HTTP协议 | 一文详解HTTP报文结构
目录
HTTP/HTTPS简介
HTTP工作原理
HTTP三点注意事项
1. HTTP是无连接的
2. HTTP是媒体独立的
3. HTTP是无状态的
HTTPS 作用
HTTP消息结构
HTTP请求消息
1. 请求行
2. 请求头
3. 空行
4. 请求数据
HTTP请求实例
HTTP请求GET和POST的区别
1. 传输数据的方式不同
2. 传输数据的大小不同
3. POST比GET安全性更高
HTTP响应消息
1. 状态行
2. 响应头
3. 空行
4. 响应正文
HTTP消息头(补充)
1. 请求头
2. 响应头
HTTP content-Type
HTTP的工作流程

![]()
HTTP/HTTPS简介
HTTP 协议是 Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网( WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
HTTP工作在 TCP/IP协议体系中的TCP协议上,是一个基于 TCP/IP 通信协议来传递数据(HTML 文件、图片文件、查询结果等)。
HTTPS 协议是 HyperText Transfer Protocol Secure(超文本传输安全协议)的缩写,是一种通过计算机网络进行安全通信的传输协议。
HTTPS 经由 HTTP 进行通信,但利用 SSL/TLS 来加密数据包,HTTPS 开发的主要目的,是提供对网站服务器的身份认证,保护交换资料的隐私与完整性。
HTTP 的 URL 是由 http:// 起始与默认使用端口 80,而 HTTPS 的 URL 则是由 https:// 起始与默认使用端口443。
HTTP中最重要的就是HTTP协议格式,分为请求协议和响应协议。通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。客户端发送给服务器的格式叫“请求协议(request)”;服务器发送给客户端的格式叫“响应协议(response)”。
客户机和服务器必须都支持 HTTP,才能在 万维网上发送和接收 HTML 文档并进行交互。
现在WWW中使用的是HTTP/1.1,它是由RFCs(Requests for comments)在1990年6月制定。目前交由IETF(Internet Engineering Task Force) 和W3C(World Wide Web)负责修改。但最终还是由RFCs对外发布。

HTTP工作原理
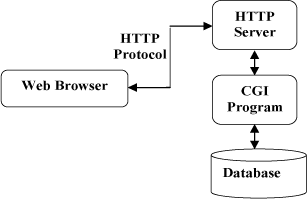
HTTP 协议工作于客户端-服务端架构上。
浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求。
Web 服务器有:Apache 服务器,IIS 服务器(Internet Information Services)等。
Web 服务器根据接收到的请求后,向客户端发送响应信息。
HTTP 默认端口号为 80,但是你也可以改为 8080 或者其他端口。
HTTP三点注意事项
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP协议有以下特点
1. HTTP是无连接的
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
注意:HTTP1.1版本后支持可持续连接。
通过这种连接,就有可能在建立一个TCP连接后,发送请求并得到回应,然后发送更多的请求并得到更多的回应。通过把建立和释放TCP连接的开销分摊到多个请求上,则对于每个请求而言,由于TCP而造成的相对开销被大大地降低了。而且,还可以发送流水线请求,也就是说在发送请求1之后的回应到来之前就可以发送请求2,也可以认为,一次连接发送多个请求,由客户机确认是否关闭连接,而服务器会认为这些请求分别来自不同的客户端。
2. HTTP是媒体独立的
这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
灵活:HTTP允许传输任意类型的数据对象。传输的类型由Content-Type加以标记。
3. HTTP是无状态的
HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
以下图表展示了 HTTP 协议通信流程:
HTTPS 作用
