深度迁移学习十八问
编者按
深度迁移学习是基于深度神经网络的迁移学习方法,BERT通过预训练模型达到深度迁移学习的效果,自从2018年底BERT横空出世以来,就以势不可挡的姿态横扫了众多榜单,甚至在阅读理解任务SQuAD 中超越人类水平。BERT在公检法、媒体出版、军工、快消零售等工业界也迅速落地。BERT几乎在所有的下游任务中效果都获得了明显提升,BERT自此开创了一个NLP的新时代,那就是pre-train + fine-tuning的时代。
基于BERT的各种改进版预训练模型层出不穷,令人眼花缭乱,似乎一不小心就会落伍。但是万变不离其宗,只要掌握了一些最基本的的思想、技术,就能让自己紧跟大神们的脚步,让更优秀的算法模型在工业界持续落地。百分点认知智能实验室梳理了以BERT为代表的基于fine-tuning模式的深度迁移学习中一些疑难问题,整理出18个典型的问题,对理解BERT论文和源代码有明显的帮助,因此分享给大家。
本文作者:崔丙剑 苏海波
基本概念
1.如何正确理解深度迁移学习?
答:迁移学习是机器学习的一个重要分支,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于新领域的一种学习过程。
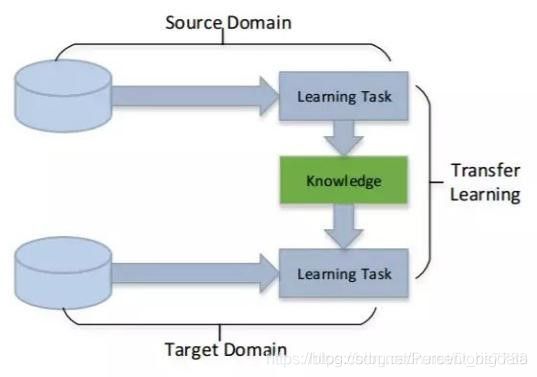
图1: 迁移学习示意图
迁移学习主要有几种形式:基于样本的迁移、基于特征的迁移、基于模型的迁移和基于关系的迁移。重点说下基于模型的迁移,其基本思想是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移。

图2: 基于模型的迁移学习
深度迁移学习主要就是模型的迁移,一个最简单最常用的方法就是fine-tuning,就是利用别人已经训练好的网络,针对目标任务再进行调整。近年来大火的BERT、GPT、XLNET等都是首先在大量语料上进行预训练,然后在目标任务上进行fine-tuning。
- 预训练方法中基于特征的方法与基于微调的方法本质区别在哪里?
答:特征提取(Feature-extract):特征提取是使用之前训练好的模型对新的样本生成特征向量,然后将这些特征作为task-specific模型的输入,训练新的模型参数。比如BERT就是之前学好的模型,把一个句子输入到BERT,可以得到这个句子的向量表示,然后将这个向量作为后续的比如分类模型的输入,在训练的过程中只训练后面的分类模型,BERT的输出仅仅是作为分类模型的输入特征。
模型微调(Fine-tuning):不同于特征提取的方式要另起灶炉针对具体任务设计新的模型,模型微调是直接使用已训练好的模型,针对当前的任务对输出层简单修改,然后在当前任务的数据上进行训练,对部分网络层的参数进行微调,让模型更适合当前的任务。这种模型微调的方式能充分利用深度神经网络强大的泛化能力,还避免了设计新的的模型,无需从头开始训练,能达到更快的收敛速度和更好的效果。
模型输入
-
BERT的输入有三个embedding,各自的作用是什么?
答:BERT embedding layer有三个输入,分别是token-embedding、segment-embedding和position-embedding。
Token-embedding:将单词转换为固定维的向量表示形式,在BERT-base中,每个单词都表示为一个768维的向量。
Segment-embedding:BERT在解决双句分类任务(如判断两段文本在语义上是否相似)时是直接把这两段文本拼接起来输入到模型中,那么模型是如何区分这两段文本呢,答案就是通过segment-embedding。对于两个句子,第一个句子的segment-embedding部分全是0,第二个句子的segment-embedding部分全是1。
Position-embedding:BERT使用transformer编码器,通过self-attention机制学习句子的表征,self-attention不关注token的位置信息,所以为了能让transformer学习到token的位置信息,在输入时增加了position-embedding。 -
BERT的输入有token-embedding、segment-embedding和position- embedding三个向量,三者之间是拼接的关系还是相加的关系,维度分别是多少?
