经过“九九八十一难”,大模型终于炼成。下一步就是架设服务,准备开门营业了。真这么简单?恐怕未必!行百里者半九十,推理优化又是新的雄关漫道。如何进行延迟优化?如何进行成本优化 (别忘了 OpenAI 8K 上下文的 GPT-4 模型,提示每 1000 词元只需 0.03 美金,补全每 1000 词元只需 0.06 美金)?如何在延迟和吞吐量之间折衷?如何处理大模型特有的分布式推理后端和网络服务前端的协作问题……要不动手之前还是先看看 BLOOM 推理服务踩过的坑吧!
本文介绍了我们在实现 BLOOM 模型高效推理服务的过程中发生的幕后故事。
在短短数周内,我们把推理延迟降低了 5 倍 (同时,吞吐量增加了 50 倍)。我们将分享我们为达成这一性能改进而经历的所有斗争和史诗般的胜利。
在此过程中,不同的人参与了不同的阶段,尝试了各种不同的优化手段,我们无法一一罗列,还请多多包涵。如果你发现本文中某些内容可能已过时甚至完全错误,这也不奇怪,因为一方面对于如何优化超大模型性能我们仍在努力学习中,另一方面,市面上新硬件功能和新优化技巧也层出不穷。
我们很抱歉如果本文没有讨论你最中意的优化技巧,或者我们对某些方法表述有误。但请告诉我们,我们非常乐意尝试新东西并纠正错误。
训练 BLOOM
这是不言而喻的,如果不先获取到大模型,那推理优化就无从谈起。大模型训练是一项由很多不同的人共同领导的超级工程。
为了最大化 GPU 的利用率,我们探索了多种训练方案。最后,我们选择了 Megatron-Deepspeed 来训练最终模型。这意味着训练代码与 transformers 库并不完全兼容。
移植至 transformers
由于上文提及的原因,我们第一件事是将现有模型移植到 transformers 上。我们需要从训练代码中提取相关代码并将其实现至 transformers 里。Younes 负责完成了这项工作。这个工作量绝对不小,我们大概花了将近一个月的时间,进行了 200 次提交 才最终完成。
有几点需要注意,我们后面还会提到:
小版的模型,如 bigscience/bigscience-small-testing 和 bigscience/bloom-560m 非常重要。因为模型结构与大版的一样但尺寸更小,所以在它们上面一切工作 (如调试、测试等) 都更快。
首先,你必须放弃那种最终你会得到比特级一致的 logits 结果的幻想。不同的 PyTorch 版本间的算子核函数更改都会引入细微差别,更不用说不同的硬件可能会因为体系架构不同而产生不同的结果 (而出于成本原因,你可能并不能一直在 A100 GPU 上开发)。
一个好的严格的测试套件对所有模型都非常重要
我们发现,最佳的测试方式是使用一组固定的提示。从测试角度,你知道提示 (prompt),而且你想要为每个提示生成确定性的补全 (completion),所以解码器用贪心搜索就好了。如果两次测试生成的补全是相同的,你基本上可以无视 logits 上的小差异。每当你看到生成的补全发生漂移时,就需要调查原因。可能是你的代码没有做它应该做的事; 也有可能是你的提示不在该模型的知识域内 [译者注: 即模型的训练数据中并不包含提示所涉及的话题],所以它对噪声更敏感。如果你有多个提示且提示足够长,不太可能每个提示都触发上述不在知识域的问题。因此,提示越多越好,越长越好。
