安卓进阶系列-系统基础
我喜欢
我喜欢花
我喜欢绿色树叶上面的被雨打过留下的露珠
我喜欢暖风
我喜欢干净
我喜欢咸咸的海风
喜欢喜欢的感觉
愿我此感觉常驻
同样祝福你
文章目录
-
- 计算机结构
-
- 冯·诺依曼结构
- 哈弗结构
- 冯·诺依曼结构与哈弗结构对比
- 安卓采用的架构
- 安卓操作系统
- 进程间通讯(IPC)
-
- 内存共享
-
- linux内存共享
- 安卓内存共享
- 管道
- Unix Domain Socket
- 同步
-
- 常见同步机制
-
- 信号量
- Mutex
- 管程
- 安卓同步机制
-
- 安卓中的Mutex
- 安卓中的Condition
- Barrier
- Autolock
- 内存管理
-
- 虚拟内存
- mmap函数
计算机结构
冯·诺依曼结构
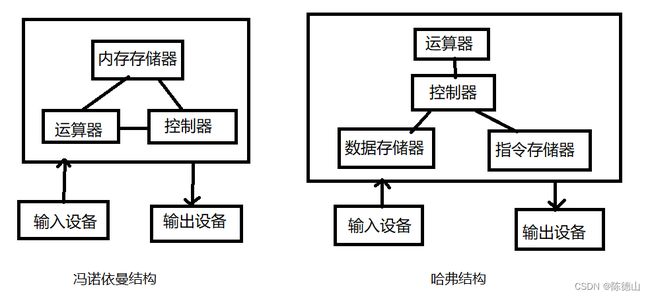
冯·诺依曼结构(也称为存储程序计算机)是一种广泛使用的计算机体系结构,是现代计算机设计的基础。它是由冯·诺依曼(John von Neumann)于1945年提出的,这种结构使用一个单一的存储器来存储指令和数据,通过一个公共总线来传输指令和数据。
冯·诺依曼结构的计算机由五个主要部件组成:中央处理器(CPU)、存储器、输入设备、输出设备和控制器。CPU包括算术逻辑单元(ALU)和控制单元(CU),其中ALU负责执行算术和逻辑操作,CU负责指令的解码和执行。
在冯·诺依曼结构中,指令和数据存储在同一个存储器中,存储器被划分为一系列地址,每个地址存储一个字节。CPU通过总线来访问存储器,可以从任意地址读取指令和数据,并可以将结果写回到存储器中。指令由操作码和操作数组成,CPU从存储器中读取指令,并根据操作码来执行相应的操作。
冯·诺依曼结构的优点是灵活性高,易于实现和扩展,使得计算机可以执行不同类型的任务。但由于指令和数据共享同一条总线,因此读取和写入指令和数据的速度会受到瓶颈的限制,这可能会影响计算机的性能。因此,在高性能计算机和嵌入式系统中,人们使用了一些改进的结构来克服这个问题,如缓存和流水线等。
哈弗结构
哈弗结构(也称为分布式存储器系统)是一种常用于嵌入式系统的计算机体系结构。哈弗结构与冯·诺依曼结构不同之处在于它使用了两个独立的存储器,一个用于存储指令,另一个用于存储数据,这两个存储器可以同时访问。
哈弗结构的CPU包含两个独立的总线接口,一个用于访问指令存储器,另一个用于访问数据存储器。指令和数据分别存储在两个不同的存储器中,因此可以在相同的时钟周期内同时从两个存储器中读取数据。这种结构可以提高计算机的运行效率,减少指令和数据访问的冲突。
由于哈弗结构使用了两个独立的存储器,因此需要更多的硬件资源来实现它。此外,由于指令和数据存储在不同的存储器中,可能会导致一些困难,例如在程序中传递指针时,需要将指针的值从数据存储器中传递到指令存储器中。这些问题可以通过使用高级编程语言和编译器来解决。
总的来说,哈弗结构具有高效的优点,但也需要更多的硬件资源来实现。在嵌入式系统中,由于对运行效率和资源的限制,哈弗结构通常被广泛使用。
冯·诺依曼结构与哈弗结构对比
冯·诺依曼结构和哈佛结构都是计算机体系结构的基本形式,它们之间的主要区别在于存储器和处理器之间的通信方式。
冯·诺依曼结构使用同一条总线来传输指令和数据。指令和数据存储在同一块存储器中,处理器通过总线读取和写入存储器中的指令和数据。这种结构的优点是灵活性高,易于实现和扩展。然而,由于指令和数据共享同一条总线,导致指令和数据的读取和写入不能同时进行,因此会出现瓶颈问题。
哈佛结构则将指令存储器和数据存储器分开,分别使用不同的总线进行通信。处理器可以同时从指令存储器和数据存储器中读取数据,因此具有更高的运行效率。但是,由于指令和数据存储在不同的存储器中,需要更多的硬件资源来实现这种结构。
