缓存模式(Cache Aside、Read Through、Write Through、Write Behind)
概览
缓存是一个有着更快的查询速度的存储技术,这里的更快是指比起从初始的数据源查询(比如数据库,以下都称作数据库)而言。我们经常会把频繁请求的或是耗时计算的数据缓存起来,在程序收到请求这些数据的时候可以直接从缓存中查询数据返回给客户端来提高系统的吞吐量,现在我们来看看有哪些缓存模式可以考虑。
Cache-Aside
Cache-Aside 是最广泛使用的缓存模式之一,如果能正确使用 Cache-Aside 的话,能极大的提升应用性能, Cache-Aside 可用来读或写操作。
读操作
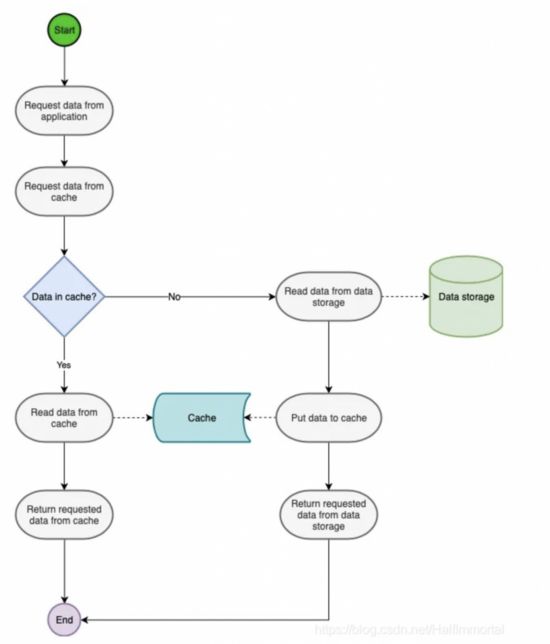
我们先来看下读操作的数据流:
- 1、程序接收数据查询的请求
- 2、程序检查要查询的数据是否在缓存上
- 如果存在(cache hit),从缓存上查询出来
- 如果不存在(cache miss),从数据库中检索数据并存入缓存中
- 3、程序返回要查询的数据
在Spring中,可如下实现,当 getRecordForSearch() 方法被调用的时候,如果缓存中存在对应key的数据,那就会自动的从缓存中获取(此时方法体不会被执行),当缓存中不存在key对应数据的时候,会执行方法体从数据库中查询数据并设置到缓存中去。
@Cacheable("default", key="#search.keyword)public Record getRecordForSearch(Search search)
更新操作
如果程序需要更新数据库中的数据且该数据也在缓存上,此时缓存中的数据也需要做相应的处理。为了解决这个不同步的问题来确认数据的一致性和操作性能,有两个方式可按需使用。
缓存失效
该情况下,当请求需要更新数据库数据的时候,缓存中的值需要被删除掉(删除掉就表示旧值不可用了),当下次该key被再次查询到就去数据库中查出最新的数据,在Spring中可实现如下:
@CacheEvict("default", key="#search.keyword)public Record updateRecordForSearch(Search search)
缓存更新
缓存数据也可以在数据库更新的时候被更新,从而在一次操作中让之后的查询有更快的查询体验和更好的数据一致性,在Spring中可实现如下:
@CachePut("default", key="#search.keyword)public Record updateRecordForSearch(Search search)
为了应对不用类型的数据需要,有以下缓存加载策略可被选择:
- 使用时加载缓存 :当需要使用缓存数据时,就从数据库中把它查询出来,第一次查询之后,接下来的请求都能从缓存中查询到数据。
- 预加载缓存 :在项目启动的时候,预加载类似“国家信息、货币信息、用户信息,新闻信息”等不是经常变更的数据。
Read-Through
Read-Through 和 Cache-Aside 很相似,不同点在于程序不需要再去管理从哪去读数据(缓存还是数据库)。相反它会直接从缓存中读数据,该场景下是缓存去决定从哪查询数据。当我们比较两者的时候这是一个优势因为它会让程序代码变得更简洁。

Write-Through
Write-Through 下所有的写操作都经过缓存,每次我们向缓存中写数据的时候,缓存会把数据持久化到对应的数据库中去,且这两个操作都在一个事务中完成。因此,只有两次都写成功了才是最终写成功了。这的确带来了一些写延迟但是它保证了数据一致性。
同时,因为程序只和缓存交互,编码会变得更加简单和整洁,当你需要在多处复用相同逻辑的时候这点变的格外明显。
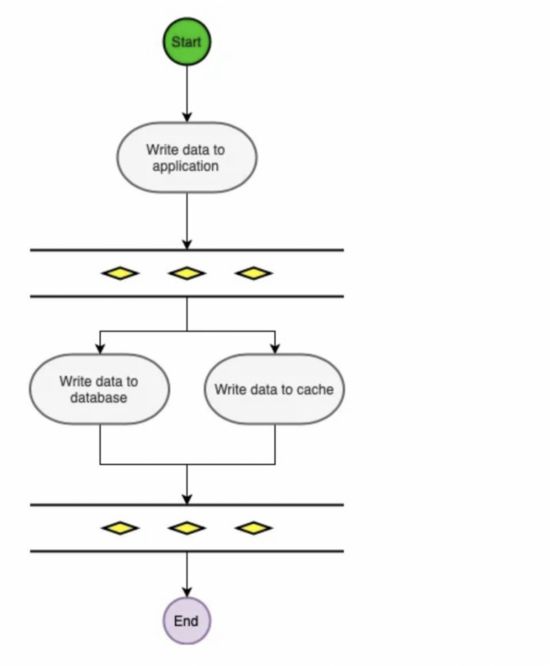
当使用 Write-Through 的时候一般都配合使用 Read-Through 。
Write-Through 适用情况有:
Write-Behind
Write-Through 的潜在使用例子是银行系统。
Write-Behind
Write-Behind 和 Write-Through 在“程序只和缓存交互且只能通过缓存写数据”这一点上很相似。不同点在于 Write-Through 会把数据立即写入数据库中,而 Write-Behind 会在一段时间之后(或是被其他方式触发)把数据一起写入数据库,这个异步写操作是 Write-Behind 的最大特点。
数据库写操作可以用不同的方式完成,其中一个方式就是收集所有的写操作并在某一时间点(比如数据库负载低的时候)批量写入。另一种方式就是合并几个写操作成为一个小批次操作,接着缓存收集写操作(比如5个)一起批量写入。
异步写操作极大的降低了请求延迟并减轻了数据库的负担。同时也放大了数据不一致的。比如有人此时直接从数据库中查询数据,但是更新的数据还未被写入数据库,此时查询到的数据就不是最新的数据。
总结
真实的系统中需求都不太一样,我们应该根据自己的需要来选择一个或组合几个模式来完成实现。