[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍
1、数据库相关概念
数据库是一种用于存储和管理数据的软件系统。
数据库英文名是 DataBase,简称DB。
数据库就是将数据存储在硬盘上,可以达到持久化存储的效果。
1.1、数据库类型
常见的数据库类型有关系型数据库(如MySQL,Oracle,SQL Server等)、非关系型数据库(如MongoDB,Redis等)和图形数据库(如Neo4j等)。
关系型数据库组织数据为表格形式,每一行为一条记录,每一列为一个字段,通过建立不同表之间的关系来组织数据。关系型数据库是建立在关系模型基础上的数据库,简单说,关系型数据库是由多张能互相连接的二维表组成的数据库
非关系型数据库不遵循表格形式,通常以文档,键值对或图形等形式存储数据。
图形数据库主要用于处理具有复杂关系的数据,通过图形模型来表示数据之间的关系。
1.2、数据库管理系统
数据库管理系统(DataBase Management System,简称 DBMS)是一种软件系统,用于创建,维护和使用数据库。常用的DBMS有MySQL,SQL Server,Oracle,PostgreSQL等。
在电脑上安装了数据库管理系统后,就可以通过数据库管理系统创建数据库来存储数据,也可以通过该系统对数据库中的数 据进行数据的增删改查相关的操作。
我们平时说的MySQL数据库其实是MySQL数据库管理系统。
1.2.1、数据库管理系统种类
常见的数据库管理系统有:
Oracle:收费的大型数据库,Oracle 公司的产品
MySQL: 开源免费的中小型数据库。后来 Sun公司收购了 MySQL,而 Sun 公司又被 Oracle 收购
SQL Server:MicroSoft 公司收费的中型的数据库。C#、.net 等语言常使用
PostgreSQL:开源免费中小型的数据库
DB2:IBM 公司的大型收费数据库产品
SQLite:嵌入式的微型数据库。如:作为 Android 内置数据库
MariaDB:开源免费中小型的数据库
最常用的是MySQL
1.2.2、SQL和MySQL的关系
MySQL是数据库管理系统,而SQL是操作数据库的编程语言
1.3、数据库相关名词简介
1.3.1、数据一致性
数据库的数据一致性是指数据库中的数据在某一特定时刻是确定的。
常用的数据一致性级别有ACID,BASE等。
ACID是数据库事务的一种概念,包括原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
BASE是非关系型数据库中的一种概念,它指的是基本可用性(Basically Available)、软状态(Soft-State)、最终一致性(Eventual Consistency)。
1.3.2、性能调优
数据库的性能调优是指通过优化数据库的结构、索引、查询语句等来提高数据库的查询性能。常用的方法有缩小数据表、创建合理的索引、优化SQL语句等。
1.3.3、备份和恢复
数据库备份和恢复是指将数据库中的数据复制到另一个地方,以防止数据丢失或灾难性故障。常用的数据库备份方法有全备、增量备份和差异备份。
1.3.4、数据库安全
数据库安全是指保护数据库中的数据不被未经授权的用户访问。常用的数据库安全措施有访问控制、加密、审计等。
1.3.5、数据库集群
数据库集群是指将多个数据库服务器组成一个集群,以提高数据库的可用性和性能。常用的数据库集群技术有MySQL Cluster、Oracle RAC、SQL Server AlwaysOn等。
1.3.6、数据仓库
数据仓库是一种用于存储和管理大量历史数据的数据库系统。常用的数据仓库软件有Oracle Warehouse Builder, SAP BW, IBM Cognos 等。
1.3.7、数据挖掘
数据挖掘是一种从大量数据中提取有用信息和知识的技术。常用的数据挖掘技术有关联规则挖掘、分类和聚类算法、回归分析等。
2、MySQL介绍
MySQL是一种关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 旗下产品。
它采用了类似于 SQL 的语言来管理数据库,支持多种操作系统平台。
MySQL是一种免费的开源软件。
MySQL支持多种存储引擎,其中包括 MyISAM, InnoDB, Memory, CSV, Archive, Blackhole 等。MyISAM是默认的存储引擎,支持全文索引和空间优化,适用于读多写少的场景。
InnoDB是支持事务和外键约束的存储引擎,适用于读写并存的场景。
MySQL还提供了许多管理工具和应用程序接口,如 MySQL Workbench, MySQL Administrator, MySQL Query Browser 等。
MySQL在Web应用,数据仓库,在线事务处理(OLTP)和数据仪表盘方面非常流行。并且在各种应用程序中都有广泛的应用,例如WordPress, Joomla, Magento等。
3、MySQL数据模型
MySQL中可以创建多个数据库,每个数据库对应到磁盘上的一个文件夹
在每个数据库中可以创建多个表,每张都对应到磁盘上一个 frm 文件
每张表可以存储多条数据,数据会被存储到磁盘中 MYD 文件中