第一个模型 (small-testing) 和大 BLOOM 一样,精度是 bfloat16 的。我们原以为两者应该非常相似,但由于小模型没有经过太多训练或者单纯只是性能差,最终表现出来的结果是它的输出波动很大。这意味着我们用它进行生成测试会有问题。第二个模型更稳定,但模型数据精度是 float16 而不是 bfloat16,因此两者间的误差空间更大。
公平地说,推理时将 bfloat16 模型转换为 float16 似乎问题不大 ( bfloat16 的存在主要是为了处理大梯度,而推理中不存在大梯度)。
在此步骤中,我们发现并实现了一个重要的折衷。因为 BLOOM 是在分布式环境中训练的,所以部分代码会对 Linear 层作张量并行,这意味着在单 GPU 上运行相同的操作会得到 不同的数值结果。我们花了一段时间才查明这个问题。这个问题没办法彻底解决,要么我们追求 100% 的数值一致性而牺牲模型运行速度,要么我们接受每次生成时都会出现一些小的差异但运行速度更快,代码更简单。我们为此设了一个标志位供用户自己配置。
首次推理 (PP + Accelerate)
注意: 这里,流水线并行 (Pipeline Parallelism, PP) 意味着每个 GPU 将分得模型的一些层,因此每个 GPU 将完成一部分操作,然后再将其结果交给下一个 GPU。现在我们有了一个能支持 BLOOM 的 transformers,我们可以开始跑了。
BLOOM 是一个 352GB (176B bf16 参数) 的模型,我们至少需要那么多显存才能放下它。我们花了一点时间试了试在小显存的 GPU 上使用 CPU 卸载的方式来推理,但是推理速度慢了几个数量级,所以我们很快放弃了它。
然后,我们转而想使用 transformers 的 pipeline API,吃一下这个 API 的狗粮。然而, pipeline 不是分布式感知的 (这不是它的设计目标)。
经过短暂的技术方案讨论,我们最终使用了 accelerate 的新功能 device_map="auto 来管理模型的分片。我们不得不解决一些 accelerate 以及 transformers 的 bug,才使得这一方案能正常工作。
它的工作原理是将 transformer 模型按层进行切分,每个 GPU 分到一些层。真正运行时,是 GPU0 先开始工作,然后将结果交给 GPU1,依次下去。
最后,在前端架一个小型 HTTP 服务器,我们就可以开始提供 BLOOM (大模型) 推理服务了!!
起点
至此,我们甚至还没有开始讨论优化!
我们其实做了不少优化,这一切过程有点像纸牌叠城堡游戏。在优化期间,我们将对底层代码进行修改,所以一定要确保我们不会以任何方式破坏模型,这一点非常重要,而且其实比想象中更容易做到。
优化的第一步是测量性能。在整个优化过程中,性能测量贯穿始终。所以,首先需要考虑我们需要测量什么,也即我们关心的是什么。对于一个支持多种选项的开放式推理服务而言,用户会向该服务发送各种不同的查询请求,我们关心的是:
- 我们可以同时服务的用户数是多少 (吞吐量)?
- 我们平均为每个用户服务的时间是多少 (延迟)?
我们用 locust 做了一个测试脚本,如下:
from locust import HttpUser, between, task
from random import randrange, random
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {"max_new_tokens": 20, "seed": random()},
