Encoder-Decoder
2021SC@SDUSC
为了更好的理解模型代码,进行的相关知识补充学习
系列文章目录
(一)面向特定问题的开源算法管理和推荐
(二)论文阅读上
(三)sent2vec
(四)BERT for Keyphrase Extraction
(五)config.py 代码分析
(六)model.py(上)
(七)论文 - 补充理解
(八)数据处理之prepro_utils.py
(九)preprocess.py代码分析
(十)preprocess.py代码分析-下
(十一)spllit_json.py代码分析
(十二)prepro_utils.py代码分析
(十三)jsonify_multidata.py + Constant.py
(十四)loader_utils.py
(十五)Keyphrase Chunking - bert2chunk_dataloader.py分析
(十六)Encoder-Decoder
(十七)bert2joint_dataloader.py
Encoder-Decoder
(以下借鉴网络博客内容)
模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:
将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题
文章目录
- 系列文章目录
- Encoder-Decoder
- 前言
- Seq2Seq模型
-
- 示例过程
- 引入“注意力”机制
- Transformer中的 Encoder-Decoder
-
- 有关的代码实现
-
- Encode
前言
Encoder-Decoder 通常称作 编码器-解码器,是深度学习中常见的模型框架,很多常见的应用都是利用编码-解码框架设计的。
Encoder 和 Decoder 部分可以是任意文字,语音,图像,视频数据,模型可以是 CNN,RNN,LSTM,GRU,Attention 等等。所以,基于 Encoder-Decoder,我们可以设计出各种各样的模型。
Encoder-Decoder 有一个比较显著的特征就是它是一个 End-to-End 的学习算法,以机器翻译为例,可以将法语翻译成英语。这样的模型也可以叫做 Seq2Seq。
编码,就是将输入序列转化转化成一个固定长度向量。解码,就是讲之前生成的固定向量再转化出输出序列。
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
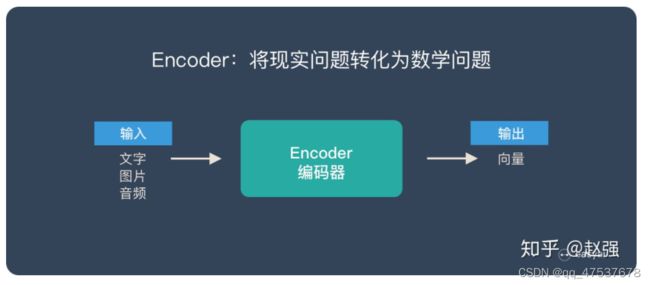
Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
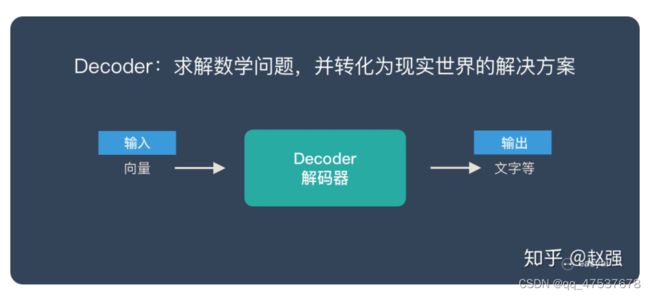
将两者连接起来:

Seq2Seq模型
Seq2Seq ( Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。
Seq2Seq 强调目的,不特指具体方法,满足输入序列,输出序列的目的,都可以统称为 Seq2Seq 模型。Seq2Seq 使用的具体方法基本都是属于 Encoder-Decoder 模型的范畴。
示例过程
- Seq2Seq模型是一类端到端(end-to-end)的算法框架,通过编码器-解码器架构来实现。
目标:给定长度为 m 的输入序列
![]()
生成长度为 n 的目标序列
![]()
在机器翻译中,x 和 y 分别代表输入和输出的两个句子。
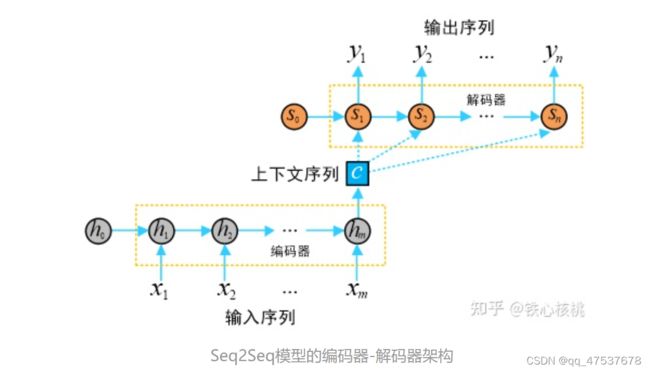
上图中:
编码器隐向量(hidden states):
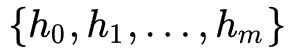
解码器隐向量:

编码器实现将输入的任意长度的输入序列映射为固定长度的上下文序列 c,该上下文序列为输入序列的一个中间编码表示,表达为

解码器用来将上述固定长度的中间序列c映射为变长度的目标序列作为最终输出 y。

-
问题一
当输入序列的长度过长时,上下文序列将无法表示整个输入序列的信息。
Seq2Seq模型理论上可以接受任意长度的序列作为输入,但是机器翻译的实践表明,输入的序列越长,模型的翻译质量越差。产生这一问题的原因在于无论输入序列的长短,编码器都会将其映射为一个具有固定长度的上下文序列c。 -
问题二
在生成每一个目标元素 [公式] 时使用的下文序列 [公式] 都是相同的,这就意味着输入序列 x 中的每个元素对输出序列 [公式] 中的每一个元素都具有相同的影响。
事实上在一个输入序列中,不同元素所携带的信息量是不同的,受到关注的程度也自然存在差异。
引入“注意力”机制
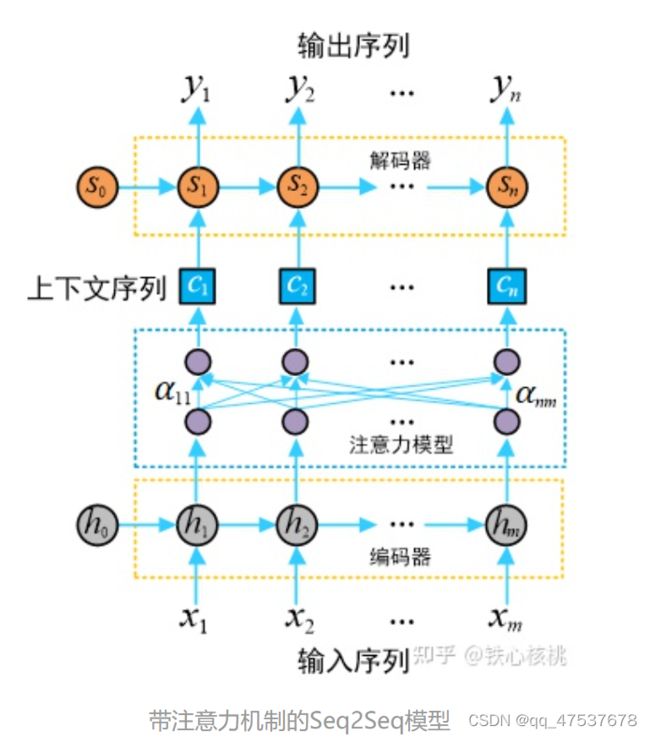
在注意力模型中,每一个上下文序列为编码器所有隐状态向量的加权和

将输入序列映射为多个下文序列 c1, c2, c3,…, cn,其中 ci 是与输出 yi 对应的上下文信息(其中 i = 1, 2, 3, …, n)。在解码器预测输出 yi 时,其结果依赖与之匹配的上下文序列 ci 以及其之前的隐状态,即
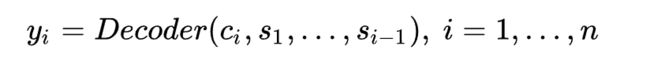
注意力模块可以视为是一个具有 m 个输入节点和 n 个输出节点的全连接神经网络。
Transformer中的 Encoder-Decoder
Transformer模型采用的也是编码器-解码器架构,但是在该模型中,编码器和解码器不再是 RNN结构,取而代之的是编码器栈(encoder stack)和解码器栈(decoder stack)(注:所谓的“栈”就是将同一结构重复多次,“stack”翻译为“堆叠”更为合适)。编码器栈和解码器栈中分别为连续 N(在 Transformer模型中 N = 6)个具有相同结构的编码器和解码器。
下图为Transformer模型的编码器-解码器架构示意图。

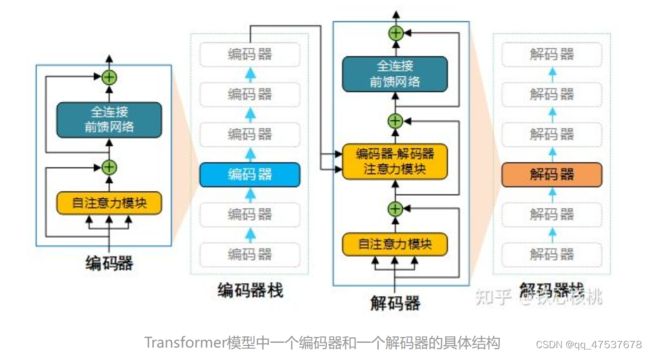
在每个解码器中,除了包含与解码器类似的自注意力模块和全连接前馈网络外,还额外在两个子网络之间添加了另外一个注意力模块(注:该注意力模块称为“编码-解码注意力”模块,同样也是采用多头注意力结构)。与编码器类似,解码器中的三个子网络也均具有残差连接,并且在每个残差合成其后都进行归一化操作。
- Transformer 中 Encoder 由 6 个相同的层组成,每个层包含 2 个部分:
Multi-Head Self-Attention
Position-Wise Feed-Forward Network (全连接层) - Decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
Multi-Head Self-Attention
Multi-Head Context-Attention
Position-Wise Feed-Forward Network
有关的代码实现
Encode

