Java集合框架底层原理
Java集合框架
- Java集合框架
- List集合
-
- ArrayList底层实现原理
-
- ArrayList数组扩容技术(数组拷贝)
- 扩容大小
- 查询和删除
- 集合中的泛型
- LinkedList
- Vector 线程安全
- LinkedList和ArrayList区别
- Map集合
-
- HashMap底层实现原理
-
- 链表存放的都是那些数据?
- 数组初始化
- HashMap的扩容机制
- ConcurrentHashMap底层原理
-
- JDK1.7 HashMap在多线程下线程不安全
-
- 如何判断单链表有环无环
- HashTable与ConcurrentHashMap
- Segment
- JDK1.8版本ConcurrentHashMap
-
- 相比于 1.7 版本,它做了两个改进
- CAS (compare and swap比较交换)
- Node链表和红黑树的切换
Java集合框架
所有集合类都位于java.util包下。Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口。
集合特点:
1、所有集合底层基本都是数组(除了LinkedList)
2、集合中可以存放无限大小的数据=>采用数组扩容
集合的关系:
Set 接口继承 Collection,集合元素不重复。
List 接口继承 Collection,允许重复,维护元素插入顺序
Map接口是键-值对象,与Collection接口没有什么关系。
List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问
List集合
List集合继承Collection,重点说一下ArrayList和LinkedList,简要说一下Vector。
ArrayList底层实现原理
1.Arraylist底层基于数组实现
private Object[] elementData;
2.Arraylist底层默认数组初始化大小为10个object数组
public ExtArraylist() throws Exception {
this(10);
}
public ExtArraylist(int initialCapacity) throws Exception {
if (initialCapacity < 0) {
throw new IllegalArgumentException("初始容量不能小于0 " + initialCapacity);
}
elementData = new Object[initialCapacity];
}
3.添加元素后大于当前数组的长度,则进行扩容,将数组的长度增加原来数组的一半。
// 增大数组空间
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 在原来容量的基础上加上
// oldCapacity/2
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity; // 最少保证容量和minCapacity一样
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity); // 最多不能超过最大容量
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
ArrayList数组扩容技术(数组拷贝)
eg:
Object[] arr = {1,2};
Object[] copyNew = Arrays.copy(arr,10);//原来数组arr,扩容加10,并保证原来数据不变。
/*
System.arraycopy方法:如果是数组比较大,那么使用System.arraycopy会比较有优势,因为其使用的是内存复制,省去了大量的数组寻址访问等时间
*/
ArrayList正是采用System.arraycopy进行扩容。System.arraycopy是一个Native修饰的方法,由C语言写的,本地是找不到的。
数组数据量不大的时候,System.arraycopy和Arrays.copy差别不大。但数组数据变大时,System.arraycopy效率优于Arrays.copy。
所以,从JDK1.6开始,Arrays.copy底层也使用了System.arraycopy来实现。
ArrayList底层采用数组实现,数组的名称叫“ElementData”。
ArrayList底层默认数组的大小为10.
JDK1.6初始化默认大小数组在构造器中,JDK1.7之后数组初始化是放在了add()方法中。因此,在定义ArrayList的时候,数组是没有初始化的。
扩容大小
扩容是在add()方法中,先判断大小,如果size=elementData.length。即实际元素个数超过数组容量,就会扩容。
ArrayList扩容是原来的1.5倍。源码如下:
int oldCapacity = elementData.length.
int newCapacity = oldCapacity + (oldCapacity>>1);//右移1位相当于除以2
如果ArrayList的初始容量为1,那么扩容后的容量为多少?