总的来说,冯·诺依曼结构具有灵活性高的优点,但指令和数据通信会出现瓶颈问题;哈佛结构具有更高的运行效率,但需要更多的硬件资源来实现。
安卓采用的架构
安卓采用的是冯·诺依曼结构。
安卓是一个基于Linux内核的移动操作系统,它使用了冯·诺依曼结构作为计算机体系结构。这是因为冯·诺依曼结构具有灵活性高、易于实现和扩展等优点,可以让计算机执行不同类型的任务。
在安卓中,所有的应用程序和系统服务都是以二进制代码的形式存储在内存中,并且都使用相同的CPU和内存。因此,采用冯·诺依曼结构的计算机可以让安卓系统更加高效地运行,从而提供更好的用户体验。
此外,安卓系统在架构上也支持哈弗结构,但这种结构通常用于一些嵌入式系统,而不是移动设备。因为哈弗结构需要更多的硬件资源来实现,这对于移动设备来说可能会影响性能和功耗。因此,冯·诺依曼结构更适合用于移动设备和操作系统。
安卓操作系统
安卓操作系统是基于Linux内核开发的移动操作系统,而Linux操作系统是一种开源的自由操作系统,其内核也是Linux。
虽然安卓和Linux都使用了Linux内核,但是它们在很多方面有所不同。下面列举一些主要的区别:
应用程序框架不同:Linux操作系统的应用程序主要是基于X11等桌面环境运行的,而安卓的应用程序框架是基于Java语言的。
用户界面不同:Linux通常使用GNOME、KDE、XFCE等桌面环境,而安卓则使用自己的用户界面。
设备驱动程序不同:安卓使用特定于移动设备的硬件驱动程序,而Linux的驱动程序则更加通用。
应用程序管理方式不同:在Linux系统中,应用程序的管理通常是基于包管理器的,而在安卓系统中则是通过应用商店或APK安装包的方式进行管理。
安全性和隐私保护不同:安卓操作系统通常需要应用程序请求权限才能访问用户的敏感数据,而Linux的用户通常会通过sudo命令或者root权限来管理系统,这样可能会增加安全风险。
总之,虽然安卓操作系统和Linux操作系统都使用了Linux内核,但是它们在很多方面都有所不同。安卓操作系统是专门为移动设备而开发的,而Linux操作系统则是通用的操作系统,可以运行在不同的计算机和设备上。
进程间通讯(IPC)
内存共享
linux内存共享
Linux系统中实现共享内存的方式也有多种,其中比较常用的方式是使用shmget()、shmat()等系统调用。
- 创建共享区域 shmget()
shmget()用于创建或访问一个共享内存区域,如果该共享内存区域不存在,则创建一个新的区域。如果区域已经存在,则返回该区域的标识符。
#include 其中,key是共享内存区域的键值,size是共享内存区域的大小,shmflg是共享内存区域的访问权限。
- shmat() 映射内存共享
shmat()用于将一个共享内存区域连接到调用进程的地址空间中,并返回该内存区域的起始地址。
#include 其中,shmid是共享内存区域的标识符,shmaddr是指定连接的地址,如果为NULL,则由系统自动分配地址,shmflg是连接的选项。
安卓内存共享
实现共享内存的方式有多种,其中比较常用的方式是使用匿名映射和共享文件映射。
- 匿名映射
匿名映射是指创建一个匿名的内存区域,并映射到不同的进程中。在安卓系统中,使用mmap()函数来创建匿名映射。
在进程A中,可以通过以下方式创建一个匿名映射区域:
void *shared_memory = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
其中,size表示要创建的映射区域的大小,PROT_READ和PROT_WRITE表示映射区域可以读写,MAP_SHARED表示映射区域是共享的,-1表示使用系统自动分配的地址,0表示起始偏移量为0。
在进程B中,也可以通过相同的方式映射同一个地址:
void *shared_memory = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_ANONYMOUS, -1, 0);
此时进程A和进程B都可以通过shared_memory来访问同一块物理内存区域,从而实现共享内存的目的。
- 共享文件映射
共享文件映射是指将同一个文件映射到不同进程的地址空间中,从而实现不同进程之间的内存共享。在安卓系统中,使用mmap()函数来创建共享文件映射。
在进程A中,可以通过以下方式创建一个共享文件映射区域:
int fd = open("shared_file", O_RDWR|O_CREAT, 0666);
ftruncate(fd, size);
void *shared_memory = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
其中,open()函数用于打开一个共享文件,ftruncate()函数用于设置文件大小,mmap()函数用于将文件映射到进程A的地址空间中。
在进程B中,也可以通过相同的方式映射同一个文件:
int fd = open("shared_file", O_RDWR, 0666);
void *shared_memory = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
此时进程A和进程B都可以通过shared_memory来访问同一块物理内存区域,从而实现共享内存的目的。
管道
在Linux系统中,进程间通信是一个重要的概念。管道是一种进程间通信的方式,它可以将一个进程的输出传递给另一个进程的输入,从而实现两个进程之间的通信。
管道的基本原理是通过创建一个临时文件来实现数据传输。在Linux系统中,管道被实现为一种特殊的文件,它具有以下特点:
- 管道是一个半双工的通道,即只能从一端读取数据,从另一端写入数据;
- 管道通常用于父子进程之间的通信,父进程可以将数据写入管道,子进程可以从管道中读取数据;
- 管道有一个固定的缓冲区大小,当缓冲区满时,写入操作会被阻塞,直到有足够的空间;
- 管道是一个临时文件,当所有相关的进程都关闭了管道之后,操作系统会自动删除这个文件。
Unix Domain Socket
Unix Domain Socket是一种Unix/Linux操作系统中的进程间通信方式。它是基于套接字(Socket)技术实现的,与网络套接字不同的是,Unix Domain Socket不需要通过网络协议栈,而是直接在内核中进行进程间通信。
Unix Domain Socket可以看作是一种本地IPC(Inter-Process Communication)方式,它可以在同一台计算机上的不同进程之间进行通信。使用Unix Domain Socket进行通信的进程之间可以是任意两个进程,它们可以是父子进程、兄弟进程、甚至不在同一个进程组中的进程。
Unix Domain Socket通常使用流式套接字(SOCK_STREAM)或数据报套接字(SOCK_DGRAM)进行通信。流式套接字提供一种可靠的、面向连接的通信方式,类似于TCP协议;数据报套接字则提供一种不可靠的、无连接的通信方式,类似于UDP协议。Unix Domain Socket支持多种通信方式,包括点对点通信、广播通信和多播通信。
Unix Domain Socket(UDS)是专门针对单机内的进程间通信提出来的,有时也被称为IPC
Socket。两者虽然在使用方法上类似,但内部实现原理却有着很大区别。大家所熟识的Network
Socket是以TCP/IP协议栈为基础的,需要分包、重组等一系列操作。而 UDS因为是本机内的“安
全可靠操作”,实现机制上并不依赖于这些协议。
Android中使用最多的一种IPC机制是Binder,其次就是UDS。相关资料显示,2.2版本以前
