优秀软件方法学“漫游记”
你好,我是东(在极客时间的 ID 是 Fredo)。大学的时候我读的是计算机专业,现在是一名工作了近3年的程序员,很高兴能和你分享我的学习体会。
我是怎样学习课程的?
首先聊聊我是怎么学习这门课的。
DDD 是一个很老的概念,但在我身边的技术圈,这仍然是个常常被提起的词。不过很多人在谈论这个概念,但很少有人说清楚,并给出详细具体的实践指导。
我就是抱着试试的心态,想看看作者到底是要怎么“手把手”教我 DDD 。我急迫地寻找课程里一些 DDD 的概念名词,试图验证一下作者讲的和我之前理解的是不是一回事,稍后我再专门说说对我启发最大的几点。
课程案例以迭代的形式展开,我试着投入其中,想象自己是敏捷团队中的一员,正在参与这个迭代。
迭代一按照“捕获需求、建立领域模型、模型实现”的顺序串了一遍,这大概还是一个三段论的模式,即发现问题(收集需求)、分析问题(建立模型)、解决问题(编码实现)。
由于我之前有一些 UML 的基础,课程里的分析图看起来没有多大障碍。每看完一节课,我都会将其中涉及的 DDD 中的术语记录在导图中。同时,跟随老师的分析,我结合自己的理解,提炼了一些重要的区分点和有助于回忆内容的关键词,把它们体现在了导图里。

第二遍阅读课程(正在进行中),我的关注点主要放在了DDD代码实现层面,主要会对比迭代中的代码,与我当前的项目结构以及代码组织方式有什么异同。
之后,我打算再跟着迭代案例分析过程,将其中的领域模型图再好好画一遍,进一步体会“领域模型与业务需求一致,系统实现与领域模型一致”的原则。
我从课里学到了什么
课程里有很多值得反复咀嚼的内容,这里我就抛砖引玉,分享一些印象最深刻的点。
编程范式的选择不是非黑即白
印象里在上大学的时候,我曾经在一门系统分析与设计类的课程,趁着课间,跑上讲台跟老师问过这样一个问题:“面向对象强调对象的属性与行为在一起,而我现在的编程方式自然地将逻辑都放在 Service 里面了。虽然使用的是面向对象的编程语言,但感觉自己还是在用面向过程的思路,该怎么办呢?”。
老师的回答已淡出了记忆,然而这个问题始终萦绕心头。不排除是大一的时候就学了 C 语言的缘故,过于习惯面向过程的处理方式。
后来工作了,编程范式上的“纠结”还是困扰着我。第10节课《要“贫血”模型还是要“充血”》讲的就是这个问题,编程范式在一个发展的过程中,开发者的认知也在成长,编程范式的选择不是一个非黑即白的问题,需要我们根据所开发的软件、编程语言、团队编程习惯等去找到一个平衡点。
模块划分方法
第11节课《怎么创建领域对象、实现领域逻辑》中,老师提到了一种指导模块划分的方法——打横(分层)与打竖(耦合关系)。
打横是站在按性质的角度对代码进行分层,如适配器层、应用服务层、领域服务层、基础Common层。
打竖是按耦合性,我们可以在已经分层的包下,再根据耦合关系来分包。按我之前的分包方式,通常是按照代码的性质分包的,也就是仅仅做了打横这一步。
对比之后不难发现,按打横与打竖的分包方式,后面的包结构在各层下面会更加细粒度。虽然包结构变多了,但是Domain层的各聚合内,代码显得更加紧凑、高内聚。
以聚合为单位进行持久化
我之前对仓库的认知是一个数据库表对应一个 DAO,就算有单独拎出一个 Repository,也仅仅做了对 DAO 的一个委派,然后在业务代码层面将数据取出来处理。
而第16课《怎么实现不变规则》中讲到,Repository 是针对整个聚合的,而不是从数据库表的角度。
这个说法打破了我的惯性认识,现在想起来仍然记忆犹新。我原先的想法缺乏领域意识,将应用服务和领域逻辑混杂在了一起,变成了基于 CRUD 的面向过程编程。
而一个 Repository 负责一个聚合的持久化,聚合内部紧密相关的对象生命周期就得到了统一管理。如果我们需要测试领域服务,只需要mock聚合对应的仓库即可,这有利于我们对领域服务代码的测试。
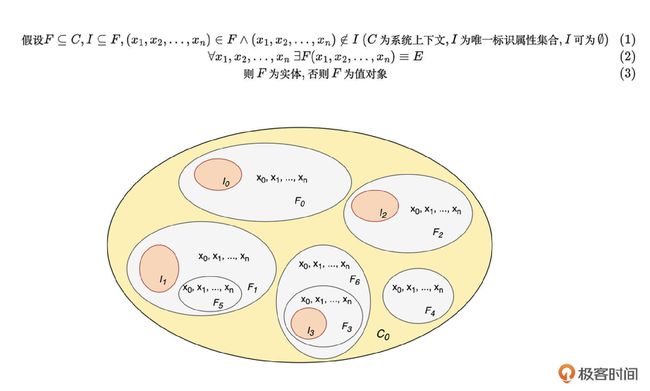
值对象和实体的本质区别
值对象和实体虽然是DDD里“人尽皆知”的知识点了,但想要说清楚两者的本质区别还是有难度的。
第20节课里,从认识论的角度去讲解,让我觉得很新颖。
这两者的区分,有一个有趣的方式可供参考判断,我们可以向自己提问:存在F的属性/属性值可以改变吗,如果属性/属性值改变了,存在F还是存在F吗?