答:三个向量是相加后作为第一层transformer的输入,三个向量的维度都是768。Pytorch版BERT-embedding具体实现代码如下,从中我们可以明显看出是相加的关系。

图3: BERT embedding层源码 -
BERT的position-embedding为什么是通过学习出来的而不像transformer那样通过sinusoidal函数生成?
答:BERT论文中作者对此没有说明原因,不过可以从以下几点进行分析:
a) 用于机器翻译的平行语料有限,transformer那篇论文在做机器翻译任务时没有像现在训练BERT⼀样海量的训练数据,所以即使⽤了learned-position-embedding也未必能够学到⼀个好的表⽰。⽽BERT训练的数据⽐transformer⼤的多,因此可以让模型⾃⼰去学习位置特征。
b) 对于翻译任务,encoder的核⼼任务是提取完整的句⼦语义信息,无需特别关注某个词的具体位置。而BERT在做下游的序列标注类任务时需要确切的位置信息,模型需要给出每个位置的预测结果,因此BERT在预训练过程中需要建模完整的词序信息。 -
BERT分词时使用的是wordpiece,wordpiece实现了什么功能,为什么要这么做?
答:先说为什么这么做,如果以传统的方式进行分词,由于单词存在时态、单复数等多种变化会导致词表非常大,严重影响训练速度,并且即使一个非常大的词表仍无法处理未登录词(OOV, Out Of Vocabulary),影响训练效果。而如果以character级别进行文本表示粒度又太细。Subword粒度在word与character之间,能够较好的解决上述分词方式面临的问题,已成为了一个重要的NLP模型性能提升方法。Subword的实现方式主要有wordpiece和BPE(Byte Pair Encoding),BERT使用了wordpiece方式。
Wordpiece的功能:Wordpiece可以理解为把⼀个单词再拆分成subword,比如"loved",“loving”, “loves"这三个单词,其实本⾝的语义都是“爱”,但是如果以单词为单位,那这些词就算是不⼀样的词。Wordpiece算法能够把这3个单词拆分成"lov”, “#ed”, “#ing”, "#es"几部分,这些单词都有一个共同的subword“lov”,这样可以把词的本⾝的意思和前缀、后缀分开,使最终的词表变得精简,并且寓意也能更清晰。 -
BERT的词汇表是怎么生成的?
答:可能很多人没思考过这个问题,虽然在上一个问题中我们已经知道wordpiece会把单词拆分成subword,但是能拆分的前提是有一个subword词汇表。这个问题中我们就来详细看下这个subword词汇表的生成方法。
将wordpiece词汇表生成之前我们还是先看下BPE词汇表是怎么生成的,因为两者非常相似。
BPE词汇表生成算法如下:
a) 准备训练语料用于生成subword词表,需要量足够大;
b) 预设定好期望的subword词表的大小;
c) 将单词拆分为字符序列并在末尾添加后缀“ ”,统计单词频率,例如“ low”的频率为5,那么我们将其改写为“ l o w ”: 5。这一阶段的subword的粒度是单字符;
d) 统计连续字节对出现的频率,选择频率最高的合并成新的subword;
e) 重复第4步,直到subword词表大小达到第2步设定的值,或下一个最高频的字节对出现频率为1。
下边来看一个例子:假设我们的训练语料为:
lower出现2次,newest出现6次,widest出现3次,low出现5次
根据上述第3步的操作可以处理成如下格式:
{'l o w e r ': 2, ‘n e w e s t’: 6, 'w i d e s t ': 3, 'l o w ': 5}
其中的key是词表中的单词拆分成字母,末尾添加后缀“”,value代表单词出现的频率。此时初始的词表中是训练语料中所有单词的字母集合,大小为10,如下表:
[l, o, w, e, r, n, s, t, i, d]
我们设定最终的词表大小为18,然后开始整个算法中最重要的是第4步,过程如下:
原始词表: {'l o w e r ': 2, 'n e w e s t ': 6, 'w i d e s t ': 3, 'l o w ': 5}
出现最频繁的序列: (‘s’, ‘t’) 9
将”st”加入词表,第1次循环结束,此时词表大小为11;
合并最频繁的序列后的词表: {'n e w e st ': 6, 'l o w e r ': 2, 'w i d e st ': 3, 'l o w ': 5}
出现最频繁的序列: (‘e’, ‘st’) 9
将”est”加入词表,第2次循环结束,此时词表大小为12;
合并最频繁的序列后的词表: {'l o w e r ': 2, 'l o w ': 5, 'w i d est ': 3, 'n e w est ': 6}