的Android系统,曾使用Binder作为整个GUI架构中的进程间通信基础。后来因某些原因不得不
弃之而用UDS,可见后者还是有一定优势的。
Unix Domain Socket的优点包括:
它是一种高效的进程间通信方式,因为它不需要经过网络协议栈,通信速度比较快;
它支持多种通信方式,能够满足不同的通信需求;
它可以在同一台计算机上进行通信,避免了网络传输带来的延迟和不稳定性;
它可以通过文件系统进行权限控制,确保通信的安全性。
在Unix/Linux系统中,使用Unix Domain Socket进行进程间通信非常常见,很多系统服务和应用程序都使用Unix Domain Socket来实现进程间通信。例如,Apache Web服务器和PHP-FPM之间就使用Unix Domain Socket进行通信,以提高Web服务器的性能。
同步
常见同步机制
信号量
信号量(Semaphore)是一种用于多进程或多线程之间同步和互斥的机制。它通常被用于控制对共享资源的访问,以避免多个进程或线程同时访问共享资源而引发的问题,如竞态条件、死锁等。
信号量的实现通常基于一个计数器和一个等待队列。计数器用于记录可用的资源数量,等待队列用于记录等待该资源的进程或线程。当一个进程或线程需要访问共享资源时,它会尝试获取信号量。如果计数器的值大于0,则该进程或线程可以访问共享资源,并将计数器的值减1;否则,该进程或线程会进入等待队列等待资源的释放。
当另一个进程或线程释放了该共享资源时,它会调用信号量的V操作(也称为“发信号”操作),将计数器的值加1,同时唤醒等待队列中的一个进程或线程,让其可以访问共享资源。
在Linux系统中,信号量的实现是通过系统调用semget、semop和semctl来完成的。其中,semget用于创建或获取一个信号量集;semop用于对信号量进行操作,如P操作(也称为“等待”操作)和V操作(也称为“发信号”操作);semctl用于对信号量进行控制操作,如获取或设置信号量的值、删除信号量等。
使用信号量可以有效地实现进程或线程之间的同步和互斥,避免了资源竞争和死锁等问题。但是,使用不当也可能会引发一些问题,如信号量的数量过多会增加系统的开销,信号量的使用不当可能会引发饥饿问题等。因此,在使用信号量时需要仔细设计和实现,以确保程序的正确性和性能。
Mutex
Mutex是一种用于多线程之间同步和互斥的机制。它通常被用于控制对共享资源的访问,以避免多个线程同时访问共享资源而引发的问题,如竞态条件、死锁等。
Mutex的实现通常基于一个标志位和一个等待队列。标志位用于记录当前是否有线程正在访问共享资源,等待队列用于记录等待该资源的线程。当一个线程需要访问共享资源时,它会尝试获取Mutex。如果标志位的值为0,则该线程可以访问共享资源,并将标志位的值设置为1;否则,该线程会进入等待队列等待资源的释放。
当另一个线程释放了该共享资源时,它会将标志位的值设置为0,并唤醒等待队列中的一个线程,让其可以访问共享资源。
在Linux系统中,Mutex的实现通常基于互斥锁(Mutex Lock)来完成。互斥锁是一种可重入的、线程安全的锁,它提供了两个主要操作:lock和unlock。当一个线程需要访问共享资源时,它会调用lock操作来获取互斥锁;当它完成访问后,会调用unlock操作来释放互斥锁。如果另一个线程试图获取已经被锁定的互斥锁,它会被阻塞直到锁被释放。
管程
管程(Monitor)是一种高级同步机制,它提供了一种结构化的方式来实现并发程序的同步和互斥。它通常用于多个线程之间共享资源,如共享内存区域、共享文件、网络连接等。
管程由一个包含多个过程(Procedure)和数据的单元组成,其中过程可以被多个线程调用来访问管程中的数据。管程提供了一种机制,确保同一时间只有一个线程可以访问管程中的数据,从而避免了多个线程同时访问数据的问题。