HTTPS 的主要作用是在不安全的网络上创建一个安全信道,并可在使用适当的加密包和服务器证书可被验证且可被信任时,对窃听和中间人攻击提供合理的防护。
HTTPS 的信任基于预先安装在操作系统中的证书颁发机构(CA)。
因此,与一个网站之间的 HTTPS 连线仅在这些情况下可被信任:
- 浏览器正确地实现了 HTTPS 且操作系统中安装了正确且受信任的证书颁发机构;
- 证书颁发机构仅信任合法的网站;
- 被访问的网站提供了一个有效的证书,也就是说它是一个由操作系统信任的证书颁发机构签发的(大部分浏览器会对无效的证书发出警告);
- 该证书正确地验证了被访问的网站(例如,访问 https://www.runoob.com 时收到了签发给 www.runoob.com 而不是其它域名的证书);
- 此协议的加密层(SSL/TLS)能够有效地提供认证和高强度的加密。
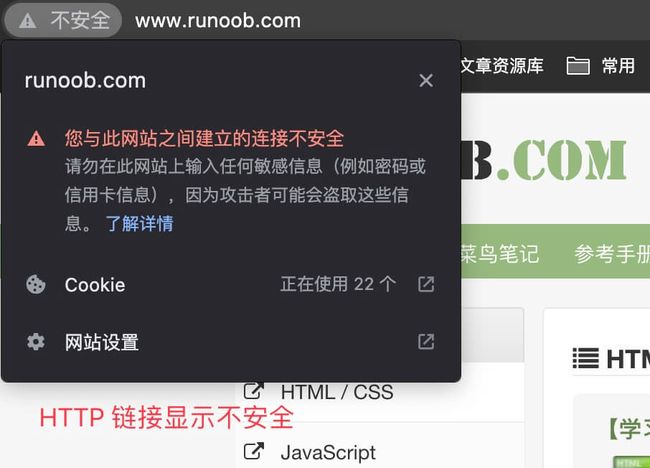
Google Chrome、Internet Explorer 和 Firefox 等浏览器在网站含有由加密和未加密内容组成的混合内容时,会发出警告。
HTTP 链接显示不安全:
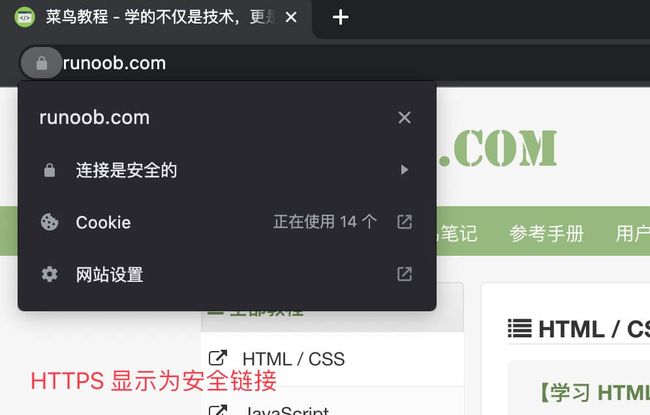
HTTPS 链接显示为安全:
◼️ 更多参考:HTTP/HTTPS 简介 | 菜鸟教程
HTTP消息结构
 HTTP协议格式
HTTP协议格式
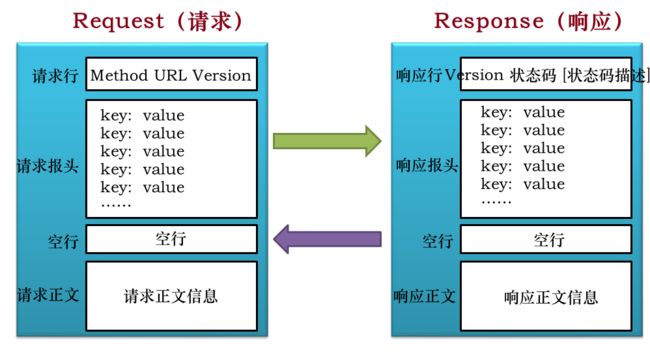
HTTP报文,又称为HTTP消息,是服务器和客户端之间交换数据的方式。有两种类型的消息:请求,由客户端发送用来触发一个服务器上的动作;响应,来自服务器的应答。
HTTP消息由采用ASCII编码的多行文本构成。在HTTP/1.1及早起版本中,这些消息通过连接公开地发送。在HTTP/2中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个HTTP帧中。
HTTP请求消息
一个HTTP请求报文(也称请求消息)由请求行(request line)、请求头(header)、空行和请求数据(也称请求体)4个部分组成,下图给出了请求报文的一般格式。
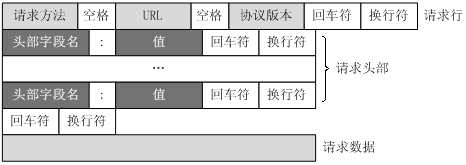
请求行
请求头1
请求头2
……
请求空行
请求体1. 请求行
请求行(也称请求起始行)由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。
请求行格式如下:Method空格Request-URI空格HTTP-Version CRLF
- Method 表示请求方法;
- Request-URl 表示一个统一资源标识符;
- HTTP-Version 表示请求的 HTTP 协议版本;
- CRLF表示回车和换行;
例如,GET /index.html HTTP/1.1。
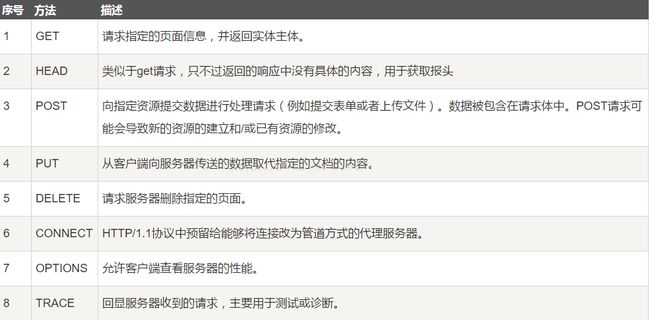
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP1.0定义了三种请求方法: GET,POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE 和 CONNECT 方法。
关于HTTP-PATCH请求
1、也许你常用的HTTP请求方式就是GET、POST,有的人会用过DELETE、PUT,其实在HTTP1.1中提到过更多的方法。PATCH在早期的HTTP文档 RFC2616中提到过 ,但是却没有完全定义它,直到2010年的RFC5789规范中才真正定义了新的HTTP1.1方法-PATCH。2、PUT和PATCH的区别
PATCH方法用于资源的部分内容的更新;PUT用于更新某个较为完整的资源;
◼️ 参考资料:HTTP-PATCH请求 | PATCH和八大请求类型
而常见的有如下几种:
1). GET
最常见的一种请求方式,当客户端要从服务器中读取文档时,当点击网页上的链接或者通过在浏览器的地址栏输入网址来浏览网页的,使用的都是GET方式。GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。
使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例如,/index.jsp?id=100&op=bind,这样通过GET方式传递的数据直接表示在地址中,所以我们可以把请求结果以链接的形式发送给好友。
