flink sql 源码走读 --- 解释flink jdbc where 条件为什么没有下推数据库
本文通过一个具体案例,说明 flink sql 如何实现 connector 加载、source/sink 端操作、数据库连接等。可以帮助大家了解其原理,并在代码中找到落库执行SQL生成逻辑,得到where条件并没有下推到库执行的结论。
(解决办法参考下篇文章:flink sql (jdbc)如何支持where 条件下推数据库)
案例如下:
create table mysql_test_12 (
ID STRING,
NAME STRING,
primary key(ID) not enforced
) with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://${mysql_hosts}:${mysql_port}/sitrdw001?useSSL=false&useUnicode=true&characterEncoding=UTF-8',
'username' = '${mysql_username}',
'password' = '${mysql_pass}',
'scan.fetch-size'='1000',
'table-name' = 'test_12'
);
create table es_test_12 (
ID STRING,
NAME STRING,
primary key(ID) not enforced
) with (
'connector' = '${es_connector}',
'hosts' = '${es_hosts}',
'username' = '${es_username}',
'password' = '${es_pass}',
'index' = 'test_12'
);
insert into es_test_12
select
*
from mysql_test_12
where ID = '20200604'
;
这是一个很简单的案例,source 端连接mysql数据库,sink 端连接 es,获取 ID = ‘20200604’ 的数据写入es。
一、整体概念

再具体展开之前,有必要熟悉一下flink sql的整体框架。
catalog:表目录的抽象,上面案例中的建表语句 create table mysql_test_12 … as … 就是一个catalog,主要包含库名、表名、列名、列数据类型等信息;
DynamicTableSourceFactory:每个connector 都会有一个固定的 factory 工厂,主要处理一些配置项(with 后面配置的选项,比如’scan.fetch-size’=‘1000’),做一些配置检查和封装工作,最终生成DynamicTableSource。
DynamicTableSource:数据源,在这里会创建可执行的 sql 语句,并生成 ScanRuntimeProvider 具体执行类。
ScanRuntimeProvider :sql执行的具体类,在这里执行 sql 查询,并提供数据查询/遍历 接口。
sink 跟source 比较类似,提供对外写出的能力,这里就不在展开。
二、创建 source 节点
案例中 ‘connector’ 配置的是 ‘jdbc’,那么 flink 是如何创建 jdbc 的source 节点呢?

CatalogSourceTable是创建source节点的入口类,可以看到这里创建了一个 JdbcDynamicTableSource 数据源,我们点击进去查看具体的实现方法,发现主要它主要调用的是 FactoryUtil 的 createTableSource 方法:
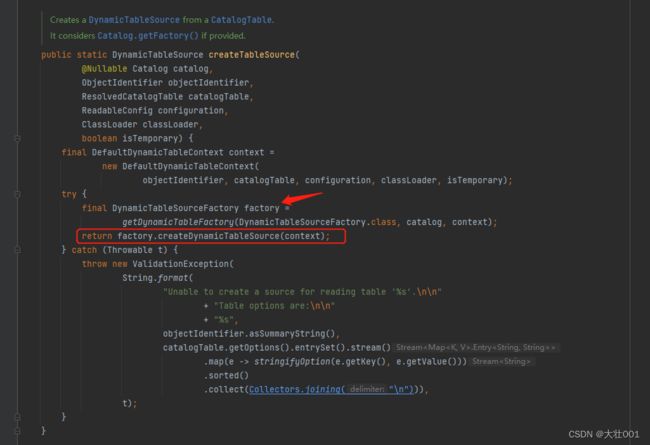 从这段代码中 可以看出,flink先获取 DynamicTableSourceFactory,再调用factory.createDynamicTableSource(context) 方法得到具体的实现source。
从这段代码中 可以看出,flink先获取 DynamicTableSourceFactory,再调用factory.createDynamicTableSource(context) 方法得到具体的实现source。
关于factory的获取,感兴趣的可以继续debug深入了解,我简单概括一下主要逻辑:
1、系统加载 META-INF.services下所有继承 Factory 的类;
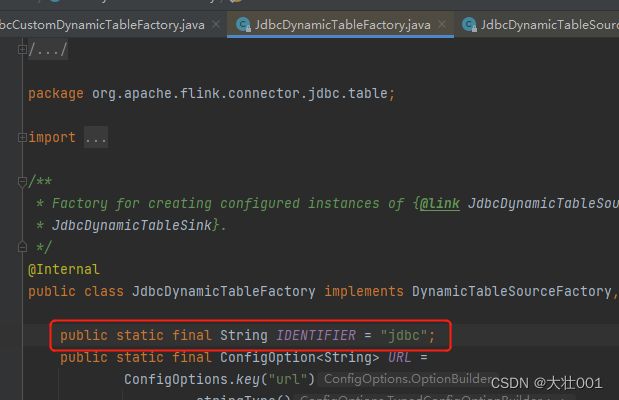
2、遍历每个factory,并调用factory的factoryIdentifier() 方法获取 标识 并进行匹配。比如 JdbcDynamicTableFactory 的 IDENTIFIER(标识符)是’jdbc’ ,刚好匹配上SQL中的connector。
3、找到 factory 后,调用 该factory的createDynamicTableSource() 方法返回source
至此,source节点创建完成。