答案:仍然是1(错误)
应该是2(正确)
因为JDK由保证最小扩容容量的代码,如下:
ensureCapacity(size + 1) //minCapacity = size + 1;所以值等于2
if(newCapacity - minCapacity < 0){
newCapacity = minCapacity;//minCapacity值是2
}
查询和删除
get(index) 使用数组下标进行查询(查之前对index是否越界进行判断)
remove(index) 删除原理:
元素:A B C D E
下标:0 1 2 3 4
删除后:
元素:A B D E null
下标:0 1 2 3 4
代码如下:
System.arrayCopy(elementData,index+1,elementData,index,numMoved)
//如果删除的是最后一个元素,就直接将最后以一个元素置空
集合中的泛型
Java的反射机制有个缺点:不能获取泛型类型。因为泛型是在编译之后是没有的。
泛型是运行时才确定类型,(通过字节码技术可以获取到泛型)
LinkedList
LinkedList是双向链表,可以双向遍历查询。
Vector 线程安全
Vector相当于线程安全的ArrayList,里面用了大量的锁。内部实现和ArrayList几乎一样。
LinkedList和ArrayList区别
首先,LinkedList底层删除和新增的时候,不会移动元素,只会维护内部节点的关系。
ArrayList删除的时候,将当前元素后面数据往前移动移位。这时会用到扩容技术,这种方式效率比较低。
其次,LinkedList查询慢。因为链表没有下标,需要一个个遍历查询。(从first开始查询)
ArrayList查询非常快,可以直接使用下标查询。
Map集合
HashMap底层实现原理
HashMap在JDK1.7中使用数组+链表,在JDK1.8中使用数组+红黑树来实现的。官方说1.8比1.7性能提升15%.
HashMap底层扩容技术:采用负载因子(0.75)
float DEFAULT_LOAD_CAPACITY = 0.75f
HashMap冲突(碰撞):采用链表(1.7)、红黑树(1.8)来处理冲突。
链表处理的时候,是把之前的Node作为新冲突Node的下一个节点。
链表存放的都是那些数据?
hash值相同,类型都是Entry。Entry包含key、value、next三个属性。
数组初始化
默认数组初始化大小为:16
DEFAULT_INITAL_CAPACITY = 16;
HashMap和ArrayList一样默认都是懒加载,初始化的数组大小都是null,只有在put(key,value)、add(element)时候才会初始化数组大小。
HashMap的扩容机制
为什么要扩容?
1、数据一旦满了的话无法存储。
2、数据一多链表查询效率低,影响HashMap的性能。
扩容之后,有什么影响?
需要重新计算hash值。
HashMap从什么时候开始扩容?
有个负载因子0.75,hash初始化容量大小是16.当数据size>=12时候开始扩容。
HashMap数组扩容,一次扩容多少?
扩容为之前数组的两倍。
ConcurrentHashMap底层原理
JDK1.7 HashMap在多线程下线程不安全
JDK7 HashMap在并发执行put()方法时候会引起死循环。是因为多线程会导致HashMap的Entry链表形成环形数据,让链表有环,查找时会陷入死循环。
如何判断单链表有环无环
方法1:单链表有环,遍历会陷入死循环。(最简单,但这种方式不靠谱)
方法2:每遍历1个节点就比较之前遍历的节点,如果重复,就表示有环。
方法3:有2个快慢指针slow和fast同时指向头结点。slow每次遍历1个节点,fast每次遍历2个节点。如果单链表无环slow永远追不上fast,否则slow能追上fast。