管程中通常包含了互斥量、条件变量等同步机制,用于实现同步和互斥。当一个线程需要访问管程中的数据时,它会首先尝试获取互斥量,以避免多个线程同时访问管程中的数据;然后,它会进入等待状态,直到条件变量满足某个条件。当另一个线程修改了数据并满足了条件时,它会通知等待线程,并将互斥量释放,让等待线程可以访问数据。
管程的实现通常依赖于操作系统提供的同步机制,如互斥锁、条件变量等。在不同的操作系统中,管程的实现可能会有所不同。在一些现代的编程语言中,如Java、Python等,也提供了管程的原语和API,方便开发者使用。
总的来说,管程是一种高级的同步机制,可以提供一种结构化的方式来实现并发程序的同步和互斥,避免了多个线程同时访问共享资源的问题,提高了程序的可维护性和可读性
安卓同步机制
安卓中的Mutex
在Android中,Mutex(互斥锁)是一种同步机制,用于控制多个线程对共享资源的访问。Mutex可以用于实现多个线程对某一资源的互斥访问,以避免多个线程同时访问该资源导致的数据竞争和不一致性。在Android中,可以使用Java中的java.util.concurrent.locks包中的ReentrantLock来实现Mutex。
ReentrantLock是一个可重入的互斥锁,支持公平或非公平的锁。ReentrantLock提供了lock()和unlock()方法来获取和释放锁,与synchronized关键字类似,但是它提供了更多的灵活性和控制。例如,ReentrantLock提供了tryLock()方法来尝试获取锁,如果锁已被占用则返回false,而不是像synchronized关键字一样一直阻塞等待锁的释放。此外,ReentrantLock还提供了lockInterruptibly()方法来实现可中断的锁,即在等待锁的过程中可以响应中断信号。
除了lock()和unlock()方法外,ReentrantLock还提供了其他方法和特性。例如,ReentrantLock可以实现公平锁,即多个线程等待锁时会按照先后顺序获取锁,从而避免饥饿现象。此外,ReentrantLock还提供了Condition对象来实现更为复杂的线程间通信和同步机制。通过Condition对象,线程可以等待某个条件满足时再继续执行,或者唤醒其他等待条件的线程。
在Android中,Mutex通常用于控制对共享资源的访问。例如,在多个线程同时访问某一文件时,可以使用Mutex来实现对该文件的互斥访问,以避免数据竞争和不一致性。另外,在Android中使用Binder通信时,也可以使用Mutex来实现对共享资源的同步访问。例如,在多个进程间共享某一资源时,可以使用Mutex来控制进程对该资源的访问,以保证数据的一致性和正确性。
安卓中的Condition
在Android中,Condition是一种同步机制,它是基于Lock(锁)的。Condition允许线程等待某个条件满足后再继续执行,这个条件可以是另一个线程通知的,也可以是其他事件发生的。在Java中,Condition接口定义在java.util.concurrent.locks包中,它是Lock的一个附属对象。
Condition对象可以通过Lock的newCondition()方法创建,每个Condition对象都与一个Lock对象关联。Condition提供了await()、signal()和signalAll()方法来实现等待和通知机制。
await()方法会使当前线程等待,直到另一个线程通知或中断它。调用await()方法会释放当前线程持有的锁,同时让线程进入等待状态。当另一个线程调用相应的signal()或signalAll()方法来通知当前线程时,当前线程才会重新获取锁并继续执行。
signal()方法会通知一个等待在该Condition对象上的线程,使其从等待状态返回。如果有多个线程在等待,则会通知其中的一个线程,通常是等待时间最长的线程。signalAll()方法会通知所有等待在该Condition对象上的线程,使它们从等待状态返回。