出现最频繁的序列: (‘est’, ‘’) 9
将“est”加入词表,第3次循环结束,此时词表大小为13;
合并最频繁的序列后的词表: {‘w i d est’: 3, 'l o w e r ': 2, ‘n e w est’: 6, 'l o w ': 5}
出现最频繁的序列: (‘l’, ‘o’) 7
将“lo”加入词表,第4次循环结束,此时词表大小为14;
合并最频繁的序列后的词表: {‘w i d est’: 3, 'lo w e r ': 2, ‘n e w est’: 6, 'lo w ': 5}
出现最频繁的序列: (‘lo’, ‘w’) 7
将“low”加入词表,第5次循环结束,此时词表大小为15;
合并最频繁的序列后的词表: {‘w i d est’: 3, 'low e r ': 2, ‘n e w est’: 6, 'low ': 5}
出现最频繁的序列: (‘n’, ‘e’) 6
将“ne”加入词表,第6次循环结束,此时词表大小为16;
合并最频繁的序列后的词表: {‘w i d est’: 3, 'low e r ': 2, ‘ne w est’: 6, 'low ': 5}
出现最频繁的序列: (‘w’, ‘est’) 6
将“west”加入词表,第7次循环结束,此时词表大小为17;
合并最频繁的序列后的词表: {‘w i d est’: 3, 'low e r ': 2, ‘ne west’: 6, 'low ': 5}
出现最频繁的序列: (‘ne’, ‘west’) 6
将“newest”加入词表,第8次循环结束,此时词表大小为18,整个循环结束。
最终我们得到的词表为:
[l, o, w, e, r, n, s, t, i, d, st, est,est, lo, low, ne, west, newest]
Wordpiece与BPE稍有不同,主要区别在于BPE是通过最高频率来确定下一个subword,而wordpiece是基于概率生成新的subword,另一个小的区别是wordpiece后缀添加的是“##”而不是“<\w>”,整个算法过程如下:
a)准备训练语料用于生成subword词表,需要量足够大;
b)预设定好期望的subword词表大小;
c)将单词拆分为字符序列并在末尾添加后缀“##”;
d)从所有可能的subword单元中选择加入语言模型后能最大程度地增加训练数据概率的组合作为新的单元;
e)重复第4步,直到subword词表大小达到第2步中设定的值,或概率增量低于某一阈值。
-
BERT的输入token-embedding为什么要在头部添加"[CLS]"标志?
答:CLS是classification的缩写,添加该标志主要用于句子级别的分类任务。BERT借鉴了GPT的做法,在句子首部增加一个特殊的token“[CLS]”,在NSP预训练任务中,就取的是“[CLS]”位置对应的最后的隐状态,然后接一个MLP输出两个句子是否是上下句关系。可以认为“[CLS]”位置的信息包含了句子类别的重要特征。同理可以取“[MASK]”位置的向量用于预测这个位置的词是什么。 -
BERT输入的长度限制为512,那么如何处理长文本?
答:BERT由于position-embedding的限制只能处理最长512个词的句子。如果文本长度超过512,有以下几种方式进行处理:
a)直接截断:从长文本中截取一部分,具体截取哪些片段需要观察数据,如新闻数据一般第一段比较重要就可以截取前边部分;
b)抽取重要片段:抽取长文本的关键句子作为摘要,然后进入BERT;
c)分段:把长文本分成几段,每段经过BERT之后再进行拼接或求平均或者接入其他网络如lstm。
模型原理 -
Attention机制相比CNN、RNN有什么样的优势?为什么?
答:在传统的seq2seq模型中,我们一般使用RNN或CNN对序列进行编码,然后采用pooling操作或者直接取RNN的终态作为输入部分的语义编码C,然后把C输入到解码模块中,在解码过程中,C对每个位置的输出重要程度是一致的,如下图所示:

图4: 普通的seq2seq
然而在自然语言中,一个句子中不同部分的重要性也是不一样的,用RNN或CNN进行句子编码,并不能学习到这样的信息。因此出现了attention,顾名思义就是在解码时能对序列中不同位置分配一个不同的注意力权重,抽取出更加关键和重要的信息,从而使模型做出更好的判断,就像我们人在看一个句子时,重点关注的是其中的重要信息,对不重要的信息根本不关心或基本不关心。
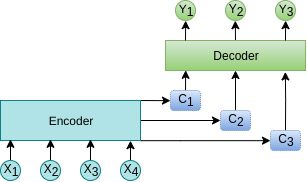
图5: 基于attention的seq2seq
-
BERT使用multi-head attention机制, multi-head的输出是如何拼接在一起的?维度大小是多少?
