Meta视觉大模型来了!完全自监督无需微调,多任务效果超OpenCLIP

©作者 | 萧箫
来源 | 量子位
无需文字标签,完全自监督的Meta视觉大模型来了!
小扎亲自官宣,发布即收获大量关注度——
在语义分割、实例分割、深度估计和图像检索等任务中,这个名叫DINOv2的视觉大模型均取得了非常不错的效果。

甚至有超过当前最好的开源视觉模型OpenCLIP之势。
虽然此前Meta就发布过自监督学习视觉大模型DINO,不过这次AI识别图像特征的能力显然更进一步,准确分割出了视频中的主体:
可别以为DINOv2通过自监督学会的只有图片分割。事实上,它已经能根据不同类别、不同场景下的照片,准确识别出同种物体(狗)的头部、身体和四肢长在哪:

换而言之,DINOv2自己学会了找图像特征。
目前Meta官方不仅已经放出了开源代码,而且还给了网页版Demo试玩。有网友内涵:
什么叫开源,LLaMA,SAM,DINOv2这才叫开源!

一起来看看,DINOv2的效果究竟如何。

准确识别不同画风的同种物体
事实上,DINOv2是基于上一代DINOv1打造的视觉大模型。
这个模型参数量是10亿级,也仍然是视觉Transformer架构(ViT),但与DINO不太一样的是,这次DINOv2在数据集上经过了精心挑选。
具体来说,DINOv2构建了一个数据筛选pipeline,将内容相似的图片精心筛选出来,同时排除掉相同的图片:
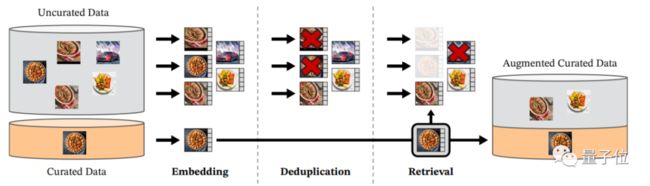
最终呈现给DINOv2的训练数据图片虽然没有文字标签,但这些图片的特征确实是相似的。
采用这类数据训练出来的视觉模型,效果如何?
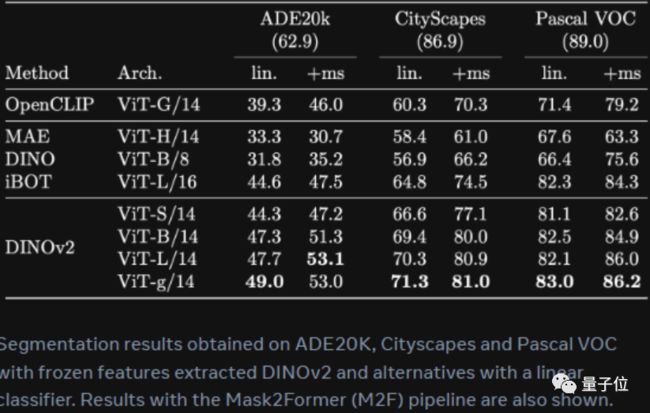
这是DINOv2在8个视觉任务上的表现,包括语义分割、分类、深度估计等,其中橙色是自监督方法的效果,深粉色是弱监督方法的效果。
可以看见,经过自监督学习的视觉模型,表现上已经与经过弱监督学习的模型性能相当。

实际效果也不错,即便在一系列照片中,相同物体的画风并不相似,DINOv2也能准确识别它们的特征,并分到相似的列表中。
如(a)组中都具有翅膀的鸟和飞机、(b)组中的大象和大象雕塑、(c)组中的汽车和汽车玩具模型、(d)组中的马和涂鸦版马:

而且从PCA(主成分分析)图像效果来看,DINOv2不仅能准确分类,还能用不同颜色标出它们“相同”的部分,例如象鼻都是绿色、车轮都是红色、马的尾巴是黄色等。
换而言之,DINOv2能理解这些图像中的相似之处,就像人会形容飞机“看起来像一只鸟”一样。
目前DINOv2已经放出Demo,我们也试了试它的实际效果。

Demo直接可玩
官网已经开放语义分割、图像检索和深度估计三大功能的试玩。
据Meta介绍,这几个任务中,DINOv2在大多数基准上超过了目前开源视觉模型中表现最好的OpenCLIP。
我们先来看看深度估计的效果。

值得一提的是,在效果更好的情况下,DINOv2运行的速度也比iBOT更快,相同硬件下只需三分之一的内存,运行速度就能比DINOv2快上2倍多。

这是Meta论文中与OpenCLIP在实际例子上的比较效果:

我们用这张猛男版新宝岛试一下,看起来还不错,即使是高糊图片也能比较好地估计出深度:

接下来是语义分割的效果,这里也先给出Meta论文中的数据对比情况:
这里也给出OpenCLIP和DINOv2的对比,中间的图片是OpenCLIP的效果,右边是DINOv2分割的效果:

我们也用一张办公室的图片试了一下,看起来DINOv2还是能比较准确地分割人体、物体的,但在细节上会有一些噪点:

最后是图片检索。
官网上给出的图片效果还是挺不错的,输入铁塔照片,可以生成不少含铁塔的相似艺术图片:

这里我们也试了试,输入一张华强买瓜,给出来的艺术图片大多数与西瓜有关:

那么,这样的自监督视觉大模型可以用在哪里?
从Meta给出的视频来看,目前有一些比较环保的用途,例如用于估计全球各地的树木高度:

除此之外,如同扎克伯格所说,DINOv2还能被用于改善医学成像、粮食作物生长等。当然这里小扎还进一步强调:
可以被用于制作更具沉浸感的元宇宙。
嗯,看来Meta的元宇宙路线还将继续……
试玩Demo地址:
https://dinov2.metademolab.com/demos
项目地址:
https://github.com/facebookresearch/dinov2
参考链接:
https://www.facebook.com/zuck/posts/pfbid02f3chCYQphfYnzRaDXeJxsT5EmyhbrFsjqLaU31KuTG63Ca4yMXFcDXQcukYPbWUMl
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