class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
x += self.positional_encoding(x.shape[1],config.d_model)
# print("After positional_encoding: {}".format(x.size()))
output = self.add_norm(x,self.muti_atten,y=x)
output = self.add_norm(output,self.feed_forward)
return output
forward 函数的参数从 x 变为
x,y:请读者观察模型架构,Decoder需要接受Encoder的输入作为公式中的V,即我们参数中的y。在普通的自注意力机制中,我们在调用中设置y=x即可。
requires_mask: 是否采用Mask机制,在Decoder中设置为True
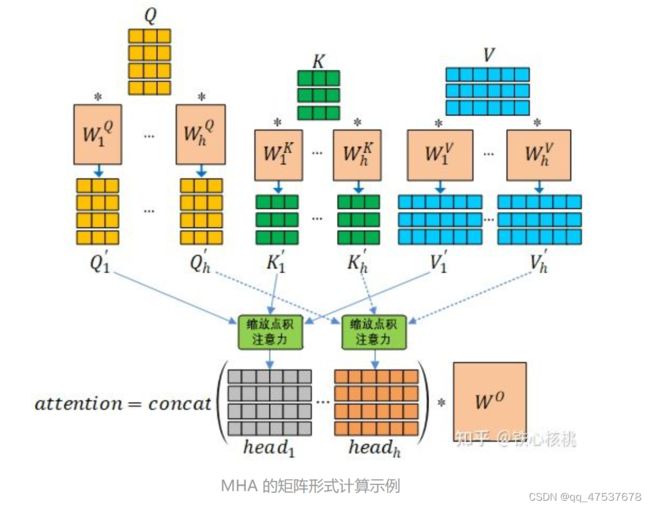
class Mutihead_Attention(nn.Module):
def __init__(self,d_model,dim_k,dim_v,n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model,dim_k)
self.k = nn.Linear(d_model,dim_k)
self.v = nn.Linear(d_model,dim_v)
self.o = nn.Linear(dim_v,d_model)
self.norm_fact = 1 / math.sqrt(d_model)
def generate_mask(self,dim):
# 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
# padding mask 在数据输入模型之前完成。
matirx = np.ones((dim,dim))
mask = torch.Tensor(np.tril(matirx))
return mask==1
def forward(self,x,y,requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# 对 x 进行自注意力
Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.n_heads) # n_heads * batch_size * seq_len * dim_k
V = self.v(y).reshape(-1,y.shape[0],y.shape[1],self.dim_v // self.n_heads) # n_heads * batch_size * seq_len * dim_v
# print("Attention V shape : {}".format(V.shape))
attention_score = torch.matmul(Q,K.permute(0,1,3,2)) * self.norm_fact
if requires_mask:
mask = self.generate_mask(x.shape[1])
attention_score.masked_fill(mask,value=float("-inf")) # 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASKSoftmax之前的结果就好了
output = torch.matmul(attention_score,V).reshape(y.shape[0],y.shape[1],-1)
# print("Attention output shape : {}".format(output.shape))
output = self.o(output)
return output
Feed_Forward(nn.Module) : 两个Linear中连接Relu即可,目的是为模型增添非线性信息,提高模型的拟合能力。
class Feed_Forward(nn.Module):
def __init__(self,input_dim,hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.L1 = nn.Linear(input_dim,hidden_dim)
self.L2 = nn.Linear(hidden_dim,input_dim)
def forward(self,x):
output = nn.ReLU()(self.L1(x))
output = self.L2(output)
return output
实现论文中提出的残差连接以及LayerNorm
class Add_Norm(nn.Module):
def __init__(self):
self.dropout = nn.Dropout(config.p)
super(Add_Norm, self).__init__()
def forward(self,x,sub_layer,**kwargs):
sub_output = sub_layer(x,**kwargs)
# print("{} output : {}".format(sub_layer,sub_output.size()))
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.size()[1:])
out = layer_norm(x)
return out
Decoder
在 Encoder 部分的讲解中,我们已经实现了大部分Decoder的模块。Decoder的Muti_head_Attention引入了Mask机制,Decoder与Encoder 中模块的拼接方式不同。以上两点读者在Coding的时候需要注意。
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(config.d_model,config.dim_k,config.dim_v,config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm()
def forward(self,x,encoder_output): # batch_size * seq_len 并且 x 的类型不是tensor,是普通list
# print(x.size())
x += self.positional_encoding(x.shape[1],config.d_model)
# print(x.size())
# 第一个 sub_layer
output = self.add_norm(x,self.muti_atten,y=x,requires_mask=True)
# 第二个 sub_layer
output = self.add_norm(output,self.muti_atten,y=encoder_output,requires_mask=True)
# 第三个 sub_layer
output = self.add_norm(output,self.feed_forward)
return output