},
)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {
"max_new_tokens": 20,
"do_sample": True,
"top_p": 0.9,
"seed": random(),
},
},
)注意: 这不是我们最佳的也不是唯一的负载测试,但始终是我们第一个运行的负载测试,因此它可用于公平地比较不同方案。在此基准测试表现最好并不意味着它绝对是最好的解决方案。我们还需要使用其他更复杂的测试场景来模拟真实场景的真实性能。
我们想观察各种实现方案部署时如何爬坡,并确保在熔断时适当地降低服务器负载。熔断意味着原本能 (快速) 响应你的请求的服务不再响应你的请求,因为同一时间有太多人想要使用它。避免 死亡之拥 (hug of death) 是极其重要的。[译者注: 死亡之拥是一个互联网领域的隐喻,意指由于极端峰值流量而导致互联网服务宕机]
在上述基准测试中,我们得到的初始性能是 (使用 GCP 上的 16xA100 40G 环境测得,本文后续所有测试都基于该环境):
每秒处理请求数 (吞吐量): 0.3
每词元延迟: 350ms
这两个值并不是很好。在正式开始工作之前,我们可以预估一下我们能得到的最好结果。BLOOM 模型所需的计算量公式为 $24Bsh^2 + 4Bs^2h * 24Bsh^2 + 4Bs^2h$,其中 B 是 batch size, s 是序列长度, h 是隐含层维度。
让我们算一下,一次前向传播需要 17 TFlop。A100 的 规格 为单卡 312 TFLOPS。这意味着单个 GPU 最多能达到 17 / 312 = 54 毫秒/词元 的延迟。我们用了 16 个 GPU,因此可得 3 毫秒/词元。这只是个上限,我们永远不可能达到这个值,况且现实中卡的性能很少能达到其规格所宣称的数字。此外,如果你的模型并不受限于计算 [译者注: 如受限于内存带宽、受限于 IO 带宽等],那么这个值你也达不到。知道理想值,只是为了让我们对优化目标心里有个数。在这里,我们到目前为止与理想值差 2 个数量级。此外,这个估计假设你将所有算力都用于延迟型服务,这意味着一次只能执行一个请求 (没关系,因为你正在最大化你的机器利用率,所以没有太多其他事情要做; 但另一个思路是,我们可以牺牲一点延迟,通过批处理方式来获得更高的吞吐量)。
探索多条路线
注意: 这里,张量并行 (Tensor Parallelism,TP) 意味着每个 GPU 将拥有部分权重,因此所有 GPU 始终处于工作状态,专注于分给它的部分工作。通常这会带来非常轻微的开销,因为会有一些工作是重复的,更重要的是,GPU 必须定期相互通信交流它们的结果,然后再继续计算。现在我们已经比较清楚地了解了我们的处境,是时候开始工作了。
我们根据我们自己及其他人的各种经验和知识尝试了各种方法。
每次尝试都值得写一篇专门的博文,由于篇幅所限,在这里我们仅将它们列出来,并只深入解释并研究那些最终应用到当前服务中去的技术的细节。从流水线并行 (PP) 切换到张量并行 (TP) 是延迟优化的一个重要一步。每个 GPU 将拥有部分参数,并且所有 GPU 将同时工作,所以延迟应该会迅速下降。但是付出的代价是通信开销,因为它们的中间结果需要经常互相通信。
需要注意的是,这里涉及的方法相当广泛。我们会有意识地学习更多关于每个工具的知识,以及在后续优化中如何使用它。
将代码移植到 JAX/Flax 中以在 TPU 上运行
