Postgresql 复制延迟 和 复制"延迟" 与 复制停止大乌龙

Mysql的逻辑复制性能虽然被诟病的比较久了,但是功能多,延迟复制,级联复制,多源复制. 尤其MYSQL的复制的灵活性有种被玩坏了感觉. POSTGRESQL 的复制方式其实也是支持延迟库的,POSTGRESQL 的WAL 的复制方式也是比较灵活的,PITR . 实际上原理就是延迟数据的重放.PostgreSQL使用的是流复制,所以它的设计速度非常快,因为WAL接收者截取了一组日志记录,然后把这些日志记录写到WAL文件中。那么这篇文字要说的一个复制延迟是人为的复制延迟, 另一个是实际上由于某些原因导致的复制延迟.
在操作延迟库前,我们需要对一些复制的参数的含义进行一个更深入的认识
max_wal_senders
max_wal_senders 设置的数字主要是供给数据复制和备份使用,所以max_wal_senders 可以设置的大一些.
wal_keep_segments
设置主服务器存留的最小的数据段,在进行主备复制的过程中,存留在主服务器的WAL日志的数量,在复制中需要被复制的WAL 日志不会被删除导致复制终止.
vacuum_defer_cleanup_age
这个参数是控制vacuum 时可见的数据的信息,默认是0 只要VACUUM进行清理就将信息清理,不会留存,但如果是从库,会因为增长操作的SELECT 语句和要清理的VACUUM 数据之间的冲突,导致SELECT 被KILL 无法执行.所以在OLAP的系统的从库可以调整这个值,延长某些数据VACUUM后可以被使用的时间.
synchronous_standby_names 主库参数
指定一个或一组可以进行数据同步复制的备用机的列表
hot_standby
指定备用机是否可以在recovery的状态中,进行数据的读取.默认是可以进行数据的读取.
wal_sender_timeout
判断从库的复制是否还在正常的最大的回应的时间
wal_receiver_status_interval = 10s
默认从库恢复主库的最大的时间的间隔
hot_standby_feedback
在从库查询数据时是否将查询的状态反馈给主库,默认是关闭,则主库的数据如果被VACUUM 则查询被终止,但如果打开,则主库的VACUUM 将被终止,所以如果系统不是OLAP等系统并且强需要从库读取处理数据则这个参数必须备份OFF
wal_retrieve_retry_interval
在主从库之间无法进行访问的情况下,从库多长时间会在重试与数据库之间的连接,默认是5S , 在网络不佳的情况下可以将值变小.
recovery_min_apply_delay
主库和从库之间的延迟的时间也就是需要延后重放数据的时间的设定,这个参数作用在于让从库的应用的WAL 日志的时间延后,这个参数必须注意,在使用这个参数是尽量不要同时使用 hot_standby_feedback 参数, 同时使用有可能会导致主库的WAL 膨胀的问题.
对POSTGRESQL 的从库进行延迟的设定也很简单,这里以PG12为例,我们在通过
pg_basebackup -h 192.168.198.101 -U repuser -p 5432 -D /pgdata/data/ -Fp -Xs -P -R
在从库将主库的数据拉取后,我们直接调整 recovery_min_appy_delay = 1h 则从库的数据理论会比主库的数据要晚一个小时.
怎么通过语句来查看复制有延迟,在从库运行如下语句
SELECT
CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
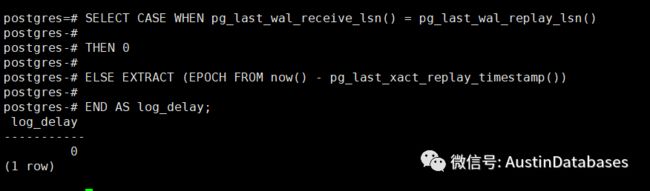
实际上复制延迟是通过主节点/主节点与备节点/从节点之间的执行时间差异计算的事务或操作延迟的成本.
什么情况下会产生复制延迟
1 网络的问题导致的
2 没有找到需要复制的WAL数据段,一般出现这样的问题主要是由于在checkpoint后wal 段被替换或回收了
3 系统繁忙的情况,系统的性能降低导致数据复制的功能被挤压
4 硬件的性能无法支持数据复制
5 错误的POSTGRESQL 的参数导致复制出现问题,例如设置不足的max_wal_senders数量
为了能发现问题,对于复制的监控就必不可少了
基本的监控方面我们通过 pg_stat_replication 来获得基本的数据,
state 字段说明当前复制的进程的状态
sent_lsn 当前最后主库发送给从库的lsn
write_lsn 当前最后从库的操作系统
flush_lsn 当前最后从库操作系统FLUSH 到磁盘的wal
replay_lsn 当前数据库系统可以可以看到的wal log
而write_lag flush_lag replay_lag 这三个是从库与主库之间的延迟时间

select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
POSTGRESQL 会对复制开一个进程进行数据的传递
说到大乌龙,其实是最近在一个服务器上进行了PITR的时间恢复后,进行了主从复制的设置,但发现一个怪的问题,只要在主库上进行相关的建表和删除表的操作,复制就停止,(这里并未进行相关的其他的DML的操作). 找问题找了半天,
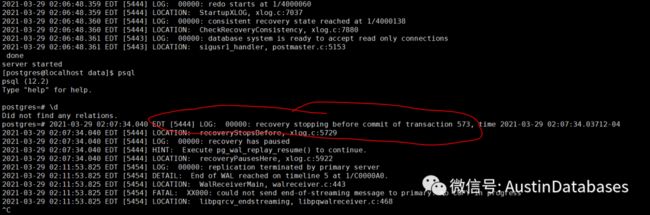
1 查看两台机器的主从复制的问题, 发现两台服务器的时间之间是不同的,这边调整了时间,重启动服务器,问题依旧.
2 搭建了同样配置的服务的服务器,并且简单配置,复制能进行,DDL操作没有问题
3 对比了没有问题和有问题的服务器的配置的POSTGRESQL.CONF 文件, 没有区别, 唯一的一个 wal log hit 的不同也都改为相同了
但问题依然没有解决.
4 打开了POSTGERSQL 的日志的详细度想从里面发现一些问题,还是没有发现什么问题
5 最终打开了postgresql.auto.conf 发现了

将这些删除掉重新操作了复制,问题解决.
有的时候不少问题,出现的原因
1 不仔细
2 原理不清晰