以用google搜索domety为例,Request格式如下:
GET /search?hl=zh-CN&source=hp&q=domety&aq=f&oq= HTTP/1.1
Accept:image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint,application/msword,application/x-silverlight,application/x-shockwave-flash, */*
Referer:http://www.google.cn/
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)
Host:www.google.cn
Connection: Keep-Alive
Cookie:PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g;NID=31=ojj8d-IygaEtSxLgaJmqSjVhCspkviJrB6omjamNrSm8lZhKy_yMfO2M4QMRKcH1g0iQv9u-2hfBW7bUFwVh7pGaRUb0RnHcJU37y-FxlRugatx63JLv7CWMD6UB_O_r 可以看到,GET方式的请求一般不包含”请求内容”部分,请求数据以地址的形式表现在请求行。地址链接如下:
http://www.google.cn/search?hl=zh-CN&source=hp&q=domety&aq=f&oq= 地址中”?”之后的部分就是通过GET发送的请求数据,我们可以在地址栏中清楚的看到,各个数据之间用”&”符号隔开。显然,这种方式不适合传送私密数据。另外,由于不同的浏览器对地址的字符限制也有所不同,一般最多只能识别2048个字符,所以如果需要传送大量数据的时候,也不适合使用GET方式,应换为POST请求方式。
◼️ 番外:你搞清楚了吗?| GET请求方式的长度限制到底是多少
在大多数人的一贯认识中,一直认为get请求方式有2048B的长度限制,其实这种说法是有失偏颇的,也可以说是错误的。
这个问题一直以来似乎是被N多人误解,其实Http Get方法提交的数据大小长度并没有限制,而是IE浏览器本身对地址栏URL长度有最大长度限制:2048个字符。这在HTTP协议规范RFC-2616中也有提到。
协议规范中虽然未对GET请求的url长度做出明确的限制规定,但是在主流的用户代理浏览器和应用服务器中对GET请求却做出限制或者相关的可配置。也就是说在真正实现中,url的长度还是受到限制的,一是服务器端的限制,二就是浏览器览器端的限制。
1、Http协议规范中对于get方法提交的URL数据长度并没有明确的限制
目前说的get提交方式有长度限制,是特定的浏览器及服务器对它的限制。各种浏览器和服务器的最大处理能力如下:
浏览器
-
IE浏览器(Microsoft Internet Explorer) 对url长度限制是2083(2K+53)个字符,超过这个限制,则自动截断(若是form提交则提交按钮不起作用,没有任何反应)。
-
Safari:url最大长度限制为80000个字符。
-
Opera:url最大长度限制为190000个字符。
-
Chrome:url最大长度限制为8182个字符。超过最大限制则服务器会返回上面列出的414错误。
-
Firefox:对Firefox浏览器url的长度限制为:65536个字符。
所以,大多数浏览器的限制在2k-8k之间,更老的版本浏览器甚至只支持255 bytes。
服务器
-
Apache能接受url长度限制为8192字符
-
Microsoft Internet Information Server(IIS):n能接受最大url的长度为16384个字符。
-
tomcat中通过较多的Connector参数控制url长度限制:
maxParameterCount:GET和POST请求参数个数,默认是10000
maxPostSize:POST请求数据最大值 -
nginx可以通过修改配置来改变url请求串的url长度限制:
client_header_buffer_size 默认值:1k
large_client_header_buffers默认值:4k或8k
所以,大多数Web服务器的限制为8192字节(8KB),通常可以在服务器配置中的某个位置进行配置
2、理论上讲,post是没有大小限制的。Http协议规范也没有进行大小限制,起限制作用的是服务器处理程序的处理能力。