- 并行方案的选择更加容易。因此 TP 的测试会更方便,这是 JAX 的设计带来的好处之一。
- 对硬件的限制更多,JAX 上 TPU 的性能可能比 GPU 更好,但 TPU 比 GPU 更难获取 (只在 GCP 上有,数量也没有 GPU 多)。
- 缺点: 需要移植工作。但无论如何,把它集成到我们的库里面这件事肯定是受欢迎的。
结果:
- 移植比较麻烦,因为某些条件语句和核函数很难准确复制,但尚可勉力为之。
- 一旦移植完后,测试各种并行方案就比较方便。感谢 JAX,没有食言。
事实证明,在 Ray 集群里与 TPU worker 通信对我们来讲真的太痛苦了。
不知道是工具原因还是网络的原因,或者仅仅是因为我们不太懂,但这事实上减慢了我们的实验速度,而且需要的工作比我们预期的要多得多。
我们启动一个需要 5 分钟时间运行的实验,等了 5 分钟没有发生任何事情,10 分钟之后仍然没有任何事情发生,结果发现是一些 TPU worker 宕机了或者是没有响应。我们不得不手动登进去看,弄清楚发生了什么,修复它,重启一些东西,最后再重新启动实验,就这样半小时过去了。几次下来,几天就没了。我们再强调一下,这未必真的是我们使用的工具的问题,但我们的主观体验确实如此。无法控制编译
我们运行起来后,就尝试了几种设置,想找出最适合我们心目中想要的推理性能的设置,结果证明很难从这些实验中推测出延迟/吞吐量的规律。例如,在 batch_size=1 时吞吐量有 0.3 RPS (Requests Per Second, RPS) (此时每个请求/用户都是独立的),延迟为 15 毫秒/词元 (不要与本文中的其他数字进行太多比较,TPU 机器与 GPU 机器大不相同),延迟很好,但是总吞吐量跟之前差不多。所以我们决定引入批处理,在 batch_size=2 的情况下,延迟增加到原来的 5 倍,而吞吐量只提高到原来的 2 倍…… 经过进一步调查,我们发现一直到 batch_size=16,每个 batch_size 之间的延迟都差不多。
因此,我们可以以 5 倍的延迟为代价获得 16 倍的吞吐量。看上去挺不错的,但我们更希望对延迟有更细粒度的控制,从而使得延迟能满足 100ms, 1s, 10s, 1mn 规则中的各档。
使用 ONNX/TRT 或其他编译方法
- 它们应该能处理大部分优化工作
- 缺点: 通常需要手动处理并行性
结果:
事实证明,为了能够 trace/jit/export 模型,我们需要重写 PyTorch 相关的一部分代码,使其能够很容易与纯 PyTorch 方法相融合。总体来讲,我们发现我们可以通过留在 PyTorch 中获得我们想要的大部分优化,使我们能够保持灵活性而无需进行太多编码工作。另一件值得注意的事情是,因为我们在 GPU 上运行,而文本生成有很多轮前向过程,所以我们需要张量留在 GPU 上,有时很难将你的张量输给某个库,返回结果,计算 logits (如 argmax 或采样),再回输给那个库。
将循环放在外部库里面意味着像 JAX 一样失去灵活性,这不是我们设想的推理服务应用场景的使用方法。
DeepSpeed
- 这是我们训练 BLOOM 时使用的技术,所以用它来推理也很公平
- 缺点: DeepSpeed 之前从未用于推理,其设计也没准备用于推理
结果:
- 我们很快就得到了很不错的结果,这个结果与我们现行方案的上一版性能大致相同。