在Android中,Condition通常与Lock一起使用,用于实现更为复杂的同步机制。例如,在多个线程之间共享某一资源时,可以使用Lock和Condition来实现对该资源的互斥访问和同步操作,以避免数据竞争和不一致性。另外,在Android中使用Binder通信时,也可以使用Condition来实现对共享资源的同步访问。例如,在多个进程间共享某一资源时,可以使用Lock和Condition来控制进程对该资源的访问,以保证数据的一致性和正确性。
使用场景:
-
生产者-消费者模型:在多线程环境下,如果一个或多个线程生产数据,另外一个或多个线程消费数据,就会出现数据竞争问题。为了解决这个问题,可以使用Condition来实现线程间的同步。生产者在生产数据后通过Condition唤醒等待的消费者,消费者在消费数据后通过Condition唤醒等待的生产者。
-
读写锁:在多线程环境下,如果多个线程同时读取共享资源,而只有一个线程写入共享资源,那么就需要使用读写锁来实现对共享资源的同步访问。可以使用Condition来实现读写锁的等待和通知机制,实现对共享资源的同步访问。
-
任务队列:在多线程环境下,如果有多个线程需要执行一些任务,那么可以使用任务队列来实现对任务的管理和调度。可以使用Condition来实现任务队列的等待和通知机制,以确保线程按照指定的顺序执行任务。
-
线程池:在多线程环境下,如果需要创建一个线程池来管理多个线程,那么可以使用Condition来实现对线程池的等待和通知机制,以确保线程池中的线程按照指定的顺序执行任务。
Barrier
Barrier是一种线程同步机制,用于实现多个线程之间的同步和协作。它可以使一组线程在某个点上同步等待,直到所有线程都到达该点后才继续执行。在多线程编程中,Barrier被广泛用于控制线程的执行顺序和协调线程之间的交互。它可以用于解决一些并发编程中的难题,比如循环屏障和分治算法等。
在Java中,Barrier通常使用java.util.concurrent.CyclicBarrier类来实现。它的使用方法与CountDownLatch类似,都是通过调用await()方法来等待其他线程的到达。不同之处在于,CyclicBarrier可以重复使用,即在所有线程到达屏障后,它会自动重置为初始状态,从而可以在之后的程序中继续使用。
下面是CyclicBarrier的一些常用方法和特点:
CyclicBarrier(int parties): 创建一个CyclicBarrier实例,指定需要同步的线程数。
await(): 当线程到达屏障时调用,如果还有其他线程未到达,则该线程将阻塞等待。
reset(): 重置屏障状态,使得CyclicBarrier可以被重复使用。
在Android中,CyclicBarrier可以用于实现多线程操作,例如在后台线程中执行耗时任务,然后将结果传递给UI线程进行更新。它也可以用于实现并发算法,比如分治算法,以提高程序的性能和效率。
总之,CyclicBarrier是一种高效的线程同步机制,可以帮助我们处理多线程编程中的复杂问题。在Android中,使用CyclicBarrier可以提高程序的并发性和可靠性,从而满足用户的需求。
Autolock
AutoLock是一种自动锁定机制,用于简化线程锁定的代码实现。在多线程编程中,锁是一种常见的同步机制,用于保证对共享资源的互斥访问,防止竞态条件和数据竞争等问题。传统的锁定方式需要手动加锁和解锁,代码实现比较繁琐且容易出错。而AutoLock可以自动管理锁定和解锁的过程,从而使代码更加简洁和易于维护。
在Java中,AutoLock通常使用try-finally语句块来实现,例如:
Lock lock = new ReentrantLock();
