日撸 Java 三百行(26 天: 栈模拟树的前、后序遍历)
注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录
一、前序与后序遍历的互换特性
二、前序遍历的迭代思想与代码实现
三、后序遍历的迭代思想与代码实现
总结
一、前序与后序遍历的互换特性
昨天我们用了大篇章讲述了中序遍历的栈模拟的迭代写法,今天按照顺序继续讲述前序与后序遍历。今天专门把这两个遍历合在一起说也是有原因的,虽然我们之前对于这俩的递归操作都是分开说明的,但是在迭代操作中,不同的遍历的代码差距是要比递归要大的。所以某些可以偷懒的地方我们可能是在复杂度不攀升的基础上尽可能偷懒了,于是乎,我们就挖掘出了后序遍历中与前序所类似的一个特性:


我们之前完成的递归遍历代码,主要是三个构成:
1.当前结点遍历-左子树-右子树
2.左子树-当前结点遍历-右子树
3.左子树-右子树-当前结点遍历
可以基本发现,无论顺序怎么变,始终是先左子树后右子树的顺序。倒不是说不可以先右后左,只是因为我们习惯的先左后右思维,于是最早定义数据结构的先辈们就基本确定了这三种遍历为主要遍历,而且我们的大部分生活问题也是基于先左后右的,所以这样定义也确实能解决大部分问题了。
然后我把前序与后序的示意图给了出来给大家观察下,现在我们不妨对后序遍历的操作进行进行镜像便可以得到CBA的遍历顺序,这个顺序恰好是前序遍历的ABC的逆。这个原因就是我们利用从右向左的“ 前序遍历 ”。我们正常的前序遍历是【结点值-左-右】,而从右自左的前序遍历时【结点值-右-左】,而这个刚好是正常后序遍历的逆操作,一般的正常的后序不可能是正常前序的逆因为他们都是满足着左孩子在左右孩子在右这个铁律,因此只有尝试从右到左的遍历才可以完成左右的逆置。
完成到这一步其实我们已经有了大概实现后序遍历的思路了,简单总结来说,就是我们完全拷贝前序遍历的思路,然后把所有访问左儿子的变成访问右儿子,访问右儿子的变成访问左儿子(遍历的镜像),然后访问的结点的操作正常进行,只不过操作不再是print输出,而在每次正常访问时都放到输出栈中。最后,把输出栈清空并输出就实现了逆序输出。
二、前序遍历的迭代思想与代码实现
因为昨天我把递归到迭代的思想转换说的比较细了,今天我们就不再画大量的文笔去描述这个过程了,而主要侧重于如何去实现这段代码。于是我们直接把迭代的思路总结出来(模仿昨天的思路,直接开始昨天博客的第三部分):
- 得到了当前的核心结点(核心结点的含义其实可以等价理解为递归方法中的当前函数)
- 访问核心结点的值
- 核心结点若有左子树:【左结点入栈,进入左子树,并回到第一步】;若无则进入第步四部
- 出栈得到核心结点,若有右子树:【右结点入栈,进入右子树,并回到第一步】;若无则进入第步四部
这个操作相比昨天,核心结点的访问操作值放到了得到核心结点后进行的第一步操作,这是因为前序遍历的特点决定的。前序遍历的值访问要先于回溯,而第一次回溯完成之后(离开左子树后)立马就要进入下一次右子树的入口,所以我们出栈得到核心结点后立马就开始判断右子树是否存在,若存在就进入,否则当前活动自然结束。回到上一次结点,当然,既然是“ 回到 ”上一个结点,那么上个结点也是在回溯的状态,所以还是执行第四部的出栈。我们昨天提到过,出栈操作就等价于递归当中的取出当前执行函数,或者当前结点操作结束后,进入上一个结点的回溯操作。
具体在代码中,我们需要进一步改进一些顺序,使得循环能够表示出来。无论是左孩子还是右儿子,在三步和第四部在失败后都会回到第一步,我们定义这是自然结束;成功后都会进入第四步,我们定义这是一次进入下一个结点的跳转,我们可以归纳这些操作,在代码中统一地、一律地执行进入操作。具体到代码,让当前核心结点tempNode直接转变为对应的子结点,这样的话子节点是否存在问题就统一转化为tempNode是否是null的问题,null的话就触发了我们上面四步骤的中的退回第一步操作;非null的话就统一进入第四步。
在具体点,这就构成了null与非null的二元问题,这就用一个if-else语句描述就好了。另外提一个思想准备,我们所谓的“进入XX结点”在代码上的表现都是令当前核心结点等于其某个子节点。
/**
*********************
* Pre-order visit with stack
*********************
*/
public void preOrderVisitWithStack() {
ObjectStack tempStack = new ObjectStack();
BinaryCharTree tempNode = this;
while (!tempStack.isEmpty() || tempNode != null) {
if (tempNode != null) {
System.out.print("" + tempNode.value + " ");
tempStack.push(tempNode);
tempNode = tempNode.leftChild;
} else {
tempNode = (BinaryCharTree) tempStack.pop();