- 我们必须想出一种方法,在多进程上架设用于处理并发请求网络服务,因为现在一个推理任务是由多个 DeepSpeed 进程完成的 (每个 GPU 一个进程),。有一个优秀的库 Mii 可供使用,它虽然还达不到我们所设想的极致灵活的目标,但我们现在可以在它之上开始我们的工作。(当前的解决方案稍后讨论)。
我们在使用 DeepSpeed 时遇到的最大问题是缺乏稳定性。
我们在 CUDA 11.4 上运行基于 11.6 编译的代码时遇到了问题。而其中一个由来已久的、我们永远无法真正解决的问题是: 经常会发生核函数崩溃 (CUDA 非法访问、尺寸不匹配等)。我们修复了其中一些问题,但在压测我们的网络服务时,我们永远无法完全实现稳定性。尽管如此,我想向帮助过我们的 Microsoft 人员说,感谢那些非常愉快的交流,它们提高了我们对正在发生的事情的理解,并为我们的后续工作提供了真知灼见。
- 另一个痛点是我们的团队主要在欧洲,而微软在加利福尼亚,所以合作时间很棘手,我们因此损失了大量时间。这与技术部分无关,但我们确实认识到合作的组织部分也非常重要。
- 另一件需要注意的事情是,DeepSpeed 依赖于
transformers来注入其优化,并且由于我们一直在更新我们的代码,这使得 DeepSpeed 团队很难在我们的主分支上工作。很抱歉让它变得困难,这也可能是transformers被称为技术最前沿的原因。
有关 Web 服务的想法
- 鉴于我们准备运行一个免费服务,支持用户向该服务发送长短不一的文本,并要求获取短至几个词,长至如整个食谱那么长的回应,每个请求的参数也可以各不相同,web 服务需要做点什么来支持这个需求。
结果:
- 我们使用绑定库 tch-rs 在
Rust中重写了所有代码。Rust 的目标不是提高性能,而是对并行性 (线程/进程) 以及 web 服务和 PyTorch 的并发性进行更细粒度的控制。由于 GIL 的存在,Python 很难处理这些底层细节。 - 结果表明,大部分的痛苦来自于移植工作,移植完后,实验就轻而易举了。我们认为,通过对循环进行精确的控制,即使在具有大量不同属性的请求的场景中,我们也可以为每个请求提供出色的性能。如果你感兴趣的话,可以查看 代码,但这份代码没有任何支持,也没有好的文档。
- Rust web 服务投入生产了几周,因为它对并行性的支持更宽松,我们可以更有效地使用 GPU (如使用 GPU0 处理请求 1,而 GPU1 处理请求 0)。在保持延迟不变的情况下,我们把吞吐从 0.3 RPS 提高到了 ~2.5 RPS。虽然在最理想情况下,我们能将吞吐提高到 16 倍。但实际工作负载上的测出来能到 8 倍左右的话也还算不错。
纯 PyTorch
- 纯粹修改现有代码,通过删除诸如
reshape之类的操作、使用更优化的核函数等方法来使其运行速度更快。 - 缺点: 我们必须自己编写 TP 代码,并且我们还有一个限制,即修改后代码最好仍然适合我们的库 (至少大部分)。
结果
- 在下一章详述。
最终路线: PyTorch + TP + 1 个自定义内核 + torch.jit.script
编写更高效的 PyTorch
第一件事是在代码中删除不必要的操作。可以通过代码走查并找出明显可被删除的某些操作:
- Alibi 在 BLOOM 中用于添加位置嵌入 (position embeddings),源代码中计算 Alibi 的地方太多,每次都重新计算一次,我们优化成只计算一次,这样效率更高。
旧代码: 链接
新代码: 链接
