Dolphin:面向营销场景的超融合多模智能引擎
1. 背景
为提升易用性和降低使用成本,大数据技术逐步向Serverless、一体化和智能化方向发展。为了更好的提升客户投放效率和效果,阿里妈妈自研了超融合多模智能引擎Dolphin(以下简称“Dolphin”)。其最初定位解决通用OLAP(OLAP全称Online Analytical Processing)在圈人场景计算性能问题,历经5年的技术发展与沉淀,目前已形成覆盖OLAP、AI、Streaming和Batch四大方向的智能超融合引擎,提供针对营销场景投前、投中、投后全链路的广告主工具和算法策略迭代。本文结合近年来营销场景生态发展梳理了Dolphin引擎技术演进过程,欢迎阅读交流。
 投放场景
投放场景
Dolphin通过统一开放的技术架构,提供智能超融合一体化使用体验,实现使用Dolphin SQL就可以连接异构计算和存储引擎,屏蔽复杂的底层技术,通过Dolphin SQL解决业务场景下各类问题,实现业务逻辑和底层技术解耦,提供一体化高效的开发能力。
1.1 Dolphin引擎技术业务大图
阿里妈妈营销场景复杂多样,包括达摩盘、搜索广告直通车和展示广告引力魔方等产品,用户规模和数据规模都是业界Top级别,Dolphin引擎经过多年发展沉淀两方面核心价值:
性能价值:解决超大规模场景下通用引擎无法解决的性能问题。
效能价值:降低通用引擎的使用成本甚至做到对用户透明无感知,从而提升开发迭代效能。
下图是Dolphin引擎相关技术和业务大图,主要分为商家端营销场景、极光(阿里妈妈交互式研发和服务平台)、Dolphin引擎和计算存储层四个部分。
 Dolphin超融合多模引擎技术业务大图
Dolphin超融合多模引擎技术业务大图
2. Dolphin内核能力
Dolphin引擎最初源于OLAP计算场景,在MPP计算引擎基础之上构建,核心能力有五个方面,包括自研引擎、SQL引擎模块、Index Build引擎模块、智能计算和一写多读能力。
2.1 自研引擎
考虑到查询性能、稳定性和生态完善程度,我们选择自研一系列能力:
计算存储分离,基于集团云基础设施对计算存储解耦,实现云化部署,对计算存储动态管理。
支持bitmap、GroupTable和AFile索引,对超大规模数据计算性能加速。
支持向量召回计算,支持高并发、高性能向量在线计算和离线批量计算。