lock.lock();
try {
// 访问共享资源
} finally {
lock.unlock();
}
上述代码中,try-finally语句块会确保锁定的释放,即使在访问共享资源时发生异常也能保证锁定的正确释放。这种方式虽然能够确保锁定的正确性,但是代码比较冗长,不易于维护。
为了简化锁定的代码实现,Java提供了AutoLock机制。使用AutoLock可以将锁定和解锁的过程自动化,例如:
Lock lock = new ReentrantLock();
try (AutoLock ignored = AutoLock.lock(lock)) {
// 访问共享资源
}
上述代码中,AutoLock的lock方法会获取指定的锁,并返回一个AutoLock对象。当代码块执行完毕后,AutoLock对象会自动释放锁定,从而避免了手动解锁的过程。这种方式比传统的try-finally语句块更加简洁和易于使用。
在Android中,AutoLock同样可以用于简化线程锁定的代码实现。它可以帮助我们处理多线程编程中的复杂问题,提高代码的可读性和可维护性,从而更好地满足用户的需求。
内存管理
虚拟内存
虚拟内存是一种计算机内存管理技术,它将计算机主存(RAM)抽象为一种看似无限大的地址空间,这个地址空间被称为虚拟地址空间。虚拟内存的实现方式是通过将主存和磁盘存储器结合使用,使得程序能够访问比实际内存更大的地址空间。
虚拟内存的主要优势在于它能够让多个进程同时运行,并且在运行过程中它们都能够访问到自己的地址空间,从而实现了内存隔离。此外,虚拟内存还能够将磁盘上的文件映射到虚拟地址空间中,这样程序就可以像访问内存一样访问文件。
在虚拟内存中,每个进程都有自己的虚拟地址空间,这个地址空间包含了程序所需的所有内存。进程使用的每个虚拟地址都被映射到实际的物理地址上。当进程访问一个虚拟地址时,虚拟内存会自动将这个虚拟地址映射到实际的物理地址上。如果这个虚拟地址对应的物理地址不在主存中,虚拟内存会从磁盘中读取相应的数据到内存中,并将这个数据的虚拟地址映射到实际的物理地址上。
虚拟内存的实现需要使用到页表和页式存储技术。页表是一个数据结构,用于记录虚拟地址和物理地址之间的映射关系。页式存储是一种存储管理技术,它将物理内存和虚拟地址空间都分成固定大小的页。当进程访问一个虚拟地址时,虚拟内存会将这个地址转换成页号和页内偏移量,然后使用页表查找这个虚拟地址对应的物理地址。如果这个物理地址不在主存中,虚拟内存会将需要的页面从磁盘中读取到主存中,并更新页表中的映射关系。
虚拟内存的实现方式有多种,包括分页式、分段式和混合式等。其中,分页式是最常见的实现方式,它将主存和虚拟地址空间都分成固定大小的页面,并使用页表来实现地址转换。虚拟内存的大小可以通过修改操作系统的参数来调整,不同的操作系统和硬件平台支持的最大虚拟内存大小也不尽相同。
理解虚拟内存机制,首先要学习三种不同的地址空间。
- 逻辑地址
逻辑地址是指程序在运行时所使用的地址,也称为虚拟地址。每个程序都有自己独立的虚拟地址空间,相互之间不会干扰。逻辑地址由操作系统管理,由CPU产生,用于指令和数据的寻址。
逻辑地址由两个部分组成:段地址和偏移地址。其中,段地址指明程序中的某一段内存空间,可以是代码段、数据段、堆栈段等,偏移地址则是该段内部的相对地址,表示距离该段起始地址的偏移量。通过这两部分地址可以唯一地确定程序中的某个内存单元。
逻辑地址的使用可以为程序提供了更大的内存空间,因为操作系统可以将物理内存分成多个虚拟地址空间,每个程序都有自己的虚拟地址空间,而不必担心物理内存的限制。此外,逻辑地址还为操作系统提供了更好的内存管理能力。在使用逻辑地址时,操作系统可以将程序需要的内存空间划分成多个段,对每个段进行保护和管理,从而保证程序之间的内存空间不会互相干扰。
