str.getBytes(),0,str.length());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}缓冲流和缓冲区
流和缓冲区都是用来描述数据的。计算机中,数据往往会被抽象成流,然后传输。
比如读取一个文件,数据会被抽象成文件流;播放一个视频,视频被抽象成视频流。
在传输层协议当中,应用往往先把数据放入缓冲区,然后再将缓冲区提供给发送数据的程序。发送数据的程序,从缓冲区读取出数据,然后进行发送。
流代表数据,具体来说是随着时间产生的数据,类比自然界的河流。你不知道一个流什么时候会完结,直到你将流中的数据都读完。读取文件的时候,文件被抽象成流。流的内部构造,决定了你每次能从文件中读取多少数据。从流中读取数据的操作,本质上是一种迭代器。流的内部构造决定了迭代器每次能读出的数据规模。比如你可以设计一个读文件的流,每次至少会读出 4k 大小。
一般情况下,对于文件流来说,打开一个文件,形成读取流。读取流的本质当然是内存中的一个对象。当用户读取文件内容的时候,实际上是通过流进行读取,看上去好像从流中读取了数据,而本质上读取的是文件的数据。从这个角度去观察整体的设计,数据从文件到了流,然后再到了用户线程,因此数据是经过流的。
如果这里想要实现一个功能,通过 Java 将一个文件(A)复制到另一个地方(B)。这里我们需要分别使用输入流从A中读取数据然后写入到B中去。我们必须要知道的是有一个线程从A中读取数据可能花费1s,而另一个线程写入到B中需要2s,这时候第一个线程就需要等待第二个线程完毕后才能继续读取文件。那么有没有更优的解决方案呢?
是有的,我们可以引入缓冲区的方案,线程一将A中的数据读取到缓冲区中,线程二批量将内容写入到B中。

缓冲流,也叫高效流,是对字节流或者字符流的一种高效利用。缓冲流的原理是,在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,降低系统IO次数,从而提高读写的效率。
那么缓冲流有什么好处么?为什么有了InputStream还需要BufferedInputStream呢?
答:BufferedInputStream、BufferedOutputStream是FilterInputStream、FilterOutputStream的子类,作为装饰器类,使用它们可以防止每次读取/发送数据时进行实际的写操作,代表着使用缓冲区。
我们有必要知道不带缓冲的操作,每读一个字节就要写入一个字节,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以不带缓冲的流效率很低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多!
同时正因为它们实现了缓冲功能,所以要注意在使用BufferedOutputStream写完数据后,要调用flush()方法或close()方法,强行将缓冲区中的数据写出。否则可能无法写出数据。与之相似还BufferedReader和BufferedWriter两个类。
缓冲流相关类就是实现了缓冲功能的输入流/输出流。使用带缓冲的输入输出流,效率更高,速度更快。
字符流
字符流的由来
因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。
字符流的分类
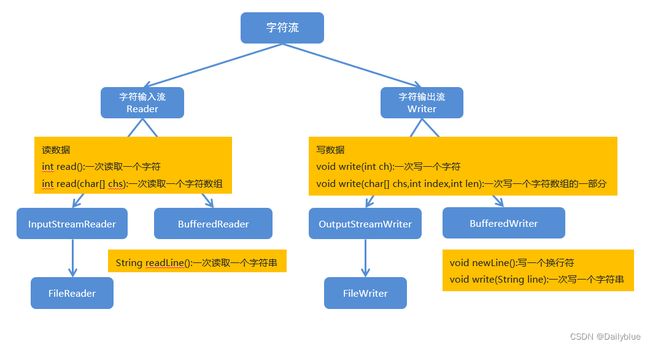
| 基础类 |
实现类 |
|
|---|---|---|
| 字符流 |
Reader:所有的输入字符流的父类,它是一个抽象类。 |
FileReader、CharArrayReader和StringReader是三种基本的介质流,它们分别从本地文件、Char数组和字符串中读取数据。 |
| PipedReader是从与其它线程共用的管道中读取数据。 |
||
| BufferedReader是一种缓冲输入处理流。 |
||
| Writer:所有的输出字符流的父类,它是一个抽象类。 |
FileWriter、CharArrayWriter和StringWriter是三种基本的介质流,它们分别从本地文件、Char数组和字符串中写入数据。 |
|
| PipedWriter是从与其它线程共用的管道中写入数据。 |
||
| BufferedWriter是一种缓冲输出处理流。 |
字节流和字符流的区别
- 读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
- 字符流:一次读入或读出是16位二进制。
- 字节流:一次读入或读出是8位二进制。
- 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。设备上的数据无论是图片或者视频,文字,它们都以二进制存储的。二进制的最终都是以一个8位为数据单元进行体现,所以计算机中的最小数据单元就是字节。意味着,字节流可以处理设备上的所有数据,所以字节流一样可以处理字符数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。
转换流
前边分别讲解了字节流和字符流,有时字节流和字符流之间可能也需要进行转换,在JDK中提供了可以将字节流转换为字符流的两个类,分别是InputStreamReader 类和 OutputStreamWriter 类,它们被称之为转换流。其中,OutputStreamWriter 类可以将一个字节输出流转换成字符输出流,而 InputStreamReade 类可以将一个字节输入流转换成字符输入流。转换流的出现方便了对文件的读写,它在字符流与字节流之间架起了一座桥梁,使原本没有关联的两种流的操作能够进行转换,提高了程序的灵活性。