这个改动获得了 10 倍的加速,最新版本还增加了对填充 (padding) 的支持!
由于此步骤仅计算一次,因此在这里,运算本身实际速度并不重要,而总体上减少操作和张量创建的次数更重要。
当你开始 剖析 代码性能时,其他部分会越来越清晰,我们大量地使用了 tensorboard 来帮助我们进行性能剖析。它提供了如下图所示的这类图像,可以提供有关性能的洞见:
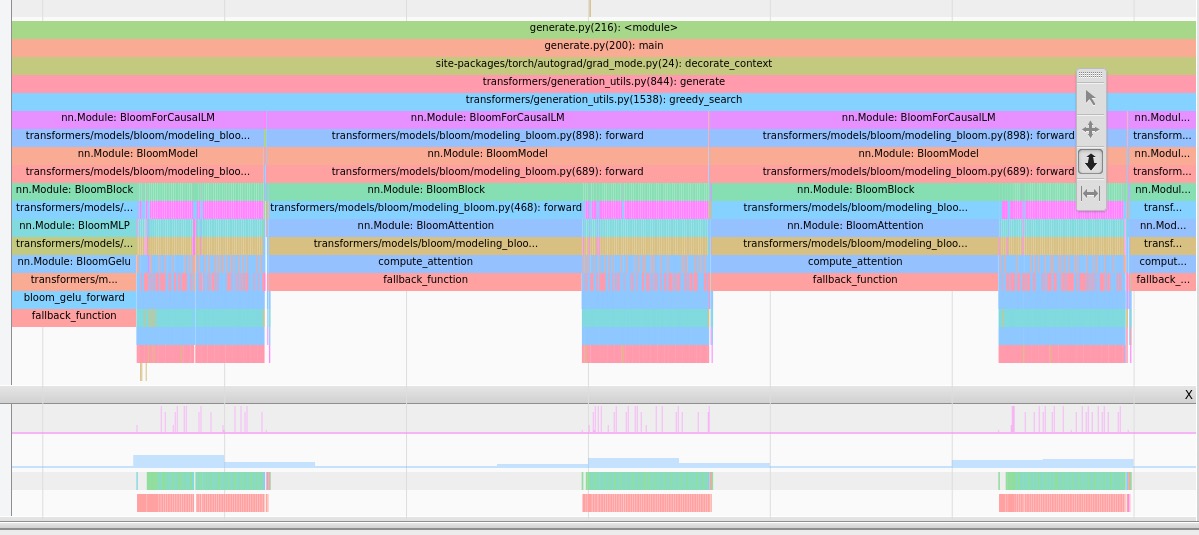
注意力层占用了很多时间,注意这是一个 CPU 视图,所以条形很长并不意味着核函数执行时间很长,它只意味着 CPU 正在等待上一步的 GPU 结果。

我们还在 baddbmm 操作之前看到许多 cat 操作。
再举个例子,在删除大量 reshape / transpose 后,我们在 tensorboard 中发现:
- 注意力是性能热点 (这是预期的,但能够通过测量数据来验证总是好的)。
- 在注意力中,由于大量的 reshape,很多核函数其实是显存拷贝函数。
- 我们 可以 通过修改权重和
past_key_values的内存布局来移除reshape。这个改动有点大,但性能确实有一定的提高!
支持 TP
好了,我们已经拿到了大部分唾手可得的成果,现在我们的 PP 版本的延迟从大约 350 毫秒/词元降低到 300 毫秒/词元。延迟降低了 15%,实际情况收益更大,但由于我们最初的测量并不是非常严格,所以就用这个数吧。
然后我们继续实现一个 TP 版。进度比我们预期的要快得多,一个 (有经验的) 开发人员仅花了半天时间就实现出来了,代码见 此处。在此过程中,我们还重用了一些其他项目的代码,这对我们很有帮助。
延迟从 300 毫秒/词元直接变为 91 毫秒/词元,这是用户体验的巨大改进。
一个简单的 20 个词元的请求延迟从 6 秒变成了 2 秒,用户体验直接从“慢”变成了轻微延迟。
此外,吞吐量上升了很多,达到 10 RPS。 batch_size=1 和 batch_size=32 延迟基本相同,因此,从这种意义上来讲,在相同的延迟下,吞吐量的上升基本上是 免费 的。
唾手可得的果实
现在我们有了一个 TP 版本的实现,我们可以再次开始进行性能剖析和优化。因为并行方案发生了改变,我们有必要再从头开始分析一遍。
首先,同步 ( ncclAllReduce) 开始成为主要热点,这符合我们的预期,同步需要花时间。但我们不打算优化这一部分,因为它已经使用了 nccl。虽然可能还有一些改进空间,但我们认为我们很难做得更好。
第二个是 Gelu 算子,我们可以看到它启动了许多 element-wise 类的核函数,总体而言它占用的计算份额比我们预期的要大。
我们对 Gelu 作了如下修改:
从
def bloom_gelu_forward(x):
return x * 0.5 *(1.0 + torch.tanh(0.79788456 * x *(1 + 0.044715 * x * x)))改成了
@torch.jit.script
def bloom_gelu_forward(x):
return x * 0.5 *(1.0 + torch.tanh(0.79788456 * x *(1 + 0.044715 * x * x)))我们使用 jit 将许多小的 element-wise 核函数融合成了一个核函数,从而节省了核函数启动开销和内存拷贝开销。
该优化降低了 10% 的延迟,从 91 毫秒/词元到 81 毫秒/词元,搞定!