支持模型推理打分,支持部署AI模型进行高并发、高性能在线推理打分计算。
支持实时写入,支持高性能实时数据写入能力。
基于引擎自研的能力,不仅扩展引擎能力边界,更减少多引擎开发及维护成本。

2.2 Dolphin SQL引擎
SQL引擎核心设计目标是解耦业务SQL和物理执行SQL,通过SQL转译让业务SQL转化为物理执行SQL,用户对底层透明,给底层提供非常大的技术扩展空间,让使用SQL开发AI、Streaming能力成为可能。SQL引擎的能力主要包括转译、执行计划优化、负载均衡、物化及联邦查询能力。
我们自研SQL编译器,实现让复杂Dolphin SQL转译为底层物理执行SQL,这里主要分为3个部分:
Dolphin JDBC:主要SQL服务入口,为了实现更接近数据库的使用体验,我们实现Dolphin JDBC驱动,让业务对接相对RPC服务也更简单。
Dolphin SQL Parser:使用性能更高的fastsql,将SQL解析为AST树。
翻译处理框架:负责对AST数进行分析,包括检查元数据、绑定物理信息、基于规则+CBO的执行计划优化,生成physical SQL提交给执行引擎。
调度器:根据物理执行计划决定哪部分算子需要在哪个引擎执行,控制联邦查询过程。
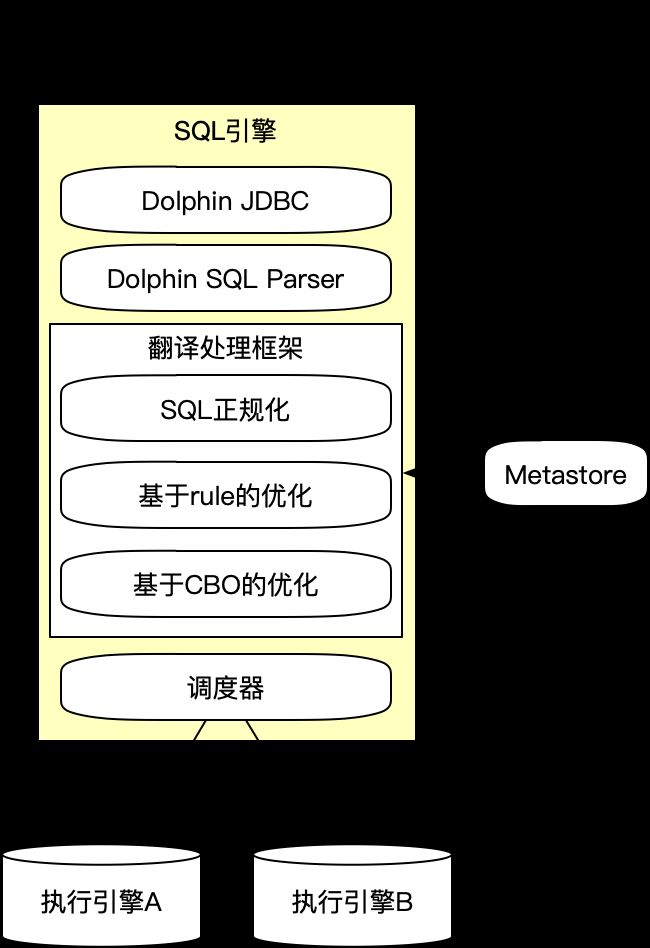 查询SQL转译过程
查询SQL转译过程
2.3 Dolphin Index Build引擎
为解决通用引擎在超大规模圈人场景性能瓶颈,我们使用Index Build引擎实现对数据的索引构建,主要有Bitmap、GroupTable和AFile索引,然后将索引导入在线MPP引擎提供查询服务。
2.3.1 Bitmap索引
我们在18年底启动使用bitmap计算升级方案,通过对原始数据进行build成index索引导入在线引擎,实现用户使用通用SQL就可以进行毫秒级圈人计算,新的bitmap索引实现部分场景数据压缩高达50倍,计算性能提升高达15倍,同时可以达到数百QPS毫秒级并发查询性能。
下图所示是把原始结构表转化为bitmap结构索引表,就把传统scan+filter计算转化为bitmap与运算,参与计算的数据量更小且可以利用CPU指令计算加速。
 bitmap计算案例
bitmap计算案例
2.3.2 GroupTable索引
