大数据笔记-NIFI(第一篇)
目录
一、NIFI简介
1、NIFi的相关概念及特点
1.1、什么是 Apache NiFi?
1.2、NiFi的核心概念
1.3、NiFi架构
1.4、NiFi的性能预期和特点
1.5、关键 NiFi 功能的高级概述
二、NiFi的安装(无证书集群内)
1、NiFi下载
2、安装NiFi
2.1、上传解压
2.2、修改配置文件
三、启动
1、we页面简介
1.1、NIFI登陆后界面
1.2、NIFI登陆界面解读
编辑
2、全局菜单
3、NIFI登陆界面解读
4、配置处理器(GetFile)
5、连接处理器(将文件转换为csv格式)
一、NIFI简介
1、NIFi的相关概念及特点
1.1、什么是 Apache NiFi?
简而言之,NiFi 旨在使系统之间的数据流自动化。虽然术语“数据流”在各种情况下使用,但我们在这里使用它来表示系统之间的自动化和管理信息流。自从企业拥有多个系统以来,这个问题空间就一直存在,其中一些系统创建数据,而一些系统消耗数据。出现的问题和解决方案模式已被广泛讨论和阐明。企业集成模式中提供了一个全面且易于使用的表格。
数据流的一些高级挑战包括:
-
系统故障
网络故障,磁盘故障,软件崩溃,人们犯错误。
-
数据访问超出了消费能力
有时,给定的数据源可能会超过处理或交付链的某些部分——只需要一个薄弱环节就会出现问题。
-
边界条件只是建议
总是会得到太大、太小、太快、太慢、损坏、错误或格式错误的数据。
-
什么是噪音,前一天变成信号
组织的优先级变化 - 迅速。启用新流程和更改现有流程必须快速。
-
系统以不同的速度发展
给定系统使用的协议和格式可以随时更改,而且通常与周围的系统无关。数据流的存在是为了连接本质上是一个大规模分布式组件系统,这些组件松散地或根本不设计为一起工作。
-
合规性和安全性
法律、法规和政策发生变化。企业对企业的协议发生变化。系统到系统和系统到用户的交互必须是安全的、可信的、负责的。
-
生产中出现持续改进
在实验室中复制生产环境通常是不可能的。
多年来,数据流一直是架构中必不可少的弊端之一。
现在,尽管有许多活跃且快速发展的运动使数据流变得更加有趣,并且对于给定企业的成功更加重要。
这些包括:面向服务的架构、API的兴起、物联网、大数据。此外,合规、隐私和安全所需的严格程度也在不断提高。
即使仍然有所有这些新概念出现,数据流的模式和需求仍然基本相同。
主要区别在于复杂性的范围、适应所需的变化率,以及在规模上边缘情况变得普遍。
NiFi 旨在帮助解决这些现代数据流挑战。
1.2、NiFi的核心概念
以下是一些主要的 NiFi 概念以及它们如何映射到 FBP:
| NiFi核心 | FBP Term | 描述 |
|---|---|---|
| FlowFile 流文件 | 信息包 | FlowFile 表示在系统中移动的每个对象,对于每个FiowFile,NiFi 都会记录它一个属性键值对和0个或多个字节内容(FlowFile又attributr和content) |
| FlowFile Processor 流文件处理器 | 黑盒子 | 实际上是处理器起主要作用。在eip术语中,处理器就是不同系统之间的数据路由,数据转换或者数据中介的组合。处理器可以访问给定FlowFile的属性及其内容。处理器可以对给定工作单元中的零或多个流文件进行操作,并提交给该工作或回滚工作 |
| Connection 连接 | 有界缓冲区 | Connection用来连接处理器。他们充当队列并允许各种进程以不同的速率进行交互。这些队列可以动态地对进行优先级排序,并且可以在负载上设置上限。从而启用背压 |
| Flow Controller 流量控制器 | 调度器 | 流控制器维护流程如何连接,并管理和分配所有流程使用的线程,流控制器充当代理,促进处理器之间流文件的交换。 |
| Process Group 进程组 | 分支网络 | 进程组是一组特定的流程和连接可以通过输入端口接收数据并通过输出端口发送数据。以这种方式,进程组允许简单地通过组合其他组件来创建全新的组件。 |
好处包括:
-
非常适合于处理器的有向图的可视化创建和管理
-
本质上是异步的,即使在处理和流速波动时也允许非常高的吞吐量和自然缓冲
-
提供高度并发的模型,开发人员无需担心并发的典型复杂性
-
促进内聚和松散耦合组件的开发,然后可以在其他环境中重用,并促进可测试单元
-
资源受限的连接使诸如背压和压力释放等关键功能非常自然和直观
-
错误处理变得像快乐路径一样自然,而不是粗粒度的包罗万象
-
数据进出系统的点以及数据流经的方式都易于理解且易于跟踪
1.3、NiFi架构