Tomcat下默认post长度为2M,可通过修改conf/server.xml中的“maxPostSize=0”来取消对post大小的限制。
更多相关参考:GET请求方式的长度限制到底是多少?| URL长度限制
◼️ 注意:(若长度超限,则服务端返回414标识)
1、首先即使有长度限制,也是限制的是整个URI长度,而不仅仅是你的参数值数据长度。
2、HTTP协议从未规定GET/POST的请求长度限制是多少
3、所谓的请求长度限制是由浏览器和web服务器决定和设置的,浏览器和web服务器的设定均不一样,这依赖于各个浏览器厂家的规定或者可以根据web服务器的处理能力来设定。
2). POST
对于上面提到的不适合使用GET方式的情况,可以考虑使用POST方式,因为使用POST方法可以允许客户端给服务器提供信息较多。POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据,这样POST方式对传送的数据大小没有限制,而且也不会显示在URL中。还以上面的搜索domety为例,如果使用POST方式的话,格式如下:
POST /search HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint,application/msword, application/x-silverlight, application/x-shockwave-flash, */*
Referer: http://www.google.cn/
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)
Host: www.google.cn
Connection: Keep-Alive
Cookie: PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g;NID=31=ojj8d-IygaEtSxLgaJmqSjVhCspkviJrB6omjamNrSm8lZhKy_yMfO2M4QMRKcH1g0iQv9u-2hfBW7bUFwVh7pGaRUb0RnHcJU37y-FxlRugatx63JLv7CWMD6UB_O_r
hl=zh-CN&source=hp&q=domety 可以看到,POST方式请求行中不包含数据字符串,这些数据保存在”请求内容”部分,各数据之间也是使用”&”符号隔开。
POST方式大多用于页面的表单中。因为POST也能完成GET的功能,因此多数人在设计表单的时候一律都使用POST方式,其实这是一个误区。GET方式也有自己的特点和优势,我们应该根据不同的情况来选择是使用GET还是使用POST。
3). HEAD
HEAD就像GET,只不过服务端接受到HEAD请求后只返回响应头,而不会发送响应内容。当我们只需要查看某个页面的状态的时候,使用HEAD是非常高效的,因为在传输的过程中省去了页面内容。
2. 请求头
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息
-
在HTTP/1.1协议中,所有的请求头,除
post外,都是可选的。 -
请求头是以
key: value的形式现示的。每一个报头域(报头域包括请求头和响应头)都是由名字+”:”+空格+值组成,消息报头域的名字是大小写无关的。 -
请求头里保存的是请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示请求头部分结束。
典型的请求头有:
- Content-Type: 数据类型(text/html等)。
- Content-Length: 请求体Body的长度。
- User-Agent:产生请求的浏览器类型。
声明用户的操作系统和浏览器版本信息
- Accept:客户端可识别的内容类型列表。
- Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。
客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上
- referer: 当前页面是从哪个页面跳转过来的。
- location: 搭配3xx状态码使用,告诉客户端接下来要去哪里访问。
- Cookie: 用于在客户端存储少量信息,通常用于实现会话(session)的功能。
注:浏览器不是根据资源的后缀判断资源的类型,而是通过Content-Type来判断资源的类型。(这是因为WEB服务器中有MIME配置)