在达摩盘标签圈选场景中,我们使用bitmap加速标签圈选已取得显著业务收益,然而在用户ID粒度计算的场景(group by ID + having)及ID join场景则无法直接应用,这类场景的计算量通常非常大,单表容量可达到百T级别,通用引擎计算的时间和存储成本很大,基本很难支持大规模场景,于是我们提出GroupTable索引结构,使用向量化+索引+压缩的方式进行存储,实现部分场景数据存储节省高达60%+,计算性能提升30倍+,该结构也可以跟bitmap结构进行混合计算,基本覆盖大部分计算场景。

2.3.3 AFile索引
在超大数据规模的用户行为分析和广告归因分析场景,因为涉及数据join关联,通用计算引擎很难达到秒级交互式查询性能,故提出AFile索引结构,通过预计算的方式提前做好数据处理,从而达到计算性能提升1到2个数量级效果。
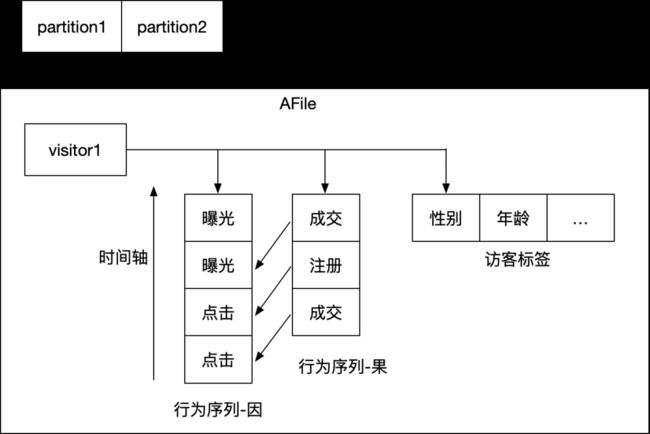 AFile结构
AFile结构
2.4 智能计算能力
在算法广泛应用的今天,如何利用算法让系统更智能化从而提升性能和降低成本,已经成为业界探索的热点,近两年我们基于Dolphin在智能化方面已经有一些探索实践。
2.4.1 智能物化
在营销场景下每天有数百万分析查询请求,如何准确物化数据,用空间换时间提升查询性能成为重要的研究方向,我们首先从统计学角度入手,从SQL的query block粒度进行物化,实现对大部分复杂耗时的请求进行物化优化。
但统计学方法会有不足,例如通常是基于历史数据统计分析,而用户行为有周期性,尤其在电商场景,每年都会有一些如38、618、双十一和年货节大促节点,这些行为特点使用统计方法很难捕捉,更适合使用机器学习方法,我们会结合用户查询行为序列数据进行建模,使用模型预测未来会到来的热点查询,从而提前物化来提升效果。
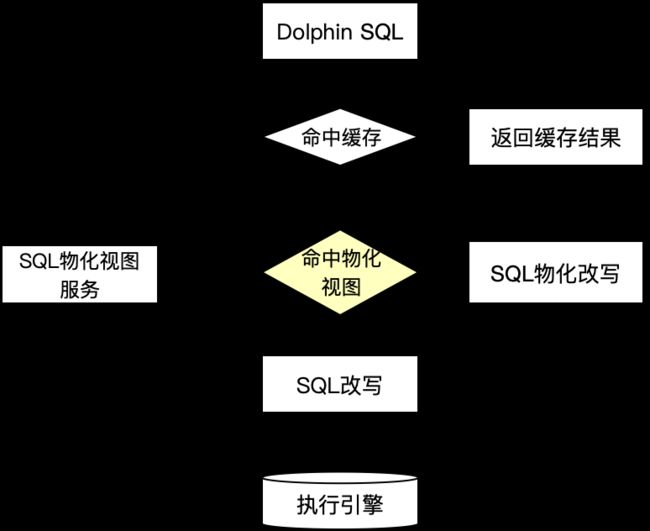 SQL查询流程
SQL查询流程
2.4.2 智能索引
在达摩盘场景,每天查询SQL覆盖数千张表,这些表都是业务方配置接入,然而业务方不用关注如何优化表来提升性能,为提升用户体验我们向业务方屏蔽表的索引优化。这么多表的索引构建很复杂,分区列选错了没有优化效果,索引建多了会造成存储冗余,索引建少了查询性能会有影响,因此我们建立了一套系统化的方案,使用表的统计数据和历史查询信息,采用启发式算法来自动选择,达到智能选择分区列和索引的目的。
 智能索引架构图
智能索引架构图
2.5 一写多读能力