具体例子如下:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第1张图片](http://img.e-com-net.com/image/info8/223127509afd4d0b8221be4159dfb718.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第2张图片](http://img.e-com-net.com/image/info8/78c0b028551c43c0ae3050f1f4c904b3.jpg)
编辑
如上图,我们通过客户端可以通过数据库管理系统创建数据库,在数据库中创建表,在表中添加数据。创建的每一个数据库 对应到磁盘上都是一个文件夹。比如可以通过SQL语句创建一个数据库(数据库名称为db1),SQL语句->create database db1;
我们可以在数据库安装目录下的data目录下看到多了一个 db1 的文件夹。所以,在MySQL中一个数据库对应到磁盘上的一个文件夹。
而一个数据库下可以创建多张表,我们到MySQL中自带的mysql数据库的文件夹目录下:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第3张图片](http://img.e-com-net.com/image/info8/99aa82325d6d432da4aa3e55df3b025c.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第4张图片](http://img.e-com-net.com/image/info8/ae1834a253e84d688f10ddc129d75251.jpg)
编辑
而上图中右边的db.frm 是表文件,db.MYD 是数据文件,通过这两个文件就可以查询到数据展示成二维表的效果。
4、MySQL数据类型
MySQL 支持多种类型,可以分为:
数值类型:int, bigint, float, double, decimal等。这些类型用于存储数字数据。
日期和时间类型:date, datetime, timestamp, year等。这些类型用于存储日期和时间数据。
字符串类型:char, varchar, text, blob, enum等。这些类型用于存储字符串数据。
二进制类型:binary, varbinary, blob等。这些类型用于存储二进制数据。
布尔类型:BOOL或者TINYINT(1)。这种类型用于存储布尔值。
枚举类型:ENUM。这种类型用于存储固定的选项列表。
JSON类型:JSON。这种类型用于存储JSON数据。
这些类型每一种都有自己的特点,在使用时需要根据实际需求来选择合适的类型。
char和varchar:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第5张图片](http://img.e-com-net.com/image/info8/f29526270aa1452394ae3916f55a3881.jpg)
5、SQL
5.1、简介
Structured Query Language,简称 SQL,结构化查询语言、操作关系型数据库的编程语言
SQL用于查询、插入、更新、删除数据。
定义操作所有关系型数据库的统一标准,可以使用SQL操作所有的关系型数据库管理系统,以后工作中如果使用到了其他的数据库管理系统,也同样的使用SQL来操作。
5.2、通用语法
语法要求如下:
①SQL语句可以单行或多行书写,以分号结尾。
②MySQL 数据库的SQL语句不区分大小写,关键字建议使用大写
③注释:
单行注释:-- 注释内容 或 #注释内容(MySQL 特有)
注意:使用-- 添加单行注释时,--后面一定要加空格,而#没有要求。
多行注释:/* 注释 */
5.3、SQL语句分类
具体分类如下:
①DDL(Data Definition Language):数据定义语言,用来定义数据库对象:数据库,表,列等
②DML(Data Manipulation Language) :数据操作语言,用来对数据库中表的数据进行增删改
③DQL(Data Query Language):数据查询语言,用来查询数据库中表的记录(数据)
④DCL(Data Control Language):数据控制语言,用来定义数据库的访问权限、安全级别、创建用户
(各单词:Definition/ˌdefɪˈnɪʃ(ə)n/,Manipulation/məˌnɪpjuˈleɪʃn/,Query/ˈkwɪəri/)
简单来说:
DDL:用来操作数据库,表等
DML:对表中数据进行增删改
DQL:对数据进行查询操作。从数据库表中查询到我们想要的数据
DML:对数据库进行权限控制。比如让某一个数据库表只能让某一个用户进行操作等。
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第6张图片](http://img.e-com-net.com/image/info8/65772646649a4e4e92e33579fb1e60f3.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第7张图片](http://img.e-com-net.com/image/info8/d3c3281c04b74e7fad616fbe8f85117c.jpg)