tempNode = tempNode.rightChild;
} // Of if
} // Of while
}// Of preOrderVisitWithStack当null的话,说明上一步结点没有任何儿子,按照四步骤来看,退回到第一步,第一步与第二步紧密相连,于是我们在if语句作用域内完成“ 2.访问核心结点的值 ”的操作。同时按照顺序进入第三步。第三步中的的“若...否则...”、“ 并回到第一步 ” 、 “ 若无则进入第步四部 ” 是二元区分关系的条件与结果,这些逻辑已经被我们解构到下次全局的if-else判断了,所以没必要再判断了,直接无脑“ 【左结点入栈,进入左子树,...】 ”就好。
当非null的话,说明上一步结点存在某个儿子,按照四步骤来看,退回到第四步,于是我们在else语句作用域内完成“ 4.出栈得到核心结点 ”的操作。同时这一步的“若...否则...”、“ 并回到第一步 ” 、 “ 若无则进入第步四部 ” 是二元区分关系的条件与结果,这些逻辑已经被我们解构到下次全局的if-else判断了,所以没必要再判断了,直接无脑“ 【右结点入栈,进入左子树,...】 ”就好。
综上分析了这样两种情况,代码设计便迎刃而解,关于while的设计我昨天已经了,这里就不再赘述了。
三、后序遍历的迭代思想与代码实现
这个就好讲多了,因为我们刚刚在第一阶段说过前序与后序遍历的互换特性,所以关于后序遍历的思想我直接用前文的总结:
完全拷贝前序遍历的思路,然后把所有访问左儿子的变成访问右儿子,访问右儿子的变成访问左儿子(遍历的镜像),然后访问的结点的操作正常进行,只不过操作不再是print输出,而在每次正常访问时都放到输出栈中。最后,把输出栈清空并输出就实现了逆序输出。
我们按照这个思路,先拷贝代码,然后把rightChild改为leftChild,leftChild改为rightChild。再额外添加一个栈tempOutputStack,把所有print的操作改为入栈。最后在我们整体的while结束后,附带上tempOutputStack的出栈并print(这个步骤是实现逆序输出)。代码如下:
/**
*********************
* Post-order visit with stack
*********************
*/
public void postOrderVisitWithStack() {
ObjectStack tempStack = new ObjectStack();
BinaryCharTree tempNode = this;
ObjectStack tempOutputStack = new ObjectStack();
while(!tempStack.isEmpty() || tempNode!=null) {
if(tempNode != null) {
//Store for output
tempOutputStack.push(tempNode.value);
tempStack.push(tempNode);
tempNode=tempNode.rightChild;
}else {
tempNode = (BinaryCharTree)tempStack.pop();
tempNode = tempNode.leftChild;
}// Of of
}// Of while
//Now reverse output.
while(!tempOutputStack.isEmpty()) {
System.out.print(""+tempOutputStack.pop()+" ");
}// Of while
}// Of postOrderVisitWithStack总结
今天的内容是昨日的延续,很多关于递归转换为迭代的思路和我的想法都在昨天的博客中。今天主要比较新颖的是关于后续遍历设计的思路。
我当初第一次了解后序的这个特性曾经在本科阶段刷题的时候看到一个大佬写的题解中的,当时我刚刷完前序与中序遍历的迭代写法,但是后序遍历确乎是半天都想不出,后来看题解发现这个解法怎么和前序那么像?为啥还用了两个栈?后来我看到解析之后,认识了后序到前序的转换技巧,大呼巧妙。确实,在学习初期,对二叉树的遍历都局限在先左后右的惯性思路中,当时老师讲二叉树的遍历时也没想那么多,没考虑为递归方法中的这三行代码明明可以按照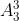 的组合为有6种,为什么我们只用了3种。没想到那不起眼的另外3种方法竟然可以作为前3种常规方法的镜像,去简化栈的辅助迭代方法。
的组合为有6种,为什么我们只用了3种。没想到那不起眼的另外3种方法竟然可以作为前3种常规方法的镜像,去简化栈的辅助迭代方法。
但是有一说一,也是在方法复杂后,我们可以考虑剑走偏锋使用这种巧妙的代替思路,要是一直只是用原先递归操作那样简单的话,我们也不会想这么多吧。但是这也暗示了:今后我们在研究中遇某些联系的,但比较麻烦的问题的时候,要灵活学习使用这种代替的思路,用熟悉的问题去化解麻烦的问题。这也算是一点点微不足道的启示吧