Dolphin底层使用MPP计算引擎,通过DBFS(DBFS是数据库场景的云原生共享文件存储服务)高性能SDD存储数据,高可用环境下会使用多集群冗余备份,为了减少数据冗余存储开销,我们采用一写多读方案,将部分存储占用大且查询量相对较少的表存在HDFS,存储占用少但查询量大的数据存在DBFS,这个思路类似冷热存储,但我们的工作不仅是数据跨介质存储,更多是在读冷数据优化方面。
为了保证查询HDFS的性能,我们做了一系列查询加速优化,如列裁剪、缓存和下推等,基于该方案,我们实现在查询性能不变的情况下,因为使用HDD存储大表数据,实现整体存储成本节省70%+。
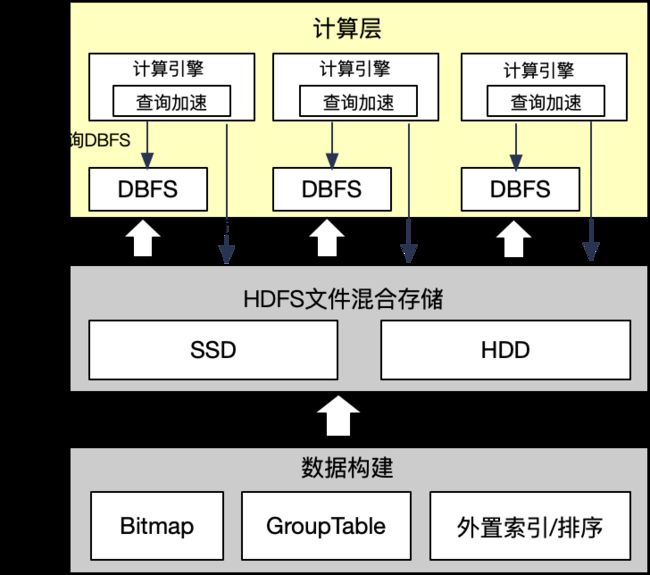
一写多读架构
3. Dolphin领域能力
在业务需求多样的营销场景,Dolphin作为超融合多模引擎,基于SQL和index build引擎核心能力,支持的能力范围已经包括OLAP、AI Service、Streaming和Batch四个方向,基本实现绝大部分需求都可以使用Dolphin一体化完成。
3.1 Dolphin OLAP
Dolphin底层引擎最初就是服务于达摩盘OLAP分析查询业务,其在OLAP方向的沉淀最久,基于Bitmap和GroupTable索引的查询加速方案可以实现百毫秒、百QPS和万亿级数据精确圈人查询,不仅服务于阿里妈妈,还跨部门支持10+BU的圈人洞察业务;此外基于MergeTree表引擎的方案可以支持高性能报表查询和归因计算。

OLAP计算架构图
3.2 Dolphin AI Service
Dolphin最初主要解决圈人问题,例如标签圈人、关键词圈人和LBS圈人等。随着商家对拉新、转化等营销诉求不断提升,需要在人群基础上进行更智能的分析挖掘,从而衍生到算法场景。
以往算法业务涉及链路很长,包括预处理、召回、排序和打分,往往需要跟多个独立系统进行交互,新的业务从数据接入、引入客户端到debug测试,环节繁杂,调试成本高,因为涉及多个系统交互,后续迭代成本也相当高。
然而单位时间内完成的迭代次数就是算法业务生产力,因此我们提出Dolphin AI Service,基于不同独立系统之上构建一个SQL服务层,将业务逻辑和各系统进行解耦,提供统一的Dolphin SQL语法,极大降低算法同学学习和开发成本,实现使用SQL就可以完成业务开发及在线调用。