NiFi 在主机操作系统的 JVM 中执行。JVM上NiFi的主要组件如下:
-
网络服务器(Web Server)
Web 服务器的目的是托管 NiFi 基于 HTTP 的命令和控制 API。
-
流量控制器(Flow Controller)
流量控制器是操作的大脑。它为要运行的扩展提供线程,并管理扩展何时接收资源以执行的计划。
-
扩展(Extensions)
其他文档中描述了各种类型的 NiFi 扩展。这里的关键点是扩展在 JVM 中运行和执行。
-
流文件存储库(FlowFile Repository)
FlowFile 存储库是 NiFi 跟踪它所知道的关于当前在流中处于活动状态的给定 FlowFile 的状态的地方。存储库的实现是可插拔的。默认方法是位于指定磁盘分区上的持久预写日志。
-
内容库(Content Repository)
内容存储库是给定流文件的实际内容字节所在的位置。存储库的实现是可插拔的。默认方法是一种相当简单的机制,它将数据块存储在文件系统中。可以指定多个文件系统存储位置,以便使用不同的物理分区来减少任何单个卷上的争用。
-
源头资料库(Provenance Repository)
源头存储库是存储所有源头事件数据的地方。存储库结构是可插入的,默认实现是使用一个或多个物理磁盘卷。在每个位置事件数据都被索引和搜索。
NiFi 也能够在集群内运行。

从 NiFi 1.0 版本开始,采用了零领导者集群范式。NiFi 集群中的每个节点对数据执行相同的任务,但每个节点对不同的数据集进行操作。
Apache ZooKeeper 选择单个节点作为集群协调器,故障转移由 ZooKeeper 自动处理。所有集群节点都向集群协调器报告心跳和状态信息。
Cluster Coordinator 负责断开和连接节点。此外,每个集群都有一个主节点,也是由ZooKeeper 选出的。
作为 DataFlow 管理器,您可以通过任何节点的用户界面 (UI) 与 NiFi 集群进行交互。您所做的任何更改都会复制到集群中的所有节点,从而允许多个入口点。
1.4、NiFi的性能预期和特点
NiFi 旨在充分利用其运行的底层主机系统的功能。这种资源最大化在 CPU 和磁盘方面尤为突出。
-
对于 IO
可以预期看到的吞吐量或延迟变化很大,具体取决于系统的配置方式。鉴于大多数主要 NiFi 子系统都有可插拔的方法,因此性能取决于实现。但是,对于具体且广泛适用的内容,请考虑开箱即用的默认实现。这些都是持久的,有保证的交付,并使用本地磁盘执行此操作。因此,保守一点,假设典型服务器中的普通磁盘或 RAID 卷的读/写速率约为每秒 50 MB。用于大量数据流的 NiFi 应该能够有效地达到每秒 100 MB 或更多的吞吐量。这是因为添加到 NiFi 的每个物理分区和内容存储库都有望实现线性增长。这将在 FlowFile 存储库和出处存储库的某个时刻成为瓶颈。我们计划提供一个包含在构建中的基准测试和性能测试模板,它允许用户轻松测试他们的系统并确定瓶颈在哪里,以及在什么时候它们可能成为一个因素。此模板还应使系统管理员可以轻松进行更改并验证影响。
-
对于 CPU
流控制器充当引擎,指示特定处理器何时被赋予执行线程。处理器被编写为在执行完任务后立即返回线程。可以给流控制器一个配置值,指示它维护的各种线程池的可用线程。使用的理想线程数取决于主机系统资源的内核数、该系统是否也在运行其他服务以及流中处理的性质。对于典型的 IO 繁重的流,使数十个线程可用是合理的。
-
对于内存
NiFi 存在于 JVM 中,因此受限于 JVM 提供的内存空间。JVM 垃圾收集成为限制总实际堆大小以及优化应用程序随时间运行情况的一个非常重要的因素。定期阅读相同内容时,NiFi 作业可能是 I/O 密集型的。配置足够大的磁盘以优化性能。
1.5、关键 NiFi 功能的高级概述
-
流量管理
保证交货
NiFi的核心理念是: 即使在非常高的规模下, 也必须保证交付。这是通过有效地使用专门构建的Write-Ahead Log和Content repository来实现的。它们一起被设计成具备允许非常高的事务速率, 有效的负载分布, 写时复制和发挥传统磁盘读/写的优势。
数据缓冲 带背压和压力释放
NiFi 支持缓冲所有排队的数据, 以及在这些队列达到指定限制时提供背压的能力(背压对象阈值, 背压数据大小阈值), 或在数据达到指定期限(其值失效)时, 老化并丢弃数据的能力。
优先排队
NiFi 允许设置一个或多个优先级方案, 用于如何从队列中检索数据。默认情况是先进先出, 但有时应该首先提取最新的数据(后进先出), 最大的数据先出或其他定制方案。
流特定的 QoS(延迟与吞吐量、丢失容限等)