编辑
6、Data Definition Language(DDL)
下面介绍DDL来操作数据库,主要介绍相关SQL语句:
6.1、操作数据库
6.1.1、查询
查询所有的数据库->show databases;
6.1.2、创建
创建数据库->create database 数据库名称;
创建的时候不知道数据库名称是否会重名,如果重名则会出现Can't create database错误,想要避免这种错误,则需要在创建新的数据库之前判断一下是否重名:
判断,如果不存在则创建->create database if not exists 数据库名称;
6.1.3、删除
删除数据库->drop database 数据库名称;
删除数据库(判断,如果存在则删除)->drop database if exists 数据库名称;
6.1.4、使用数据库
数据库创建好了之后,要在数据库中执行操作,得先明确在哪个数据库中,因此就需要明确使用数据库。
使用数据库->use 数据库名称;
查看当前使用的数据库->select database();
6.2、操作表(CURD)
操作表也就是对表进行增(Create)删(delete)改(Update)查(Retrieve),俗称CURD
6.2.1、查询
查询当前数据库下所有表名称->show tables;
查询表结构->desc 表名称;
(desc->降序排列 descend 的缩写)
6.2.2、创建
CREATE TABLE 表名 (
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);
注意:最后一行末尾,不能加逗号
举例:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第8张图片](http://img.e-com-net.com/image/info8/99ba515abbeb4cedaf39904bbae5693e.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第9张图片](http://img.e-com-net.com/image/info8/ad5b622ae52e4e32ac8740e3da30e723.jpg)
编辑
create table tb_user (
id int,
username varchar(20),
password varchar(32)
);
6.2.3、删除
删除表->drop table 表名;
删除表时判断表是否存在->drop table if exists 表名;
6.2.4、修改
①修改表名->alter table 表名 rename to 新的表名;
Ex:alter table student rename to stu; -- 将表名student修改为stu
②添加一列->alter table 表名 add 列名 数据类型;
EX:alter table stu add address varchar(50); -- 给stu表添加一列address,该字段类型是varchar(50)
③修改数据类型->alter table 表名 modify 列名 新数据类型; (modify : 修改)
EX:alter table stu modify address char(50); -- 将stu表中的address字段的类型改为 char(50)
④修改列名和数据类型->alter table 表名 change 列名 新列名 新数据类型;
EX:alter table stu change address addr varchar(50);
-- 将stu表中的address字段名改为 addr,类型改为varchar(50)
⑤删除列->alter table 表名 drop 列名;
EX:alter table stu drop addr; -- 将stu表中的addr字段 删除
7、Data Manipulation Language(DML)
DML主要是对数据进行增(insert)删(delete)改(update)操作。
7.1、添加
给指定列添加数据->insert into 表名(列名1,列名2,…) values(值1,值2,…); (insert 插入、嵌入)
给全部列添加数据->insert into 表名 values(值1,值2,…);
批量添加数据->
insert into 表名(列名1,列名2,…) values(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
insert into 表名 values(值1,值2,…),(值1,值2,…),(值1,值2,…)…;
7.2、修改
修改表数据->update 表名 set 列名1=值1,列名2=值2,… [where 条件] ;
注意:
1. 修改语句中如果不加条件,则将所有数据都修改!