不过要小心,这种方法可不是任何时候都有效,算子融合不一定每次都会发生。另外如果原来的算子实现已经非常高效了,就算融合了也不能带来很多的增益。
我们发现它在下面几个场合有用:
- 你有很多小的、
element-wise的操作 - 你的性能热点里有一些难以去除的
reshape算子,这些算子一般就是拷贝 - 算子能融合时
滑铁卢
在测试期间,有一段时间,我们观察到 Rust 服务的延迟比 Python 服务低 25%。这很奇怪,但因为它们的测试环境是一致的,而且去除了核函数后我们还是能测到这个速度增益,我们开始感觉,也许降低 Python 开销可以带来不错的性能提升。
我们开始了为期 3 天的重新实现 torch.distributed 部分代码的工作,以便在 Rust 里运行 nccl-rs。代码能工作,但生成的句子与 Python 版有些不一样,于是我们开始调查这些问题,就在这个过程中,我们发现 …… 在测量 PyTorch 版性能时,我们忘记删除 PyTorch 里的 profiler 代码了 ……
我们遭遇了滑铁卢,删除 profiler 代码后延迟降低了 25%,两份代码延迟一样了。其实我们最初也是这么想的,Python 一定不会影响性能,因为模型运行时运行的主要还是 torch cpp 的代码。虽然 3 天其实也不算啥,但发生这样的事还是挺糟糕的。
针对错误的或不具代表性的测量数据进行优化,这很常见,优化结果最终会令人失望甚至对整个产品带来反效果。这就是为什么 小步快走 以及 设立正确预期有助于控制这种风险。
另一个我们必须格外小心的地方是产生第一个新词的前向过程 [译者注: 第一个新词 past_key_values 为 None ] 和产生后续新词的前向过程 [译者注: 此时 past_key_values 不为空] 是不一样的。如果你只针对第一个词优化,你反而会拖慢后续的那些更重要并且占大部分运行时间的词的生成时间。
另一个很常见的罪魁祸首是测量时间,它测量的是 CPU 时间,而不是实际的 CUDA 时间,因此运行时需要用 torch.cuda.synchronize() 来确保 GPU 执行完成。
定制核函数
到目前为止,我们已经实现了接近 DeepSpeed 的性能,而无需任何自定义代码!很简约。我们也不必在推理 batch size 的灵活性上做出任何妥协!
但根据 DeepSpeed 的经验,我们也想尝试编写一个自定义核函数,以对 torch.jit.script 无法完成融合的一些操作进行融合。主要就是下面两行:
attn_weights = attention_scores.masked_fill_(attention_mask, torch.finfo(attention_scores.dtype).min)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)第一个 masked_fill_ 是创建一个新的张量,这里只是告诉 softmax 运算符忽略这些值。此外,softmax 需要在 float32 上计算 (为了数值稳定性),但在自定义核函数中,我们可以减少向上数据类型转换的次数,仅在求和及累加时转换。
你可以在 此处 找到我们的代码。
请记住,我们的优化只针对一个特定的 GPU 架构 (即 A100),所以该核函数不适用于其他 GPU 架构; 同时我们也不是编写核函数的专家,因此很有可能有更好的实现方法。
这个自定义核函数又提供了 10% 的延迟提升,延迟从 81 毫秒/词元降低到 71 毫秒/词元。同时,我们继续保持了灵活性。
在那之后,我们调查、探索了更多优化手段,比如融合更多的算子来删除剩下的 reshape 等等。但还没有哪个手段能产生足够大的提升而值得被放入最终版本。
Web 服务部分
就像我们在 Rust 里做的一样,我们必须实现对具有不同参数的请求的批处理。由于我们处于 PyTorch 世界中,我们几乎可以完全控制正在发生的事情。
而又由于我们处于 Python 世界中,我们有一个限制因素,即 torch.distributed 需要多进程而不是多线程运行,这意味着进程之间的通信有点麻烦。最后,我们选择通过 Redis 发布/订阅来传递原始字符串,以便同时将请求分发给所有进程。因为我们处于不同的进程中,所以这样做比进行张量通信更容易、通信量也很小。
然后我们不得不放弃使用 generate 函数,因为这会将参数应用于 batch 中所有的序列,而实际上每个序列的参数可能各不相同。值得庆幸的是,我们可以重用较底层的 API ,如 LogitsProcessor,以节省大量工作。因此,我们重构了一个 generate 函数,它接受一个参数列表并将列表中的参数分别应用于 batch 中的各个序列。
最终用户体验主要还是看延迟。由于我们支持不同的请求有不同的参数,因此可能出现这样的情况: 一个请求想要生成 20 个词元,而另一个请求想要生成 250 个词元。由于每个词元需要 75 毫秒的延迟,因此一个请求需要 1.5 秒,而另一个需要 18 秒。如果我们一直进行批处理的话,我们会让第一个用户等待 18 秒,因此看起来好像我们正在以 900 毫秒/词元的速度运行,太慢了!