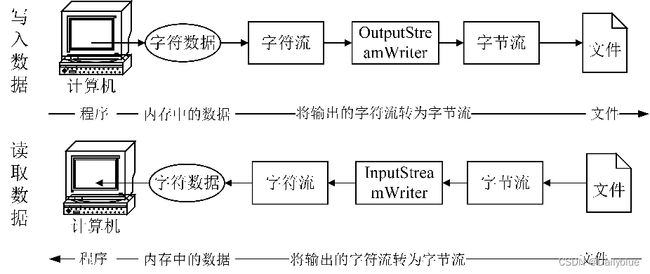
InputStreamReader、OutputStreamReader实现字节流和字符流之间的转换。
InputStreamReader、OutputStreamWriter要InputStream或OutputStream作为参数,实现从字节流到字符流的转换。
InputStreamReader(InputStream);//通过构造函数初始化,使用的是本系统默认的编码表GBK。
InputStreamWriter(InputStream,String charSet);//通过该构造函数初始化,可以指定编码表。
OutputStreamWriter(OutputStream);//通过该构造函数初始化,使用的是本系统默认的编码表GBK。
OutputStreamwriter(OutputStream,String charSet);//通过该构造函数初始化,可以指定编码表。
序列化和反序列化
Java 序列化就是指把 Java 对象转换为字节序列的过程,Java 反序列化就是指把字节序列恢复为 Java 对象的过程。

序列化
序列化是指把一个 Java 对象变成二进制内容,实质上就是一个 byte[]。因为序列化后可以把 byte[] 保存到文件中,或者把 byte[] 通过网络传输到远程,如此就相当于把 Java 对象存储到文件或者通过网络传输出去了。
序列化的实现
序列化的实现有三种方式:
- 若 Person 类仅实现了 Serializable 接口,则 ObjectOutputStream采用默认的序列化方式,对 Person 对象的非 transient 的实例变量进行序列化。
- 若 Person 类不仅实现了 Serializable 接口,并且还定义了 writeObject(ObjectOutputSteam out) 方法,则 ObjectOutputStream 调用 Person 对象的writeObject(ObjectOutputStream out) 的方法进行序列化。
- 若 Person 类实现了 Externalnalizable 接口,且 Person 类必须实现 readExternal(ObjectInput in) 和 writeExternal(ObjectOutput out) 方法,则ObjectOutputStream 调用 Person 对象的 writeExternal(ObjectOutput out) 的方法进行序列化。
下面我们通过演示第一种方式的实现过程:
一个 Java 对象要能序列化,必须实现一个特殊的 java.io.Serializable 或者 Externalizable 接口,它的定义如下:
public interface Serializable {}Serializable 接口没有定义任何方法,它仅仅是一个空接口。这样的空接口被称之为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个“标记”,并没有增加任何方法。
然后通过 ObjectOutputStream 类将对象序列化:
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//序列化 guanwei.obj 后缀没什么要求
OutputStream os = new FileOutputStream("guanwei.obj");
ObjectOutputStream oos = new ObjectOutputStream(os);
// Person 类必须实现 Serializable 接口
Person person = new Person("关为", "男", "23");
oos.writeObject(person);
oos.flush();
oos.close();
}
}反序列化
把一个二进制内容(也就是 byte[])变回 Java 对象。有了反序列化,保存到文件中的 byte[] 又可以“变回” Java 对象,或者从网络上读取 byte[] 并把它“变回” Java 对象。反序列化能做以下操作:
- 以面向对象的方式将数据存储到磁盘上的文件。例如,Redis 存储 Person 对象的列表。
- 将程序的状态保存在磁盘上。例如保存游戏状态。
- 通过网络以表单对象形式发送数据。例如,在聊天应用程序中以对象形式发送消息。
反序列化的实现
同序列化一样,也是有三种实现方式:
- 若 Person 类仅实现了 Serializable 接口,则 ObjcetInputStream 采用默认的反序列化方式,对 Person 对象的非 transient 的实例变量进行反序列化。
- 若 Person 类不仅实现了 Serializable 接口,并且还定义了 readObject(ObjectInputStream in) 方法,则 ObjectInputStream 会调用 Person 对象的readObject(ObjectInputStream in) 的方法进行反序列化。
- 若 Person 类实现了 Externalnalizable 接口,且 Person 类必须实现 readExternal(ObjectInput in) 和 writeExternal(ObjectOutput out) 方法,则ObjectInputStream 会调用 Person 对象的 readExternal(ObjectInput in) 的方法进行反序列化。