三、为什么 where 条件不支持下推数据库
想要了解where 条件有没有下推,我们需要去看SQL是如何创建的。DynamicTableSource(jdbc的实现类是JdbcDynamicTableSource)负责构建SQL,核心代码如下:
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
// 用来执行 SQL的具体对象
final JdbcRowDataInputFormat.Builder builder =
JdbcRowDataInputFormat.builder()
.setDrivername(options.getDriverName())
.setDBUrl(options.getDbURL())
.setUsername(options.getUsername().orElse(null))
.setPassword(options.getPassword().orElse(null))
.setAutoCommit(readOptions.getAutoCommit());
// 设置 fetch-size
if (readOptions.getFetchSize() != 0) {
builder.setFetchSize(readOptions.getFetchSize());
}
final JdbcDialect dialect = options.getDialect();
// 通过schema 生成 select 语句。对照案例,query = "SELECT `ID`, `NAME` FROM `test_12`"
String query =
dialect.getSelectFromStatement(
options.getTableName(), physicalSchema.getFieldNames(), new String[0]);
// 如果设置了分区扫描,在sql 后面拼接 where {scan.partition.column} BETWEEN ? AND ?
if (readOptions.getPartitionColumnName().isPresent()) {
long lowerBound = readOptions.getPartitionLowerBound().get();
long upperBound = readOptions.getPartitionUpperBound().get();
int numPartitions = readOptions.getNumPartitions().get();
builder.setParametersProvider(
new JdbcNumericBetweenParametersProvider(lowerBound, upperBound)
.ofBatchNum(numPartitions));
query +=
" WHERE "
+ dialect.quoteIdentifier(readOptions.getPartitionColumnName().get())
+ " BETWEEN ? AND ?";
}
// 设置limit
if (limit >= 0) {
query = String.format("%s %s", query, dialect.getLimitClause(limit));
}
builder.setQuery(query);
final RowType rowType = (RowType) physicalSchema.toRowDataType().getLogicalType();
builder.setRowConverter(dialect.getRowConverter(rowType));
builder.setRowDataTypeInfo(
runtimeProviderContext.createTypeInformation(physicalSchema.toRowDataType()));
return InputFormatProvider.of(builder.build());
}
通过上面的代码逻辑,不难看出,SQL 主要是根据 schema和 scan.partition来生成的,并没有拼接 where ID = ‘20200604’。where操作应该是在内存中通过 filter 算子进行过滤。
由此可能造成的问题是,即使只需要处理一条数据,flink sql 也会把 test_12 所有的数据加载到内存中,如果遇到大表,会造成处理性能下降的后果。