3. 空行
一个空行指示所有关于请求的元数据已经发送完毕,即空行标志着请求头的结束,也标志着请求体的开始。空行可以用
\r\n书写。
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。
4. 请求数据
GET方法没有请求体,因为GET方法的请求参数都已经跟在了URL(地址栏)的后面。空行后面的内容都是请求体 ,请求体允许为空字符串. 如果请求体存在, 则在请求头中会有一个Content-Length属性来标识Body的长度。
请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
HTTP请求实例
1).GET
| //请求首行 GET /hello/index.jsp HTTP/1.1 //请求头信息,因为GET请求没有正文 Host: localhost User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-cn,zh;q=0.5 Accept-Encoding: gzip, deflate Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7 Connection: keep-alive Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98 //空行 //因为GET没有正文,所以下面为空 |
2).POST
| // 请求首行 POST /hello/index.jsp HTTP/1.1 //请求头信息 Host: localhost User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-cn,zh;q=0.5 Accept-Encoding: gzip, deflate Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7 Connection: keep-alive Referer: http://localhost/hello/index.jsp Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98 Content-Type: application/x-www-form-urlencoded Content-Length: 14 // 这里是空行 //POST有请求正文 username=hello |
HTTP请求GET和POST的区别
1. 传输数据的方式不同
GET提交:GET参数通过URL传递。
请求的数据会附在URL之后(就是把数据放置在HTTP协议头<request-line>中),以?分割URL和传输数据,多个参数用&连接;例如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0 %E5%A5%BD。如果数据是英文字母/数字,原样发送,如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII。
POST提交:POST放在Request body中。
把提交的数据放置在是HTTP包的包体<request-body>中。上文示例中红色字体标明的就是实际的传输数据。
因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
2. 传输数据的大小不同
首先声明,HTTP协议没有对传输的数据大小进行限制,HTTP协议规范也没有对URL长度进行限制。 而在实际开发中存在的限制主要有:
GET:特定浏览器和服务器对URL长度有限制,例如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。
因此对于GET提交时,传输数据就会受到URL长度的限制。
POST:由于不是通过URL传值,理论上数据不受限。但实际各个WEB服务器会规定对post提交数据大小进行限制,Apache、IIS6都有各自的配置。
3. POST比GET安全性更高
POST的安全性要比GET的安全性高。因为GET传递的参数直接暴露在URL上,所以不能用来传递敏感信息。
注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义,比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为:
(1) GET请求参数会被完整保留在浏览器历史记录里,也就是说会被浏览器主动缓存(cache),而POST中的参数不会被保留。
(2) 其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了。
这个安全其实也是相对的。也就是说如果用get请求,因为有浏览器缓存问题,下次在url中输入这个url的一部分时,浏览器会在地址栏给你选择能匹配这个url的所有地址,举个例子:比如,你之前输入过 http://baidu.com/?username=test&pwd=pwd ,当你在浏览器中输入baidu.com时,浏览器会让你选择所有浏览器缓存过的url而 http://baidu.com/?username=test&pwd=pwd 可能会被选中,这个时候账号密码就暴露了。
番外:关于安全性
我们常听到GET不如POST安全,因为POST用body传输数据,而GET用url传输,更加容易看到。但是从攻击的角度,无论是GET还是POST都不够安全,因为HTTP本身是明文协议。每个HTTP请求和返回的每个byte都会在网络上明文传播,不管是url,header还是body。这完全不是一个“是否容易在浏览器地址栏上看到“的问题。
为了避免传输中数据被窃取,必须做从客户端到服务器的端端加密。业界的通行做法就是https——即用SSL协议协商出的密钥加密明文的http数据。这个加密的协议和HTTP协议本身相互独立。如果是利用HTTP开发公网的站点/App,要保证安全,https是最最基本的要求。
当然,端端加密并不一定非得用https。比如国内金融领域都会用私有网络,也有GB的加密协议SM系列。但除了军队,金融等特殊机构之外,似乎并没有必要自己发明一套类似于ssl的协议。
回到HTTP本身,的确GET请求的参数更倾向于放在url上,因此有更多机会被泄漏。比如携带私密信息的url会展示在地址栏上,还可以分享给第三方,就非常不安全了。此外,从客户端到服务器端,有大量的中间节点,包括网关,代理等。他们的access log通常会输出完整的url,比如nginx的默认access log就是如此。如果url上携带敏感数据,就会被记录下来。但请注意,就算私密数据在body里,也是可以被记录下来的,因此,如果请求要经过不信任的公网,避免泄密的唯一手段就是https。这里说的“避免access log泄漏“仅仅是指避免可信区域中的http代理的默认行为带来的安全隐患。比如你是不太希望让自己公司的运维同学从公司主网关的log里看到用户的密码吧。
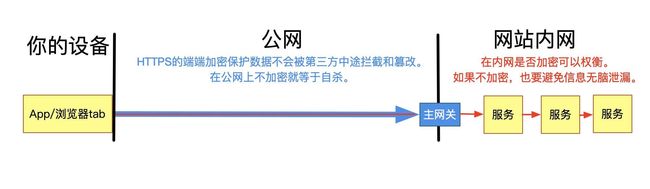
另外,上面讲过,如果是用作接口,GET实际上也可以带body,POST也可以在url上携带数据。所以实际上到底怎么传输私密数据,要看具体场景具体分析。当然,绝大多数场景,用POST + body里写私密数据是合理的选择。一个典型的例子就是“登录”:
POST http://foo.com/user/login
{
"username": "dakuankuan",
"passowrd": "12345678"
}安全是一个巨大的主题,有由很多细节组成的一个完备体系,比如返回私密数据的mask,XSS,CSRF,跨域安全,前端加密,钓鱼,salt,…… POST和GET在安全这件事上仅仅是个小角色。因此单独讨论POST和GET本身哪个更安全意义并不是太大。只要记得一般情况下,私密数据传输用POST + body就好。——资料来源:GET 和 POST 到底有什么区别? - 知乎
总结一下
以下标准答案参考自w3schools
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
◼️ 更多get和post相关:GET 和 POST 到底有什么区别? | get和post请求的区别
HTTP响应消息
HTTP响应也由三个部分组成,分别是:状态行、响应头、空行、响应正文。
状态行
响应头1
响应头2
……
响应空行
响应体1. 状态行
正如你所见,在响应中唯一真正的区别在于第一行中用状态信息代替了请求信息。状态行(status line)通过提供一个状态码来说明所请求的资源情况。
状态行包括:协议版本,状态码,[状态码说明],状态行格式如下:
HTTP-Version空格Status-Code空格Reason-Phrase CRLF
- HTTP-Version表示服务器HTTP协议的版本,例如为HTTP/1.1;
- Status-Code表示服务器发回的响应状态代码,例如200;