2. 像上面的语句中的中括号,表示在写sql语句中可以省略这部分
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第10张图片](http://img.e-com-net.com/image/info8/9ba4ddfeed404ff8a571915ead6ccca3.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第11张图片](http://img.e-com-net.com/image/info8/acce56b83e0146859b4823dfc21988e3.jpg)
编辑
7.3、删除
删除数据->delete from 表名 [where 条件] ;
Ex:delete from stu where name = '张三'; -- 删除张三记录
delete from stu; -- 删除stu表中所有的数据
8、Data Query Language(DQL)
使用背景:当我们浏览网页的时候,像百度搜索或者京东商品展示页面,这些页面上展示的数据肯定是在数据库中的表中存储,而我们需要将数据库中的数据查询出来并展示在页面给用户。但是数据库中的数据很多的,不可能在将所有的数据在一页进行全部展示,则页面上会有分页展示的效果
DQL是对数据进行查询操作
8.1、基础查询
查询多个字段->
select 字段列表 from 表名;
select * from 表名; -- 查询所有数据
去除重复记录->select distinct 字段列表 from 表名;
起别名->AS (AS 也可以省略)
Ex:select name,math as 数学成绩,english as 英文成绩 from stu;
8.2、条件查询
8.2.1、语法
select 字段列表 from 表名 where 条件列表;
8.2.2、条件
条件列表的运算符:
符号
|
功能
|
>
|
大于
|
<
|
小于
|
>=
|
大于等于
|
<=
|
小于等于
|
=
|
等于
|
<>或!=
|
不等于
|
BETWEEN . AND…
|
在某个范围之内(都包含)
|
IN(…)
|
多选一
|
LIKE占位符
|
模糊查询,"_"单个任意字符;"%"多个任意字符
|
IS NULL
|
是NULL
|
IS NOT NULL
|
不是NULL
|
AND或&&
|
并且
|
OR或Ⅱ
|
或者
|
NOT或!
|
非,不是
|
8.2.2.1、like
模糊查询使用like关键字,可以使用通配符进行占位:
(1)_ : 代表单个任意字符
(2)% : 代表任意个数字符
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第12张图片](http://img.e-com-net.com/image/info8/04f5e956e7f647778da8f782bb2a170a.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第13张图片](http://img.e-com-net.com/image/info8/82c285c81e5640e09e8f00549e312a0f.jpg)
编辑
8.3、排序查询
语法->select 字段列表 from 表名 order BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …;
上述语句中的排序方式有两种,分别是:
ASC : 升序排列 (默认值)
DESC : 降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第14张图片](http://img.e-com-net.com/image/info8/46a67d8a1edc401bbb115abc7af05746.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第15张图片](http://img.e-com-net.com/image/info8/5f2cbf09ec144a6eacfb4b51ebf4f87e.jpg)
编辑
8.4、聚合函数
8.4.1、概念
将一列数据作为一个整体,进行纵向计算。
理解:假设有一份学生成绩单,要计算全班数学成绩的总和,即把学生的数学成绩那一列作为一个整体,进行纵向求和
8.4.2、聚合函数分类
函数名
|
功能
|
|
count(列名)
|
统计数量(一般选用不为null的列)
|
|
max(列名)
|
最大值
|
|
min(列名)
|
最小值
|
|
sum(列名)
|
求和
|
|
avg(列名)
|
平均值
|
|
8.4.3、语法
select 聚合函数名(列名) from 表;
注意:null 值不参与所有聚合函数运算
8.5、分组查询
8.5.1、语法
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第16张图片](http://img.e-com-net.com/image/info8/6bf76907a8cc4fc0ade49e0e3e00ee45.jpg)
编辑
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
8.5.2、⭐Example
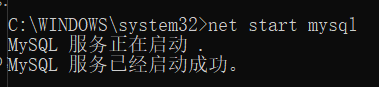
①启动MySQL
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第17张图片](http://img.e-com-net.com/image/info8/8e79314d42654f9fa7dddd8578f004cf.jpg)
编辑
②创建一个数据库student