如果得到的答案是“是”,则F为实体,否则就是值对象。
还有一些需要注意的点,需要根据上下文结合判断(这也是 DDD 原书中提到的),比如在邮政软件或地图软件中重新划分了行政区域,那么所有使用邮政软件或地图软件的地址都将改变,这个上下文里面,地址就是实体。而对于某个用户的购物软件中的收件地址,仅表示这个用户实体的收件地址,这里就应该当成值对象来处理。
我还尝试用数学语言和图解描述了一下(可能不准确,欢迎批评指正)。
泛化的表设计策略
软件架构或设计里经常需要我们做取舍,没有唯一的答案,具体问题具体分析,权衡利弊之后,才能得到当前问题域下的一个相对最优解。这种不确定性很有意思,同时也很有挑战。
就拿泛化的数据库表设计来说,我之前的常用做法是整个泛化体系一张表。可能我碰到的大多数情况,子类没有太多的不同属性,即便有几个字段的空间浪费,也可以接受。
而第25节课里,不但提到了泛化的三种数据库表设计策略。更重要的是给了我一个指导方针,在空间效率、时间效率、系统的可维护性这些维度去考量。相比原先凭直觉行事,知其所以然的衡量判断,才更有可能在设计上给出有说服力的方案。
品读经典与刻意练习
工作之后,我们常常被一些糟糕的代码“折磨”,但心中仍追求着整洁代码、优雅的分析设计,希望实现“良质”的软件开发(“良质”这个词来自《禅与摩托车维修艺术》这本书,你有兴趣的话可以去翻一下)。
在我看来,计算机领域里,“良质”和软件大师们探索、归纳出的分析方法、原则、模式是异曲同工的。沿着他们的思路,配合自己的实践,我们才更有可能实现一个具备“良质”的软件系统。
而想要了解这些经验模式,很重要的一个途径就是阅读经典、学习原著。老师经常在课程中指出知识点在 DDD 原书中的出处,正好我旁边也放着两本书《领域驱动设计》和《实现领域驱动设计》,可以随时看一下对应的章节。
课程里还特意用两节选学的内容介绍了相关的经典书籍,让我燃起了重读经典的兴趣,算是意外惊喜。
之前我曾细读了《实现领域驱动设计》,可惜因畏难情绪而将原书《领域驱动设计》放置一旁,《分析模式》更是从未问津。老师有个“经”与“传”的提法,将原书比作“经”,一手资料的知识密度及重要性可见一斑。
我尝试了在课程学习过程中去阅读一些相关图书,感觉对巩固知识很有帮助。在迭代一第12节课中,老师的案例用到了不少重构手法,我们可以在《重构》原书中找到对应的章节。
比方说有两个技能点,我现在已经有意识地用在了日常工作里,分别是提高封装性的“表意接口”,还有发现和消除“特性依恋”。你可以在《重构》的3.9节找到它们,这两招能让我们的代码更加 OO done right (把面向对象做对)。
通过命名表达意图和将函数写短的方法也很实用,如果命名已经清晰地说明了一切,就没有注释的必要(《重构》3.24节)。
另外,再补充一个我在实际开发时发现的问题,也和封装性有关。项目开发中很多小伙伴喜欢用的 lombok 插件,虽然能够为我们节约一些时间,但不假思索地使用 @Data 注解会破坏封装性,需要收敛着用。

经典仰之弥高,课程里的迭代案例亦循循善诱。在阅读经典的过程中,我时常会惊讶于我所遇到的问题,前人早已就碰到了,并且分析问题直捣本质,给人以启发。
不过,软件工程没有银弹,这些经典提供了各式各样的思路和方案,能培养我们对“好”的认识。但想要把高手的心法招式化为己用,还离不开刻意练习。
就像王小波说的那样,“生活就是个缓慢受锤的过程”,编程技艺的学习旅程也是同样的体验。希望我们面对各种锤炼仍然能生猛下去,热爱雕琢技艺,也热爱滚烫生活。
文章来源:极客时间《手把手教你落地 DDD》