可能在数据流的某些节点上数据至关重要, 不容丢失, 并且在某些时刻这些数据需要在几秒钟就处理完毕传向下一节点才有意义。对于这些方面 NiFi 也可以做到细粒度的配置。
-
使用方便
可视化流程
数据流的处理逻辑和过程可能会非常复杂。能够可视化这些流程并以可视的方式来表达它们可以极大地帮助用户降低数据流的复杂度, 并确定哪些地方需要简化。NiFi 可以实现数据流的可视化建立, 而且是实时的。并不是"设计, 部署", 它更像泥塑。如果对数据流进行了更改, 更改就会立即生效, 并且这些更改是细粒度的和组件隔离的。用户不需要为了进行某些特定修改而停止整个流程或流程组。
流模板
FlowFile 往往是高度模式化的, 虽然通常有许多不同的方法来解决问题, 但能够共享这些最佳实践却大有帮助。流程模板允许设计人员构建和发布他们的流程设计, 并让其他人从中受益和复用。
数据起源跟踪
在对象流经系统时, 甚至在扇入,扇出, 转换等过程中, NiFi 会自动记录, 索引并提供可用的源数据。这些信息在故障排除, 优化以及其他方案中变得极为关键。
可以记录和重放的细粒度历史记录缓冲区
NiFi 的Content Repository旨在充当历史数据的滚动缓冲区。数据仅在Content Repository老化或需要空间时才会被删除。Content Repository 与 Data Provenance 能力相结合, 为在对象的生命周期中的特定点实现查看内容, 内容下载和内容重放等功能提供了非常有用的基础。
-
可扩展架构
水平扩展
NiFi 的设计是可集群, 可横向扩展的。如果配置单个节点并将其配置为每秒处理数百MB的数据, 那么可以相应的将集群配置为每秒处理GB级的数据。但这也带来了 NiFi 与其获取数据的系统之间的负载平衡和故障转移的挑战。采用基于异步排队的协议(如kafka)可以提供帮助解决这些问题。
扩展和缩小
NiFi 可以非常灵活的放大和缩小。从 NiFi 框架的角度来看, 在增加吞吐量这方面, 可以在配置时增加"调度"选项卡下处理器的并发任务数。这允许更多线程同时执行, 从而提供更高的吞吐量。另一方面, 也可以完美的将 NiFi 缩小到适合在边缘设备上运行, 因为硬件资源有限, 所需的占用空间很小, 这种情况可以使用MINIFI。
二、NiFi的安装(无证书集群内)
常用术语
FlowFile:每条“用户数据”(即用户带进NIFI的需要进行处理和分发的数据)称为FlowFile。FlowFile由两部分组成:Attrbutes和Content。Content是用户数据本身,Attributes是与用户数据关联的键值对。
Processor:处理器,是NiFi组件,负责创建,发送,接收,转换,路由,拆分,合并和处理FlowFiles。他是NIFI用户可用于构建其数据流的最重要的构建块
1、NiFi下载
下载地址:Apache NiFi Downloads
文档地址:Apache NiFi Documentation
2、安装NiFi
2.1、上传解压
unzip nifi-1.17.0-bin.zip -d /opt/
unzip nifi-toolkit-1.17.0-bin.zip -d /opt/
scp -r nifi-1.17.0 bigdata014232:/opt/
scp -r nifi-1.17.0 bigdata014233:/opt/
echo "10000 65000" > /proc/sys/net/ipv4/ip_local_port_range2.2、修改配置文件
三台主机公共配置:
修改配置了zookeeper节点的nifi安装目录下的/conf/state-management.xml
vim state-management.xml
134.64.14.236:12181,134.64.14.237:12181,134.64.14.238:12181 修改每个节点的/conf/zookeeper.properties
vim zookeeper.properties
server.1=134.64.14.236:12888:13888;12181
server.2=134.64.14.237:12888:13888;12181
server.3=134.64.14.238:12888:13888;12181配置JVM
vim bootstrap.conf
java.arg.2=-Xms10240m
java.arg.3=-Xmx10240m第一台主机
cd /opt/nifi-1.17.0/conf/
vim nifi.properties
nifi.web.http.host=134.64.14.236