答:mutli-head attention的计算过程如下图所示:

图6: Multi-head attention计算过程
输入向量维度为768维,经过每个self-attention后得到隐层输出为64维,然后把12个输出拼接起来得到768维的向量。 -
BERT MLM(Masked Language Model)任务具体训练方法为:随机遮住15%的单词作为训练样本,其中80%用“[MASK]” 来代替,10%用随机的一个词来替换,10%保持这个词不变。这么做的目的是什么?
答:要弄明白为什么这样构造MLM的训练数据,我们需要首先搞明白什么是MLM、为什么要使用MLM,以及MLM存在哪些问题。
a)为什么使用MLM:传统的语言模型一般都是单向的,要同时获取上下文信息的常见做法是分别训练正向与反向的语言模型,然后再做ensemble,但这种做法并不能充分利用上下文信息。MLM 的意义在于能够真正利用双向的信息,使模型学习到上下文相关的表征。具体做法就是随机屏蔽(mask)输入文本中的部分token,类似于完形填空,这样在预测被mask部分的token时就能够同时利用上下文信息。
b)MLM存在问题:由于预训练数据中存在“[MASK]”这个token,而在实际的下游任务中对BERT进行fine-tuning时,数据中没有“[MASK]”,这样就导致预训练模型使用的数据和fine-tuning任务使用的数据不一致,会影响fine-tuning的效果。
为了让MLM能够学习上下文相关特征,同时又尽量避免pre-train和fine-tuning数据不一致的问题,数据处理时就采取题目中策略,具体处理策略和原因解释如下:

-
BERT的参数量如何计算?
答:要计算BERT的参数量,首先需要对BERT的结构了解的非常清楚,下面我们就来看下base版BERT 110M的参数到底是怎么计算出来的。
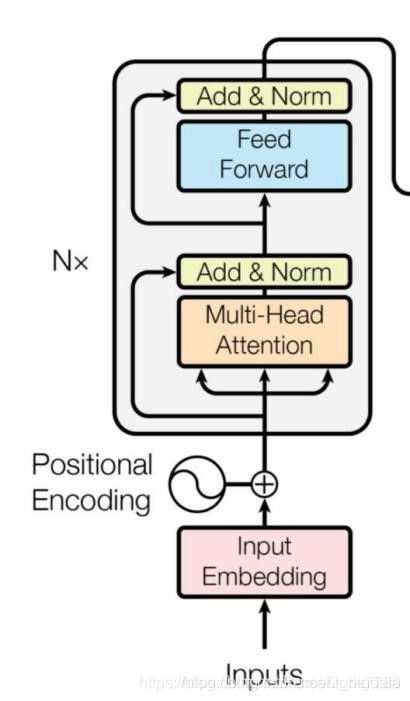
图7: BERT结构图
a) embedding层的参数
BERT的输入有三种embedding,如下源码中所示:

图8: BERT embedding层源码
vocab_size=30522,hidden_size为768,最大位置长度为512,type_vocab_size=2,因此可以计算出:
embedding层的参数量 =(30522+512+2)*768=23,835,648
b) multi-headattention的参数

图9: Self attention计算过程
先来看下multi-head attention的计算过程:embedding层的输出x分别与三个矩阵WQ、Wk、Wv相乘得到Q、K、V,再经过右上图的计算得到一个self-attention的输出,12个self-attention的输出拼接起来得到,再经过一个线性变换得到multi-head attention的输出。
WQ、Wk、Wv的维度均为76864,head数为12,线性变换矩阵为768768,因此可以计算出:
multi-head的参数量 =76864312+768768=2,359,296
c) 全连接层(FeedForward)的参数量
全连接层把multi-head attention输出的维度从768映射到3072又映射到768,公式如下图所示:
其中W1维度为7683072,W2维度为3072768,因此可以计算出:
全连接层的参数量 = 76830722=4,718,592
Base版BERT使用了12层transformer的encoder,因此可以计算出:
总参数量 = embedding参数量+12(multi-headattention参数量+全连接参数量)
=23,835,648+12*(2,359,296+4,718,592)=108,770,304≈110M
- BERT基于NSP和MLM两个任务进⾏预训练,如果对BERT进⾏改进,⼀个可⾏的⽅向就是增加更多的预训练任务,那么除了这两个任务之外,还可以增加哪些预训练任务呢?