逻辑地址的使用还可以方便地实现动态链接、虚拟内存等功能。动态链接是指程序在运行时才会根据需要链接所需的库文件,而不是在编译时就将库文件链接进程序中。虚拟内存是指将部分程序数据暂时存储在硬盘上,以释放物理内存,待需要时再将其调入内存,从而扩大程序可以使用的内存空间。
- 线性地址
线性地址是由虚拟地址通过页表映射得到的,它具有以下两个特征:
-
线性地址是连续的,这意味着CPU可以将它们视为一个大的地址空间,而不必担心实际内存中的数据在哪里存储。
-
线性地址是与物理地址分离的。物理地址是在RAM中分配的实际内存地址,而线性地址是虚拟地址,可以映射到任何物理地址。
因此,虚拟内存和线性地址允许操作系统和CPU管理内存,使多个进程可以共享相同的物理内存而不会互相干扰,也可以保护进程不受其他进程的干扰。同时,虚拟内存也为操作系统提供了一种将内存映射到磁盘上的方法,从而使操作系统能够更有效地使用系统资源。
- 物理地址
物理地址是指实际的硬件地址,是计算机内存中每个存储单元的唯一地址。在计算机系统中,程序代码和数据必须存储在内存中才能被CPU访问,而CPU访问内存时需要使用物理地址。
物理地址与逻辑地址和线性地址相对应。逻辑地址是程序代码中使用的地址,由程序生成,而不是实际存在于内存中的地址。线性地址是虚拟地址,通过页表映射得到的地址。物理地址是实际存在于内存中的地址,它是通过线性地址再次映射得到的。
物理地址是在计算机系统中非常重要的概念,因为它决定了CPU访问内存时的实际位置。操作系统负责将逻辑地址或线性地址映射到物理地址,这个过程通常是由CPU的内存管理单元(MMU)来处理的。
在访问内存时,CPU将逻辑地址或线性地址发送到MMU中,MMU通过页表将线性地址映射到物理地址。然后,CPU使用物理地址从内存中读取数据或写入数据。
物理地址的大小由计算机系统的架构和硬件决定。在32位系统中,物理地址通常是32位长,可以寻址最多4GB的内存。而在64位系统中,物理地址通常是64位长,可以寻址的内存空间非常巨大,远远超过目前可用的物理内存容量。
mmap函数
mmap() 是一个 UNIX/Linux 操作系统下的系统调用函数,主要用于实现文件的内存映射操作。mmap() 函数可以将一个文件或者其它对象映射到调用进程的地址空间,然后进程就可以像访问内存一样访问该文件。
mmap() 函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
参数解释:
- addr:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址。
- length:代表将文件中多少字节映射到内存中。
- prot:映射区域的保护方式,可取值为 PROT_NONE, PROT_READ, PROT_WRITE 和 PROT_EXEC,分别代表该区域不能被访问、该区域可被读取、该区域可被写入和该区域可被执行。这些属性是可以通过或运算组合在一起使用的。
- flags:指定映射对象的类型,常见的是 MAP_SHARED 和 MAP_PRIVATE。MAP_SHARED 表示映射区域的修改会反映回文件中,而 MAP_PRIVATE 表示映射区域的修改仅仅对该进程可见,不会反映回文件中。在使用 MAP_PRIVATE 时,映射区域是写时拷贝的,即只有当写入时才会发生真正的写操作,此时才会分配物理内存并将文件数据复制到其中。
- fd:被映射对象的文件描述符。
- offset:从文件起始位置开始的偏移量,通常设置为 0。
- mmap() 函数成功执行后,会返回一个指向被映射区域的起始地址的指针,如果操作失败,则返回 MAP_FAILED。
mmap() 函数的优点在于能够快速、方便地实现文件到内存的映射,同时支持共享内存和私有内存两种映射方式。在实现进程间通信和共享数据时,mmap() 函数非常实用。