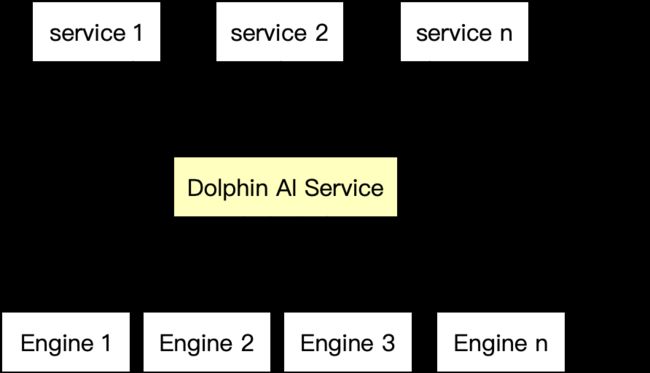 中间层设计思路
中间层设计思路
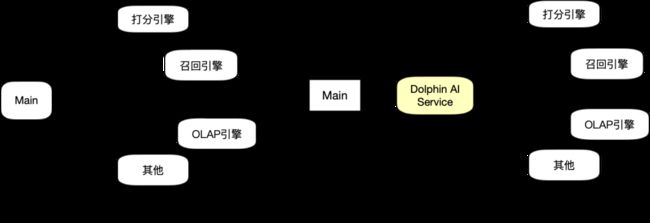
引入中间层之后,算法开发业务只需要对接Dolphin AI Service,使用SQL就可以完成预处理、向量召回和模型打分等计算需求。
下图所示是算法用户使用SQL实现关键词推荐的计算流程,包括词的预处理、模型打分,向量TopK召回和组合优化计算,所有计算都使用SQL表达,实现学习、调试及开发效率显著提升。
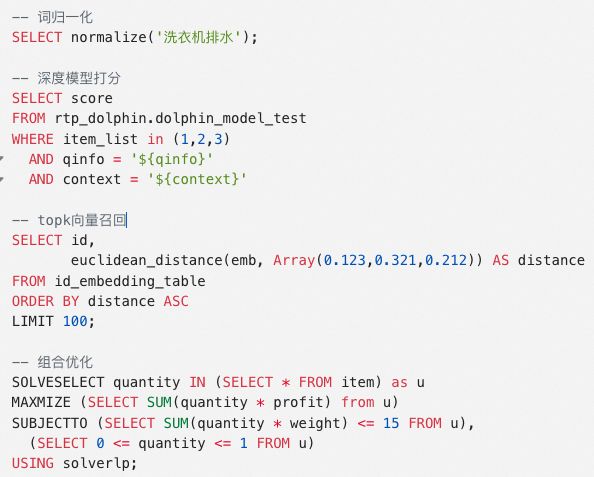 SQL执行AI在线计算
SQL执行AI在线计算
3.3 Dolphin Streaming
在阿里妈妈商家端算法场景,算法业务迭代使用的数据是离线T+1甚至T+7更新频率,为更全面、实时的挖掘潜在需求,利用实时行为及反馈帮助广告主更好诊断选择,我们在已有引擎基础之上构建出Dolphin Streaming,提出像开发数据库一样开发实时作业(DB for Streaming),基于该理念的设计特点包括:
底层透明:用户无需感知底层Flink引擎和存储,极大降低学习和开发成本。
极简SQL:设计的SQL开发语法屏蔽不易理解的实时开发术语,例如TUMBLE,HOP。
流程一体化:打通从实时数据开发、测试到上线读取全流程,实现用SQL开发的特征也用SQL读取。
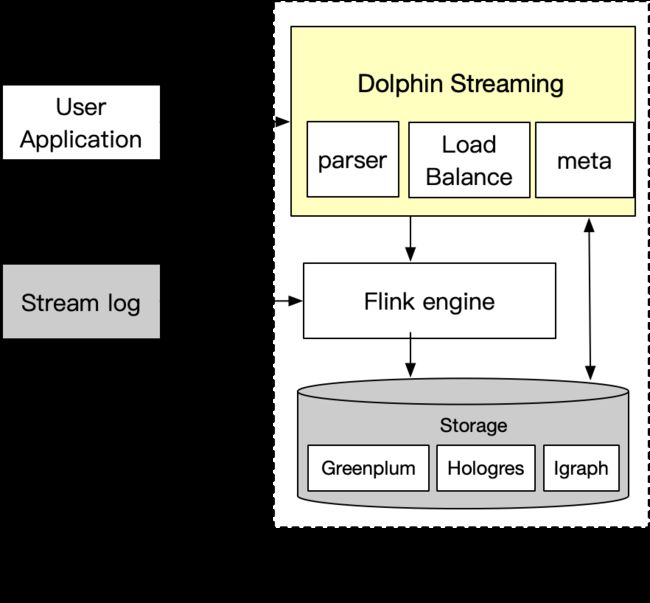
Dolphin Streaming提供数据库SQL操作体验,结合Flink成熟大规模计算能力,屏蔽存储,让实时数据开发和查询一体化,是用户体验和系统性能都能达到较高水准的架构方案。
基于Dolphin Streaming开发实时作业分为三步:
定义输入源,一般为实时数据源,只需要第一次定义,后续复用。
定义输出表,可以写入实时数据源,也可以直接落盘存储,用户无需感知底层存储引擎。
定义计算逻辑,这里主要是对输入源进行处理转换,数据写入输出源。
运行作业后就可以直接使用SQL查询特征结果:
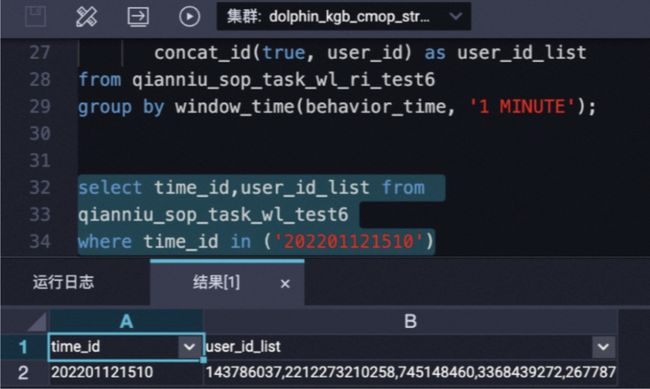 SQL查询实时特征
SQL查询实时特征
此外为解决数据分散使用困难问题,我们还基于Dolphin Streaming构建实时数据体系,让数据在体系内循环沉淀,用户可以在商家数据中心查询需要的上游实时数据,然后使用SQL实现实时特征开发及生产,实现用户只需要懂SQL就可轻松完成实时作业开发。