Status-Code用于机器自动识别,Reason-Phrase用于人工理解。Status-Code可以省略。 Status-Code的第一个数字代表响应类别,可能取5个不同的值。 后两个数字没有分类作用。 Status-Code的第一个数字代表响应的类别,后续两位描述在该类响应下发生的具体状况。
- Reason-Phrase表示状态代码的文本描述,解释Status-Code的具体原因。
例如:HTTP/1.1 200 OK

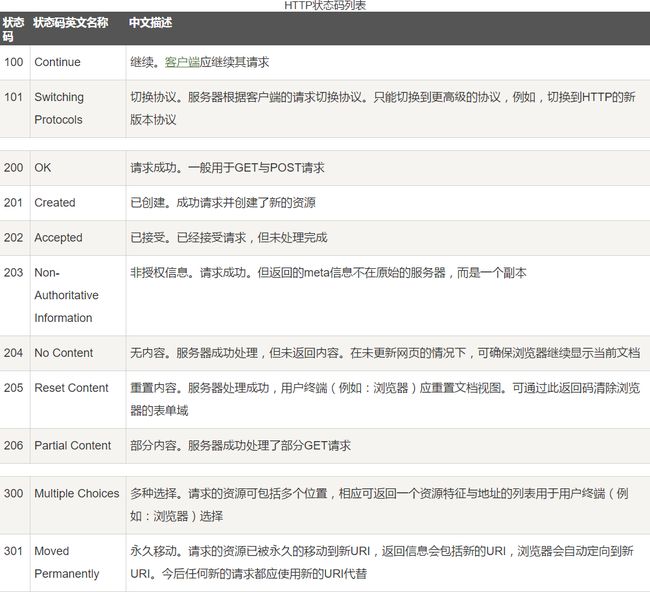
HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
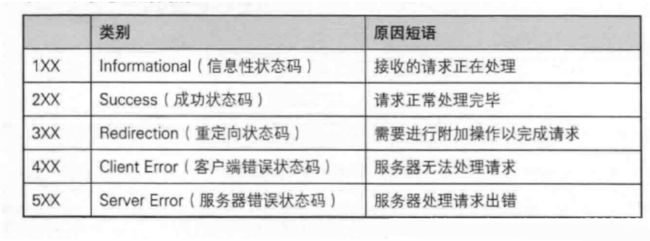
- 1xx:指示信息--表示请求已接收,继续处理。
- 2xx:成功--表示请求已被成功接收、理解、接受。
- 3xx:重定向--要完成请求必须进行更进一步的操作。
- 4xx:客户端错误--请求有语法错误或请求无法实现。
- 5xx:服务器端错误--服务器未能实现合法的请求。
常见状态代码、状态描述的说明如下。
- 200 OK:客户端请求成功。
- 301 Permanently Moved:资源(网页等)被永久转移到其它URL
- 302 Found:资源(网页等)被临时性转移(Temporarily Moved)到其它URL ——Redirect,重定向
- 400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
- 401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
- 403 Forbidden:服务器收到请求,但是拒绝提供服务。
- 404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
- 500 Internal Server Error:服务器发生不可预期的错误。
- 503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常,举个例子:HTTP/1.1 200 OK(CRLF)。




2. 响应头

3. 空行
空行标志着请求头的结束,也标志着请求体的开始。空行可以用\r\n书写。
4. 响应正文
响应正文也称响应体(Body)。空行后面的内容都是Body。 Body允许为空字符串。 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面,那么html页面内容就是在body中。
HTTP消息头(补充)
补充说明关于HTTP协议中重要的消息头内容。
HTTP消息由客户端到服务器的请求和服务器到客户端的响应组成。请求消息和响应消息都是由开始行(对于请求消息,开始行就是请求行,对于响应消息,开始行就是状态行),消息报头(可选),空行(只有CRLF的行),消息正文(可选)组成。
每一个报头域都是由名字+”:”+空格+值组成,消息报头域的名字是大小写无关的。(报头域包括请求头和响应头)
1. 请求头
请求报头允许客户端向服务器端传递请求的附加信息以及客户端自身的信息。
例如,请求头中的Referer说明:
Referer:该请求头指明请求从哪里来。
如果是地址栏中输入地址访问的都没有该请求头(因为这就是你的初始访问页面)。如果从初始访问页面点击进入下一个页面(不建立新的标签页的情况下),通过请求可以看到,此时多了一个Referer的请求头,并且后面的值为该请求从哪里(初始访问页面)发出。比如百度竞价,只能从百度来的才有效果,否则不算;通常用来做统计工作、防盗链。
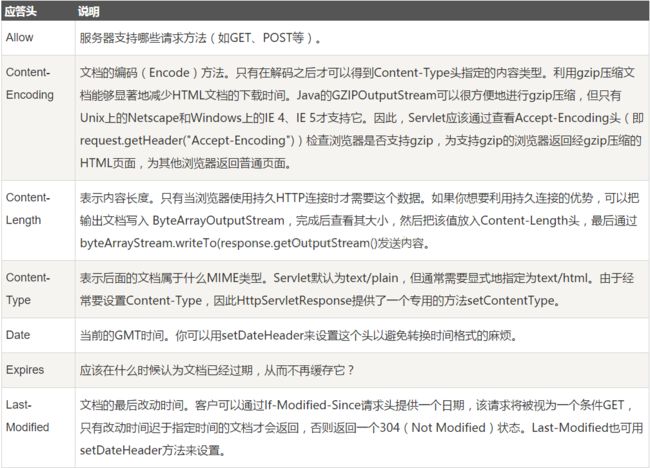
2. 响应头
响应报头允许服务器传递不能放在状态行中的附加响应信息,以及关于服务器的信息和对Request-URl所标识的资源进行下一步访问的信息。
例如,请求头中的Location说明:
-
Location:Location响应报头域用于重定向接受者到一个新的位置。
Location响应报头域,常用在更换域名的时候。
如:response.sendRedirect("http://www.baidu.com"); -
Refresh:自动跳转(单位是秒),可以在页面通过html中在标签里的meta标签实现,也可在后台实现。
如:
注:不写后面的url说明每三秒刷新自己的页面,加上,说明三秒后跳转到指定的url页面位置。
HTTP content-Type
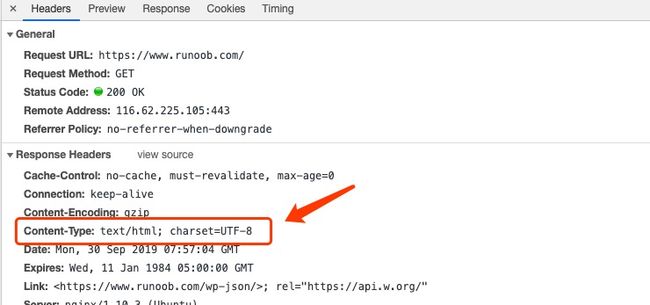
Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些Asp网页点击的结果却是下载到的一个文件或一张图片的原因。
Content-Type 标头告诉客户端实际返回的内容的内容类型。
语法格式:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something实例:
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded :
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
◼️ 更多content-Type相关:HTTP content-type 对照表
HTTP的工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
扩展:MIME 类型
MIME (Multipurpose Internet Mail Extensions) 是描述消息内容类型的标准,用来表示文档、文件或字节流的性质和格式。
MIME 消息能包含文本、图像、音频、视频以及其他应用程序专用的数据。
浏览器通常使用 MIME 类型(而不是文件扩展名)来确定如何处理URL,因此 We b服务器在响应头中添加正确的 MIME 类型非常重要。如果配置不正确,浏览器可能会无法解析文件内容,网站将无法正常工作,并且下载的文件也会被错误处理。
语法
MIME 类型通用结构:
type/subtypeMIME 的组成结构非常简单,由类型与子类型两个字符串中间用 / 分隔而组成,不允许有空格。type 表示可以被分多个子类的独立类别,subtype 表示细分后的每个类型。
MIME类型对大小写不敏感,但是传统写法都是小写。
两种主要的 MIME 类型在默认类型中扮演了重要的角色:
- text/plain 表示文本文件的默认值。
- application/octet-stream 表示所有其他情况的默认值。
常见的 MIME 类型
-
超文本标记语言文本 .html、.html:text/html
-
普通文本 .txt: text/plain
-
RTF 文本 .rtf: application/rtf
-
GIF 图形 .gif: image/gif
-
JPEG 图形 .jpeg、.jpg: image/jpeg
-
au 声音文件 .au: audio/basic
-
MIDI 音乐文件 mid、.midi: audio/midi、audio/x-midi
-
RealAudio 音乐文件 .ra、.ram: audio/x-pn-realaudio
-
MPEG 文件 .mpg、.mpeg: video/mpeg
-
AVI 文件 .avi: video/x-msvideo
-
GZIP 文件 .gz: application/x-gzip
-
TAR 文件 .tar: application/x-tar
| 类型 | 描述 | 典型示例 |
|---|---|---|
text |
表明文件是普通文本,理论上是人类可读 | text/plain, text/html, text/css, text/javascript |
image |
表明是某种图像。不包括视频,但是动态图(比如动态gif)也使用image类型 | image/gif, image/png, image/jpeg, image/bmp, image/webp, image/x-icon, image/vnd.microsoft.icon |
audio |
表明是某种音频文件 | audio/midi, audio/mpeg, audio/webm, audio/ogg, audio/wav |
video |
表明是某种视频文件 | video/webm, video/ogg |
application |
表明是某种二进制数据 |
|
◼️ 更多MIME类型相关:MIME 对照表
参考资料
——「计算机网络」HTTP 协议详解 ——
| GET 和 POST 到底有什么区别? | GET和POST的区别? | HTTP 方法:GET 对比 POST |
| HTTP报文消息详解 | HTTP报文详解——请求消息、响应消息、请求方法、响应状态码 |
![]()