答:⾸先这些预训练任务的训练数据要能从⽆监督的数据中获取,这样才能获取到海量的训练数据,符合这⼀条件的任务都可以进⾏尝试,如百度的ERNIE增加了很多个预训练任务,相比于原始BERT有了明显的提升。几个有代表性的预训练任务如下:
Knowledge Masking Task:BERT的MLM任务中是对句⼦中单个的token进⾏mask,可以对于句⼦中的短语和命名实体进⾏mask。
Capitalization Prediction Task:预测单词是否⼤写,与其他词语相⽐,⼤写词语通常具有特定的语义价值。
Token-Document Relation Prediction Task:预测⼀个段落中的某个token是否出现在原始⽂档的其他段落中。根据经验,在⽂档不同部分都出现的单词通常是⽂档的关键词,因此这⼀任务可以在⼀定程度上使模型能够捕获文档的关键字。
Sentence Distance Task:⼀个学习句⼦间距离的任务,该任务被建模为⼀个3类分类问题,“0”表示两个句⼦在同⼀个文档中相邻,“1”表示两个句⼦在同⼀个文档中,但不相邻,“2”表示两个句子来自两个不同的文档。
模型的进化
15.自回归语言模型(AR, Autoregressive LM)与自编码语言模型(AE, Autoencoder LM)的区别?
答:自回归语言模型:根据上文内容预测下一个单词或者根据下文内容预测上一个单词,这样单向的语言模型就是自回归语言模型。LSTM、GPT、ELMO都是自回归语言模型。自回归语言模型的缺点,是不能同时利用上下文信息。
自编码语言模型:自编码器是一种通过无监督方式学习特征的方法,用神经网络把输入变成一个低维的特征,这就是编码部分,然后再用一个解码器把特征恢复成原始的信号,这就是解码部分。具体到语言模型中,BERT使用的MLM就是自编码语言模型,对一些token进行mask,然后拿被mask位置的向量(包含了上下文的信息)来预测该位置真正的token。
自编码语言模型的优点就是可以同时利用上下文信息,缺点就是预训练阶段和fine-tuning阶段使用的训练数据不一致,因为fine-tuning阶段的数据是不会被mask的。
16.XLNET相对于BERT做了哪些重要改进?
答:BERT的AE语言模型虽然能同时学习上下文信息但是会导致预训练数据和fine-tuning阶段的数据不一致从而影响fine-tuning的效果。而XLNET的思路就是使用AR语言模型,根据上文预测下文,但是在上文中添加了下文信息,这样既解决了BERT面临的问题也同时利用了上下文信息。
XLNET改进后的语言模型叫做PermutationLanguage Model(PLM),其重点就是permutation,用一个例子来解释:对于一个输入句子X=[x1, x2, x3, x4],我们希望预测x3,在正常的输入中通过AR语言模型只能看到x1和x2。为了在预测x3时能看到x4,XLNET的操作是固定x3的位置,然后把其它的词进行随机排列,得到如:[x4, x1, x3, x2],[x1, x4, x3, x2]等数据,这样就可以使用单向的AR语言模型来学习双向信息。
这时有人可能就会有疑问:就算训练时可以对输入句子进行排列组合,但是fine-tuning时没法这样做啊。没错,fine-tuning阶段确实不能对输入做排列,只能输入原始句子,所以XLNET在预训练阶段也是不能显示地对输入进行排列的。为了解决这个问题,XLNET的输入还是原始的句子,只不过是在transformer内部利用attention mask来实现的,而无需真正修改句子中词语的顺序。例如原来的句子是X=[x1, x2, x3, x4],如果随机生成的序列是[x3, x2, x4,x1],但输入到 XLNET 的句子仍然是[x1, x2,x3, x4],此时设置attention mask如下图:

图10: Attention mask示意图
图中的掩码矩阵,白色表示不遮掩,黑色表示遮掩。第 1 行表示 x1 的掩码,因为x1是句子的最后一个 token,因此可以看到之前的所有 token [x3,x2,x4];第2行是x2的掩码,因为x2是句子的第二个token,所以能看到前一个token x3;第3行、第4行同理。这样就实现了尽管当前输入看上去仍然是[x1, x2, x3, x4],但是已经改成排列组合的另外一个顺序[x3, x2,x4, x1]了。如果用这个例子用来从左到右训练LM,意味着当预测x2的时候,它只能看到上文x3;当预测x4的时候,只能看到上文x3和x2,……
17.RoBERTa相对于BERT做了哪些重要改进?