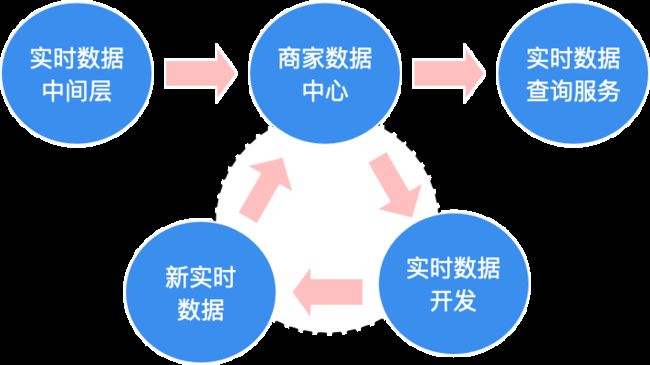 数据循环流动
数据循环流动
3.4 Dolphin Batch
在各业务场景离线计算是非常普遍需求,集团ODPS可提供通用数据离线计算能力,但难以高效满足领域计算场景,很多相同业务逻辑的需求都是各自独立开发,大量重复建设,例如离线批量向量召回,离线批量打分等,因此我们构建出Dolphin Batch解决领域计算场景重复建设成本问题和性能问题。
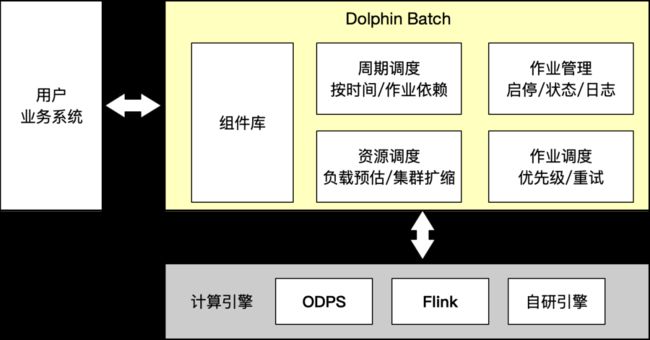 Dolphin Batch架构图
Dolphin Batch架构图
基于Dolphin Batch我们在交互式web界面5分钟就可以完成一个向量召回作业的配置,该能力通过产品化不仅支持妈妈内部团队,还支持其他BU。我们不仅实现领域能力产品化复用,还通过使用自研引擎的向量召回方案,实现性能和作业调度稳定性大幅提升。
 离线批量向量召回
离线批量向量召回
4. 总结及规划
这些年来大数据技术在产品使用和技术演进层面都在向超融合数据库发展,技术方面如事物、向量计算、索引、冷热存储、物化、实时读写和模型应用等。大数据的使用从用户角度看就是一体化数据库系统,算法工程师和数据科学家可以使用SQL完成任意规模数据处理、实时作业开发和算法开发等业务需求,其背后底层是极其复杂的工程和算法实现。
Dolphin未来将持续基于Serverless、一体化和智能化方向不断升级,面向用户需求扩展业务边界,让用户体验简单高效,屏蔽复杂流程和性能问题,通过技术推动经营增长。
阿里妈妈工程平台智能分析引擎团队-系列文章:
阿里妈妈Dolphin分布式向量召回技术详解
阿里妈妈Dolphin智能计算引擎基于Flink+Hologres实践
Dolphin Streaming实时计算,助力商家端算法第二增长曲线
面向数智营销的 AI FAAS 解决方案
FAE:阿里妈妈归因分析与用户增长分析引擎
开源greenplum向量计算库:https://github.com/AlibabaIncubator/gpdb-faiss-vector
END

关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”ღ~
↓欢迎留言参与讨论↓