由于我们处于具有极大灵活性的 PyTorch 世界中,我们可以做的是在生成前 20 个词元后立即从批处理中提取第一个请求,并在 1.5 秒内返回给该用户!这同时也节省了 230 个词元的计算量。
因此,灵活性对于获得最佳延迟非常重要。
最后的笔记和疯狂的想法
优化是一项永无止境的工作,与任何其他项目一样,20% 的工作通常会产生 80% 的结果。
从某个时间点开始,我们开始制定一个小的测试策略来确定我们的某个想法的潜在收益,如果测试没有产生显著的结果,我们就会放弃这个想法。1 天增加 10% 足够有价值,2 周增加 10 倍也足够有价值。2 周提高 10% 就算了吧。
你试过……吗?
由于各种原因,有些方法我们知道但我们没使用的。可能原因有: 感觉它不适合我们的场景、工作量太大、收益潜力不够大、或者甚至仅仅是因为我们有太多的选择要试而时间不够所以就放弃了一些。以下排名不分先后:
- CUDA graphs
- nvFuser (它是
torch.jit.script的后端,所以从这个角度来讲,我们也算用了它。) - FasterTransformer
- Nvidia’s Triton
- XLA (JAX 也使用 XLA!)
- torch.fx
- TensorRT
如果你最喜欢的工具没有列在这儿,或者你认为我们错过了一些可能有用的重要工具,请随时与我们联系!
Flash attention
我们简单集成过 flash attention,虽然它在生成第一个词元 (没有 past_key_values) 时表现非常好,但在有了 past_key_values 后,它并没有产生太大的改进。而且如果我们要用上它,我们需要对其进行调整以支持 alibi 张量的计算。因此我们决定暂时不做这项工作。
OpenAI Triton
Triton 是一个用于在 Python 中构建定制核函数的出色框架。我们后面打算多用它,但到目前为止我们还没有。我们很想知道它的性能是否优于我们手写的 CUDA 核函数。当时,在做方案选择时,我们认为直接用 CUDA 编写似乎是实现目标的最短路径。
填充和 reshape
正如本文通篇所提到的,每次张量拷贝都有成本,而生产环境中运行时的另一个隐藏成本是填充。当两个查询的长度不同时,你必须使用填充 (使用虚拟标记) 以使它们等长。这可能会导致很多不必要的计算。更多信息。
理想情况下,我们可以永远 不 做这些计算,永远不做 reshape。
TensorFlow 有 RaggedTensor 而 PyTorch 也有 嵌套张量 的概念。这两者似乎都不像常规张量那样精简,但能使我们的计算更好,这对我们有好处。
理想的情况下,整个推理过程都可以用 CUDA 或纯 GPU 代码来实现。考虑到我们在融合算子时看到性能改进,这种方法看起来很诱人。但我们不知道性能提升能到什么程度。如果有更聪明的 GPU 专家知道,我们洗耳恭听!
致谢
所有这些工作都是许多 HF 团队成员合作的结果。以下排名不分先后, @ThomasWang @stas
@Nouamane @Suraj
@Sanchit @Patrick
@Younes @Sylvain
@Jeff (Microsoft) @Reza
以及 BigScience 项目中的所有人。
英文原文: https://hf.co/blog/bloom-inference-optimization
作者: Nicolas Patry
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
排版/审校: zhongdongy (阿东)