HashTable与ConcurrentHashMap
使用synchronized同步锁,保障了线程安全,但是效率不高。
synchronized关键字对put()等方法加锁,而synchronized是对整个对象加锁。put()方法在并发修改数据时候,锁住了整个Hash散列表。故HashTable效率低下。
JDK1.7 ConcurrentHashMap的做法:
JDK1.7ConcurrentHashMap对象保存了一个Segment数组,即将Hash分为16段。每个Segment元素即相当于一个HashTable。
执行put方法时,根据Hash算法定位到哪个Segment,然后对Segment加锁。第二次Hash定位到元素头部链表位置。
所以ConcurrentHashMap可以在多线程下实现put操作。
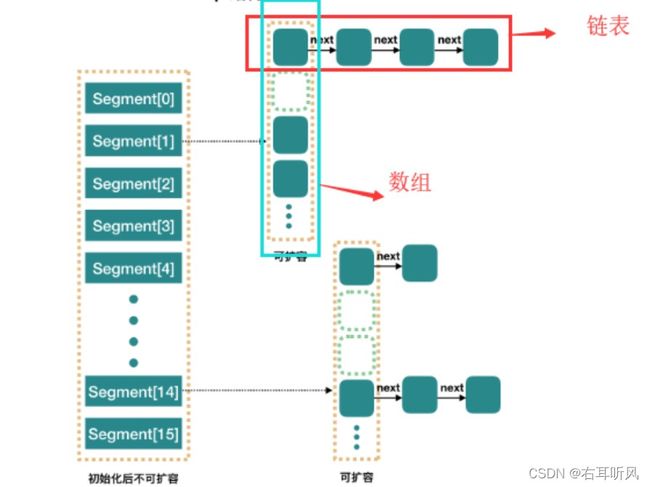
Segment
Segment继承了ReetrantLock,表示Segment是一个重入锁。因此ConcurrentHashMap可以通过重入锁对每个分段加锁。
默认情况下,初始化数组的大小是16,Segment数组长度也是16,负载因子也是0.75。
ConcurrentHashMap的get方法是不加锁的,用volatile保证。
ConcurrentHashMap规定key和value均不能为null,否则会抛出空指针异常。(因为会产生线程安全问题)
JDK1.8版本ConcurrentHashMap
JDK1.8版本ConcurrentHashMap采用数组+链表+红黑树来实现。加锁使用CAS和synchronized实现。
相比于 1.7 版本,它做了两个改进
- 取消了 segment 分段设计,直接使用 Node 数组来保存数据,并且采用 Node 数组元素作为锁来实现每一行数据进行加锁来进一步减少并发冲突的概率
- 将原本数组+单向链表的数据结构变更为了数组+单向链表+红黑树的结构。为什么要引入红黑树呢?
在正常情况下,key hash 之后如果能够很均匀的分散在数组中,那么 table 数 组中的每个队列的长度主要为 0 或者 1.但是实际情况下,还是会存在一些队列长度过长的 情况。如果还采用单向列表方式,那么查询某个节点的时间复杂度就变为 O(n);
因此对于 队列长度超过 8 的列表,JDK1.8 采用了红黑树的结构,那么查询的时间复杂度就会降低到 O(logN),可以提升查找的性能;
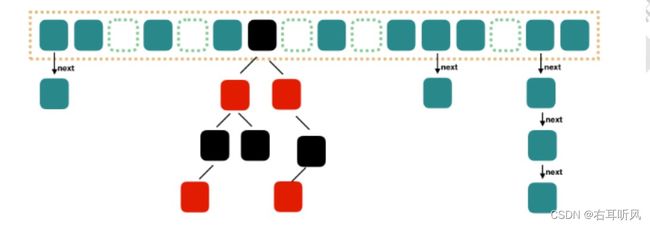
这个结构和 JDK1.8 版本中的 Hashmap 的实现结构基本一致,但是为了保证线程安全性, ConcurrentHashMap 的实现会稍微复杂一下
CAS (compare and swap比较交换)
CAS有3个操作数,内存值V,预期值A,要修改的值B,当且仅当V=A时,才会将V改为B,否则什么都不做。
Java中CAS是通过本地方法JNI实现的。
CAS的缺点:
1、存在ABA问题,其解决思路是使用版本号。
2、循环时间长,开销大
3、只能保证一个共享变量的原子操作。
Java解决ABA问题,有下面2个原子类:
1、AtomicStampedReference类
带有一个时间戳的对象引用。
2、AtomicMarkableRefrence类
维护一个Boolean值标识,处于true和false的切换。这样做只能减少ABA发生的概率,并不能杜绝。
Node链表和红黑树的切换
JDK1.8版本ConcurrentHashMap,加锁是加在Node头部结点上,锁粒度更细,效率更高,大大提升了性能。扩容时阻塞所有读写操作,并发扩容。
如果链表节点超过8个,则会触发链表转化为红黑树。
当红黑树节点小于6个,则红黑树会转化为链表。