nifi.web.http.port=11011
nifi.cluster.node.address=bigdata014236
nifi.cluster.node.protocol.port=11012
nifi.remote.input.host=134.64.14.236
nifi.remote.input.secure=false
nifi.remote.input.socket.port=11013
nifi.sensitive.props.key=123456789012
nifi.state.management.embedded.zookeeper.start=true
nifi.zookeeper.connect.string=134.64.14.237:12181,134.64.14.236:12181,134.64.14.238:12181cd /opt/nifi-1.17.0
mkdir -p state/zookeeper
echo 1 > ./state/zookeeper/myid第二台主机
cd /opt/nifi-1.17.0/conf/
vim nifi.properties
nifi.web.http.host=134.64.14.237
nifi.web.http.port=11011
nifi.cluster.node.address=bigdata014237
nifi.cluster.node.protocol.port=11012
nifi.remote.input.host=134.64.14.237
nifi.remote.input.secure=false
nifi.remote.input.socket.port=11013
nifi.sensitive.props.key=123456789012
nifi.state.management.embedded.zookeeper.start=true
nifi.zookeeper.connect.string=134.64.14.237:12181,134.64.14.236:12181,134.64.14.238:12181cd /opt/nifi-1.17.0
mkdir -p state/zookeeper
echo 2 > ./state/zookeeper/myid第三台主机
cd /opt/nifi-1.17.0/conf/
vim nifi.properties
nifi.web.http.host=134.64.14.238
nifi.web.http.port=11011
nifi.cluster.node.address=bigdata014238
nifi.cluster.node.protocol.port=11012
nifi.remote.input.host=134.64.14.238
nifi.remote.input.secure=false
nifi.remote.input.socket.port=11013
nifi.sensitive.props.key=123456789012
nifi.state.management.embedded.zookeeper.start=true
nifi.zookeeper.connect.string=134.64.14.237:12181,134.64.14.236:12181,134.64.14.238:12181cd /opt/nifi-1.17.0
mkdir -p state/zookeeper
echo 3 > ./state/zookeeper/myid三、启动
cd /opt/nifi-1.17.0/bin
./nifi.sh start
./nifi.sh status1、we页面简介
1.1、NIFI登陆后界面

1.2、NIFI登陆界面解读
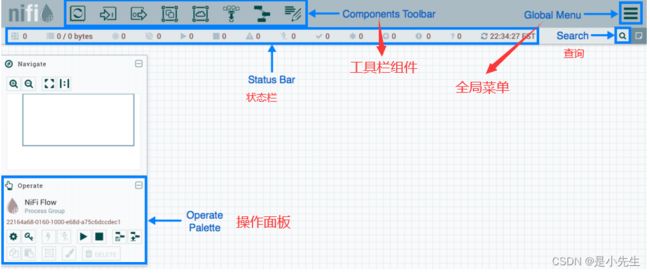
2、全局菜单

3、NIFI登陆界面解读
我们现在可以通过在画布中添加Processor来开始创建数据流。
对话框允许我们选择要添加的处理器

提示:各个处理器的用途及配置在官网上都有介绍,大约提供了近300个常用处理器。包含但不限于:数据格式转换、数据采集、数据(local/kafka/solr/hdfs/hbase/mysql/hive/http等)的读写等功能,使用方便,如果不能满足需求,还可以自定义处理器。
4、配置处理器(GetFile)
 5、连接处理器(将文件转换为csv格式)
5、连接处理器(将文件转换为csv格式)

细节请参照官网解读