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第18张图片](http://img.e-com-net.com/image/info8/8840a442b2164b72902deec8d2674e51.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第19张图片](http://img.e-com-net.com/image/info8/636338528cfa484cb13d6e39b60f22e5.jpg)
编辑
③使用数据库,准备开始操作
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第20张图片](http://img.e-com-net.com/image/info8/56b74c53d45f4d1db97ebdc028c628d6.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第21张图片](http://img.e-com-net.com/image/info8/d589420b012d47efaeec3b7d6d0a1254.jpg)
编辑
④创建表单stu
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第22张图片](http://img.e-com-net.com/image/info8/3ecead01f0ec439b818595b65b3fab7e.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第23张图片](http://img.e-com-net.com/image/info8/c54194370ab2436fbf8c526ec8e64fad.jpg)
编辑
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第24张图片](http://img.e-com-net.com/image/info8/8487c05f9c714e329e06a937aeede388.png)
编辑
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第25张图片](http://img.e-com-net.com/image/info8/828841b0d53c45429876def7de83740d.png)
编辑
⑤向表中插入数据
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第26张图片](http://img.e-com-net.com/image/info8/a892881799754f66afc8cbd33e625a5e.jpg)
编辑
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第27张图片](http://img.e-com-net.com/image/info8/7fb1eab450f246c788e7056355146aa7.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第28张图片](http://img.e-com-net.com/image/info8/09b6f126fbc945eb93da4cf64ee93708.jpg)
编辑
⑥分组查询
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第29张图片](http://img.e-com-net.com/image/info8/4e29a108fd6a4651a0dffb030ea0ee75.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第30张图片](http://img.e-com-net.com/image/info8/c9bb8153924c46d3afef3cf044b71149.jpg)
编辑
可以看到,分组查询命令中,只有聚合函数部分决定结果,其余字段不影响。
8.6、分页查询
语法->select 字段列表 from 表名 limit 起始索引 , 查询条目数;
注意: 上述语句中的起始索引是从0开始
起始索引计算公式:起始索引 = (当前页码 - 1) * 每页显示的条数
9、Data Control Language(DCL)
DCL 是数据库管理系统中的一种语言,主要用于管理数据库中的用户权限和安全性。
DCL常用的命令有:
GRANT:用于给用户授予数据库对象的访问权限。
REVOKE:用于撤销用户的数据库对象的访问权限。
(grant:授予;revoke:撤回、撤销)
语法:
GRANT->grant 权限 on 数据库对象 to 用户 [with grant option];
REVOKE->revoke 权限 on 数据库对象 from 用户;
其中权限可以是 SELECT, INSERT, UPDATE, DELETE, EXECUTE 等。
数据库对象可以是表、视图、存储过程等。
例如:
-- 给用户张三授予读取表employee的权限
GRANT SELECT ON employee TO zhangsan;
-- 撤销用户张三读取表employee的权限
REVOKE SELECT ON employee FROM zhangsan;
需要注意的是,DCL 操作会影响到整个数据库的安全性和数据的可用性,因此需要特别小心。
10、约束
10.1、为什么要约束
在实际的数据库操作中,关于表中的数据,如若不做约束可能存在以下问题:
①id 列一般是用标示数据的唯一性的,不约束可能出现多个id重复
②存储用户年龄的数据的age列的数据可能出现四位数五位数,而人并没有这么长寿,如此有违常理
③成绩是负数,而一般情况来说成绩很少出现负数
④成绩值为null,而成绩即使没考也应该是0分
10.2、概念
针对上述数据问题,我们就可以从数据库层面在添加数据的时候进行限制,这就是约束。
10.3、约束的分类
10.3.1、非空约束
非空约束: 关键字是 NOT NULL
保证列中所有的数据不能有null值。
Ex:create table user(name varchar(10) not null);