同样我们通过第一种方式实现反序列化:
public class SerializableTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//反序列化
InputStream is = new FileInputStream("guanwei.obj");
ObjectInputStream ois = new ObjectInputStream(is);
Person person = (Person) ois.readObject();
System.out.println(person);
}
}Externalnalizable 方式的实现
// 必须书写无参数构造器
public class Student implements Externalizable {
private Integer id;
private String name;
public Student() {
}
public Student(Integer id, String name) {
this.id = id;
this.name = name;
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(id);
out.writeObject(name);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
id = (int)in.readObject();
name = (String)in.readObject();
}
}
测试类调用
public class App {
private static void a() throws IOException{
File file = new File("D://a//stu.obj");
OutputStream out = new FileOutputStream(file);
ObjectOutputStream oos = new ObjectOutputStream(out);
Student stu = new Student(1,"李四");
stu.writeExternal(oos);
}
private static void b() throws IOException, ClassNotFoundException {
File file = new File("D://a//stu.obj");
InputStream in = new FileInputStream(file);
ObjectInputStream ois = new ObjectInputStream(in);
Student student = new Student();
student.readExternal(ois);
System.out.println(student);
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
a();
}
}序列化的好处
序列化最重要的作用:在传递和保存对象时.保证对象的完整性和可传递性。对象转换为有序字节流,以便在网络上传输或者保存在本地文件中。
反序列化的最重要的作用:根据字节流中保存的对象状态及描述信息,通过反序列化重建对象。
总结:核心作用就是对象状态的保存和重建。通过序列化以字节流的形式使对象在网络中进行传递和接收。
注意实现:
- 某个类可以被序列化,则其子类也可以被序列化。
- 声明为 static 和 transient 的成员变量,不能被序列化。static 成员变量是描述类级别的属性,transient 表示临时数据。
- 反序列化读取序列化对象的顺序要保持一致。
serialVersionUID 常数
serialVersionUID 是一个常数,用于唯一标识可序列化类的版本。从输入流构造对象时,JVM 在反序列化过程中检查此常数。如果正在读取的对象的 serialVersionUID 与类中指定的序列号不同,则 JVM 抛出 InvalidClassException。这是为了确保正在构造的对象与具有相同 serialVersionUID 的类兼容。
serialVersionUID 是可选的。如果不显式声明,Java 编译器将自动生成一个。
public class Person extends Person implements Serializable {
public static final long serialVersionUID = 123456789L;
}
为何要必须显式声明 serialVersionUID?
原因是:自动生成的 serialVersionUID 是基于类的元素(成员变量、方法和构造函数等)计算的。如果这些元素之一发生更改,serialVersionUID 也将更改。想象一下这种情况:
- 一个程序,将 Person 类的某些对象存储到文件中。Person 类没有显式声明的 serialVersionUID。
- 而后更新了 Person 类(比如新增了一个私有方法),现在自动生成的 serialVersionUID 也被更改了。
- 该程序无法反序列化先前编写的 Person 对象,因为那里的 serialVersionUID 不同。JVM 抛出InvalidClassException。
transient 修饰符
transient 修饰的变量也被称之为瞬时变量,JVM 在序列化过程中会跳过瞬态变量。这意味着在序列化对象时不会存储瞬时变量的值。因此,如果成员变量不需要序列化,则可以将其标记为瞬态。