答:RoBERTa相对于BERT在模型结构上并没有改变,改进的是预训练方法,主要改进有以下几点:
a) 静态mask变为动态mask
BERT MLM任务中,有15%的样本在预处理阶段会进行一次随机mask,具体的mask方式参考问题12,然后在整个训练过程中,这15%的被mask的样本其mask方式就不再变化,也不会有新的被mask样本,这就是静态mask。
RoBERTa采用了一种动态mask的方式,它并没有在预处理的时候对样本进行mask,而是在每次向模型提供输入时动态生成mask,所以训练样本是时刻变化的,并且实验表明这种动态mask的方式要比BERT原始的静态mask效果要好。
b) 去除NSP任务
很多实验表明NSP任务的没多大意义,RoBERTa中去除了该任务,不过在生成数据时也做了一些改进,原始的BERT中是选择同一篇文章中连续的两个句子或不同文章中的两个句子,而RoBERTa的输入是连续的多个句子(总长度不超过512)。
c) 更多的数据、更大的mini-batch、更长的训练时间
BERT base的训练语料为13G,batch-size为256,而RoBERTa的训练语料扩大了10到130G,训练中batch-size为8000,实为大力出奇迹的杰出代表。
18.ALBERT相对于BERT做了哪些重要改进?
答:ALBERT是一个精简的BERT,参数量得到了明显的降低,使得BERT的大规模应用成为可能。相对于BERT,ALBERT主要有三点改进:
a) Embedding matrix因式分解
在BERT、XLNET等模型中,embedding的维度 E 和隐藏层维度 H 是相等的,都是768,V是词表的大小一般的3万左右。从建模的角度来说,embedding层的目标是学习上下文无关的表示,而隐藏层的目标是学习上下文相关的表示,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H>>E。如果像BERT那样让E=H,那增大H之后,embedding matrix大小VH会变的很大。
ALBERT采取因式分解的方式来降低参数量,先将单词映射到一个低维的embedding空间,然后再将其映射到高维的隐藏空间,让H>>E,这样就可以把embedding matrix的维度从O(VH)减小到O(VE+EH),参数量减少非常明显。
b) 跨层权重共享
Transformer参数共享可以只共享全连接层、只共享attention层,ALBERT结合了这两种方式,让全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数,采用该方案后效果下降的并不多,但是参数量减少了很多,训练速度也提升了很多。此外实验还表明ALBERT每一层的输出embedding相比于BERT来说震荡幅度更小一些,可以增加模型的鲁棒性。
c) 修改预训练任务NSP为SOP
一些研究表明BERT的NSP并不适合用于预训练任务,原因可能是负样本来源于不同的文档,模型在判断两个句子的关系时不仅考虑了两个句子之间的连贯性,还会考虑两个句子的话题,而两篇文档的话题通常不同,模型可能更多的通过话题去分析两个句子的关系,而不是连贯性,这使得NSP任务变的相对简单。
ALBERT中设计了SOP(Sentence-orderprediction)任务,其正样本选取方式与BERT一致(来自同一文档的两个连续句子),而负样本也同样是选自同一文档的两个连续句子,但交换了两个句子的顺序,从而使模型可以更多地建模句子之间的连贯性而不是句子的话题。
参考文献:
1.http://jd92.wang/assets/files/transfer_learning_tutorial_wjd.pdf
2.https://jalammar.github.io/illustrated-transformer/
3.https://medium.com/@init/why-BERT-has-3-embedding-layers-and-their-implementation-details-9c261108e28a
4.https://medium.com/@makcedward/how-subword-helps-on-your-nlp-model-83dd1b836f46
5.BERT Explained: State ofthe art language model for NLP.
https://towardsdatascience.com/BERT-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
6.https://zhuanlan.zhihu.com/p/70257427
7.https://arxiv.org/pdf/1706.03762
8.https://arxiv.org/pdf/1906.08237
9.https://arxiv.org/pdf/1907.11692
10.https://arxiv.org/pdf/1909.11942
11.https://arxiv.org/pdf/1905.07129