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第31张图片](http://img.e-com-net.com/image/info8/69fae1121ad64585a66f7e6ff5507442.png)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第32张图片](http://img.e-com-net.com/image/info8/26b2b005415a4ef99b56fc6f52725964.jpg)
编辑
可以看到,进行非空约束之后,再传入null,会报错。
10.3.2、唯一约束
唯一约束:关键字是 UNIQUE
保证列中所有数据各不相同。 (unique唯一)
create table user(name varchar(10),unique(name));
10.3.3、主键约束⭐
主键约束: 关键字是 PRIMARY KEY
主键是一行数据的唯一标识,要求非空且唯一。一般我们都会给每张表添加一个主键列用来唯一标识数据。
例如:id就可以作为主键,来标识每条数据。那么这样就要求数据中id的值不能重复,不能为null值。
create table user(id int,name varchar(10),primary key(id));
10.3.4、检查约束⭐⭐
检查约束: 关键字是 CHECK
保证列中的值满足某一条件。
例如:我们可以给age列添加一个范围,最低年龄可以设置为1,最大年龄就可以设置为300,这样的数据才更合理些。
SQL->create table user(age int check(age>18 and age<80));
注意:MySQL不支持检查约束。
解决办法:从数据库层面不能保证,以后可以在java代码中进行限制,一样也可以实现要求。
10.3.5、默认约束
默认约束: 关键字是 DEFAULT
保存数据时,未指定值则采用默认值。
例如:我们在给english列添加该约束,指定默认值是0,这样在添加数据时没有指定具体值时就会采用默认给定的0。
create table user(english int default 0);
10.3.6、外键约束
外键约束: 关键字是 FOREIGN KEY
外键用来让两个表的数据之间建立链接,保证数据的一致性和完整性。
比如orders表中的userId必须参考user表中的id,如果插入的userId在user表中不存在,则无法插入
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第33张图片](http://img.e-com-net.com/image/info8/5e0b155c4d754c4cabf23de1c18890e6.jpg)
编辑
SQL->create table orders(id int primary key,userId int,foreign key(userId) references user(id));
10.3.7、unique和primary key的区别⭐
unique和primary key约束都可以为一列值的唯一性提供保障,但是unique在同一个表中可以出现多次,而primary key在同个表中只能出现一次
11、数据库设计
11.1、简介
11.1.1、软件的研发步骤:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第34张图片](http://img.e-com-net.com/image/info8/7c69cd0773bd45ee9b64be9c6c3456df.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第35张图片](http://img.e-com-net.com/image/info8/d2c59ce282fa49fb8fad1a057fd690c8.jpg)
编辑
11.1.2、数据库设计概念
数据库设计就是根据业务系统的具体需求,结合我们所选用的DBMS,为这个业务系统构造出最优的数据存储模型,建立数据库中的表结构以及表与表之间的关联关系的过程。
11.1.3、数据库设计的步骤
①需求分析(数据是什么? 数据具有哪些属性? 数据与属性的特点是什么)
②逻辑分析(通过ER图对数据库进行逻辑建模,不需要考虑我们所选用的数据库管理系统)
③物理设计(根据数据库自身的特点把逻辑设计转换为物理设计)
④维护设计(1.对新的需求进行建表;2.表优化)
如下图就是ER(Entity/Relation)图:
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第36张图片](http://img.e-com-net.com/image/info8/358fffff982846e3afc18a36184d5445.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第37张图片](http://img.e-com-net.com/image/info8/b2045eb3407140f2aadc7713bd87f1a1.jpg)
编辑
11.2、表关系
表关系有三种:一对一、一对多、多对多
11.2.1、一对一
如:用户和用户详情
一对一关系多用于表拆分,将一个实体中经常使用的字段放一张表,不经常使用的字段放另一张表,用于提升查询性能
实现方式:在任意一方加入外键,关联另一方主键,并且设置外键为唯一(UNIQUE)
11.2.2、一对多
如:部门和员工
一个公司有多个部门,一个部门有多个员工,则部门表对应员工表
一个部门对应多个员工,一个员工对应一个部门
实现方式:在多的一方建立外键,指向一的一方的主键
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第38张图片](http://img.e-com-net.com/image/info8/fb98949086cb438eb77dd54cbd88c1b5.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第39张图片](http://img.e-com-net.com/image/info8/90f102cc66144448894ac8eefd3af052.jpg)
编辑
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第40张图片](http://img.e-com-net.com/image/info8/5903653a72d3463a8dfeddedb3f3867b.jpg)
编辑
例如:CONSTRAINT fk_emp_dept FOREIGN KEY(dep_id) REFERENCES tb_dept(id)
11.2.3、多对多
如:商品和订单
一个商品对应多个订单,一个订单包含多个商品
实现方式:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第41张图片](http://img.e-com-net.com/image/info8/6a8eaaabd9b4467a9a6bc3d9281f7aeb.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第42张图片](http://img.e-com-net.com/image/info8/4c8367e1088847c68a163a709b609658.jpg)
编辑
12、多表查询
多表查询:从多张表中一次性的查询出我们想要的数据
12.1、内连接查询
内连接相当于查询A和B的交集数据
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第43张图片](http://img.e-com-net.com/image/info8/65412f82389d435da8c165ee357d21ad.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第44张图片](http://img.e-com-net.com/image/info8/842e7c21b95649ae82db8effd3ba606f.jpg)
编辑
-- 隐式内连接
SELECT 字段列表 FROM 表1,表2… WHERE 条件;
-- 显示内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 条件;
12.2、外连接查询
左外连接:相当于查询A表所有数据和交集部分数据
右外连接:相当于查询B表所有数据和交集部分数据
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第45张图片](http://img.e-com-net.com/image/info8/853c7e593c7b4eb89c1997e1d54f2a63.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第46张图片](http://img.e-com-net.com/image/info8/6af47aed6166428ca3fd446b714a6c9f.jpg)
编辑
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
12.3、子查询
概念:查询中嵌套查询,称嵌套查询为子查询。
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第47张图片](http://img.e-com-net.com/image/info8/75296b4ca8674feba9380ba9771de897.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第48张图片](http://img.e-com-net.com/image/info8/dc2cca1fc581424b89267060d58593b1.jpg)
编辑
13、事务
数据库的事务(Transaction)是一种机制、一个操作序列,包含了一组数据库操作命令。
事务把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么同时成功,要么同时失败。
事务是一个不可分割的工作逻辑单元
13.1、如何理解
一个事务就是一块命令,比如转账操作,数据在更新的时候有先后。
比如A向B转钱的过程中程序刚好出现了错误,那么有可能出现A的余额变少了但是B的余额并没有增加的情况,此时就需要事务来解决这个问题。
把转账这个操作看成一个整体,如果出了异常,便回滚事务,即A转账出错时,A的资金余额回到转账前
13.2、语法
①开启事务->START TRANSACTION; 或者 BEGIN;
②提交事务->commit;
③回滚事务->rollback;
Ex:
begin;
一系列操作
commit;
rollback;
⭐在开发中一般不这样操作,而是在java中进行操作,在java中可以抓取异常,没出现异常提交事务,出现异常回滚事务。
13.3、四大特征
事务的四大特征:
①原子性(Atomicity) : 事务是不可分割的最小操作单位,要么同时成功,要么同时失败
②一致性(Consistency) :事务完成时,必须使所有的数据都保持一致状态
③隔离性(Isolation) : 多个事务之间,操作的可见性
④持久性(Durability) : 事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第49张图片](http://img.e-com-net.com/image/info8/f92dff966f764c8cae29438c5ee554ec.jpg)
![[Java Web]MySQL数据库|一文带你了解并熟悉数据库相关知识和各种操作,超6000字详细介绍_第50张图片](http://img.e-com-net.com/image/info8/04cc8ce0a64c4675b956193f73909523.jpg)
编辑